Одноклассники состоят из более чем восьми тысяч железных серверов, расположенных в нескольких датацентрах. Каждая из этих машин была специализированной под конкретную задачу, как для обеспечения изоляции отказов, так и для обеспечения автоматизированного управления инфраструктурой.
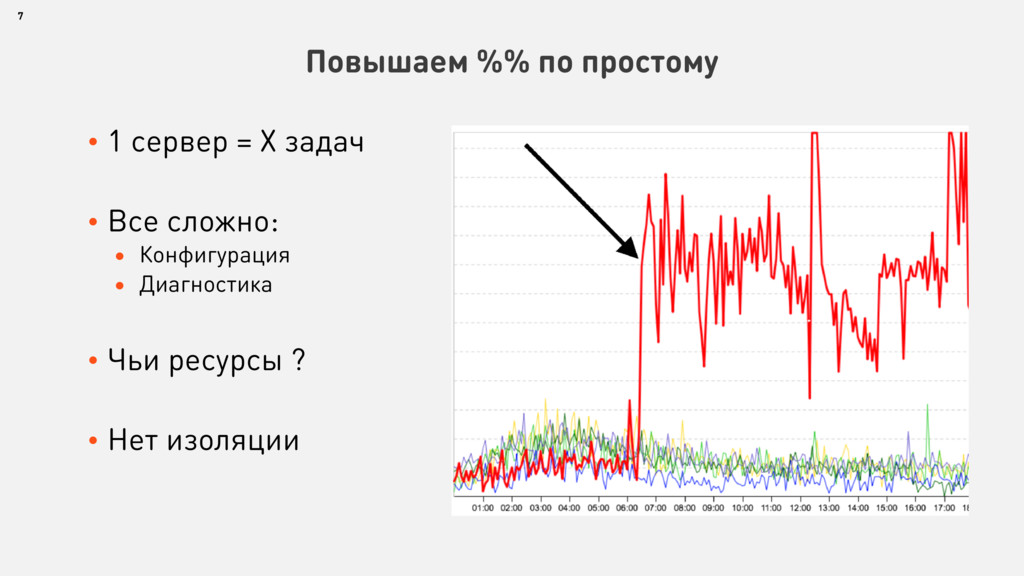
В определенный момент мы поняли, что внедрение новой системы управления позволит нам более эффективно загрузить технику, облегчить управление доступами, автоматизировать (пере)распределение вычислительных ресурсов, ускорить запуск новых сервисов, ускорить реакции на масштабные аварии.
В данном докладе расскажу об основных принципах и процессах, лежащих в основе нашего облака; обеспечения отказоустойчивости как самого облака, так и выполяемых ею задач; нашем подходе к изоляции задач и повышения плотности использования техники.
Я также попытаюсь дать ответ на главный вопрос жизни, вселенной и всего сущего: можно ли сделать так, чтобы Docker не падал.
Social network OK.RU consists of more than 8 000 servers located in several data centers. Each one of these machines was allocated for a specific task, both for failure isolation and for providing automated infrastructure management.
At a certain moment it became clear that a new datacenter management system could improve efficiency in utilizing the hardware, make access management easier, automate resouce managemet, better time to market for new services, faster repair of incidents and even full outages.
This talk is about basic principles and processes of the cloud; fault tolerance of the one-cloud as well as tasks run by it; our strategies of failure isolation and more dense hardware utilization.
Also I'll try to answer the ultimate question of life, the universe and everything: whether it is possible to make Docker work stable.
![one-cloud ОС уровня датацентра в ОК Олег Анастасьев @m0nstermind [email protected]](https://files.speakerdeck.com/presentations/fe1e5b1f7a644653b5c7058d72132c0b/slide_0.jpg){kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
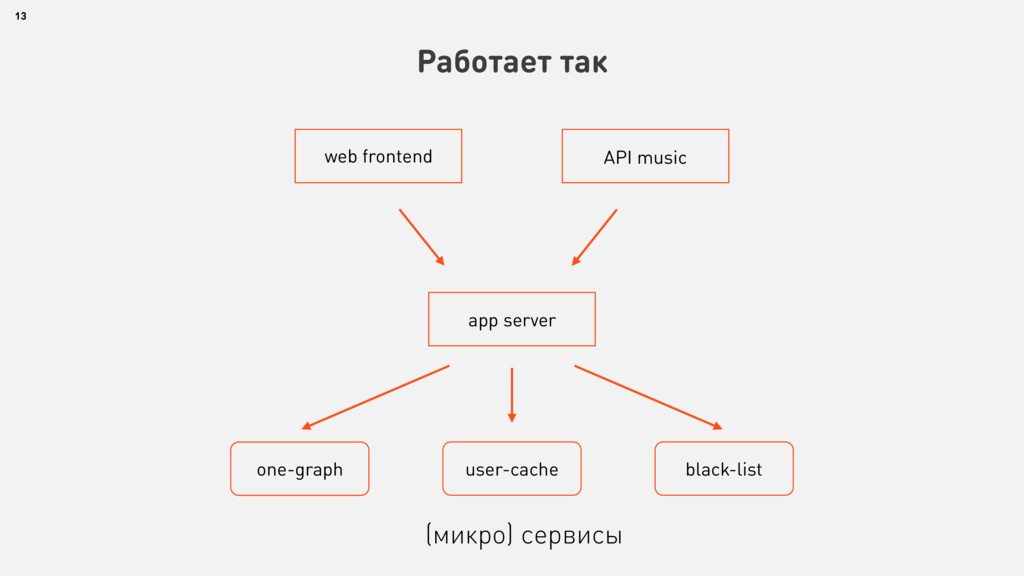{kind=link}
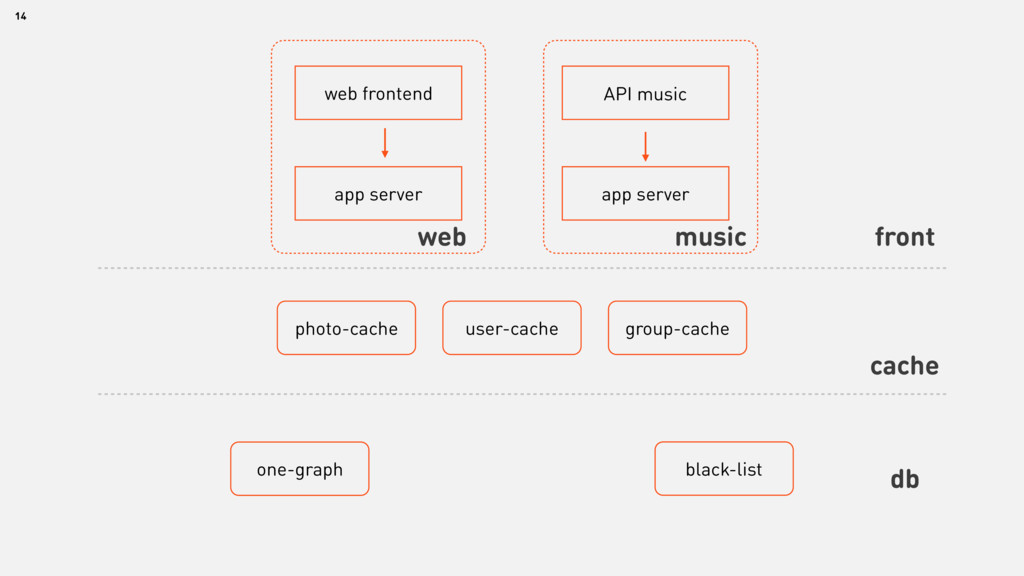{kind=link}
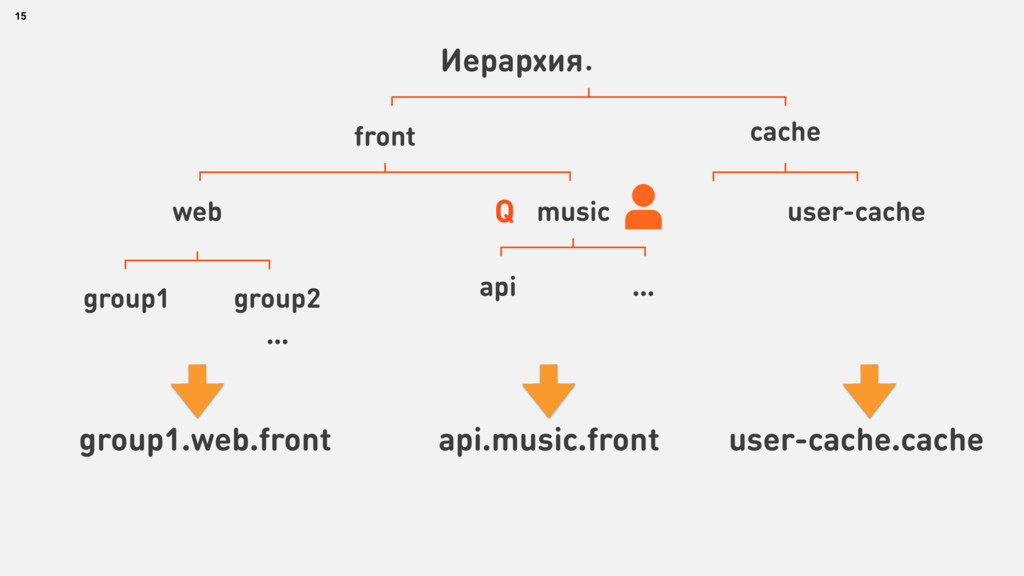{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
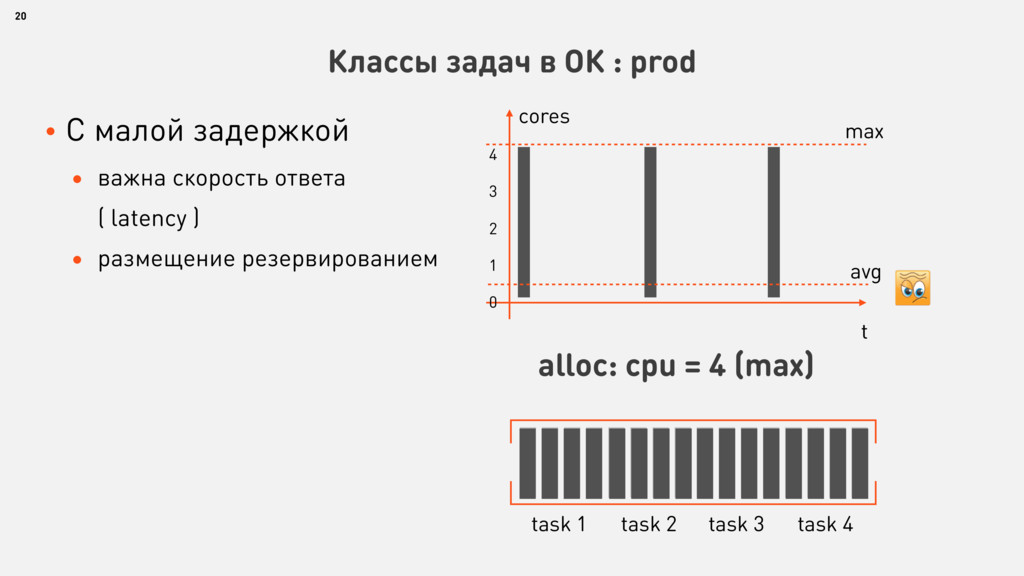{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
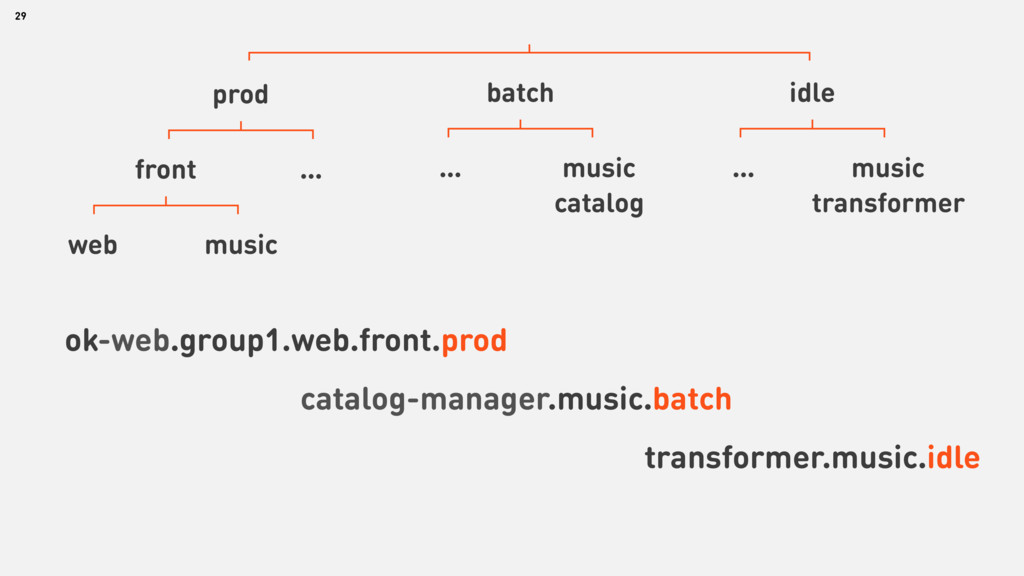{kind=link}
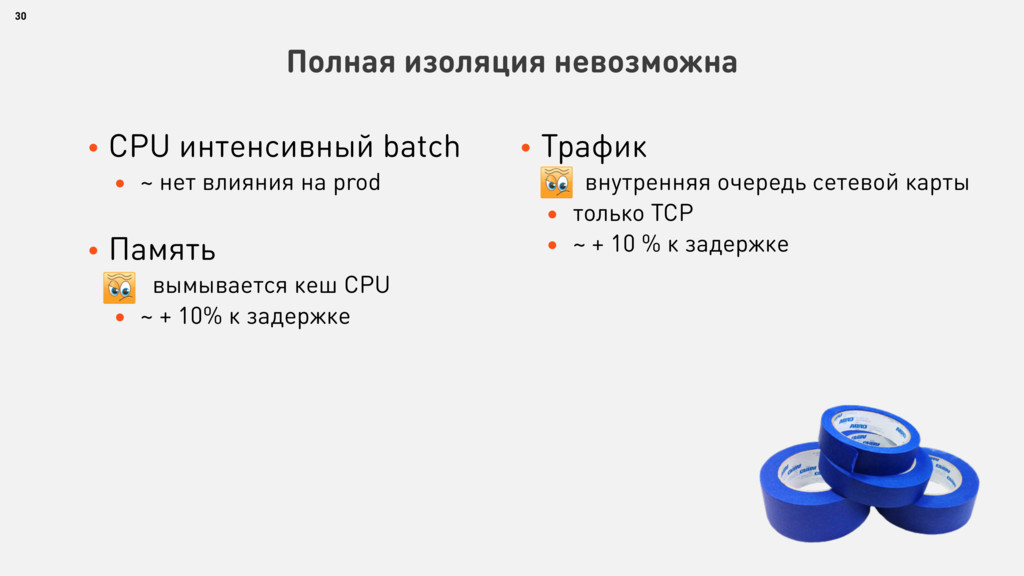{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
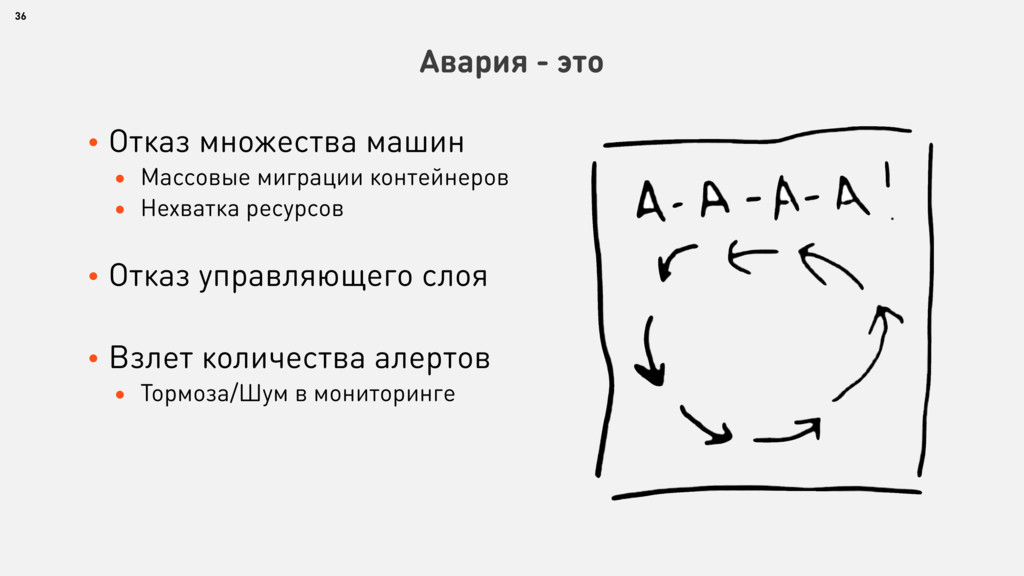{kind=link}
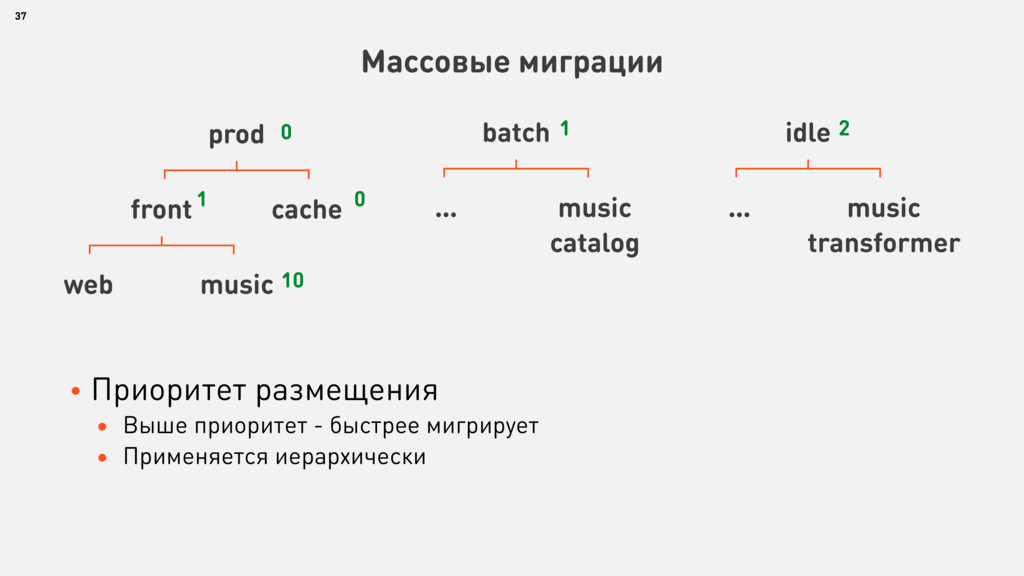{kind=link}
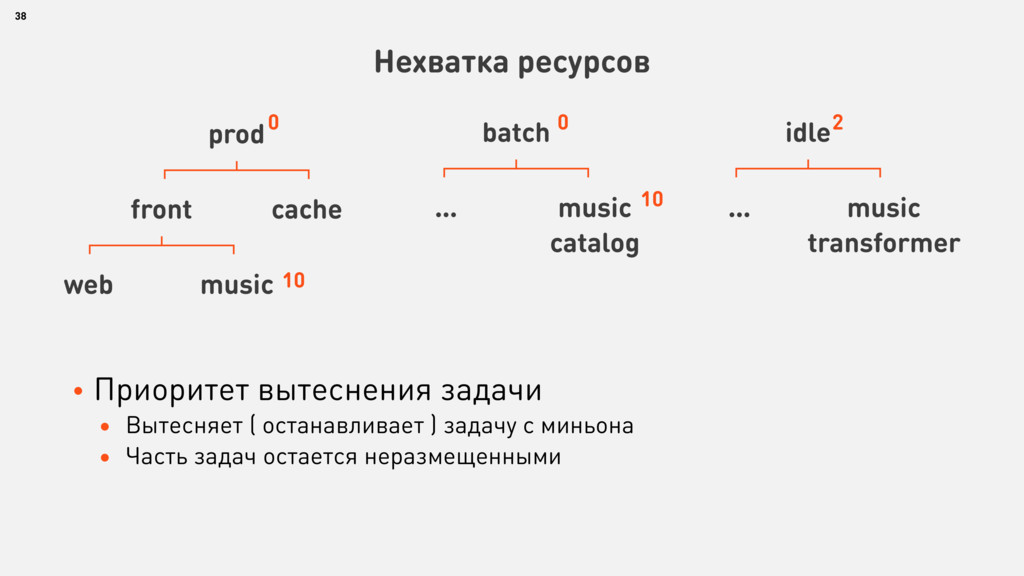{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
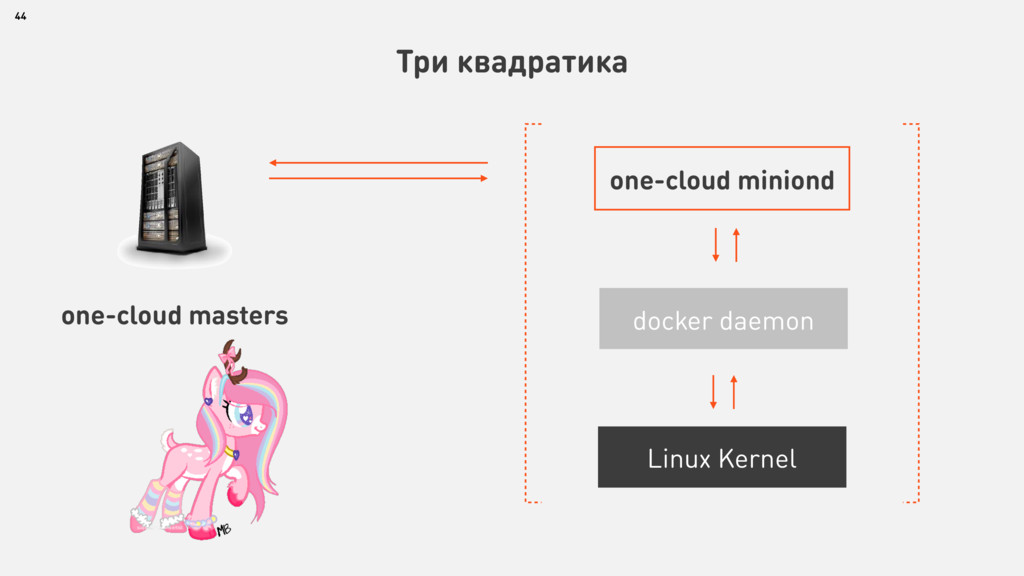{kind=link}
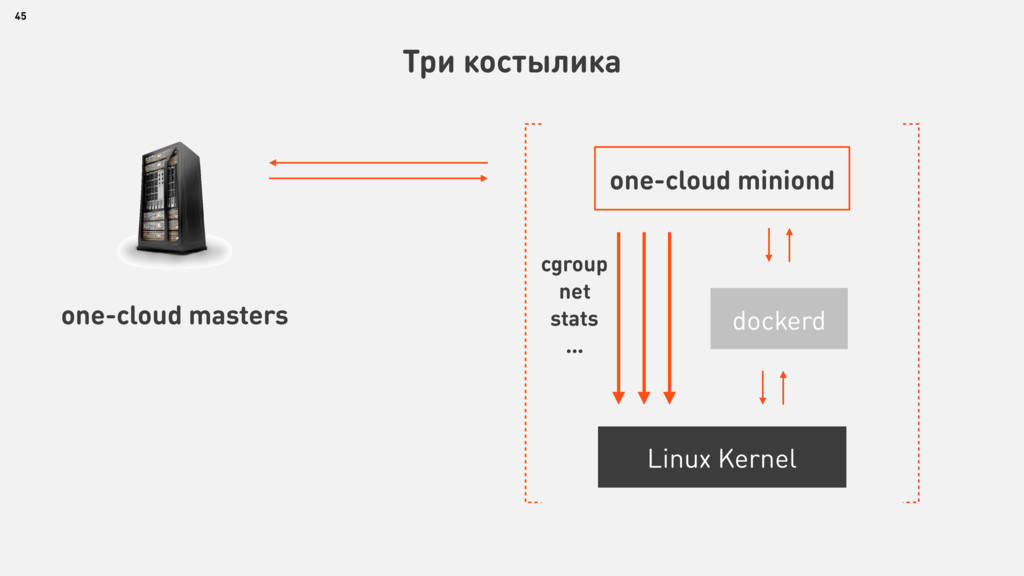{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}