Одноклассники состоят из более чем восьми тысяч железных серверов, расположенных в нескольких дата-центрах. Каждая из этих машин была специализированной под конкретную задачу - как для обеспечения изоляции отказов, так и для обеспечения автоматизированного управления инфраструктурой.
В определенный момент мы поняли, что внедрение новой системы управления позволит нам более эффективно загрузить технику, облегчить управление доступами, автоматизировать (пере)распределение вычислительных ресурсов, ускорить запуск новых сервисов, ускорить реакции на масштабные аварии.
В данном докладе расскажу об основных принципах и процессах, лежащих в основе нашего облака; наиболее интересных деталях его реализации; об обеспечении отказоустойчивости как самого облака, так и выполняемых им задач; нашем подходе к изоляции задач и повышения плотности использования техники.
Также затронем темы реальной эксплуатации как самого облака, так и задач в нем.
![one-cloud Система управления датацентром в ОК Олег Анастасьев @m0nstermind [email protected]](https://files.speakerdeck.com/presentations/0e849700633847d5ba4562c3c01653be/slide_0.jpg){kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
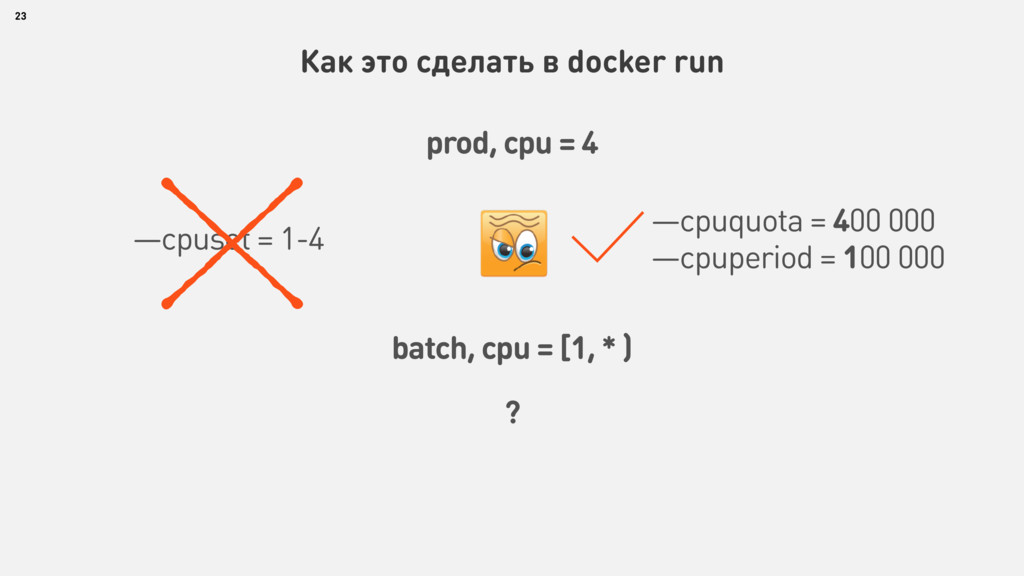{kind=link}
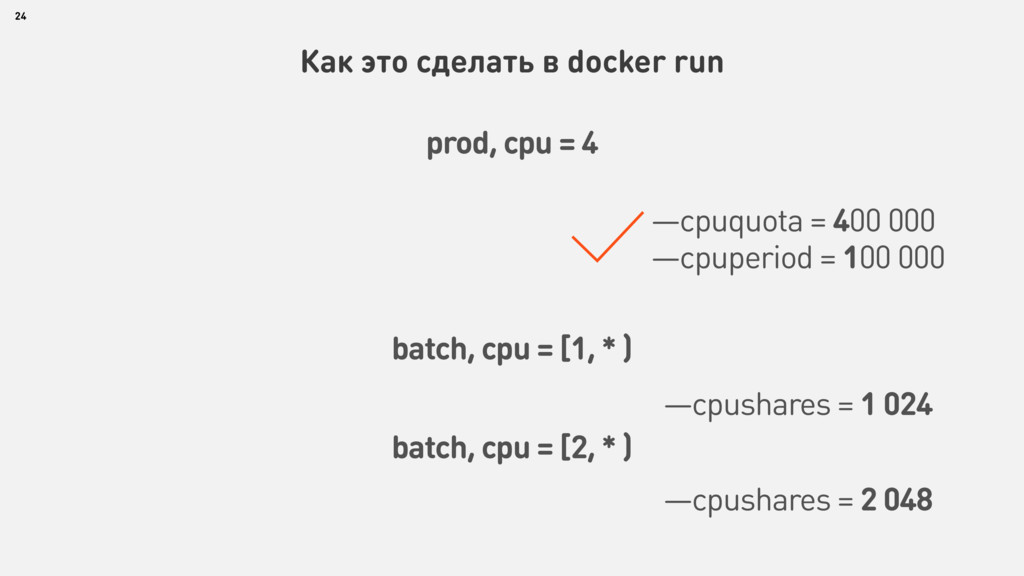{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
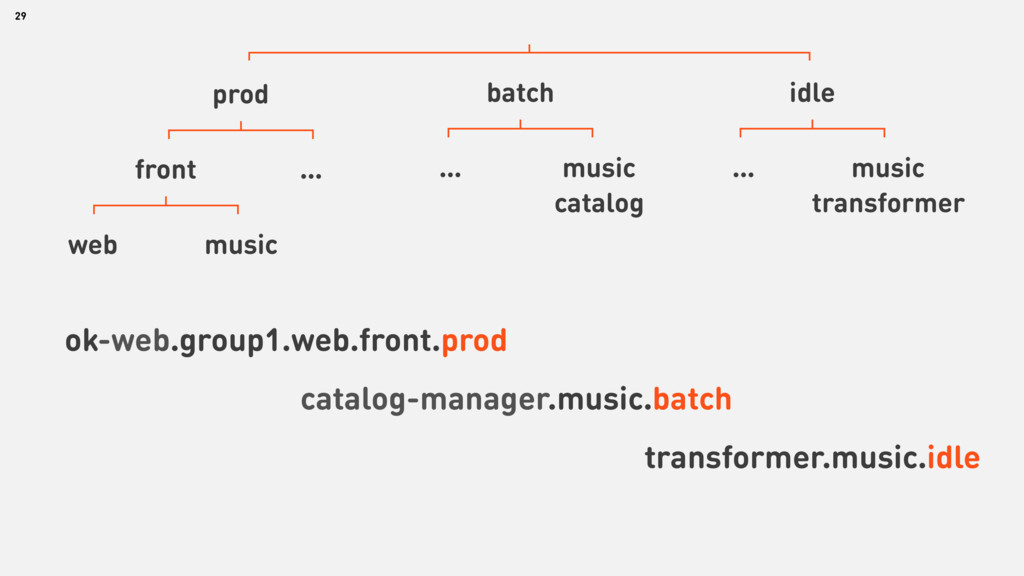{kind=link}
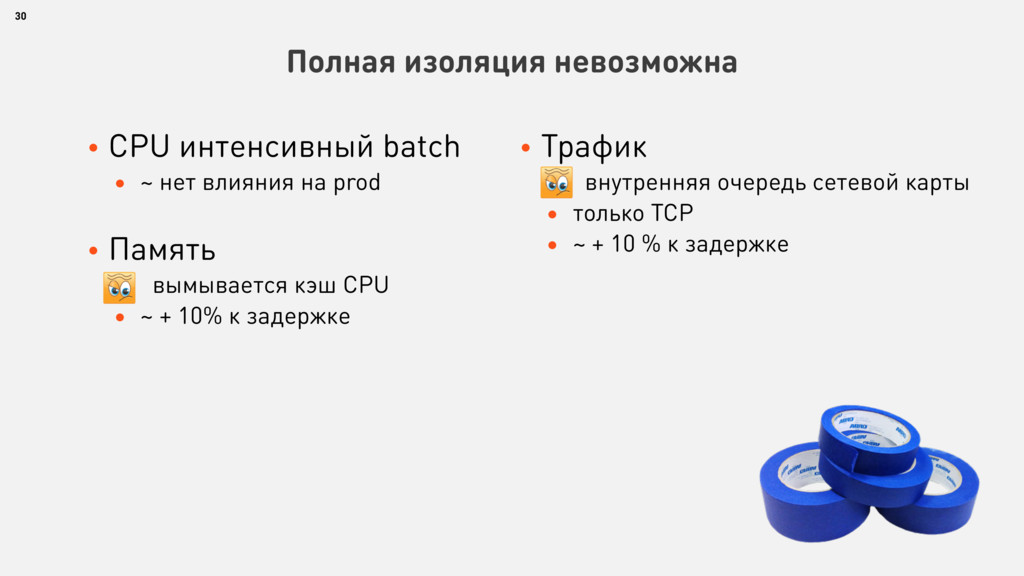{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
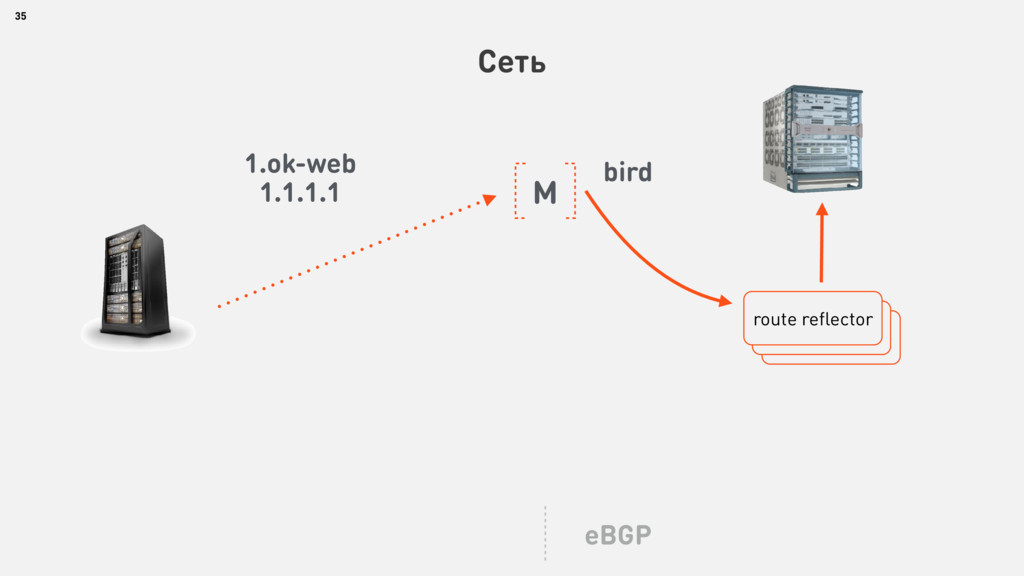{kind=link}
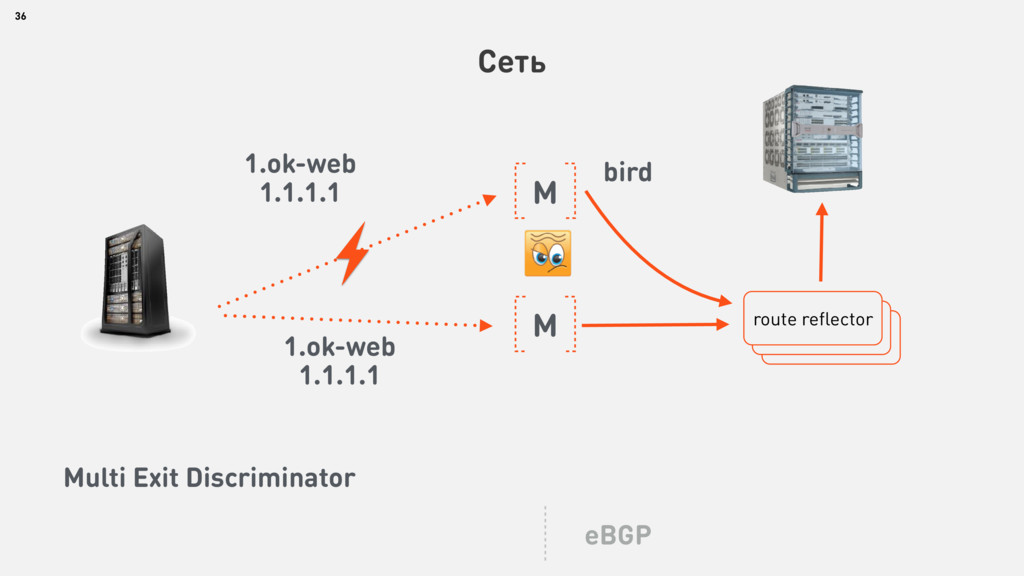{kind=link}
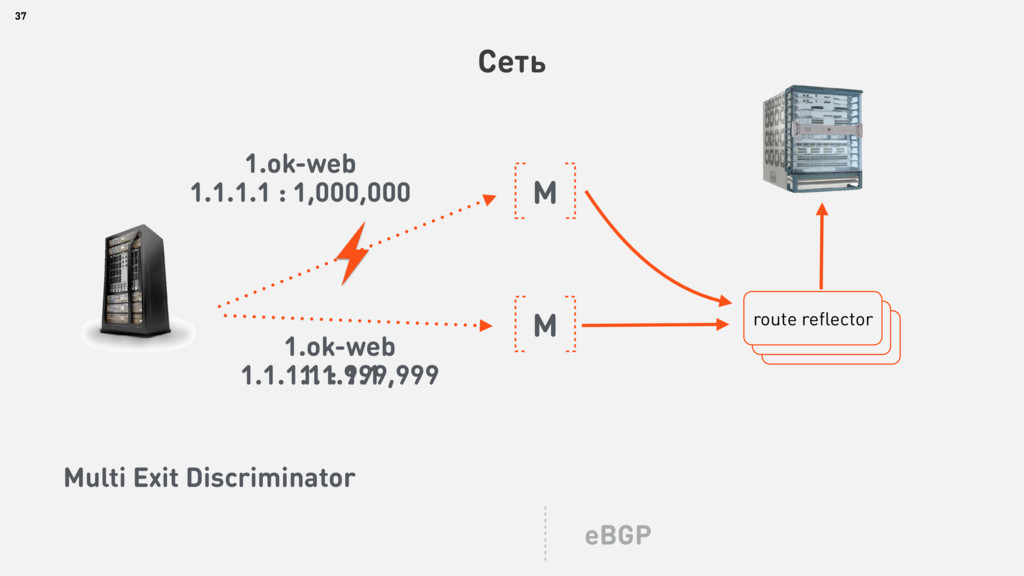{kind=link}
{kind=link}
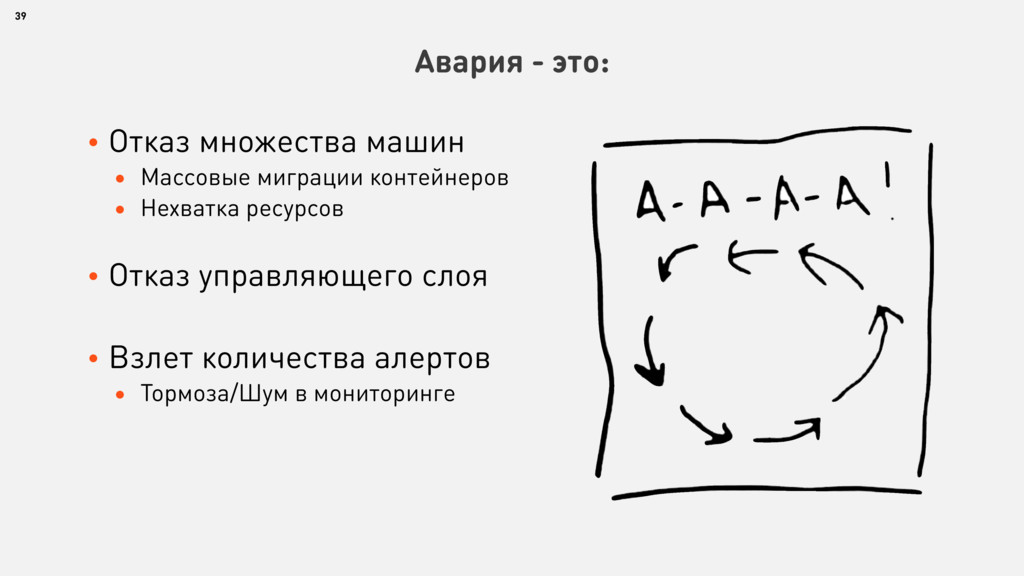{kind=link}
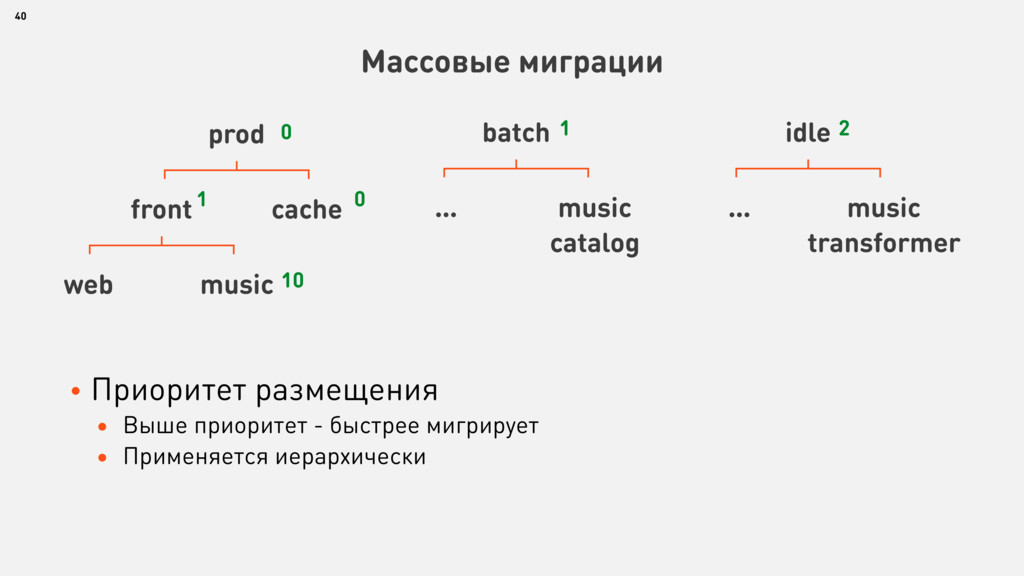{kind=link}
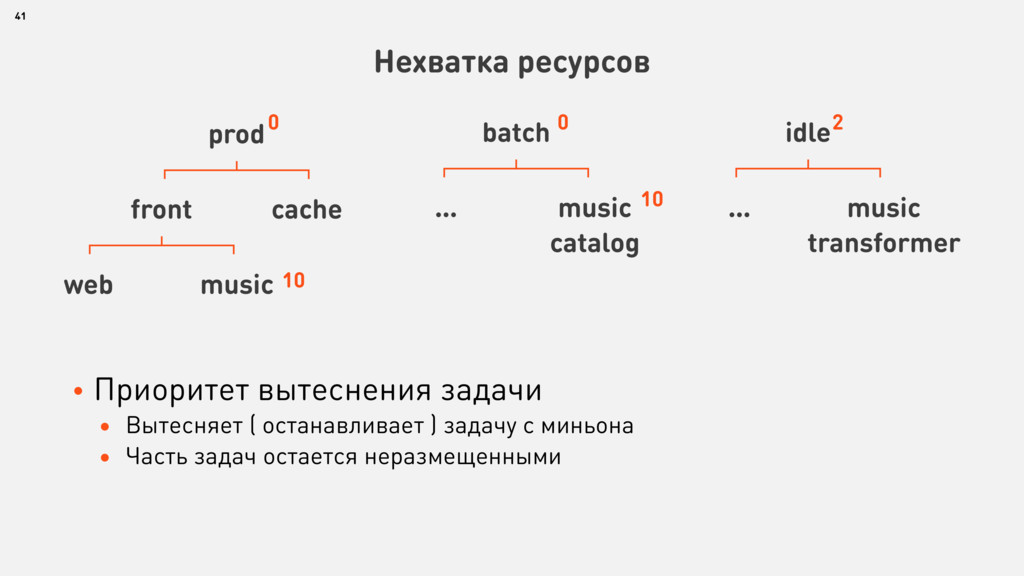{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
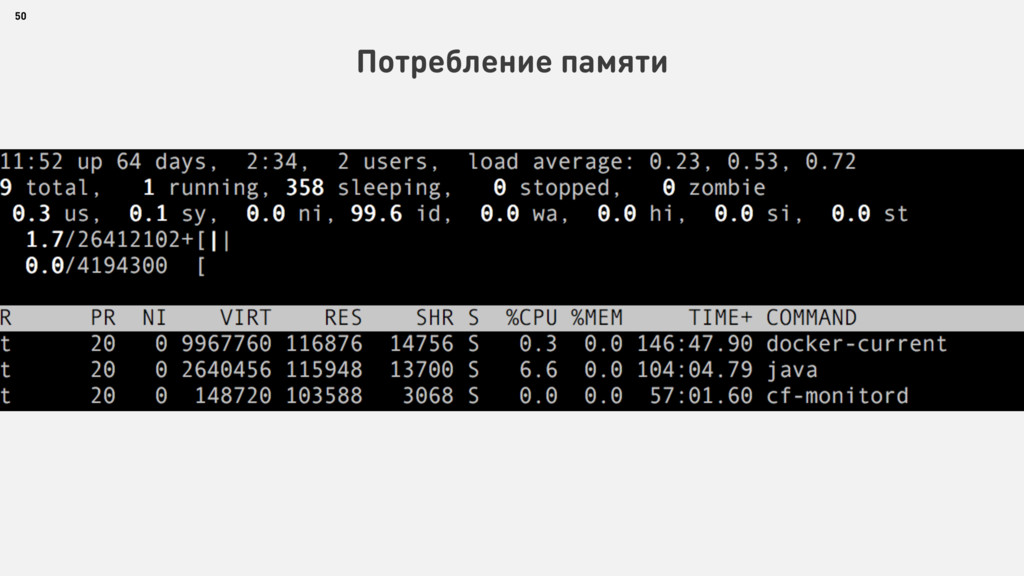{kind=link}