model which imitates target model -> Need real training data (That is very difficult in real problems!) • Score-based, Decision-based (e.g. ZOO[2]) ✓Need many query on test ✓Not need substitute model [1]Ian J Goodfellow, Jonathon Shlens, and Christian Szegedy. Explaining and harnessing adversarial examples. Inter- national Conference on Learning Representations (ICLR), 2015 [2] Pin-Yu Chen, Huan Zhang, Yash Sharma, Jinfeng Yi, and Cho-Jui Hsieh. Zoo: Zeroth order optimization based black- box attacks to deep neural networks without training sub- stitute models. In Proceedings of the 10th ACM Workshop on Artificial Intelligence and Security, pages 15‒26. ACM, 2017 5
model which imitates target model -> Need real training data (That is very difficult in real problems!) • Score-based, Decision-based (e.g. ZOO[2]) ✓Need many query on test ✓Not need substitute model • DaST(proposed mothod) : Not attack method • Train substitute model without real training data -> useful when we need substitute model as Gradient-based attack methods [1]Ian J Goodfellow, Jonathon Shlens, and Christian Szegedy. Explaining and harnessing adversarial examples. Inter- national Conference on Learning Representations (ICLR), 2015 [2] Pin-Yu Chen, Huan Zhang, Yash Sharma, Jinfeng Yi, and Cho-Jui Hsieh. Zoo: Zeroth order optimization based black- box attacks to deep neural networks without training sub- stitute models. In Proceedings of the 10th ACM Workshop on Artificial Intelligence and Security, pages 15‒26. ACM, 2017 6 Give a Solution
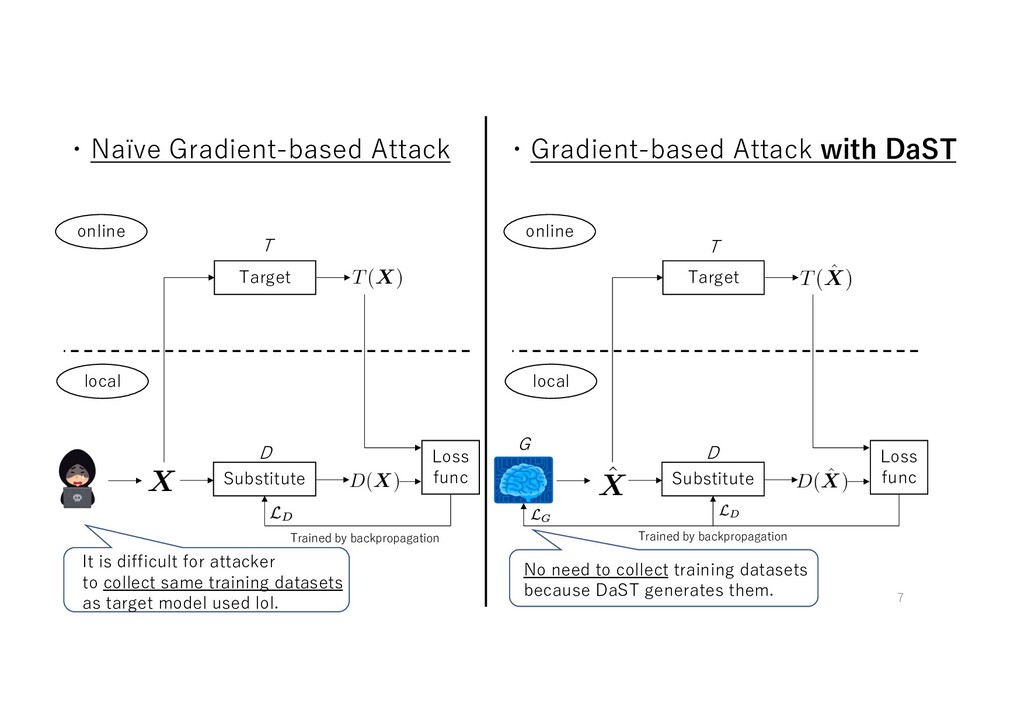
local Target Substitute Loss func ・Gradient-based Attack with DaST It is difficult for attacker to collect same training datasets as target model used lol. Trained by backpropagation Trained by backpropagation No need to collect training datasets because DaST generates them. T T D D G 7
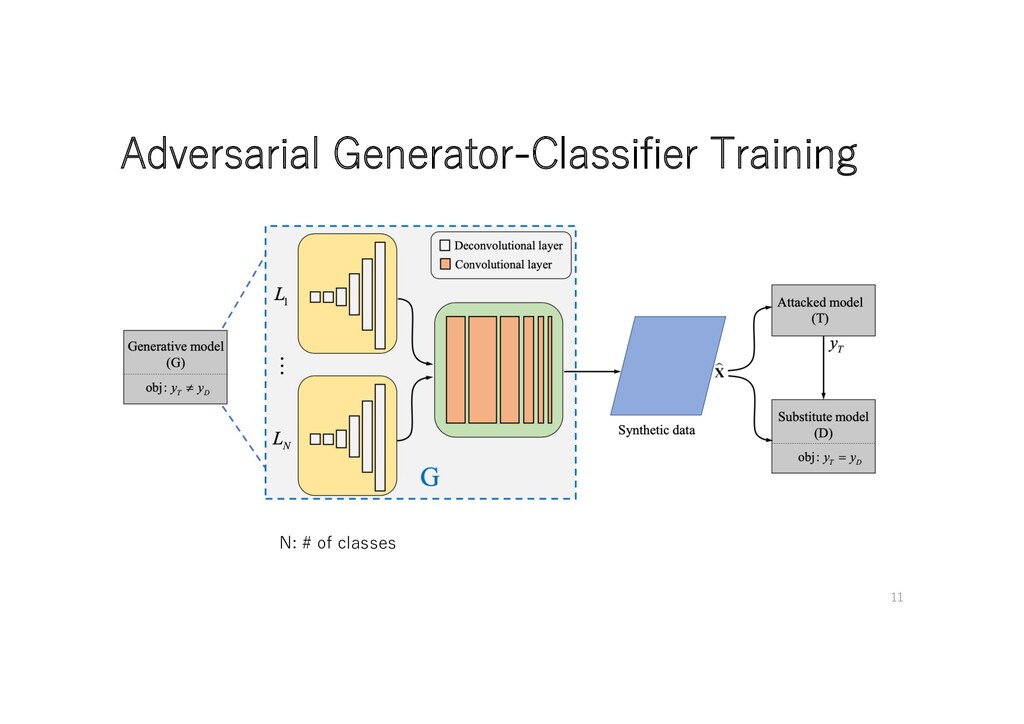
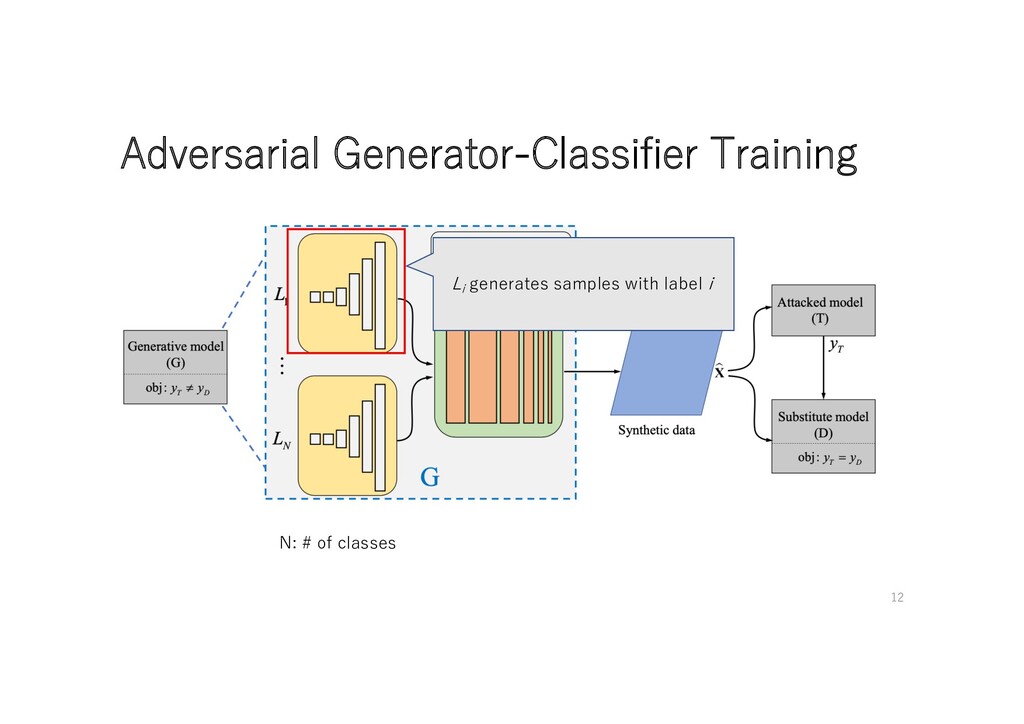
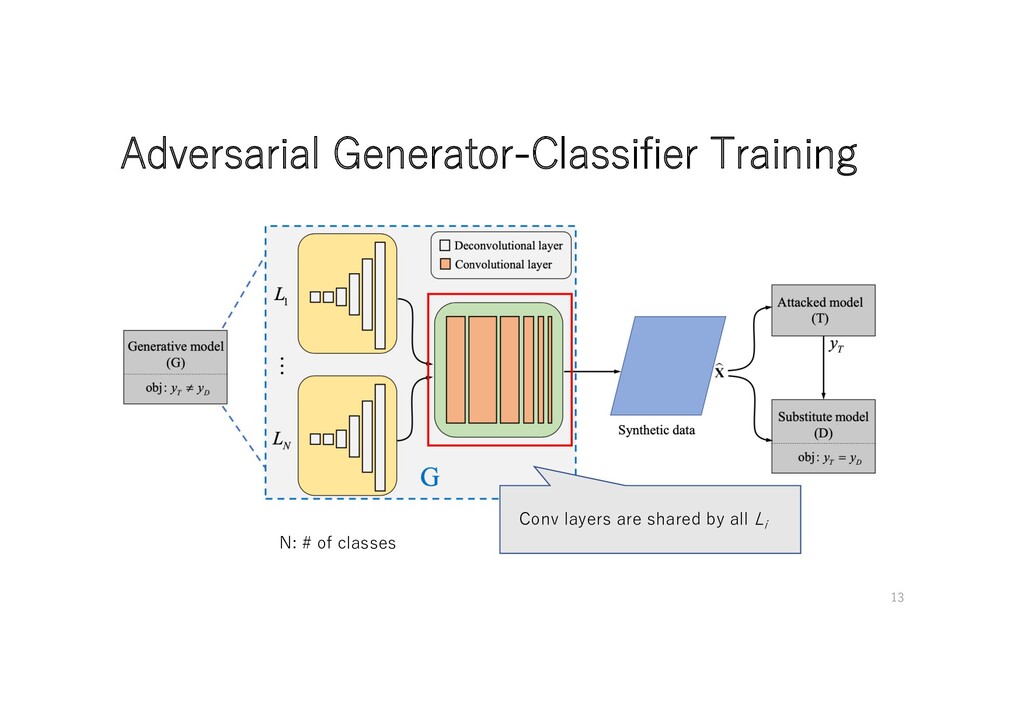
• Objective of D • Imitate attacked model(T ) • Objective of G • Generate new samples with the given label n ( ) • Generate new samples that maximizes distance between D and T ( ) (CE: cross entropy) ( is more stable on training than ) to increase diversity of generated samples 8
• Objective of D • Imitate attacked model(T ) • Objective of G • Generate new samples with the given label n ( ) • Generate new samples that maximizes distance between D and T ( ) Canʼt access T ʼs grad In training progresses, D≒T (CE: cross entropy) to increase diversity of generated samples 9
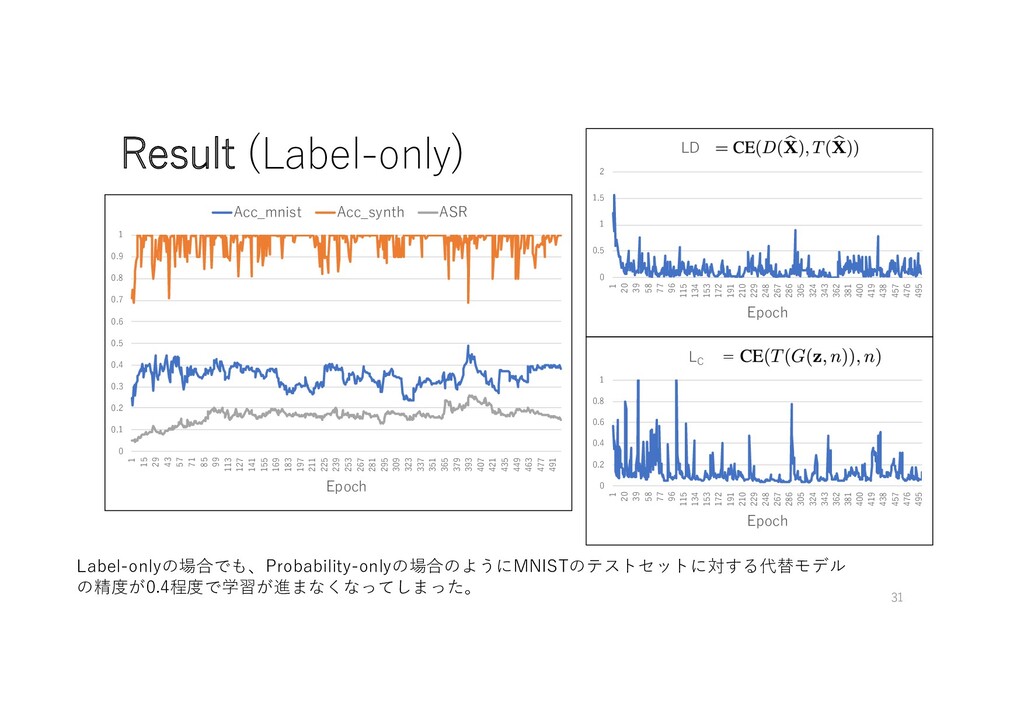
hard-label of the attacked model • Probability-only • Attackers can probe the output probability of the attacked model prob label prob prob (e.g. [0, 0, …, 0, 1, 0, …, 0]) (e.g. [0.03, 0.1, …, 0.05, 0.7, 0.01, …, 0.04]) 10
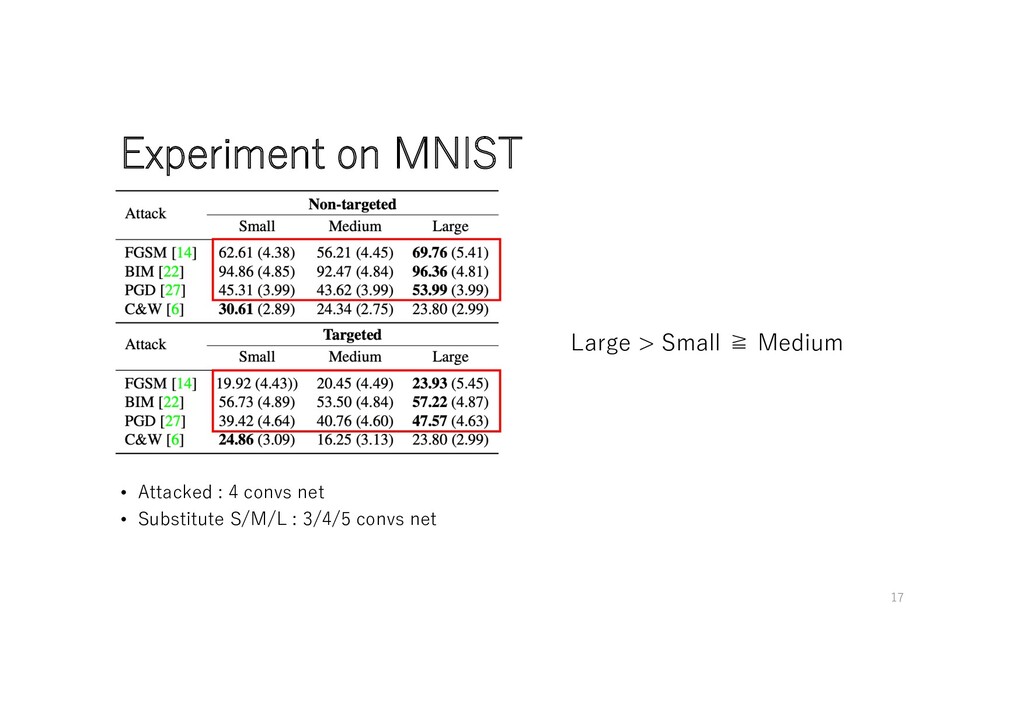
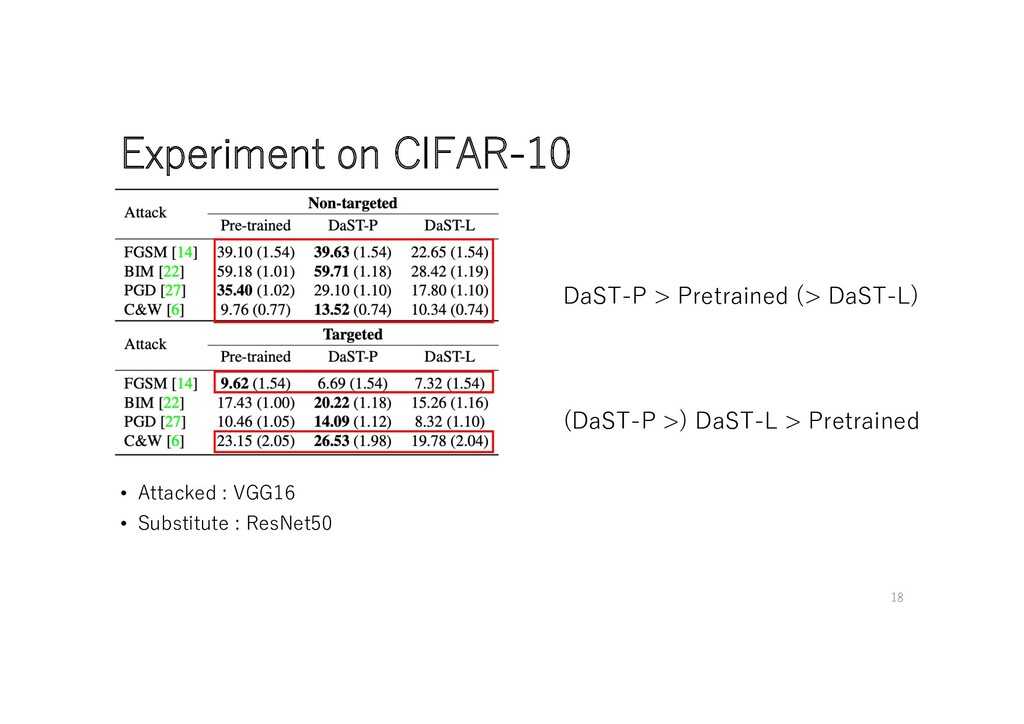
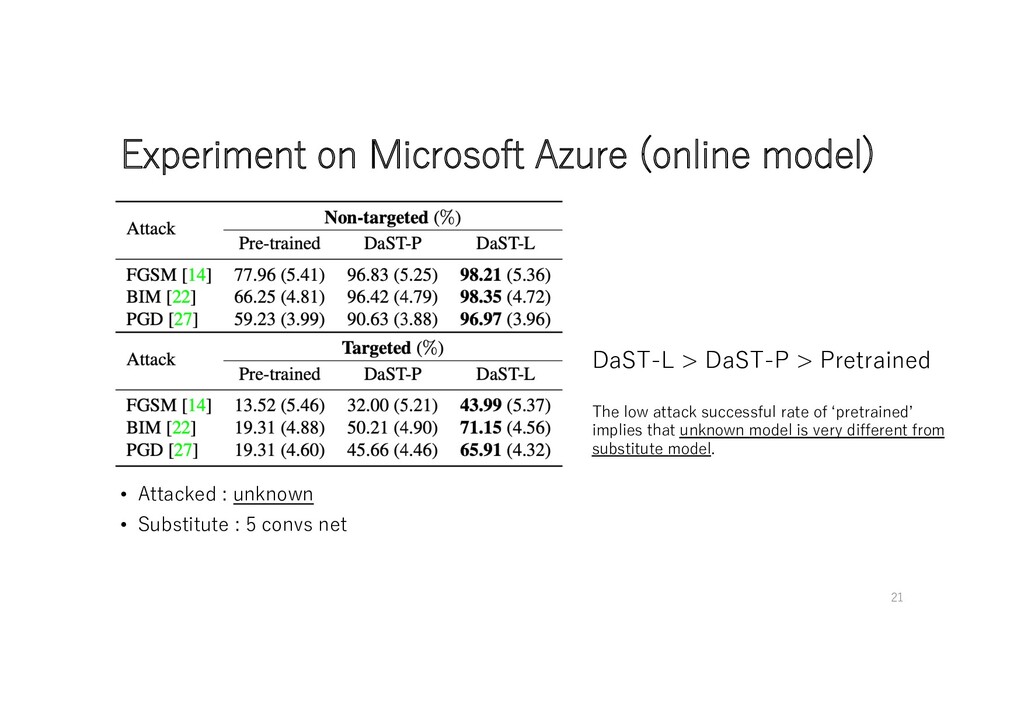
DaST-L > Pretrained • Attacked : 4 convs net • Substitute : 5 convs net 16 Surprisingly, Attack Successful Rate of DaST is higher than one of Pretrained.
Pretrained • Attacked : unknown • Substitute : 5 convs net The low attack successful rate of ʻpretrainedʼ implies that unknown model is very different from substitute model. 21
![DaST: Data-free Substitute Training for Adversarial Attack [CVPR2020] M1, Kaede](https://files.speakerdeck.com/presentations/9fa71b06483049a9af7465182881e6fe/slide_0.jpg){kind=link}
{kind=link}
{kind=link}
{kind=link}
![Traditional Adversarial Attack methods • Gradient-based (e.g. FGSM[1]) ✓Need pretrained](https://files.speakerdeck.com/presentations/9fa71b06483049a9af7465182881e6fe/slide_4.jpg){kind=link}
![Traditional Adversarial Attack methods • Gradient-based (e.g. FGSM[1]) ✓Need pretrained](https://files.speakerdeck.com/presentations/9fa71b06483049a9af7465182881e6fe/slide_5.jpg){kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}