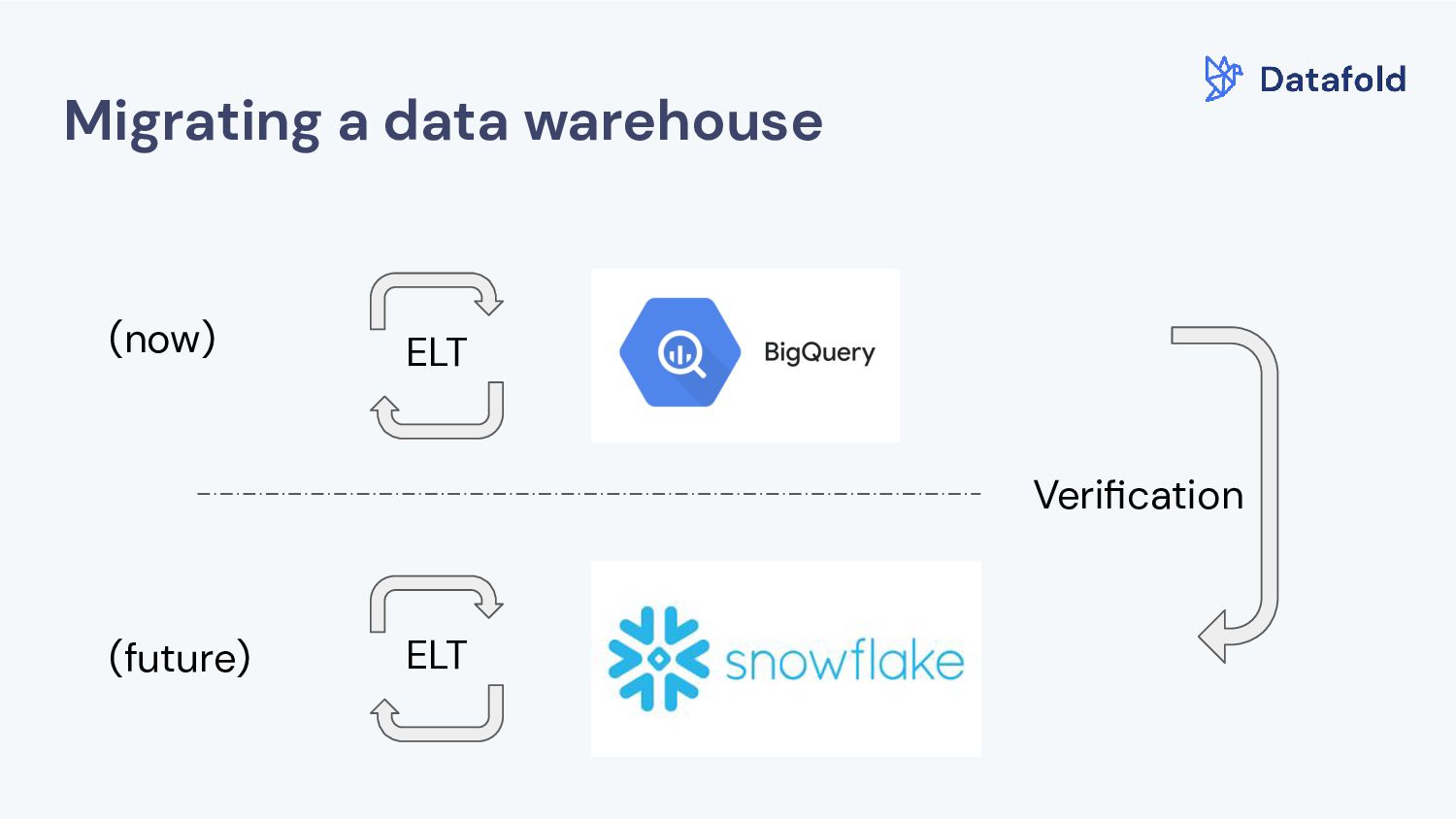
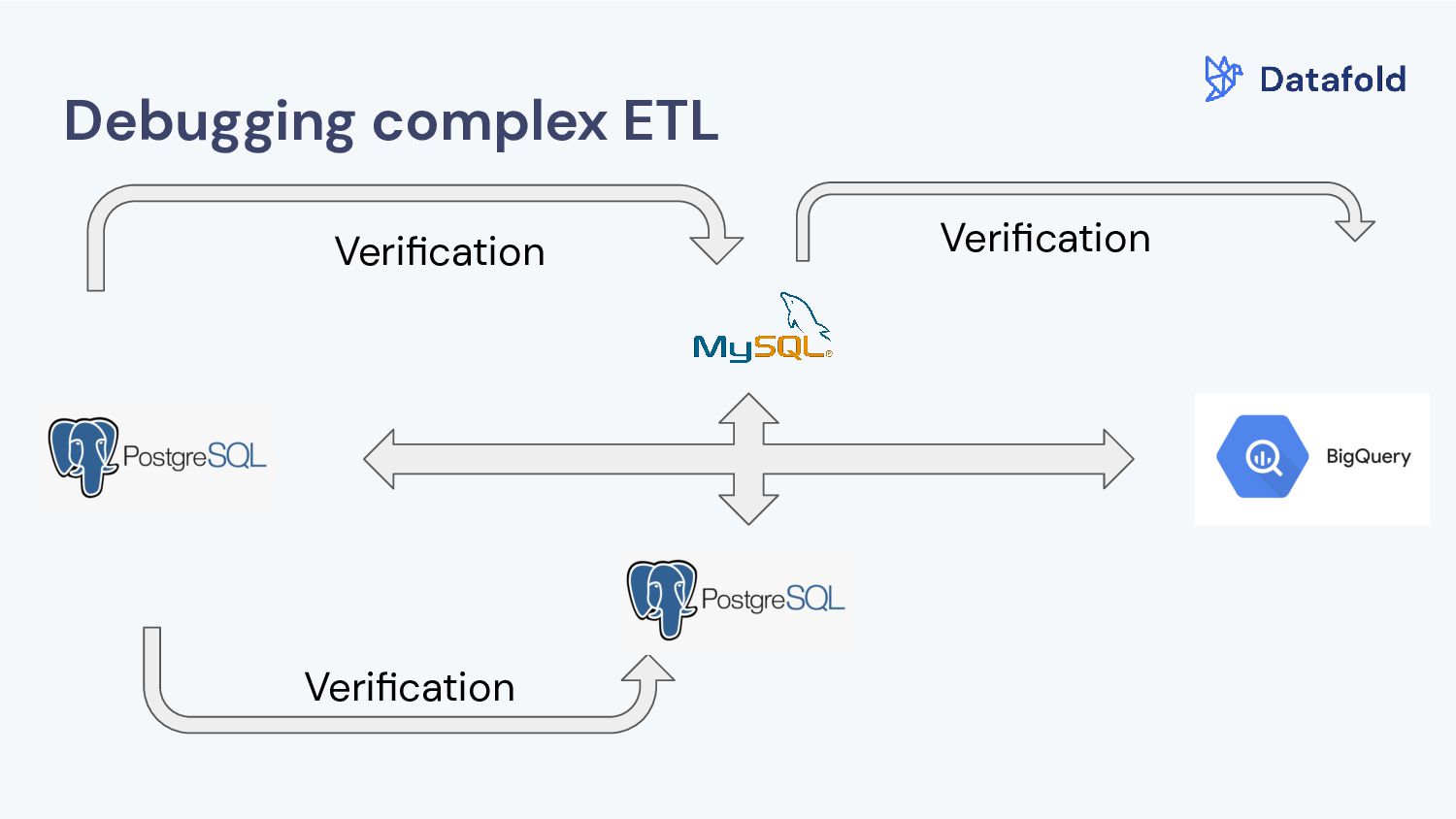
Copying data into your data warehouse through ETL tooling b. Migrating your database or warehouse to a different vendor c. Debugging complex data pipelines across multiple storage systems d. Detecting hard deletes e. Maintaining data integrity SLO’s
Takes advantage of parallelization ◦ Avoids full table scans ◦ Optimized for few differences in rows ◦ 25 million rows in ~10 seconds, 1 billion rows in ~2 minutes • Supports many data storage vendors ◦ Engine must support efficient hashing
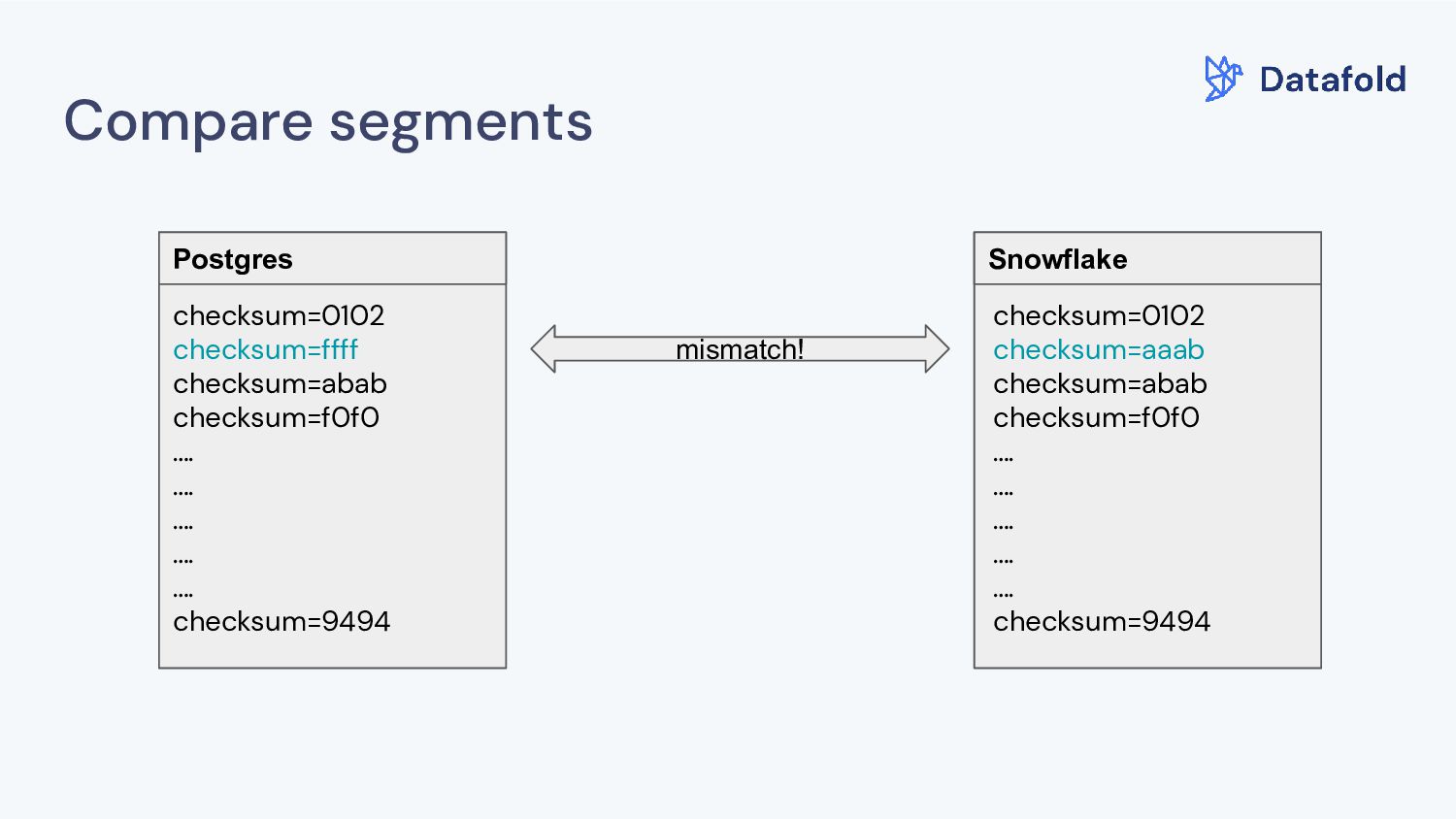
unsigned)) FROM `some_table` WHERE (id >= 1) AND (id < 100000) • Concatenate columns of interest: here id and updated_at • Calculate MD5 over each concatenation of each row • Preserve the first 18 characters of the calculated hash • Convert it from a 16-hexadecimal to 10-base decimal system • Cast the value for each row to an unsigned integer • Sum all integers of the entire segment
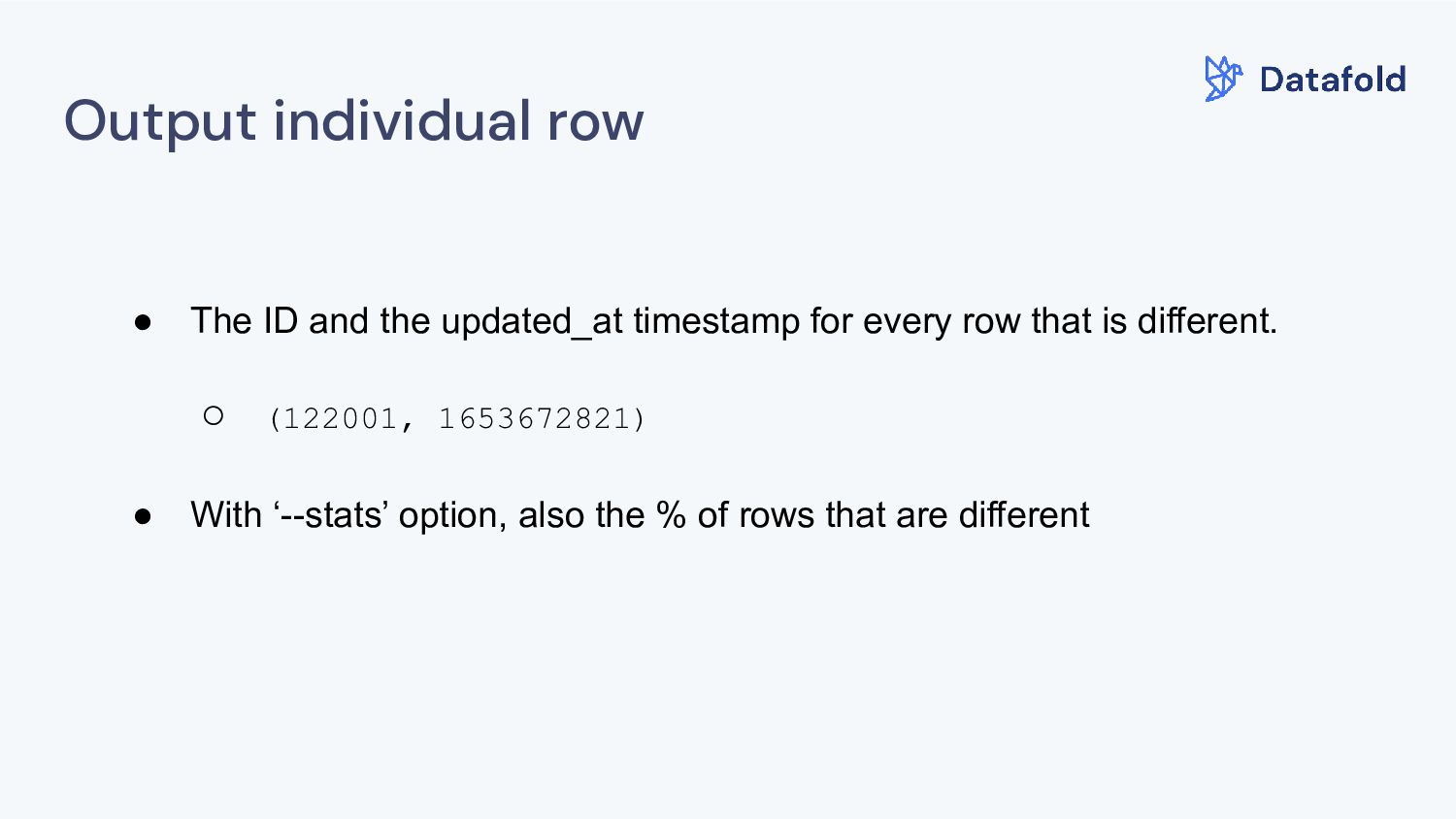
You can see the execution plan for each query • Full control over the bisection parameters • Compare rows against any set of columns you want with the “--column” parameter • Extra statistics with “--stats” • Ignore recent rows: “--min-age” and “--max-age”
it here: ◦ https://github.com/datafold/data-diff • We are in the #tools-data-diff Locally Optimistic Slack: ◦ https://locallyoptimistic.com/community/ • Open an issue: ◦ https://github.com/datafold/data-diff/issues
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
![Thank you for your attention! Gerard Toonstra: [email protected] We are](https://files.speakerdeck.com/presentations/e4d29c206f8244ea8fcc9dce1ee4ce0e/slide_21.jpg){kind=link}