Komplexní instrukční sada • Optimalizované pro rychlost provedení 1 instrukce • GPU • Hodně jednoduchá instrukční sada • Optimalizované pro provádění stovek až tisíců instrukcí paralelně
ne • Hry primárně používají “shadery” pro práci s GPU • Shadery obsahují specifické funkce pro práci s 3D grafikou • GPU má optimalizované procesory/paměti pro 3D grafiku
Lepší API • Aktivnější vývoj ze strany nVidie • NVIDIA se také podílí na vývoji OpenCL (Khronos group) ! • Lepší nástroje a ovladače • profiler, cuda-gdb, cuda-memcheck, nsight • Občas “rychlejší” ! • Statická kompilace kernelu (také “JIT”, ale s omezeními) • Může být i nevýhoda (optimalizace pro dané GPU)
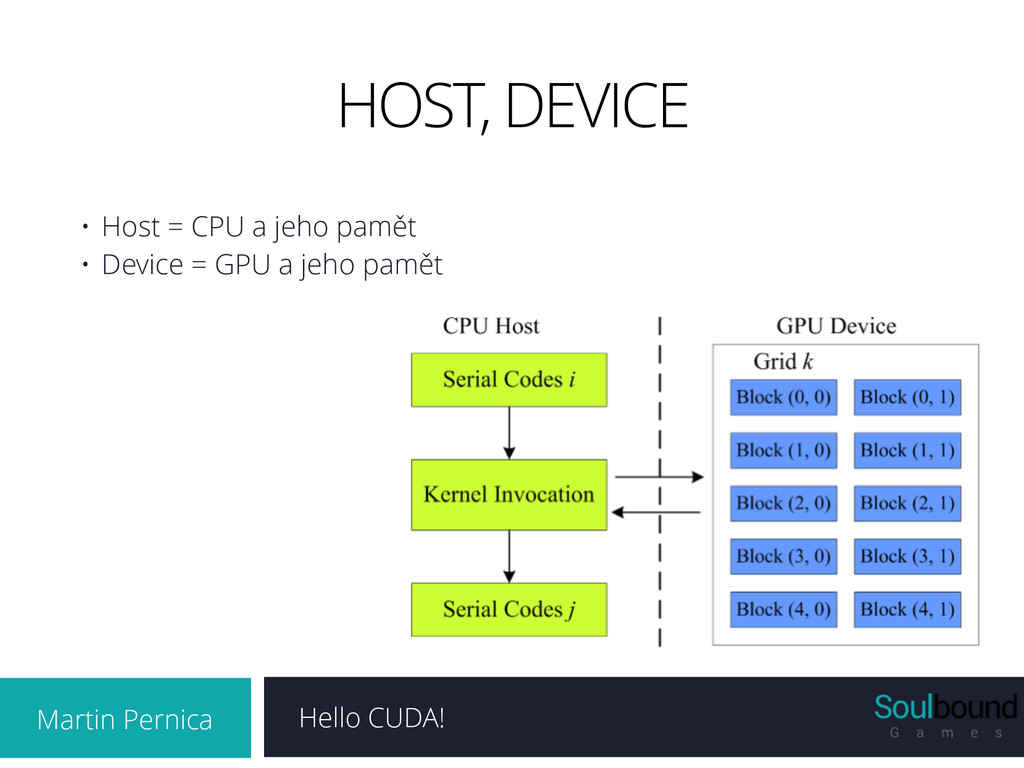
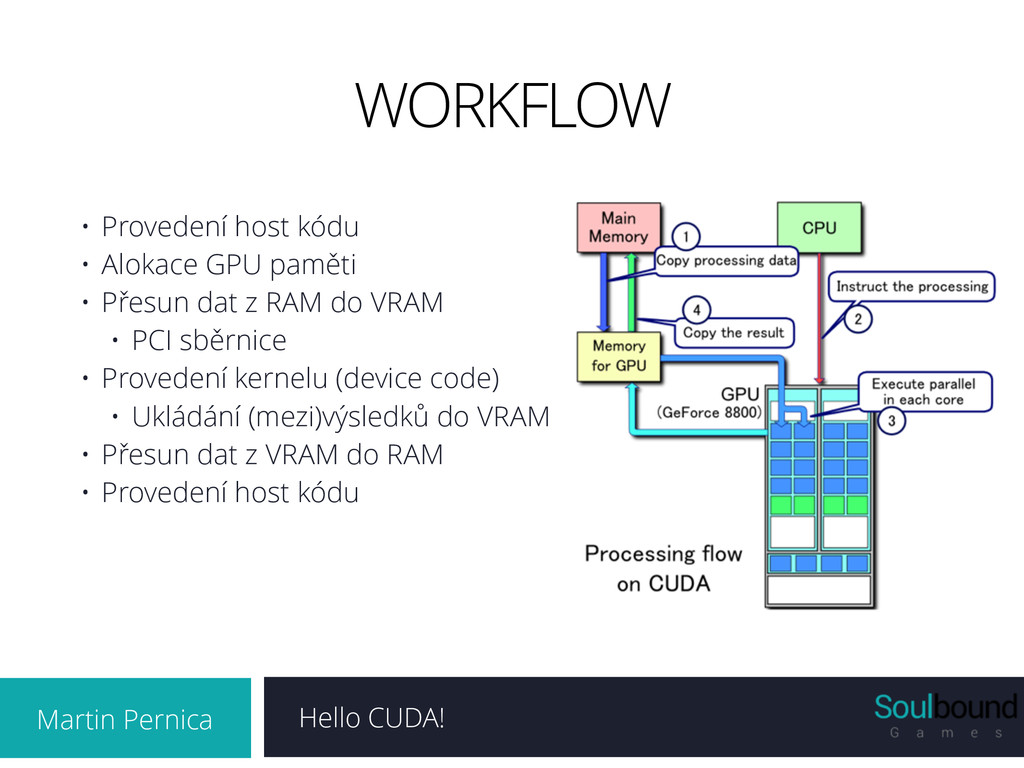
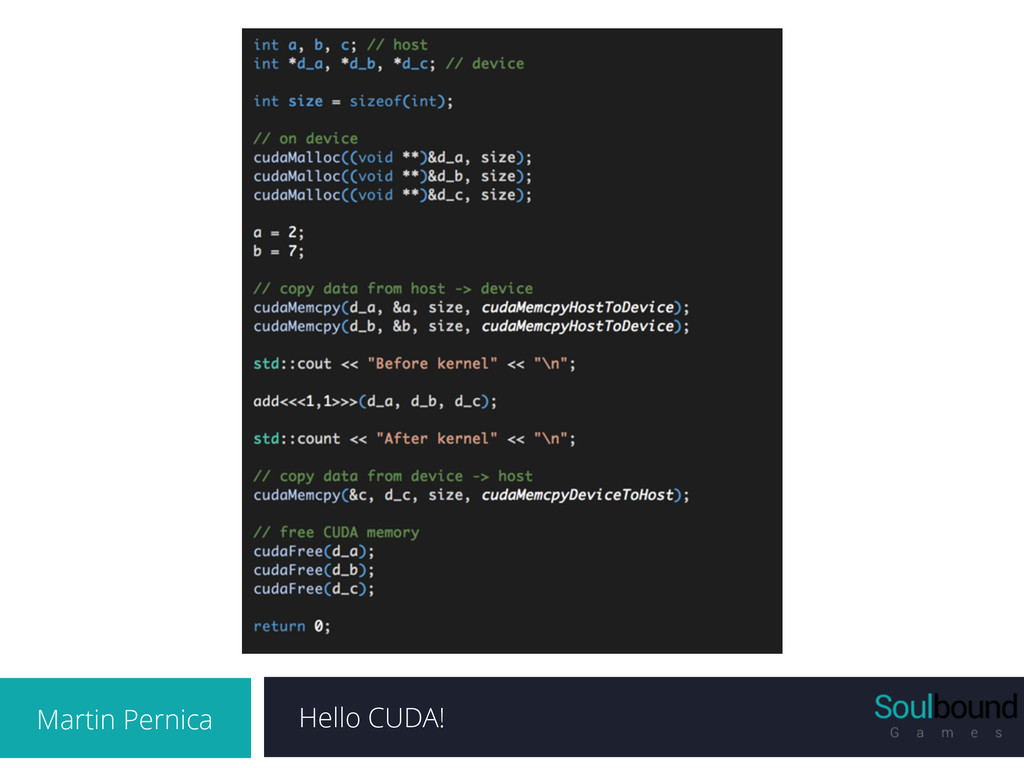
Alokace GPU paměti • Přesun dat z RAM do VRAM • PCI sběrnice • Provedení kernelu (device code) • Ukládání (mezi)výsledků do VRAM • Přesun dat z VRAM do RAM • Provedení host kódu
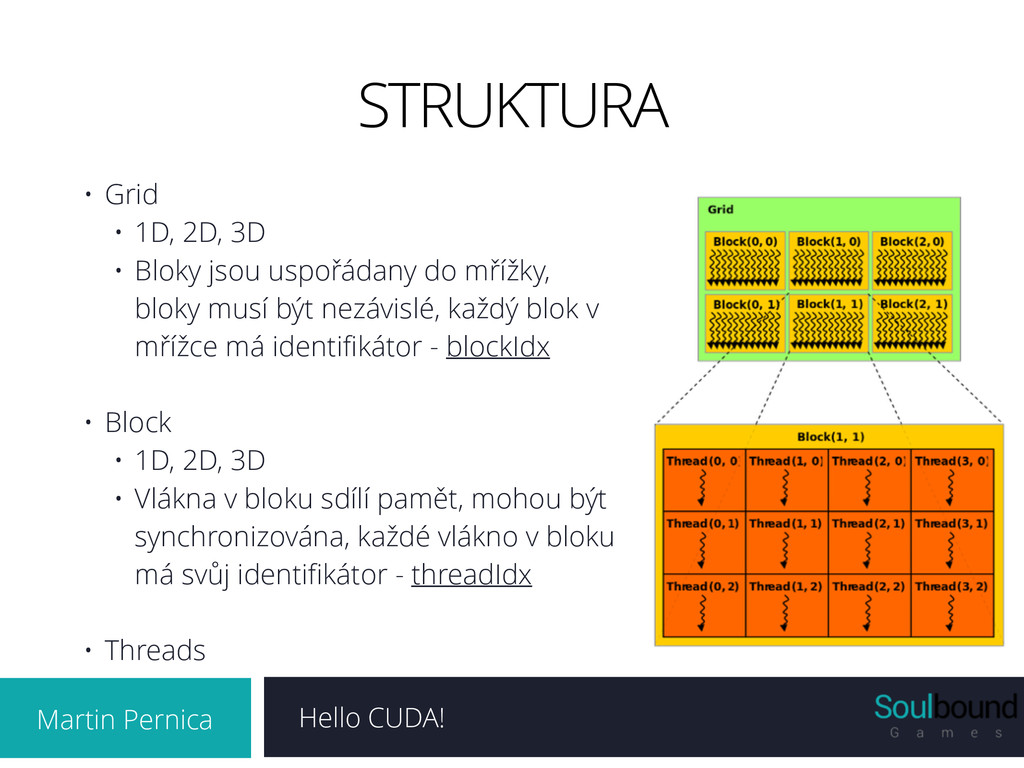
3D • Bloky jsou uspořádany do mřížky, bloky musí být nezávislé, každý blok v mřížce má identifikátor - blockIdx ! • Block • 1D, 2D, 3D • Vlákna v bloku sdílí pamět, mohou být synchronizována, každé vlákno v bloku má svůj identifikátor - threadIdx ! • Threads
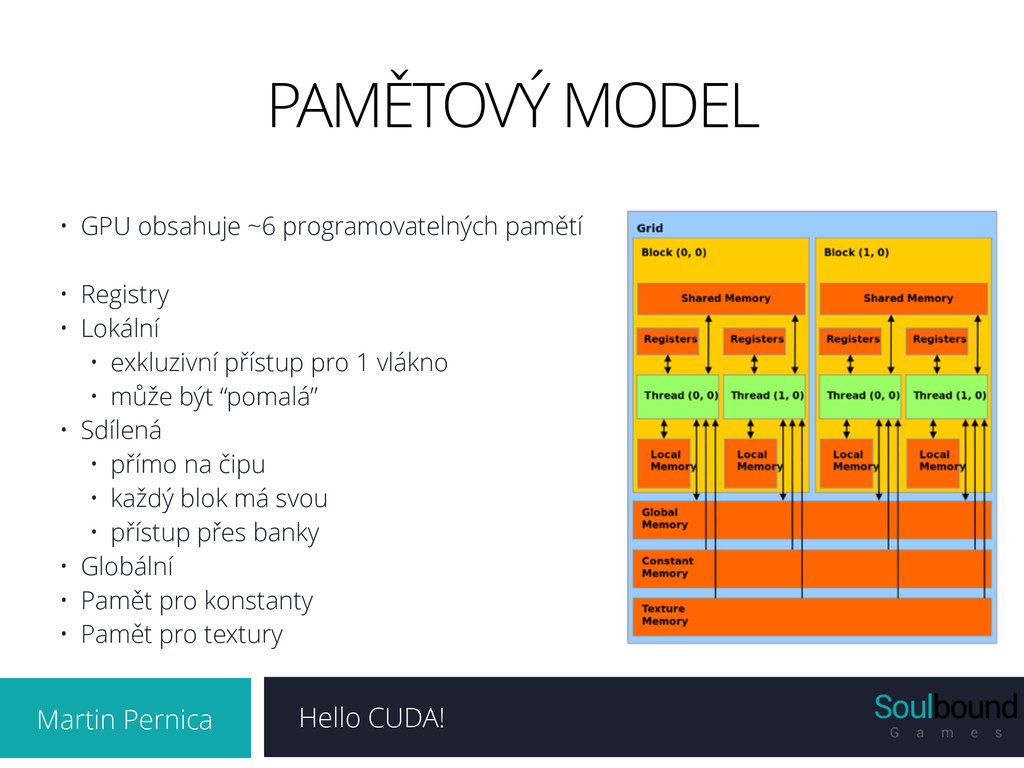
programovatelných pamětí ! • Registry • Lokální • exkluzivní přístup pro 1 vlákno • může být “pomalá” • Sdílená • přímo na čipu • každý blok má svou • přístup přes banky • Globální • Pamět pro konstanty • Pamět pro textury
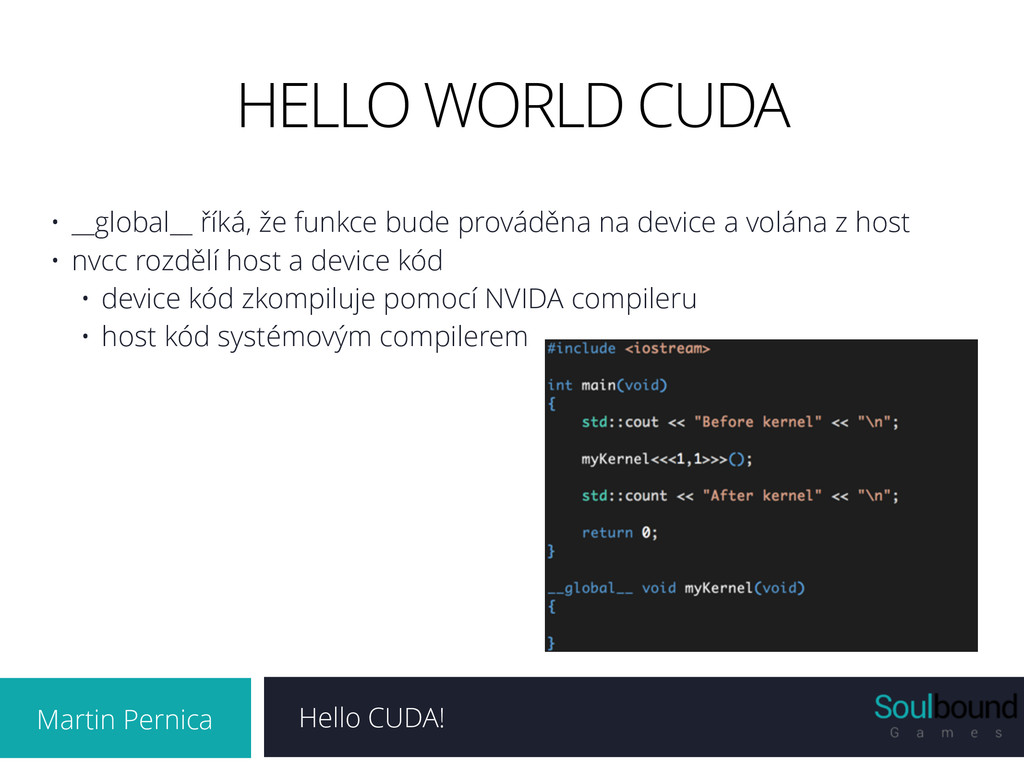
že funkce bude prováděna na device a volána z host • nvcc rozdělí host a device kód • device kód zkompiluje pomocí NVIDA compileru • host kód systémovým compilerem
asynchronně ! • To znamená, že CPU nečeká na dokončení kernelu! • cudaMemcpy() blokuje, cudaMemcpyAsync() neblokuje CPU ! • Můžeme také synchronizovat pomocí cudaDeviceSynchronize() či cudaStreamSynchronize()
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
![OTÁZKY? Hello CUDA! Martin Pernica [email protected] | @martindeveloper](https://files.speakerdeck.com/presentations/eb171f00b54b0131871e5671d5dbfd15/slide_27.jpg){kind=link}
{kind=link}
{kind=link}
![DĚKUJI ZA POZORNOST! Hello CUDA! Martin Pernica [email protected] | @martindeveloper](https://files.speakerdeck.com/presentations/eb171f00b54b0131871e5671d5dbfd15/slide_30.jpg){kind=link}