Upgrade to Pro
— share decks privately, control downloads, hide ads and more …
Speaker Deck
Features
Speaker Deck
PRO
Sign in
Sign up for free
Search
Search
転置ファイルを用いた全文検索について
Search
masaya82
February 27, 2018
850
0
Share
Embed
Copy iframe code
Copy JS code
Copy link
Start on current slide
転置ファイルを用いた全文検索について
masaya82
February 27, 2018
More Decks by masaya82
See All by masaya82
文献紹介 : More is not always better: balancing sense distributions for all-words
masaya82
0
170
文献紹介:Enhancing Modern Supervised Word Sense Disambiguation Models
masaya82
0
180
文献紹介:The Word Sense Disambiguation Test Suite at WMT18
masaya82
0
120
文献紹介:Preposition Sense Disambiguation and Representation
masaya82
0
150
文献紹介:Word Sense Disambiguation Based on Word Similarity Calculation Using Word Vector Representation from a Knowledge-based Graph
masaya82
0
170
Distributional Lesk: Effective Knowledge-Based Word Sense Disambiguation
masaya82
0
130
Japanese all-words WSD system using the Kyoto Text Analysis ToolKit
masaya82
0
150
Improving Word Sense Disambiguation in Neural Machine Translation with Sense Embeddings
masaya82
0
160
Learning_to_Identify_the_Best_Contexts_for_Knowledge-based_WSD
masaya82
0
150
Featured
See All Featured
Sharpening the Axe: The Primacy of Toolmaking
bcantrill
46
2.9k
The #1 spot is gone: here's how to win anyway
tamaranovitovic
3
1.1k
Data-driven link building: lessons from a $708K investment (BrightonSEO talk)
szymonslowik
1
1.2k
世界の人気アプリ100個を分析して見えたペイウォール設計の心得
akihiro_kokubo
PRO
72
40k
Leo the Paperboy
mayatellez
8
1.9k
Practical Tips for Bootstrapping Information Extraction Pipelines
honnibal
25
2k
Building the Perfect Custom Keyboard
takai
2
820
Conquering PDFs: document understanding beyond plain text
inesmontani
PRO
4
2.9k
GraphQLの誤解/rethinking-graphql
sonatard
75
12k
GitHub's CSS Performance
jonrohan
1033
470k
Everyday Curiosity
cassininazir
0
260
Hiding What from Whom? A Critical Review of the History of Programming languages for Music
tomoyanonymous
3
1k
Transcript
転置ファイルを用いた 全文検索について 自然言語処理研究室 福嶋 真也
参考文献 北 研二、津田 和彦、獅々堀 正幹 著 「情報検索アルゴリズム」 2002年 共立出版株式会社 P160-179
1
転置ファイル法 転置インデックス法とも呼ばれる 転置ファイルを作成し、検索時に転置ファイルに アクセスすることで検索を行う手法 転置ファイルとは →ある索引語に対し、それが出現する文書情報を表構造に まとめた索引 例:ある索引語 に対して :
1 , 3 , … :文書 2
転置ファイル法 転置ファイルには他の形式も存在 ・文書番号の並びをビット列形式で表現する文書番号ベクトル(bitmap)を 用いて索引語が文書に入っているかどうかを表現 例:ある索引語 に対して : 1 2 3
… :ビット値(0 or 1) :文書数 ・索引語の出現する文書に加えて、出現位置も格納 例:ある索引語 に対して : (1 ;11 , … , 11 ), (3 ;21 , … , 22 ), … ( ;1 , … , ) :文書 :出現位置 3
転置ファイルの構成法 ・英語など単語間に明確な区切りが存在する言語について 1. 文書集合から文書を取り出す 2. 文書を先頭から見ていき、単語を取り出してそれが索引語 なら文書と位置情報を転置ファイル内に追加し、次の単語 に対して2の操作を行う それ以外なら次の単語に対して2の操作を行う 文書集合が空集合となるまで1,2の操作を繰り返し、その後、
索引語が昇順に並ぶように並べ替えを行う 4
転置ファイルの構成法 文書番号ベクトルを用いる方法 例:以下の文書に対し転置ファイルを作成 5 行番号 索引語 文書 文書番号ベクトル 1 algorithm
3, 4, 5 0 0 1 1 1 2 file 2 0 1 0 0 0 3 full 1 1 0 0 0 0 4 index 2, 4 0 1 0 1 0 5 information 5 0 0 0 0 1 6 inverted 2 0 1 0 0 0 7 retrieval 5 0 0 0 0 1 8 search 1, 3, 4 1 0 1 1 0 9 sequential 3 0 0 1 0 0 10 text 1 1 0 0 0 0 1=full text search 2=inverted index file 3=sequential search algorithm 4=index search algorithm 5=information retrieval algorithm ※文書の位置は先頭を0とし、 空白も1文字とカウントする
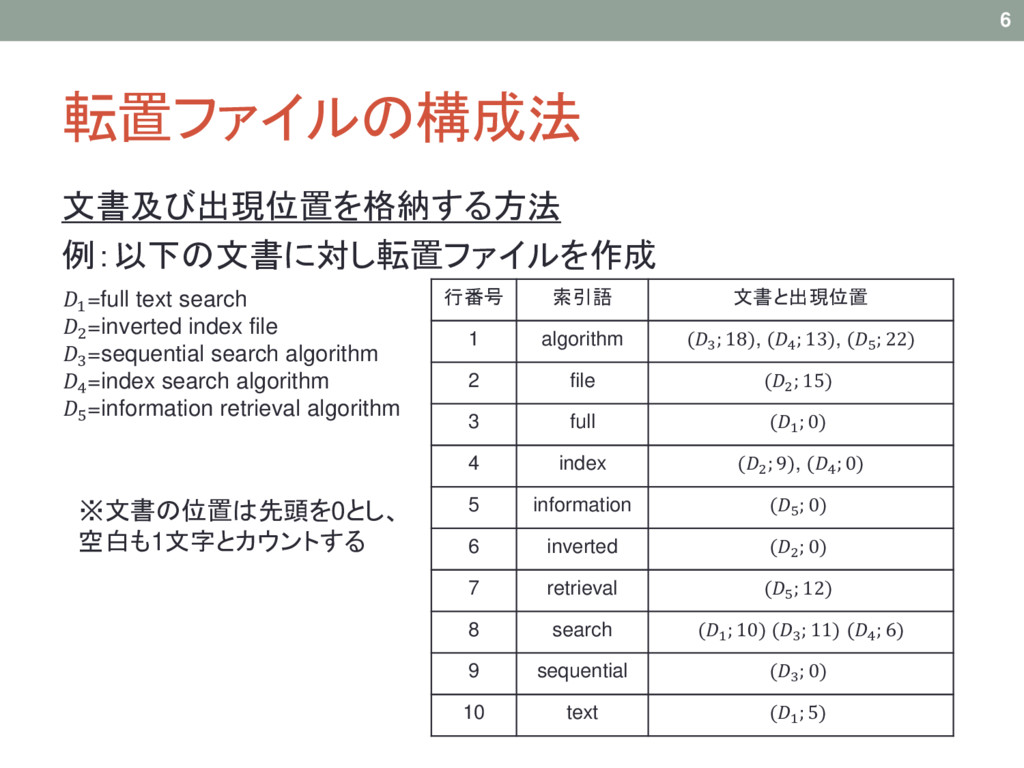
転置ファイルの構成法 文書及び出現位置を格納する方法 例:以下の文書に対し転置ファイルを作成 6 行番号 索引語 文書と出現位置 1 algorithm (3
; 18), (4 ; 13), (5 ; 22) 2 file (2 ; 15) 3 full (1 ; 0) 4 index (2 ; 9), (4 ; 0) 5 information (5 ; 0) 6 inverted (2 ; 0) 7 retrieval (5 ; 12) 8 search (1 ; 10) (3 ; 11) (4 ; 6) 9 sequential (3 ; 0) 10 text (1 ; 5) 1=full text search 2=inverted index file 3=sequential search algorithm 4=index search algorithm 5=information retrieval algorithm ※文書の位置は先頭を0とし、 空白も1文字とカウントする
転置ファイルの構成法 ・日本語など単語間に明確な区切りが存在しない言語について 区切りがないため新たな処理が必要 大きく分けて2つの手法が存在 (1)形態素解析を行い、単語間の区切りを特定してから 索引語について転置ファイルを作成 (2)文書から直接転置ファイルを作成 (1)については形態素解析以降に英語と同様にして 転置ファイルを作成 (2)については別の手法を用いて索引を作成
7
転置ファイルの構成法 Nグラム索引 あらかじめ文字数を指定し、その文字数単位で索引語を 作成して索引を形成する 例:「にわにはにわにわとりがいる」(ユニグラム索引) 8 行番号 索引語 出現位置 1
い 22 2 が 20 3 と 16 4 に 0,4,8,12 5 は 6 6 り 18 7 る 24 8 わ 2,10,14 日本語は1文字に つき2バイト
転置ファイルによる検索法 基本的に検索単語を元に転置ファイルから検索単語が 存在する文書や位置情報などを取得する 例:「algorithm」を検索単語としたとき 右の表より文書3、4、5が検索結果として 表示される 検索単語が複数のときは転置ファイルの 形式によって方法が変化 9 行番号
索引語 文書 1 algorithm 3, 4, 5 2 file 2 3 full 1 4 index 2, 4 5 information 5 6 inverted 2 7 retrieval 5 8 search 1, 3, 4 9 sequential 3 10 text 1
転置ファイルによる検索法 文書番号ベクトルを用いた方法の場合 文書番号ベクトルに対し、ビットごとにAND検索なら論理積、 OR検索なら論理和、NOT検索なら論理否定を求める 例:クエリを「search AND algorithm」としたとき 論理積は 0 0
1 1 0 →文書3、4が検索結果となる 10 行番号 索引語 文書 文書番号ベクトル 1 algorithm 3, 4, 5 0 0 1 1 1 2 file 2 0 1 0 0 0 3 full 1 1 0 0 0 0 4 index 2, 4 0 1 0 1 0 5 information 5 0 0 0 0 1 6 inverted 2 0 1 0 0 0 7 retrieval 5 0 0 0 0 1 8 search 1, 3, 4 1 0 1 1 0 9 sequential 3 0 0 1 0 0 10 text 1 1 0 0 0 0
転置ファイルによる検索法 索引語の出現する文書と出現位置を格納する方法の場合 検索単語が文書に存在するかどうかに加えて出現する順序も 指定可能 →複合語についても検索可能 例:クエリを「search AND algorithm」としたとき 右の表より文書3、4が該当 さらに出現位置を見ると
searchの出現位置からsearchの文字数(6文字)+1(空白) =7バイト後にalgorithmが存在 →「search algorithm」という複合語となっている 11 索引語 文書と出現位置 algorithm (3 ; 18), (4 ; 13), (5 ; 22) search (1 ; 10) (3 ; 11) (4 ; 6)
転置ファイルによる検索法 Nグラム索引を用いた方法(日本語など) (ユニグラム索引) 例:クエリを「にわとり」としたとき 転置ファイルから「に」、「わ」、「と」、「り」の情報をそれぞれ 取得する 位置情報の少ない順に並べなおす ここでは「と」、「り」、「わ」、「に」の順に 並べたとする 12
索引語 出現位置 に 0,4,8,12 わ 2,10,14 と 16 り 18
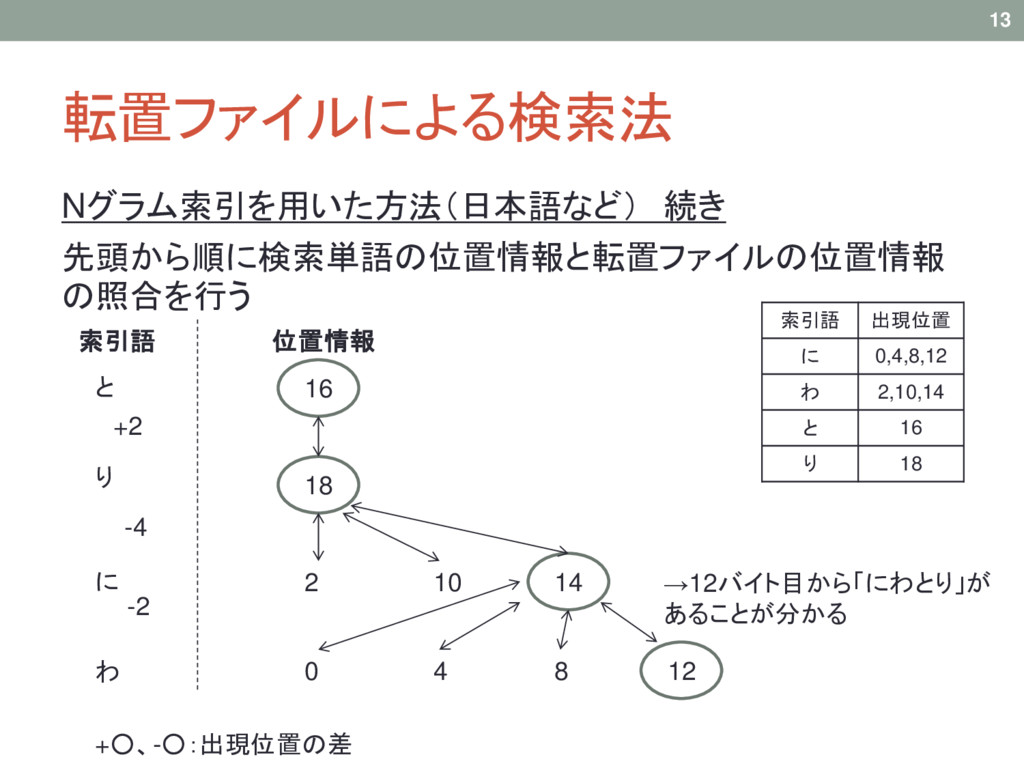
転置ファイルによる検索法 Nグラム索引を用いた方法(日本語など) 続き 先頭から順に検索単語の位置情報と転置ファイルの位置情報 の照合を行う 13 索引語 出現位置 に 0,4,8,12
わ 2,10,14 と 16 り 18 16 18 2 10 14 0 4 8 12 と り に わ 索引語 位置情報 →12バイト目から「にわとり」が あることが分かる +2 -4 -2 +◦、-◦:出現位置の差
転置ファイルによる検索法 N≧2のときでも同じように検索可能 Nグラム索引を用いた方法(日本語など) (バイグラム索引) 例:クエリを「にわとり」としたとき 「とり」、「にわ」の順に並び替えて照合 →3回の照合で終了 (ユニグラムでは8回) 14 索引語
出現位置 にわ 0,8,12 とり 16 「にわにはにわにわとりがいる」
転置ファイルによる検索法 照合回数が減るならNは増やしたほうがいい? →× Nが大きいと… 位置情報量、照合回数は減少、しかしパターン数増加 Nが小さいと… パターン数は減少、位置情報量、照合回数は増加 N=2、3(ユニグラム索引、トライグラム索引)がよく用いられる 15
転置ファイルによる検索法 Nを統一せず、文字の種類ごとに変化させる方法も存在 →複合型Nグラム索引 漢字列およびひらがな列→バイグラム索引 カタカナ列→トライグラム索引もしくはまとめて1つの索引 例:文書が「情報検索アルゴリズム」のとき 16 行番号 索引語 出現位置
1 情報 0 2 報検 2 3 検索 4 4 索 6 5 アルゴリズム 8
今回の発表内容 ・転置ファイル法 ・転置ファイルの構成法 ・転置ファイルによる検索 17
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}