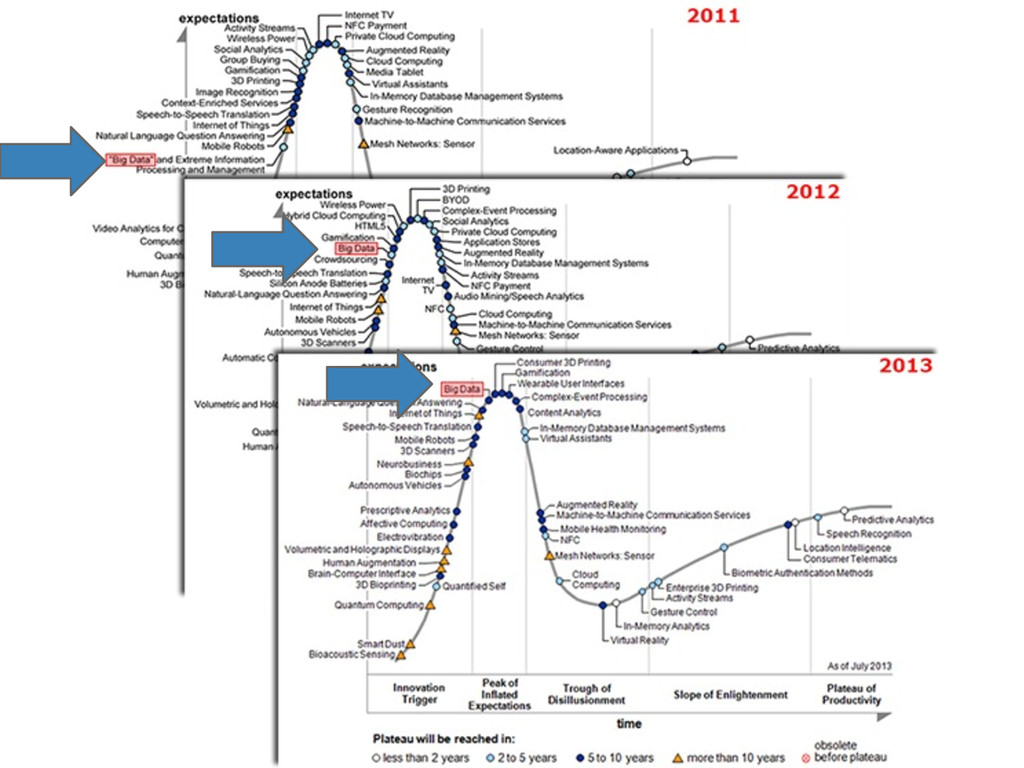
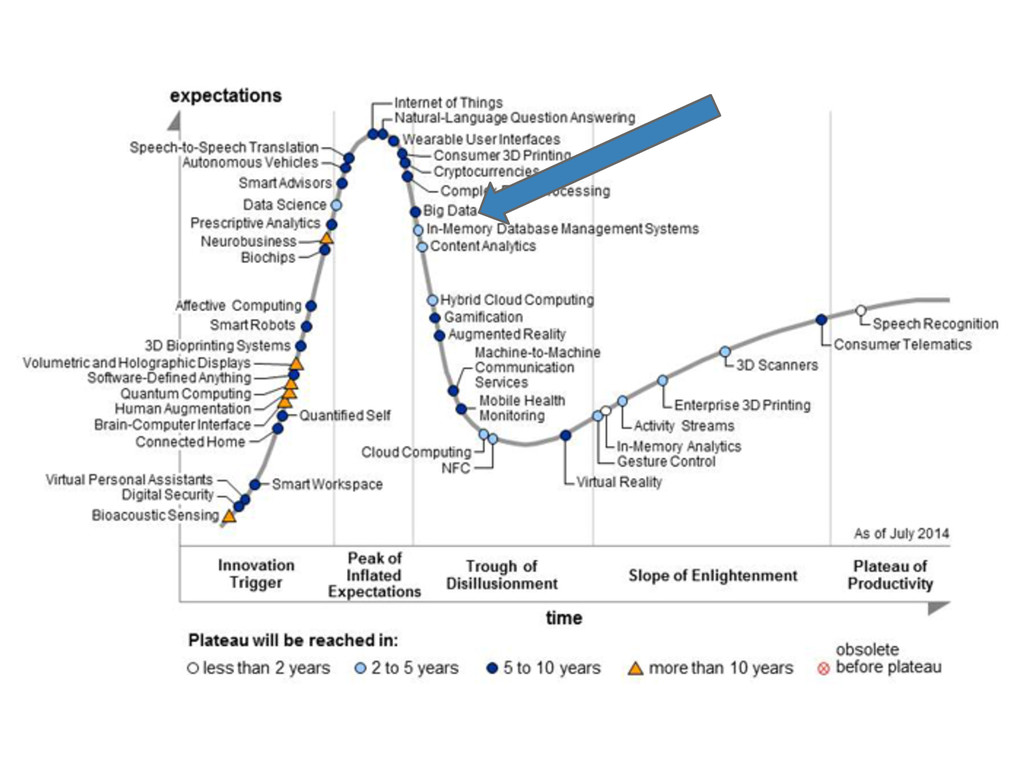
that India and South Korea are rated with the highest interest, with the USA a distant third. So, all of the Big Data vendors should now focus on India and South Korea, and leave my email inbox clean Steve Hamby, CTO Orbis Technologies http://www.huffingtonpost.com/steve-hamby/the-big-data-nemesis-simp_b_1940169.html
Big data is already well along on the so-called Plateau of Productivity as its countless success stories already prove. …Today, it is those big data skeptics that we should not take too seriously. Irfan Khan, Vice President and Chief Technology Officer for Sybase http://www.itworld.com/it-managementstrategy/293397/gartner-dead-wrong-about-big-data-hype-cycle
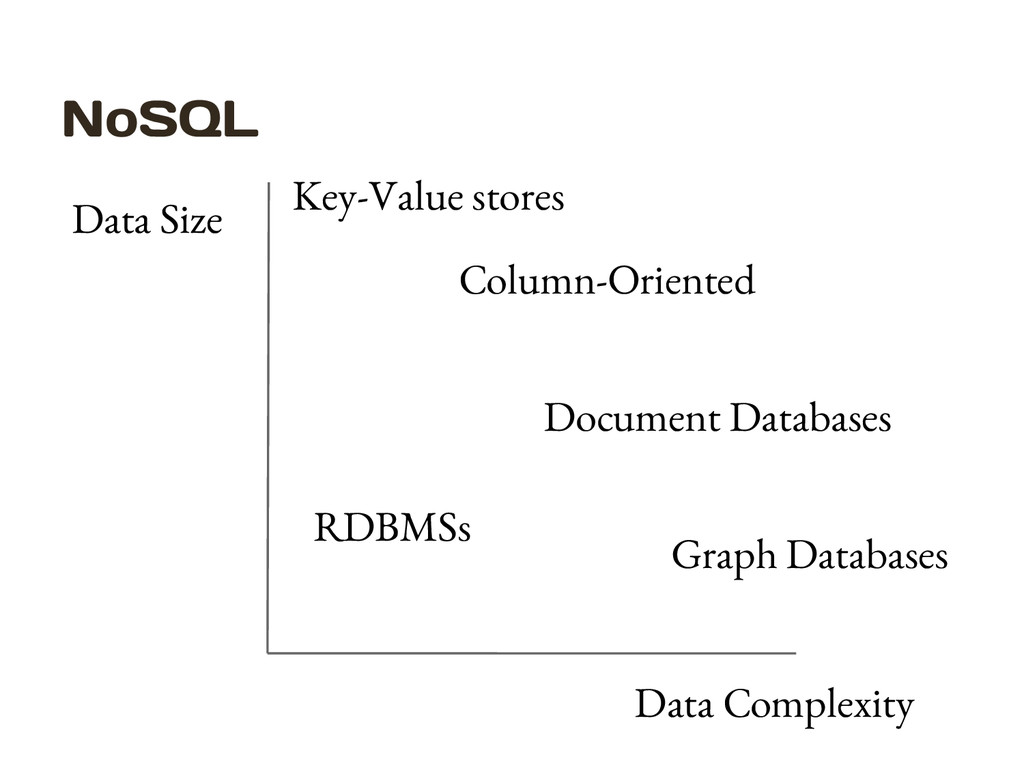
for any collection of data sets so large and complex that it becomes difficult to process using on-hand data management tools or traditional data processing applications. http://en.wikipedia.org/wiki/Big_data
diversity, and complexity require new architecture, techniques, algorithms, and analytics to manage it and extract value and hidden knowledge from it… No single standard definition
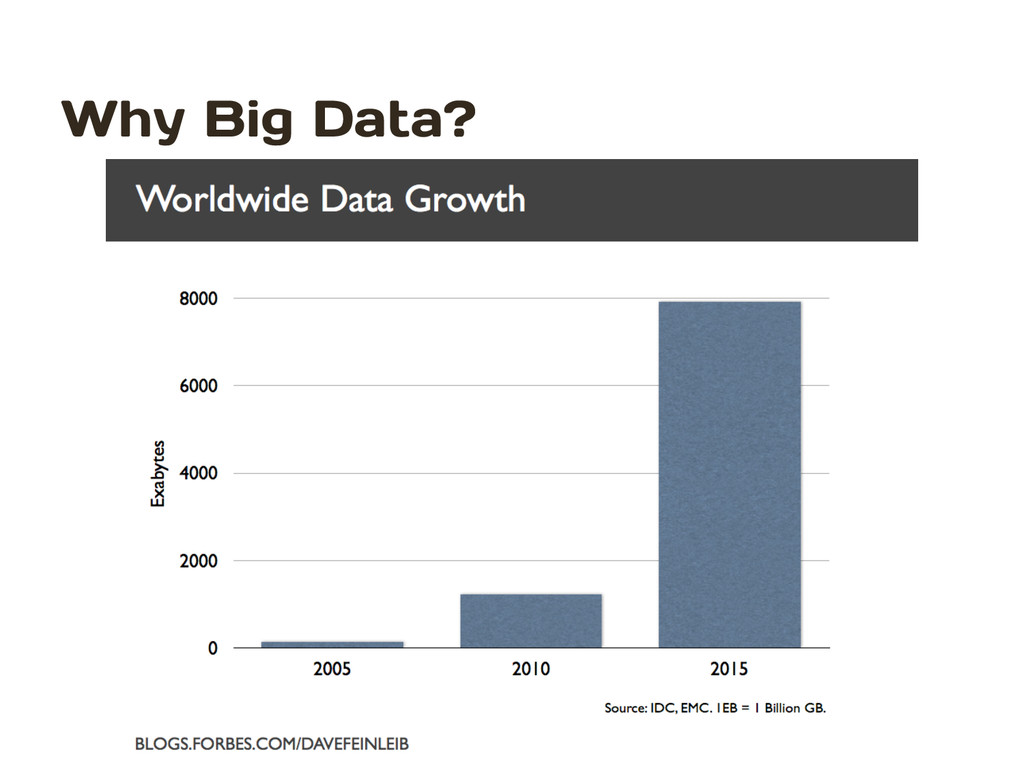
humankind generated five exabyte of data. Now we produce five exabyte every two days… and the pace is accelerating. Eric Schmidt Executive Chairman, Google
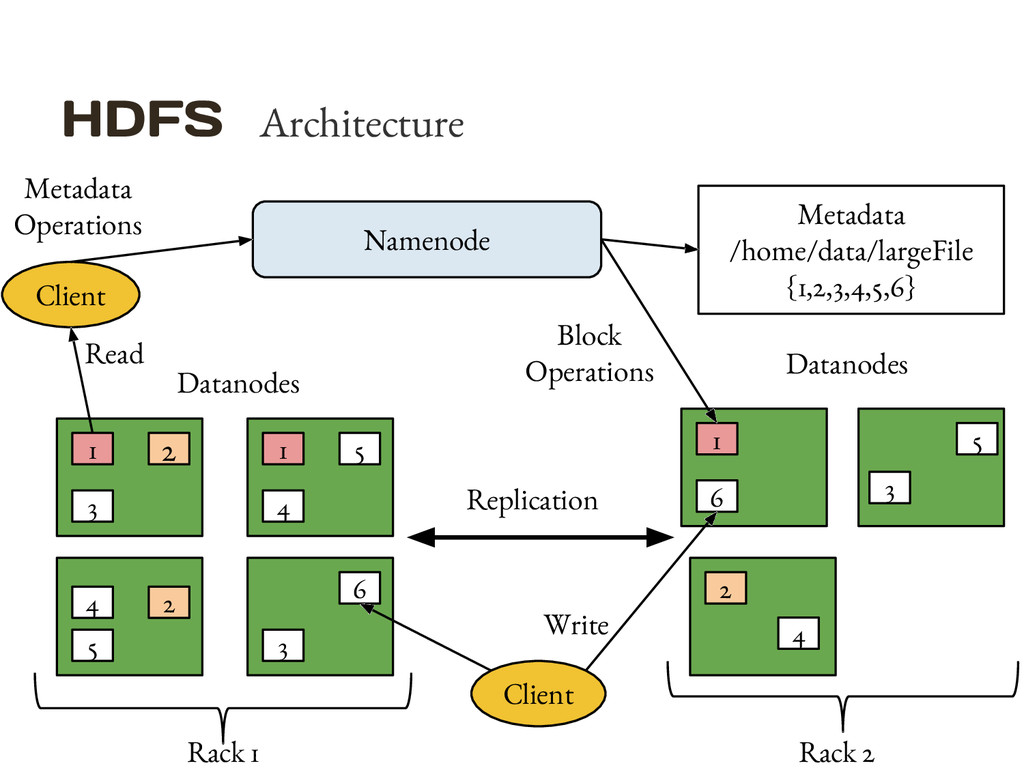
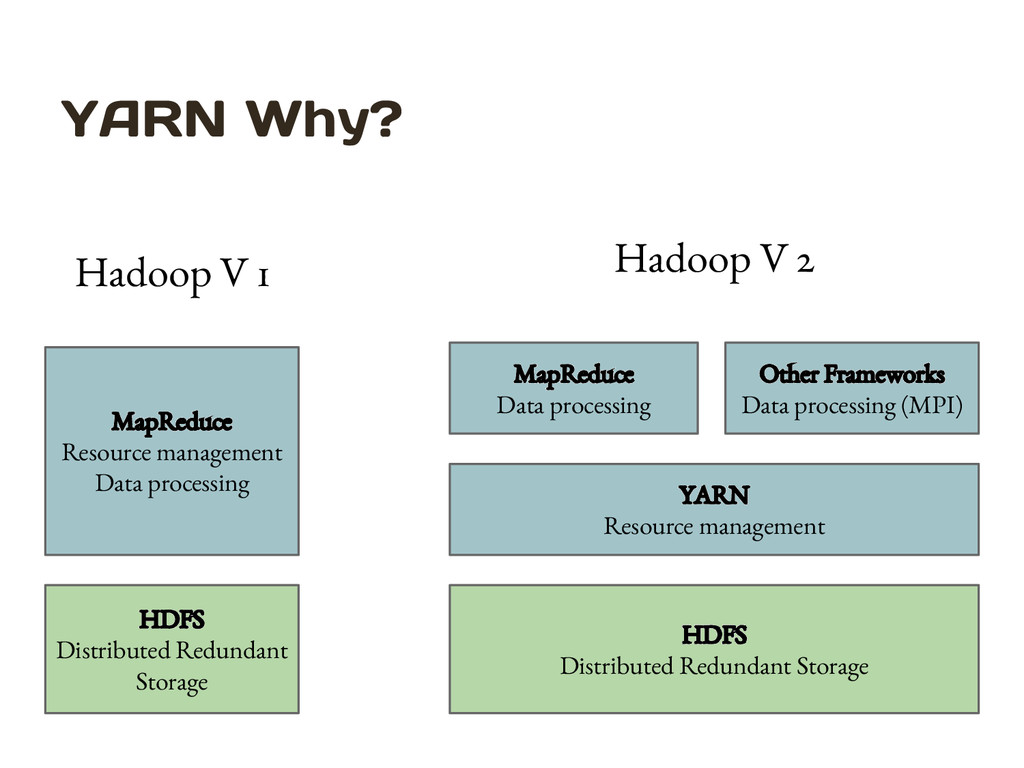
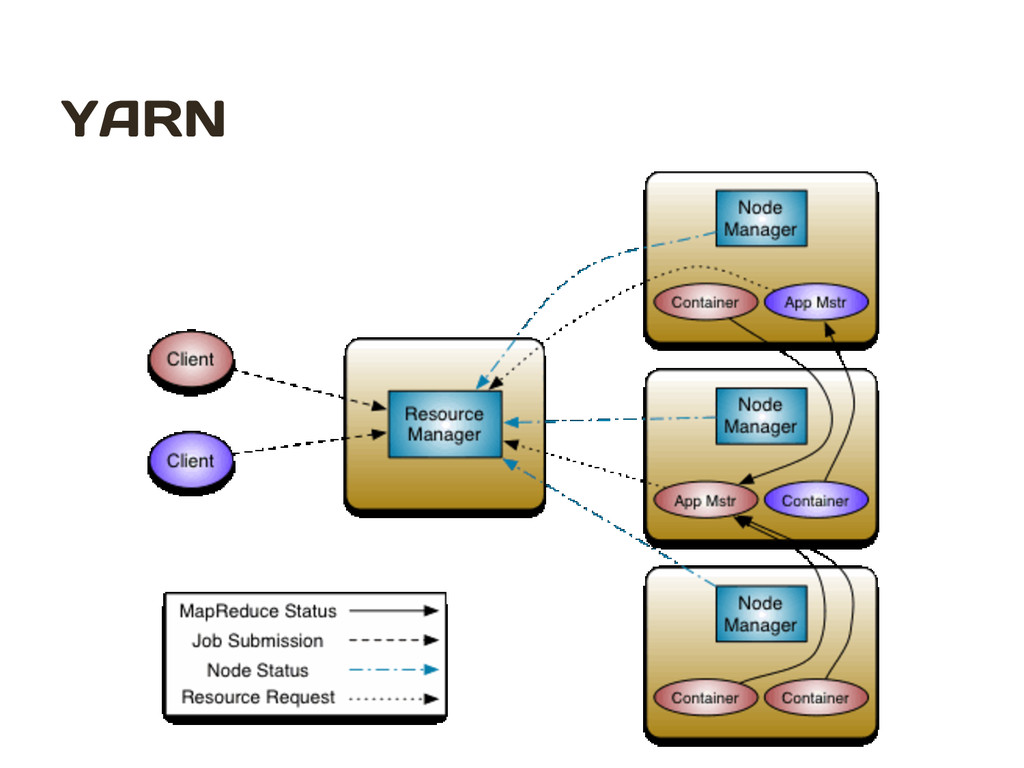
processing HDFS Distributed Redundant Storage YARN Resource management MapReduce Data processing Other Frameworks Data processing (MPI) Hadoop V 1 Hadoop V 2
the data using a SQL-like language called HiveQL Built-in user defined functions (UDFs) Custom mappers and reducers Different storage types HDFS or HBase
as hour_view, sum(page_views) as counter FROM page_view_wiki_parquet WHERE lang = 'it' GROUP BY lang, datetime ) it_views GROUP BY hour_view ORDER BY hour_view ASC
in the pipeline paradigm while SQL is instead declarative. Pig Latin script describes a directed acyclic graph (DAG) Is able to store data at any point during a pipeline
AS (filename:chararray, lang:chararray, page_name:chararray, view_count: long, page_size:long); B = FOREACH A { date = REGEX_EXTRACT(filename, '.*?pagecounts-([0-9]*-[0-9]*)', 1); date_object = ToDate(date,'yyyyMMdd-HHmmss','+00:00'); unixtime = ToUnixTime(date_object); GENERATE (long)unixtime AS datetime, lang, page_name, view_count, page_size; } STORE B INTO 'page_views_parquet' USING parquet.pig.ParquetStorer;
for data stored in a computer cluster running Apache Hadoop Real-time query for HDFS and HBase Easy to Hive users to migrate For some things MapReduce is just too slow
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
![Map a.map(_ + 1) Array[Int] = Array(2, 3, 4) MapReduce](https://files.speakerdeck.com/presentations/6feb4ce026e50132408f62c99fab29cb/slide_34.jpg){kind=link}
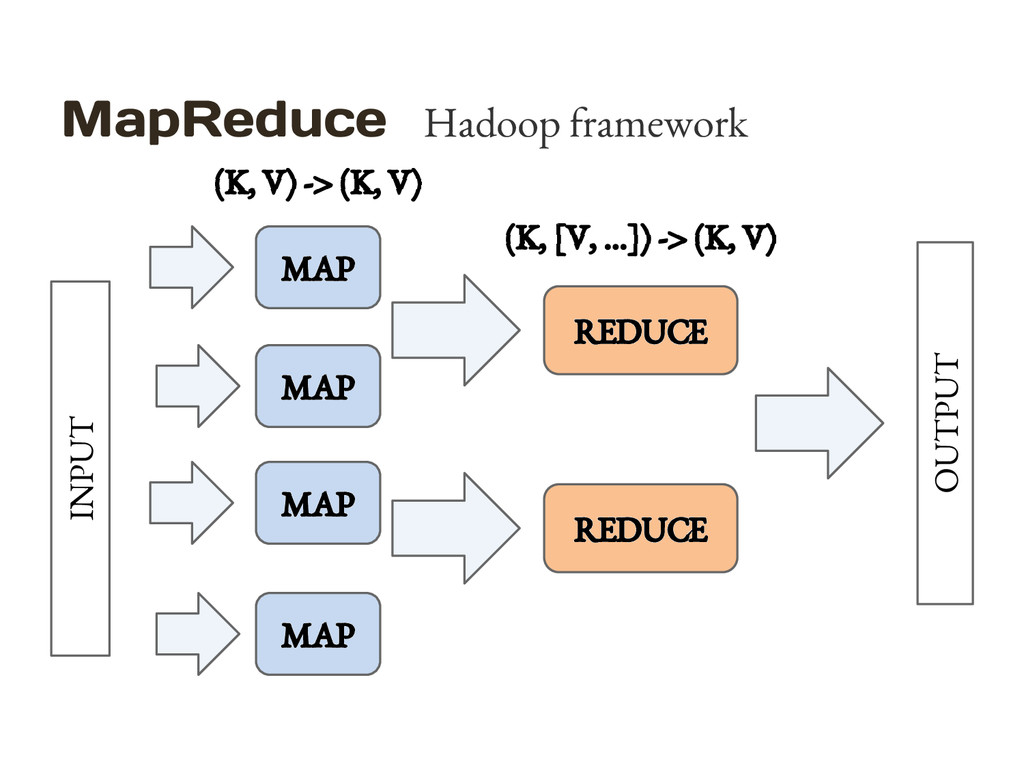{kind=link}
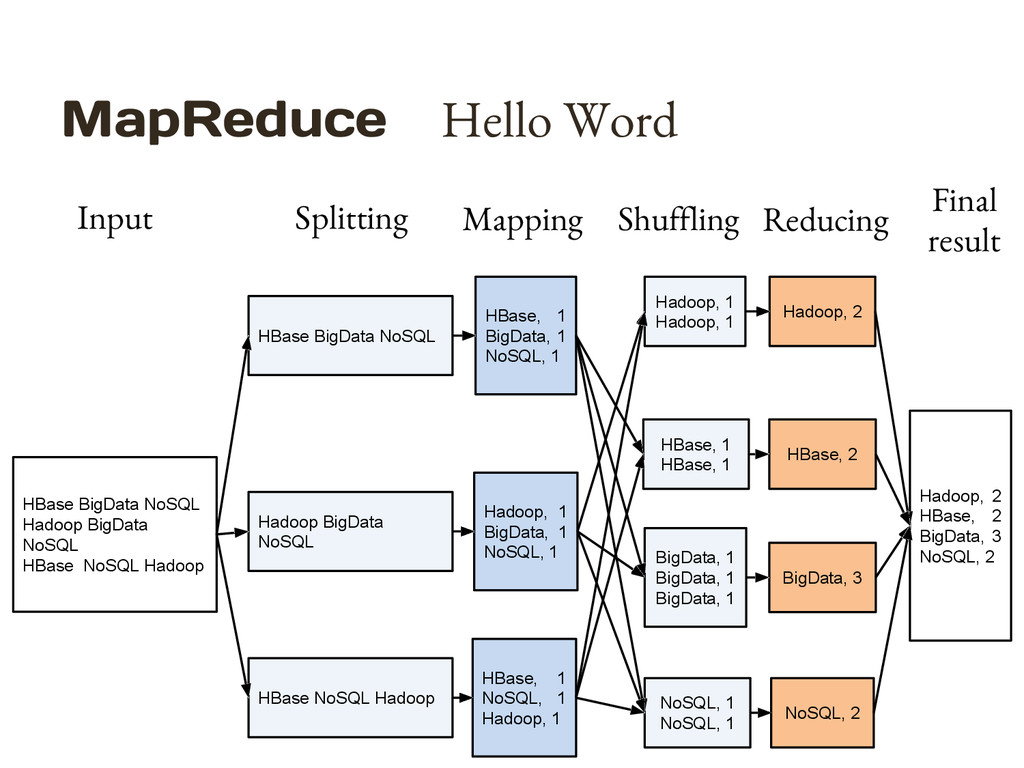{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}