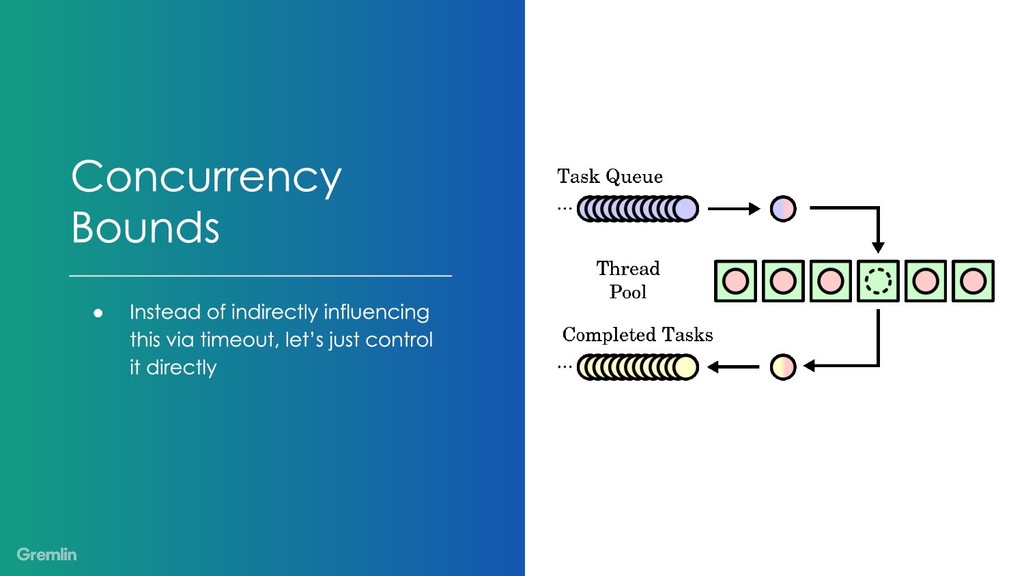
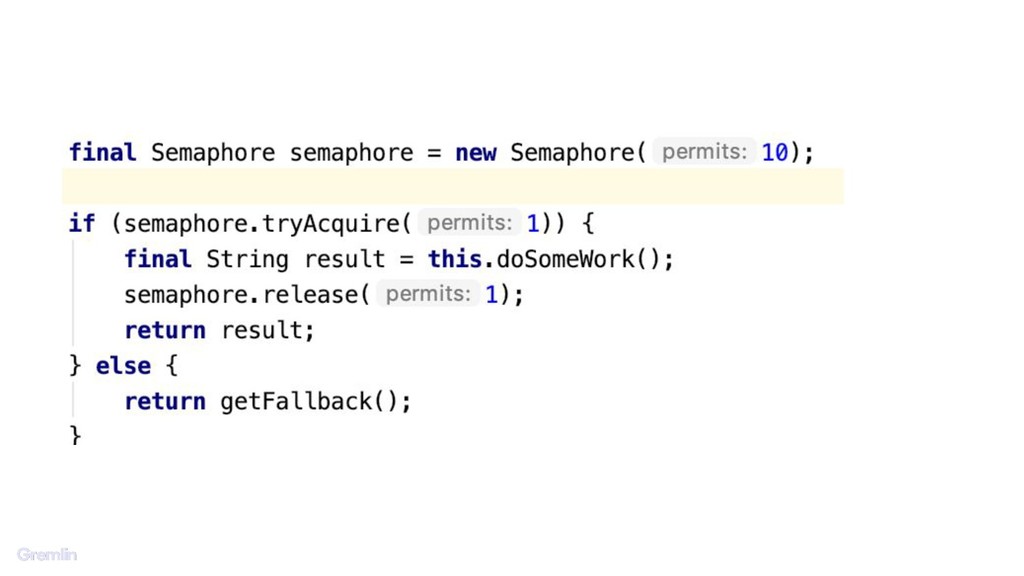
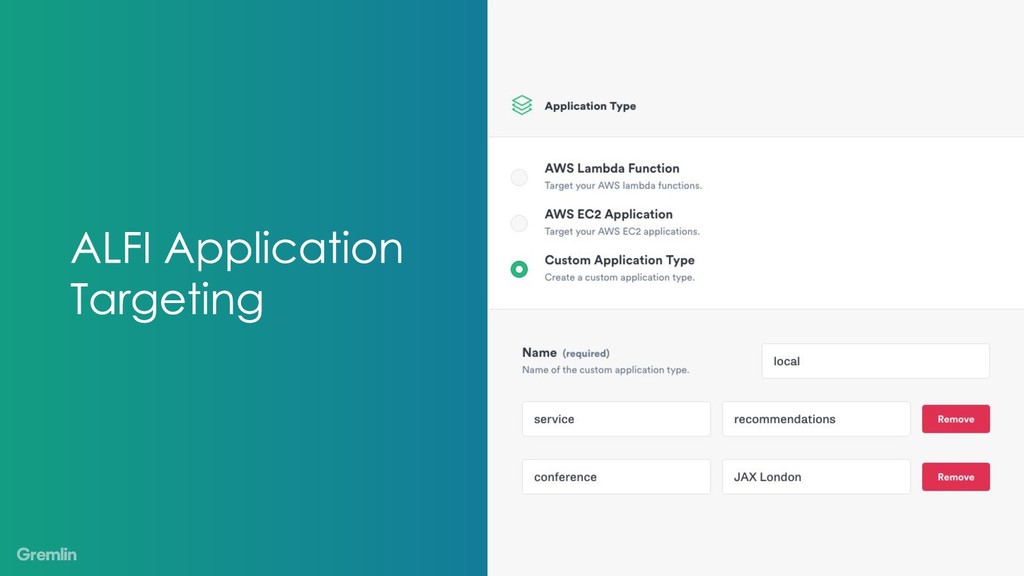
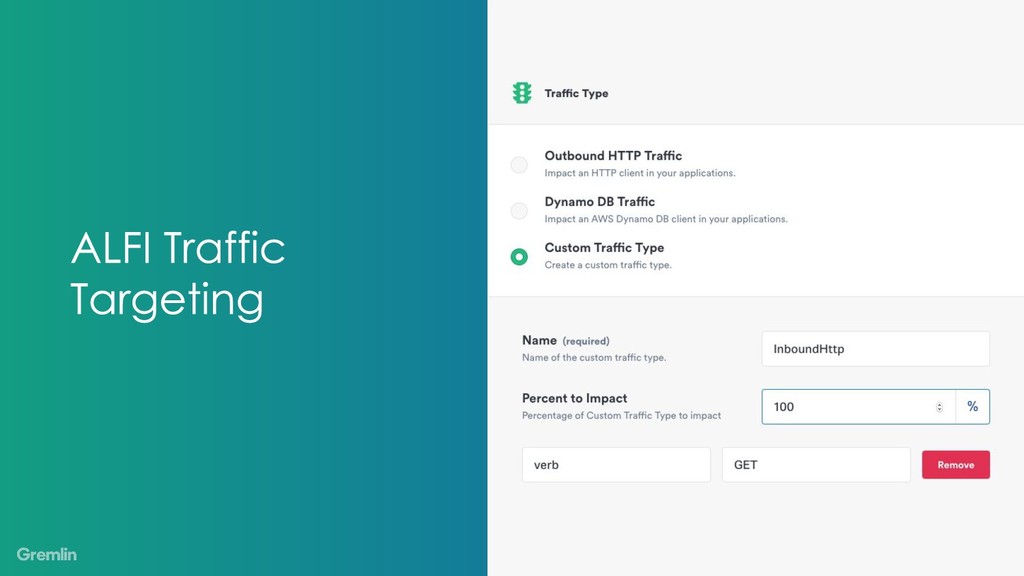
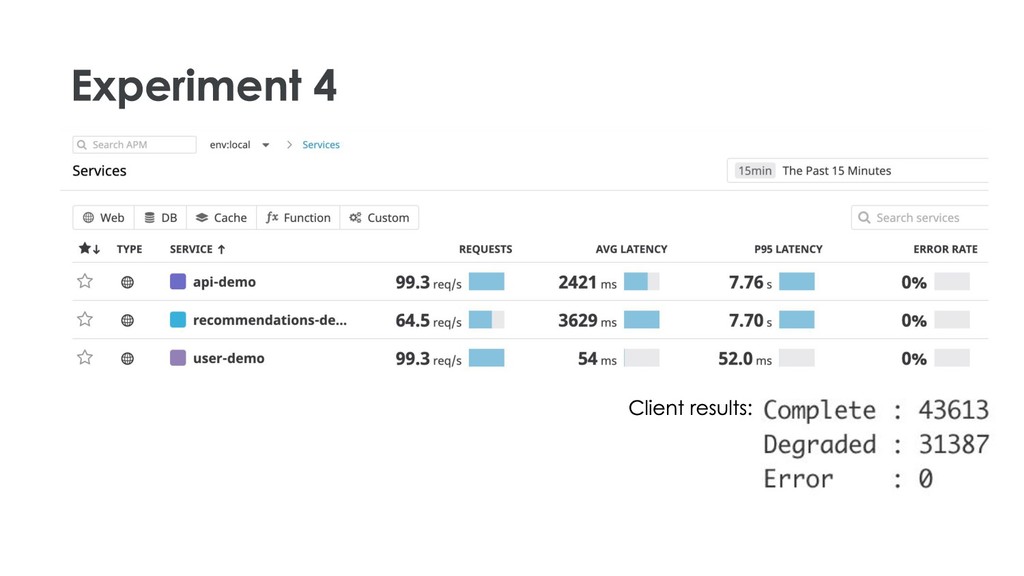
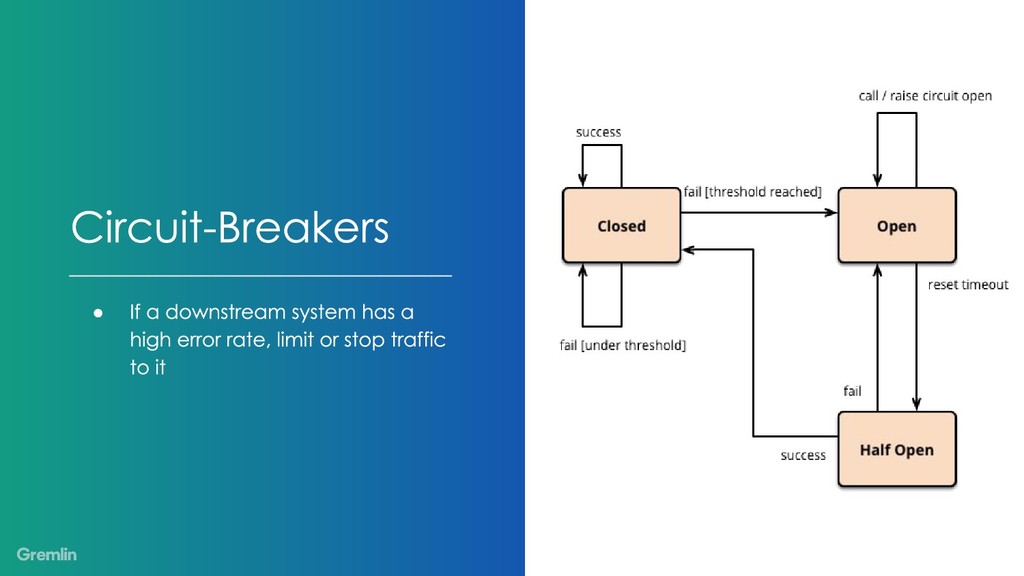
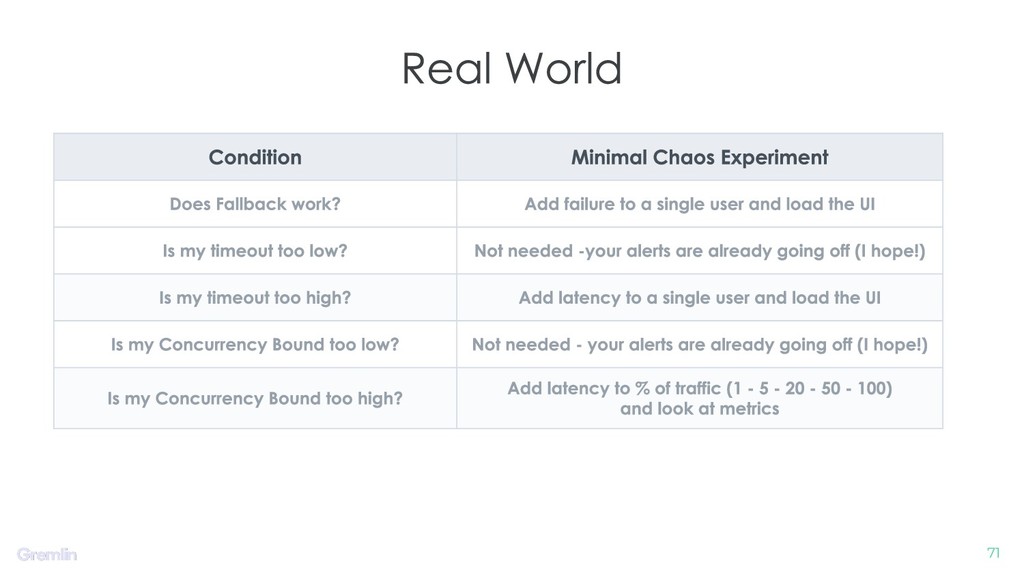
As our systems are growing more complex, we’ve come up with a standard set of ideas to help manage the dependencies between components. Ideas like timeouts, concurrency bounds, and circuit breakers let us control these interactions.
However, these ideas are complex too. Each of them has a variety of knobs to tune, and they’re rarely exercised in steady-state. So there’s a lot of opportunity for them to behave poorly when called upon, and especially when a few of them kick in at once.
My talk will show how to use chaos engineering to increase confidence in your usage and tuning of timeouts, concurrency bounds, and circuit breakers. You can use these ideas to understand your system better and hopefully make future incidents more manageable.
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
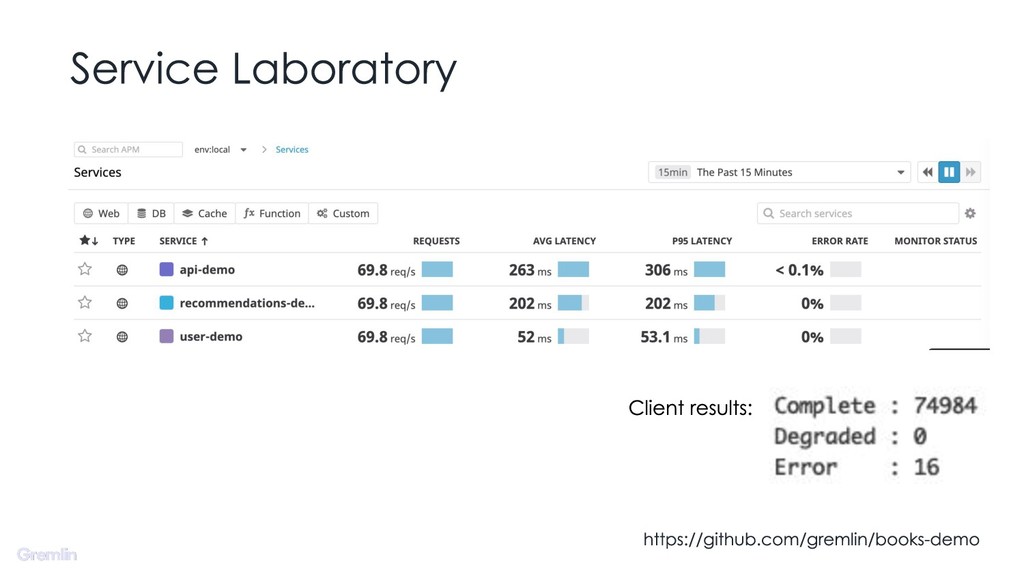{kind=link}
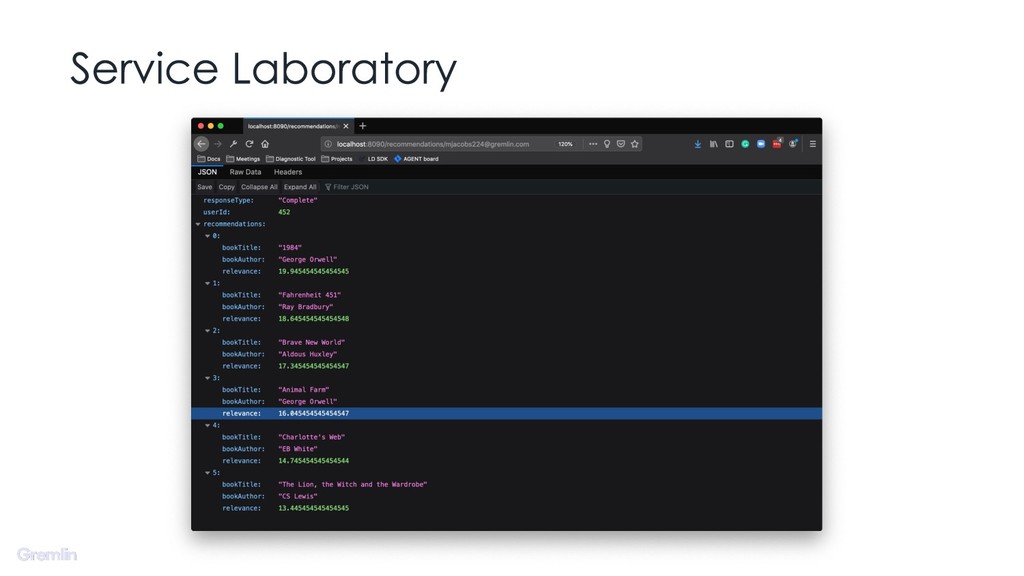{kind=link}
{kind=link}
{kind=link}
{kind=link}
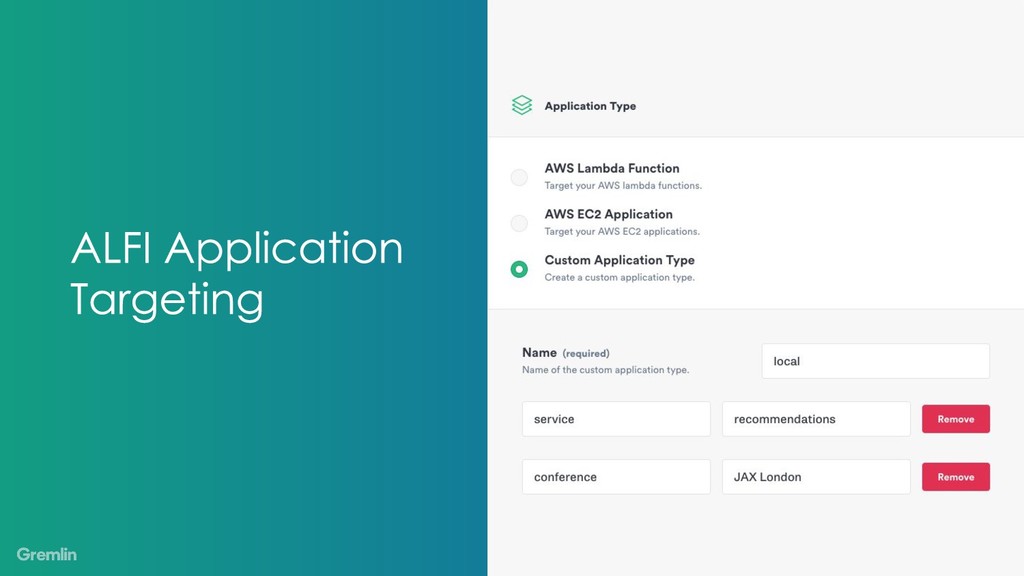{kind=link}
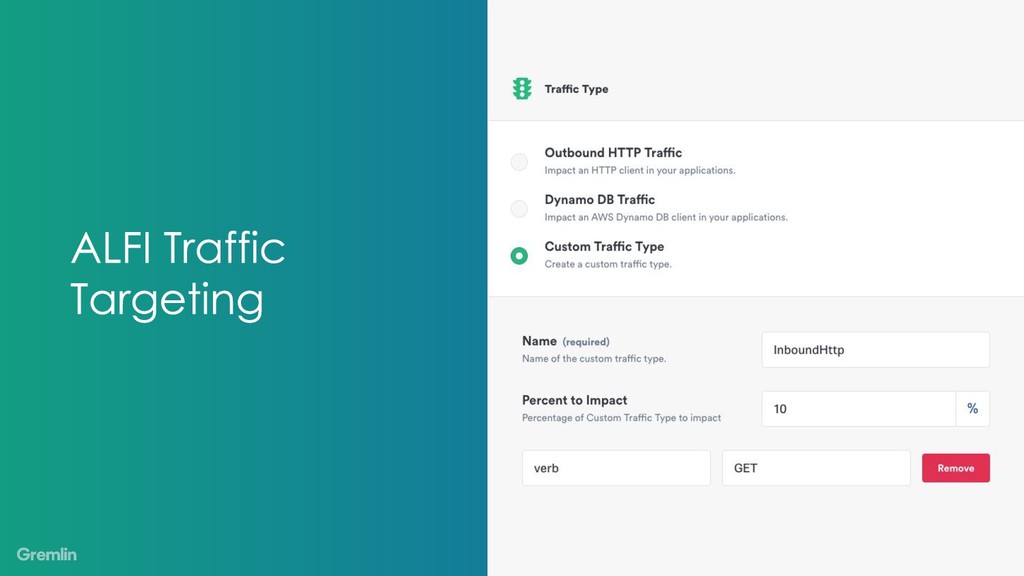{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}