Embedded languages are a convenient and expressive method to capture patterns of high-performance code in functional languages. These patterns can be turned into efficient low-level code by template instantiation of code skeletons, where code fusion combines individual skeleton instances to minimise the abstraction penalty.
In this talk, I will illustrate these concepts as used in Accelerate, an embedded language for general-purpose GPU computing in Haskell that delivers competitive performance with a fraction of the effort required in low-level GPGPU frameworks, such as CUDA or OpenCL.
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
![dotp :: [Float] -> [Float] -> Float dotp xs ys](https://files.speakerdeck.com/presentations/b8572120e6df0130d2771a67bd7877ee/slide_16.jpg){kind=link}
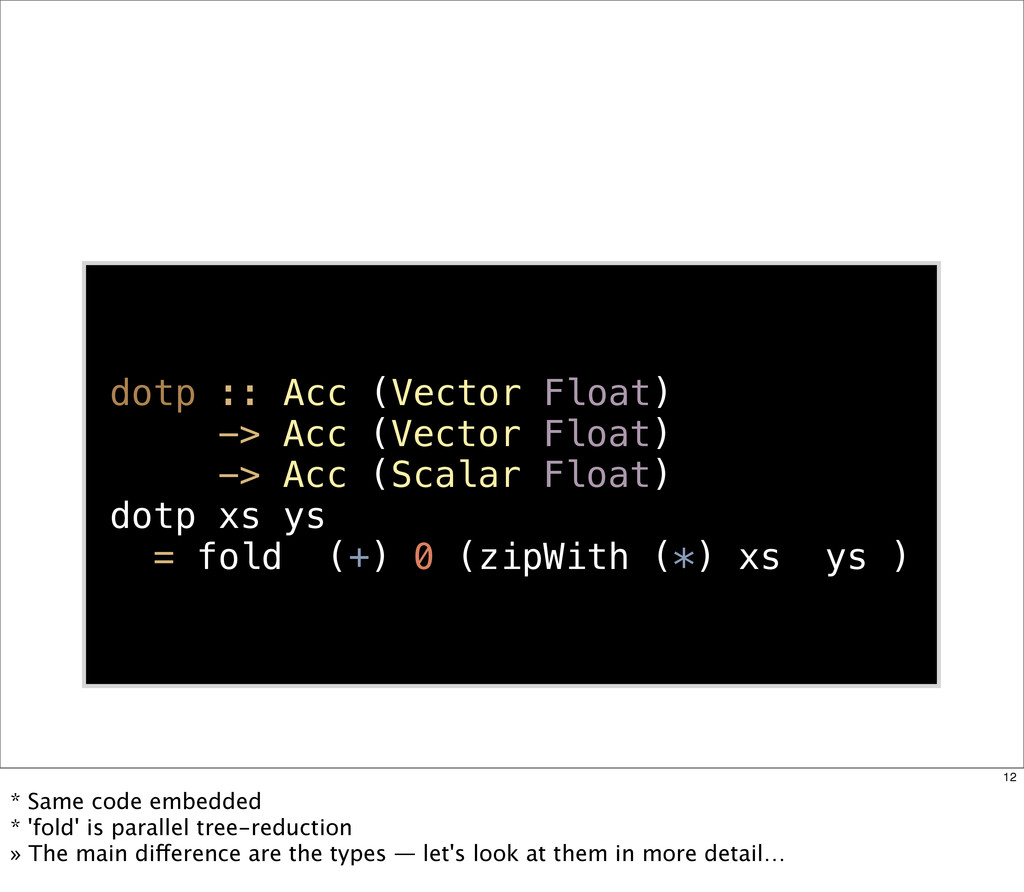{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
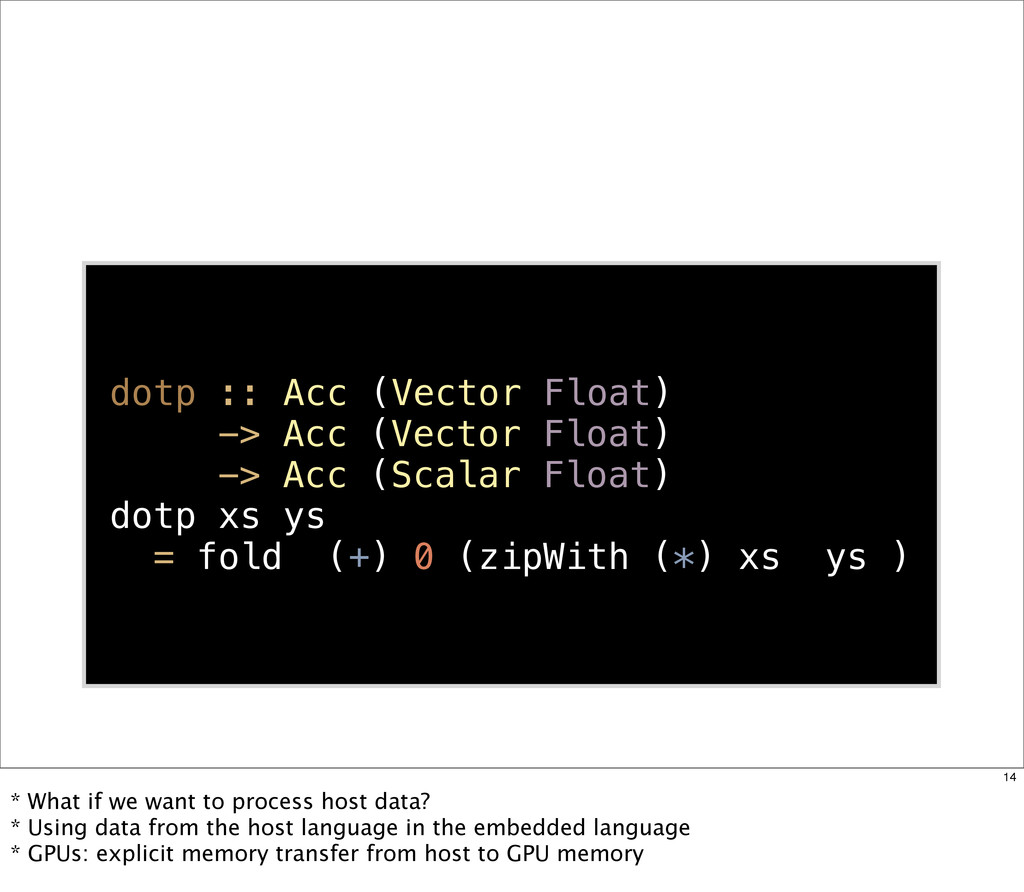{kind=link}
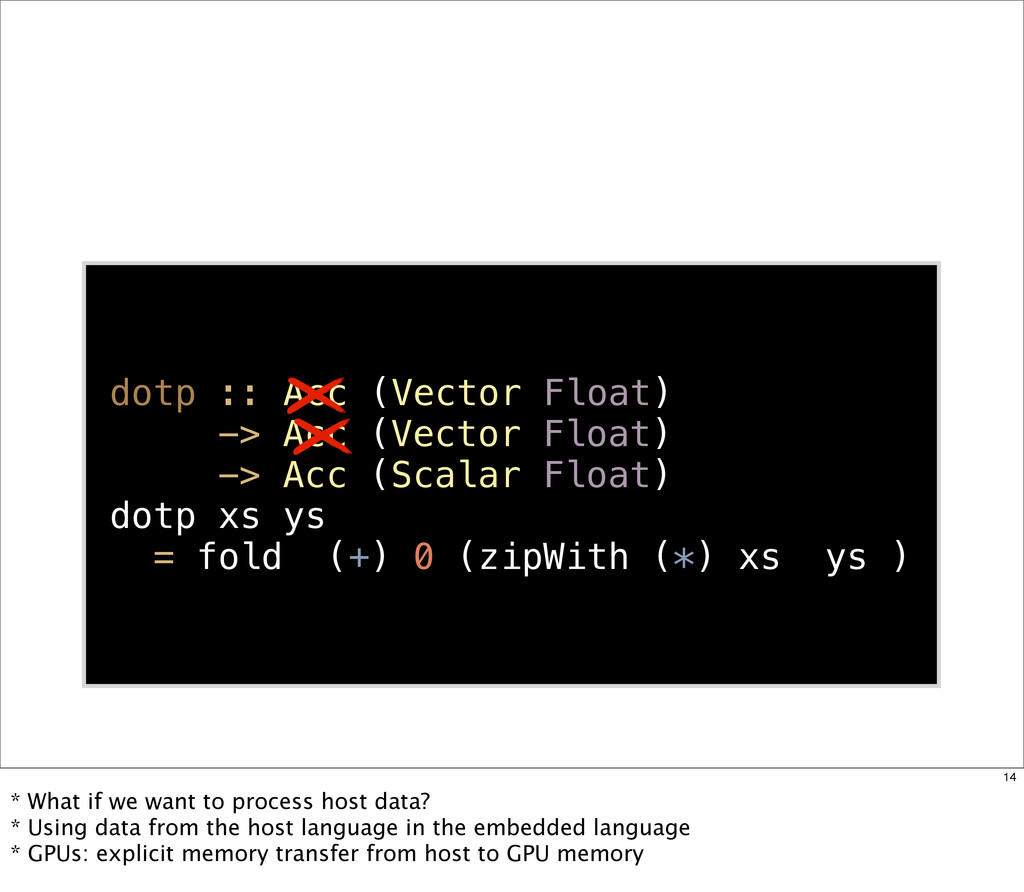{kind=link}
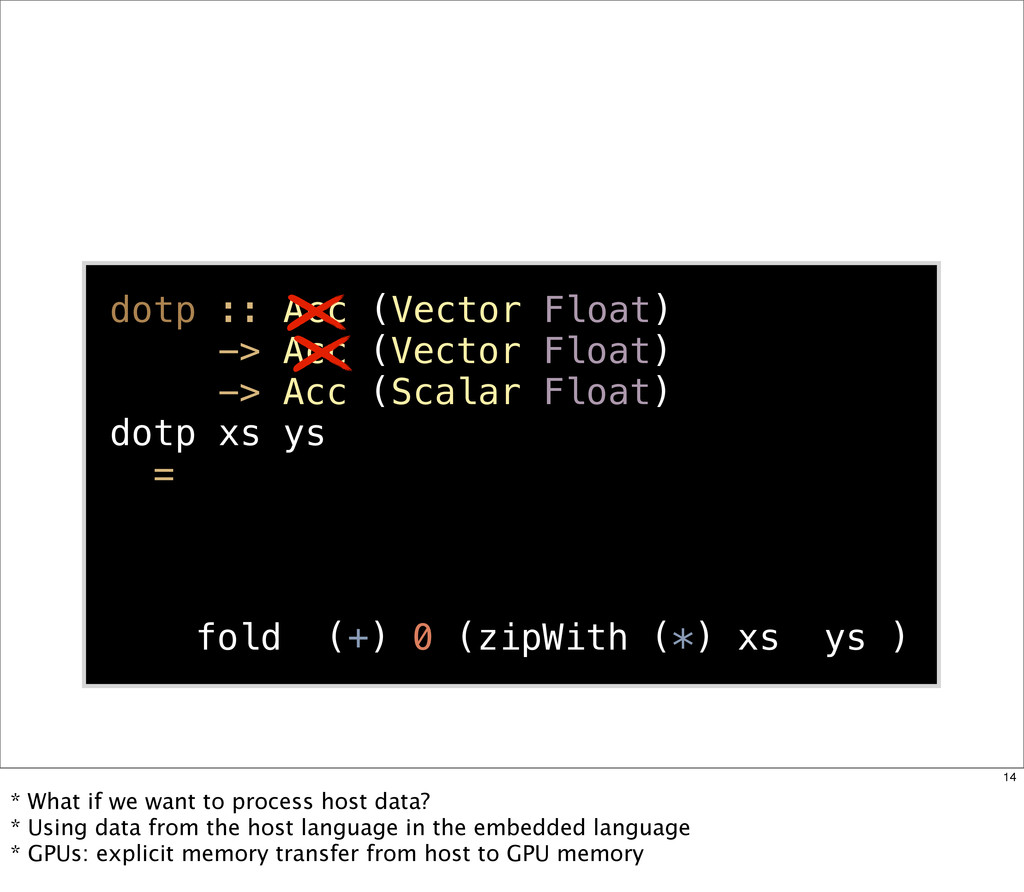{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
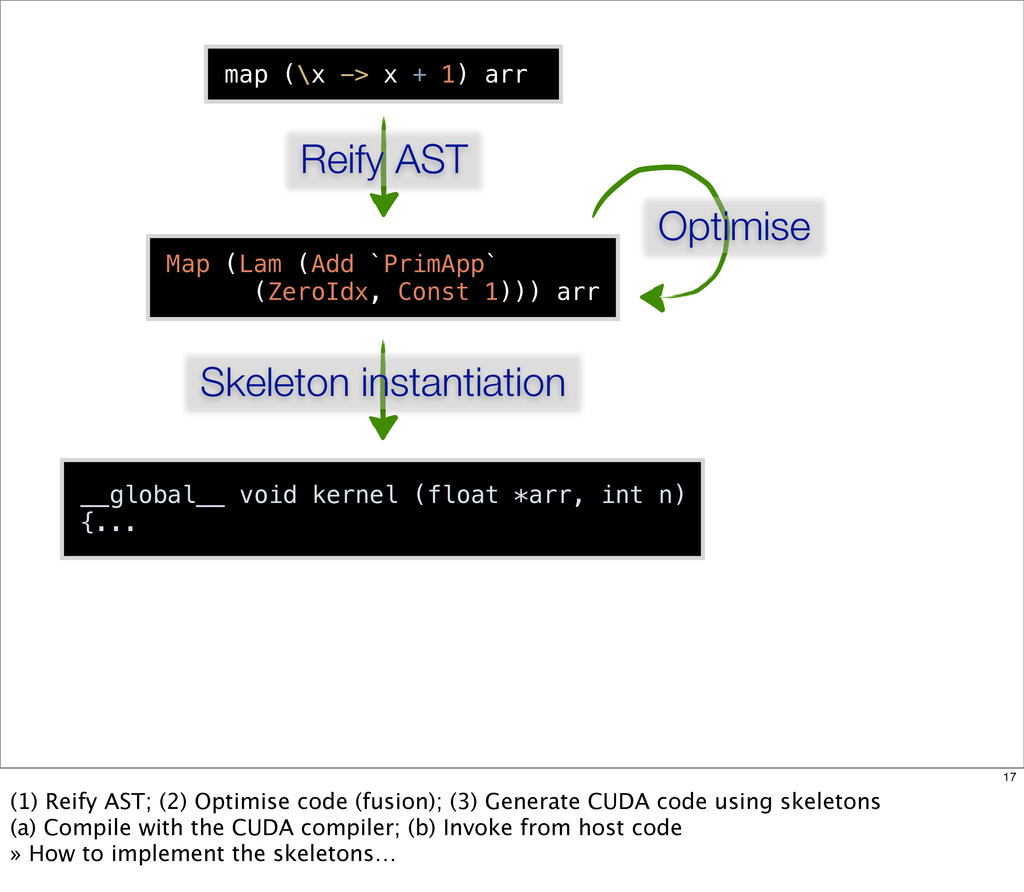{kind=link}
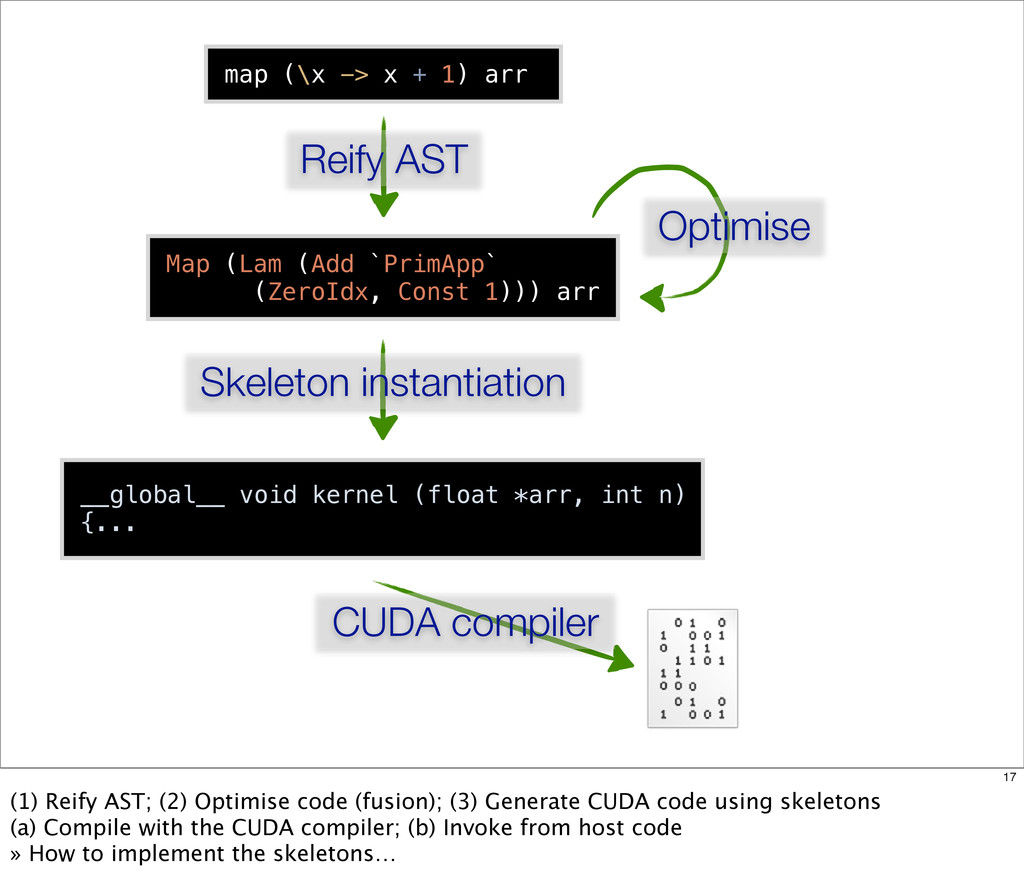{kind=link}
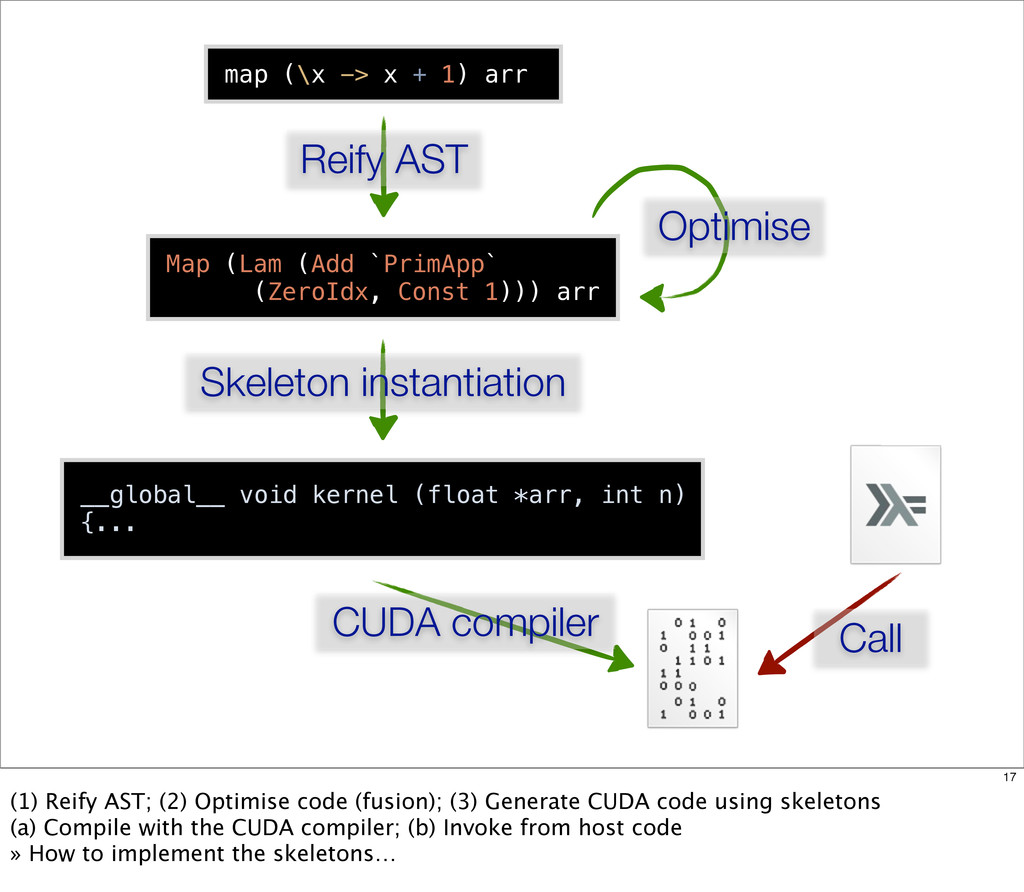{kind=link}
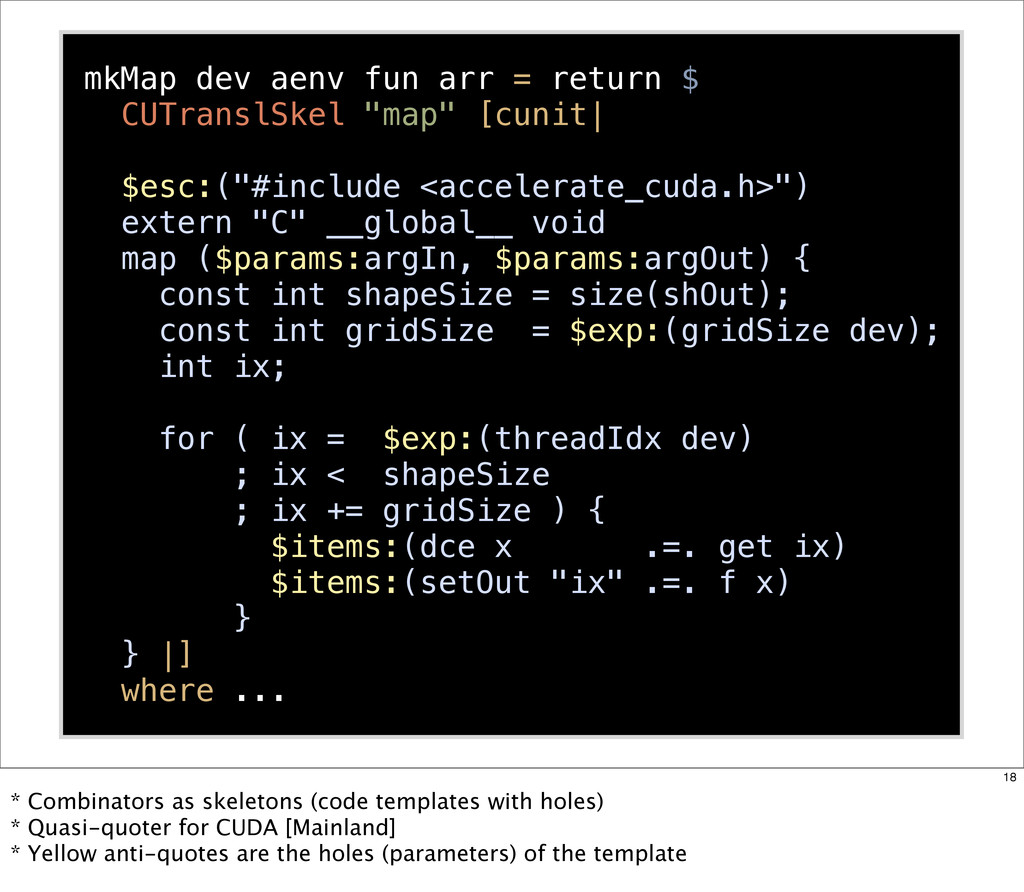{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
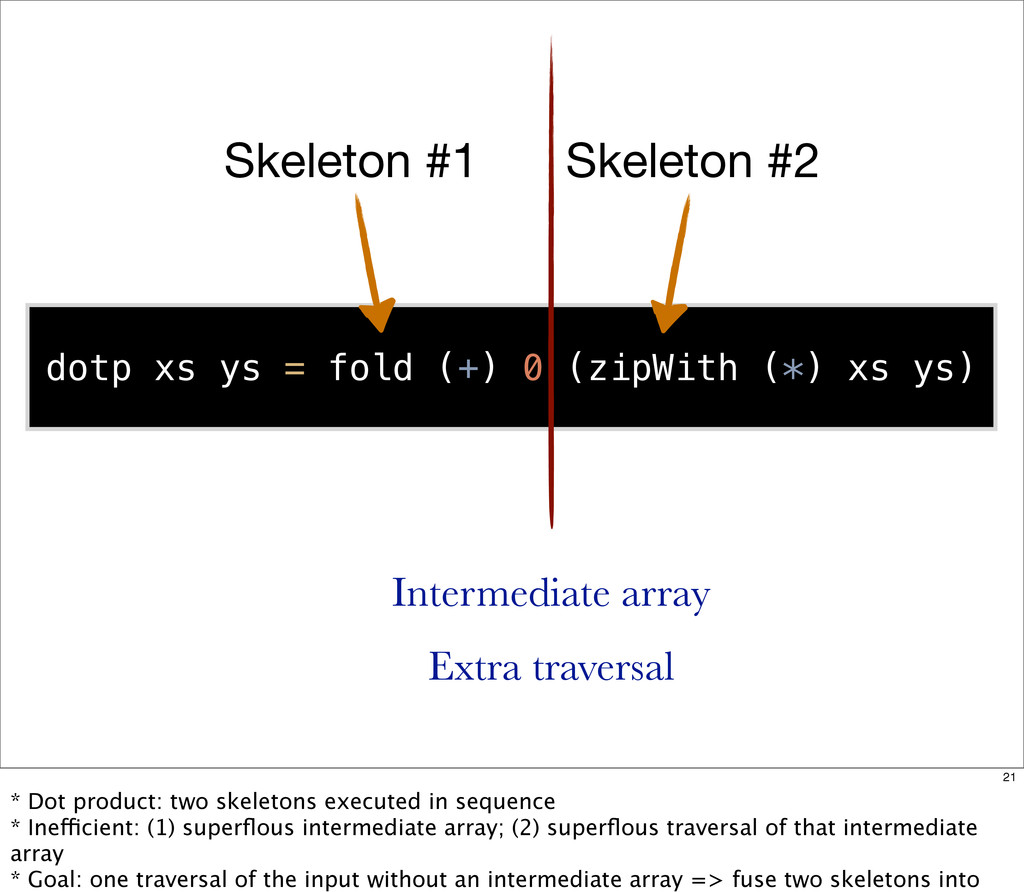{kind=link}
{kind=link}
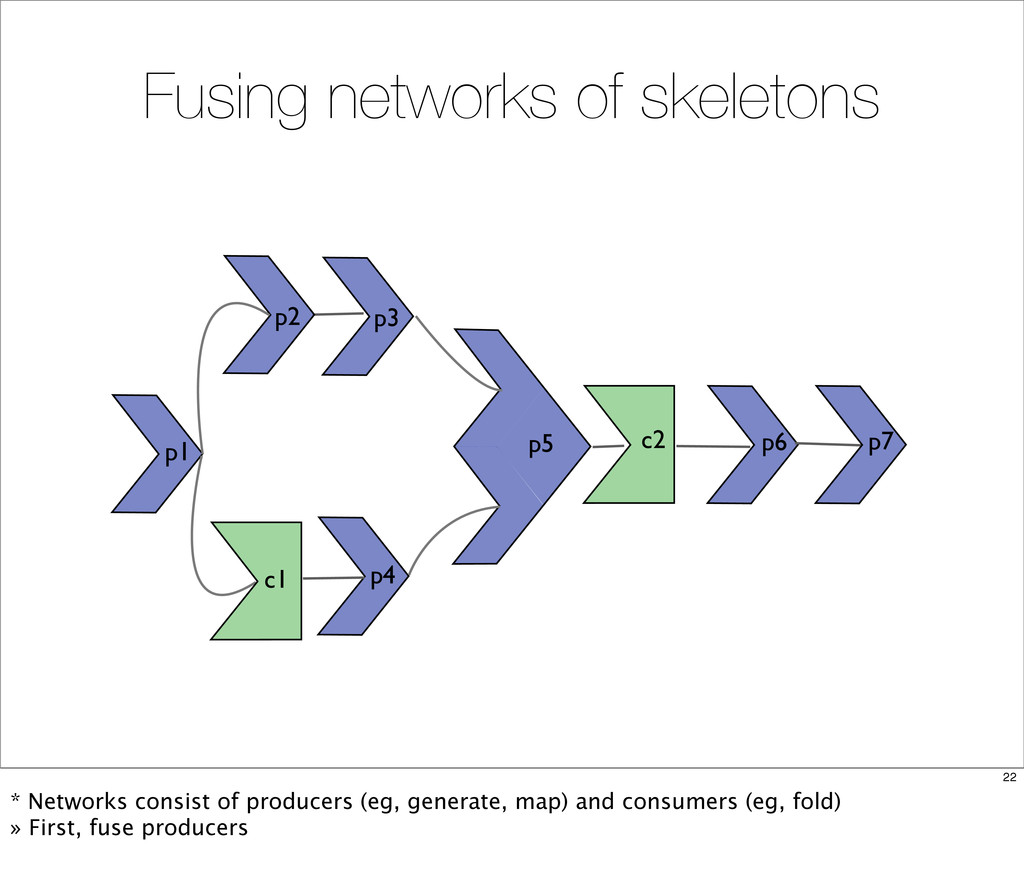{kind=link}
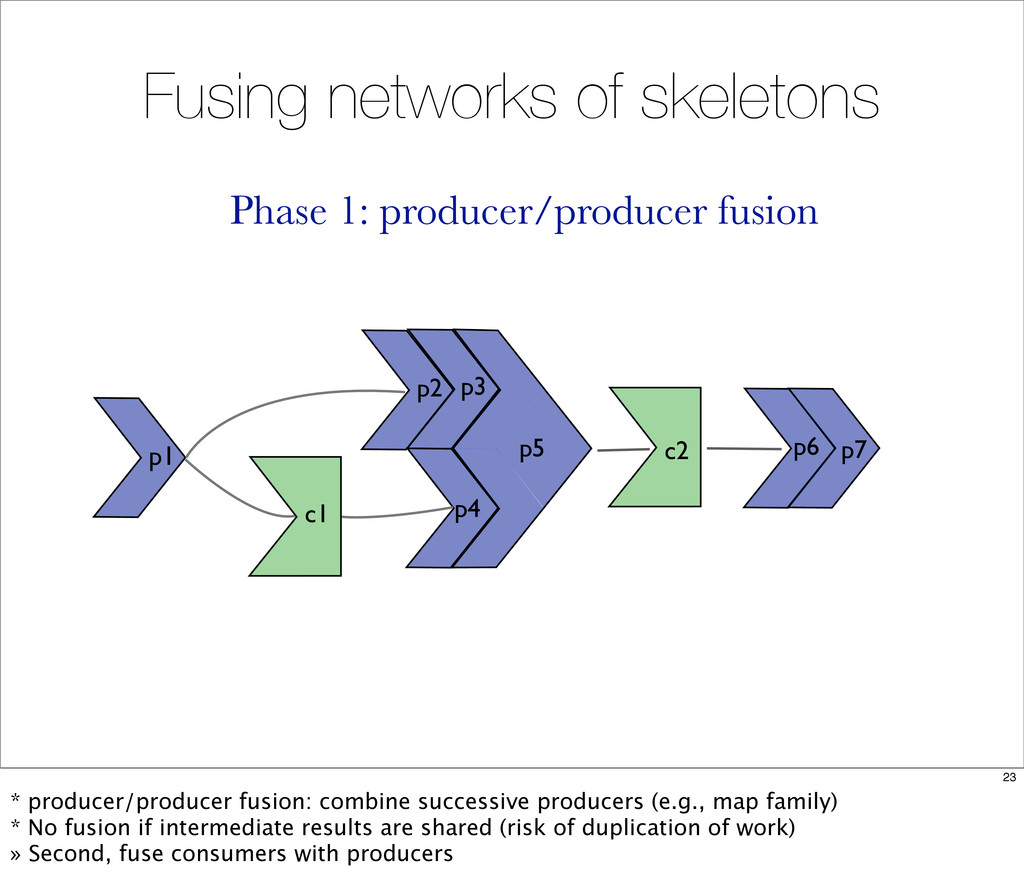{kind=link}
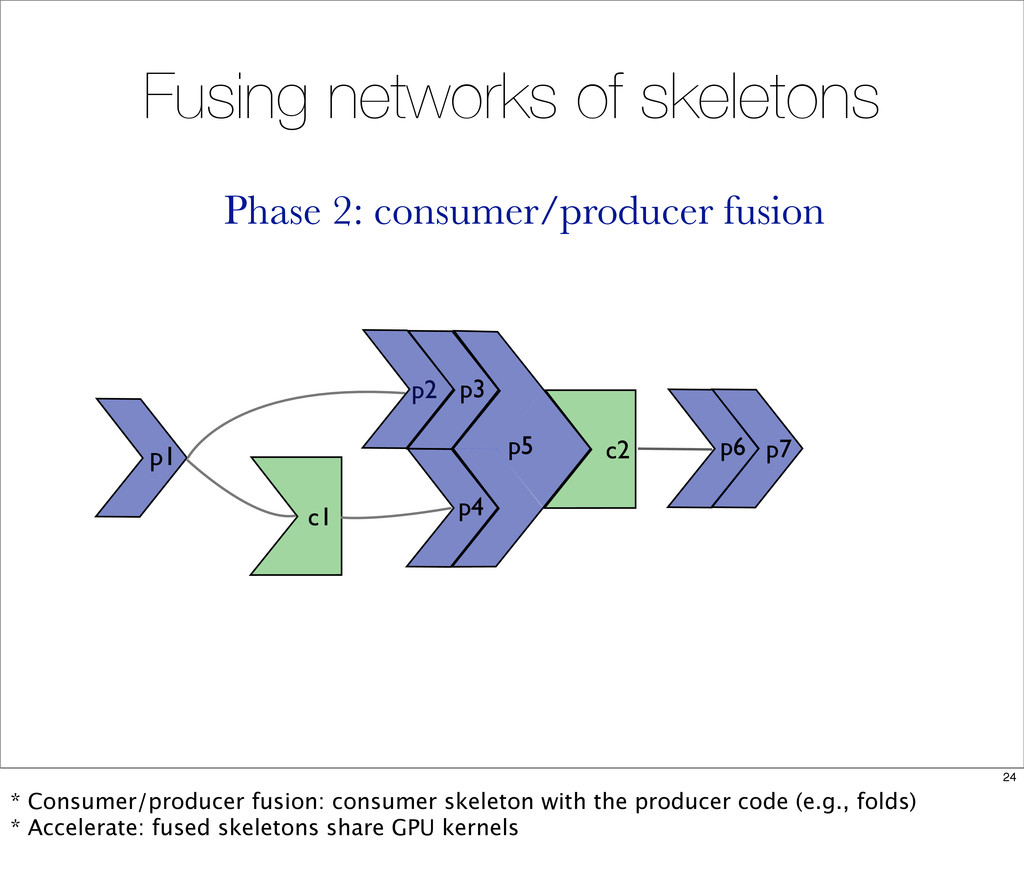{kind=link}
{kind=link}
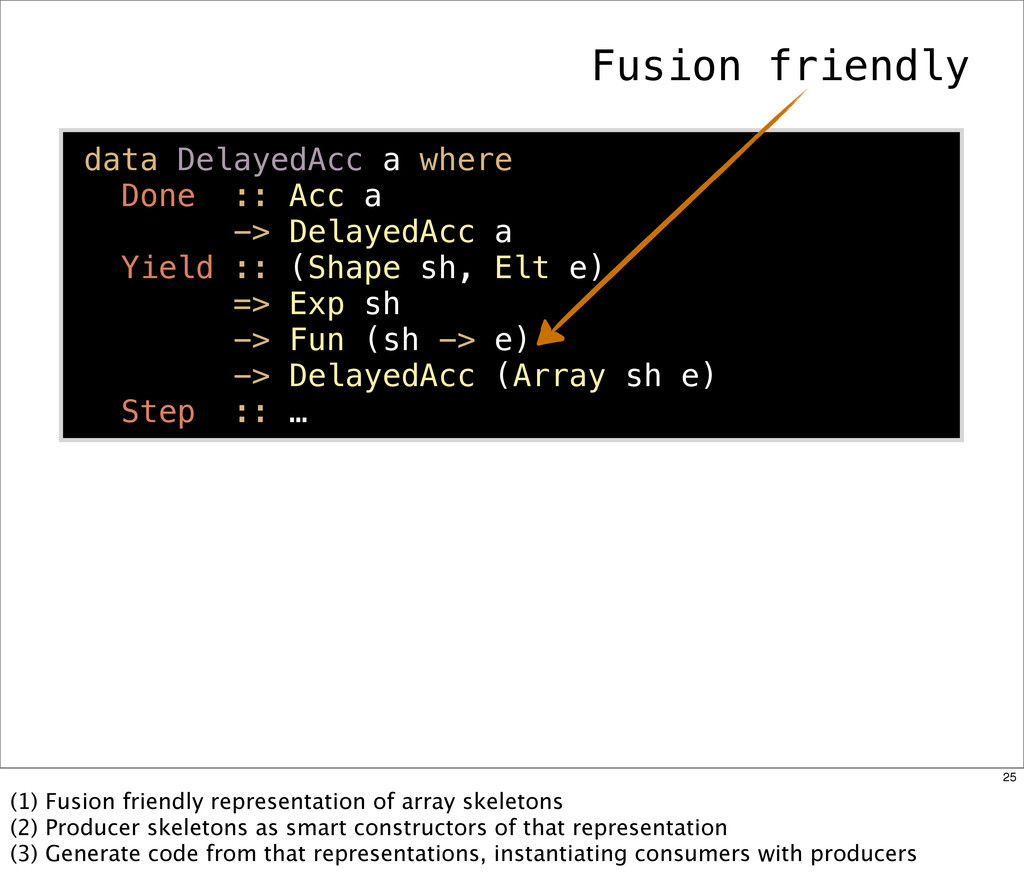{kind=link}
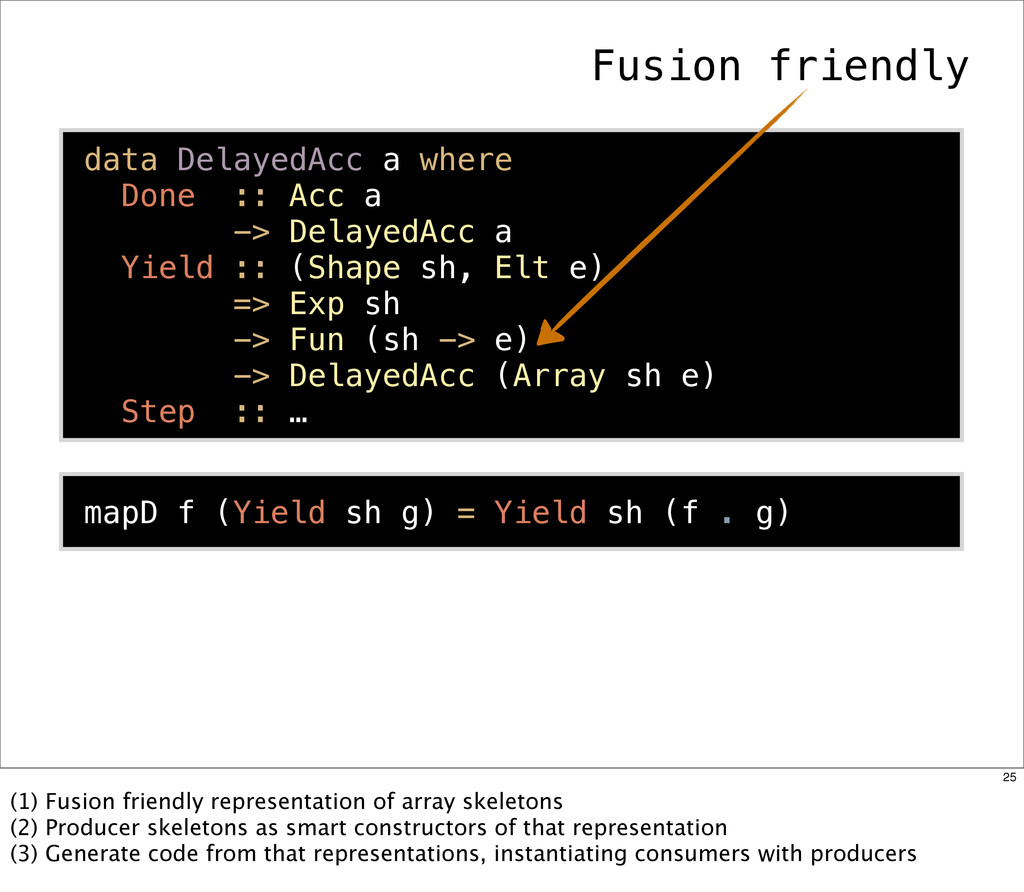{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
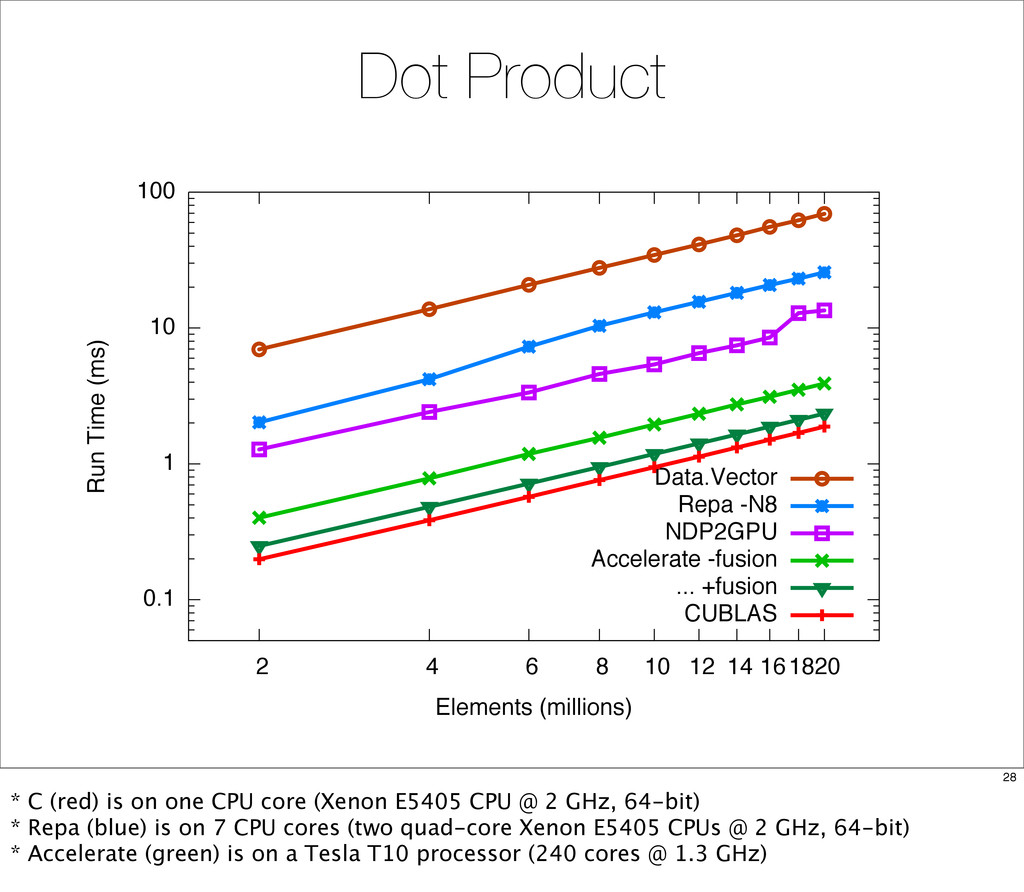{kind=link}
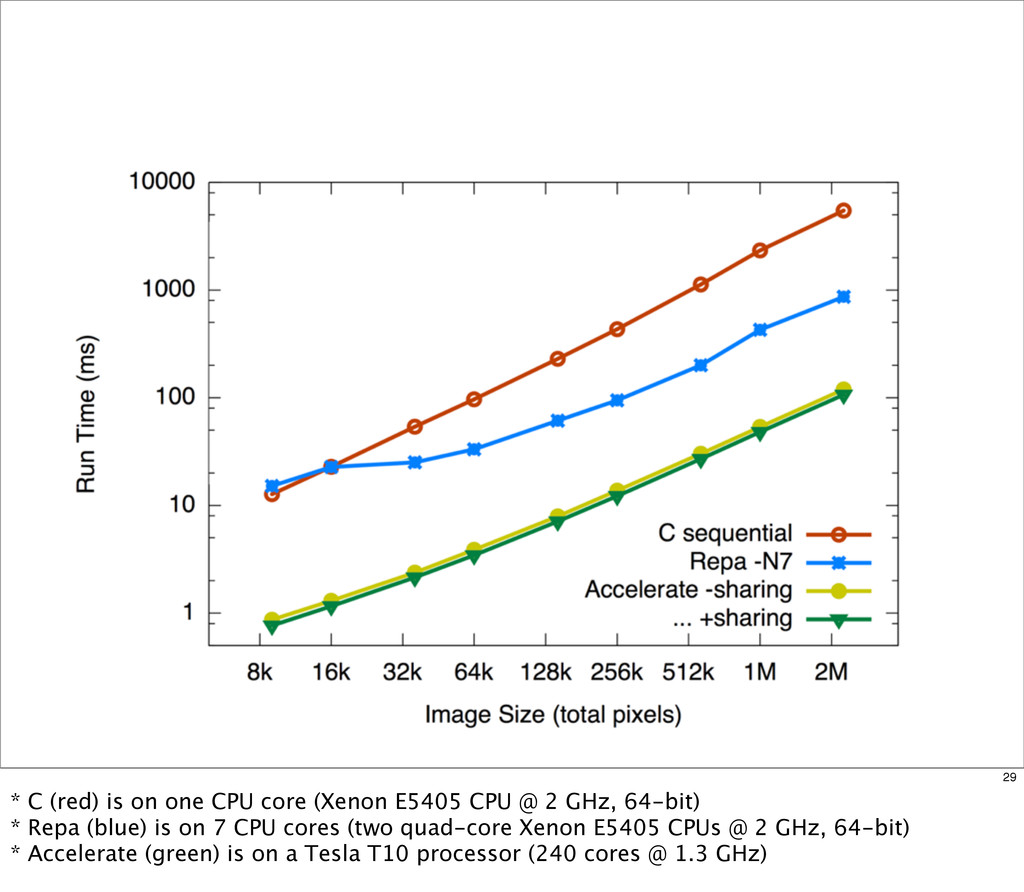{kind=link}
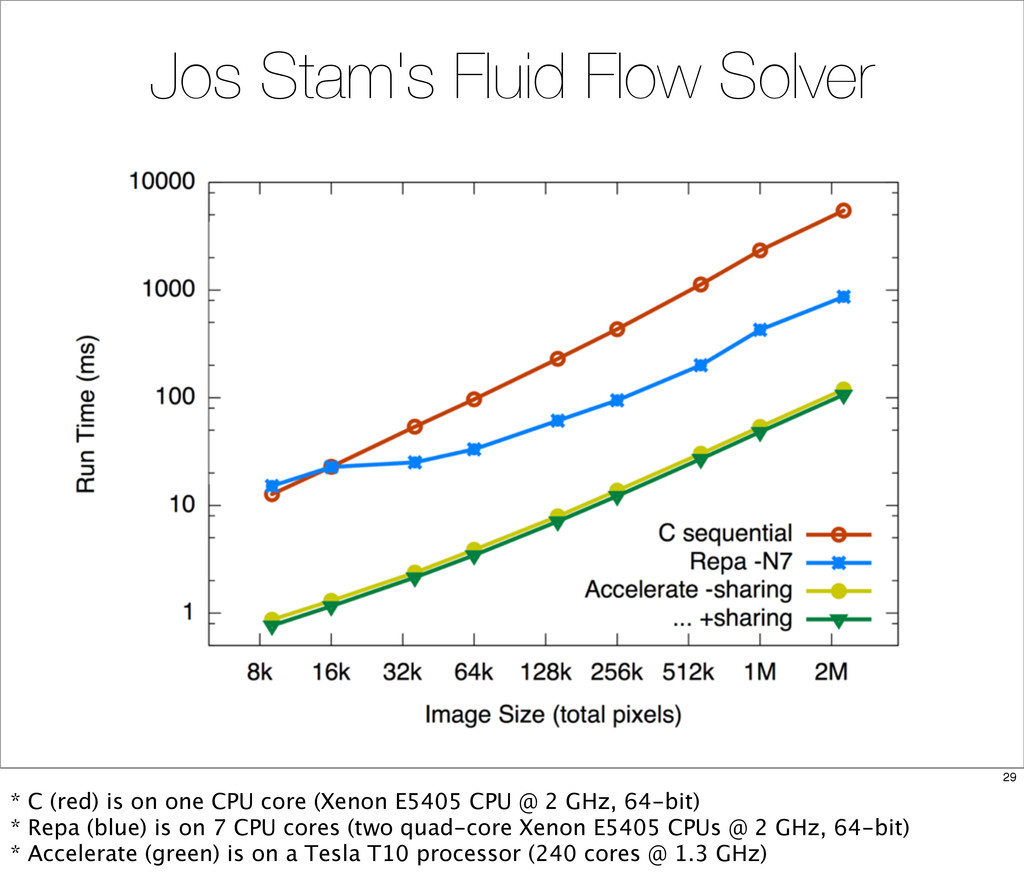{kind=link}
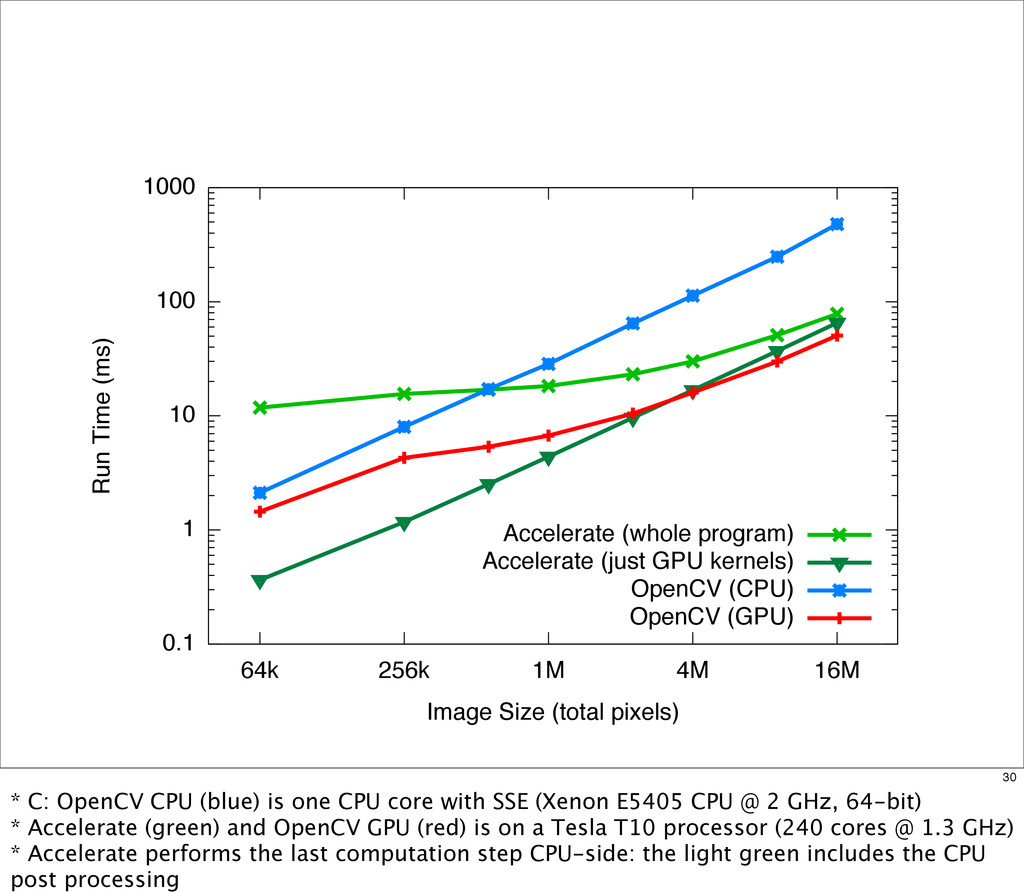{kind=link}
{kind=link}
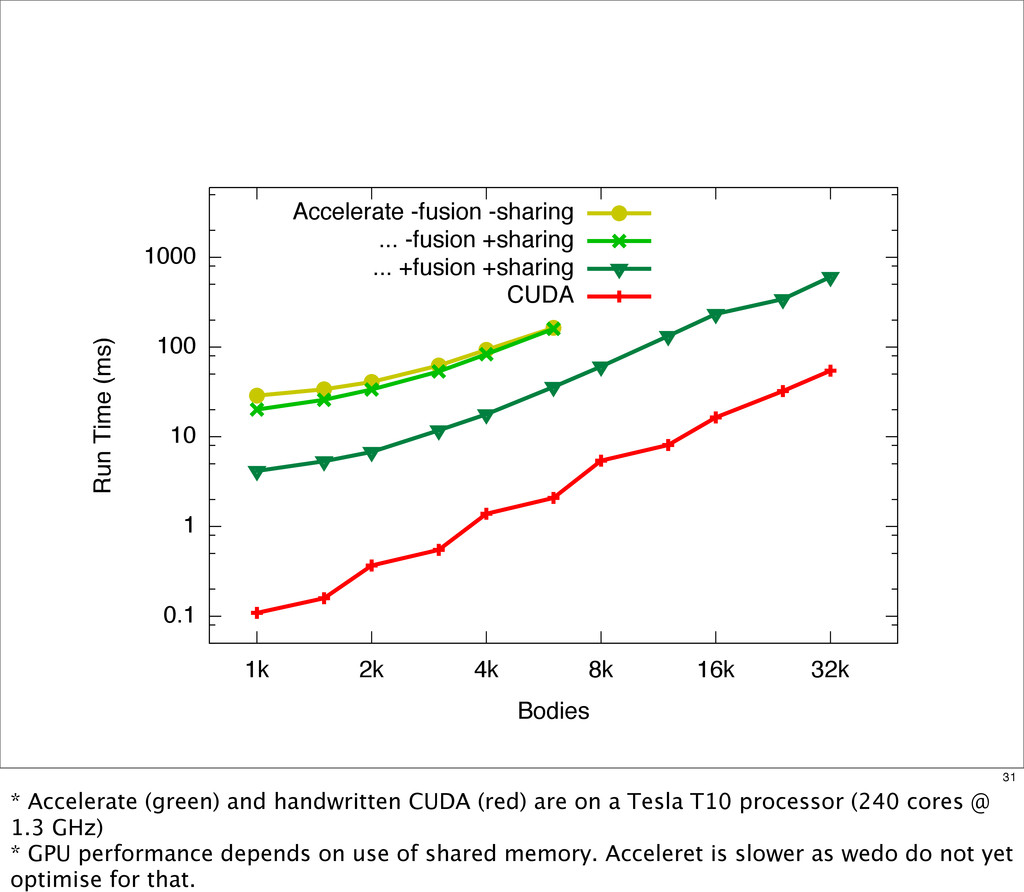{kind=link}
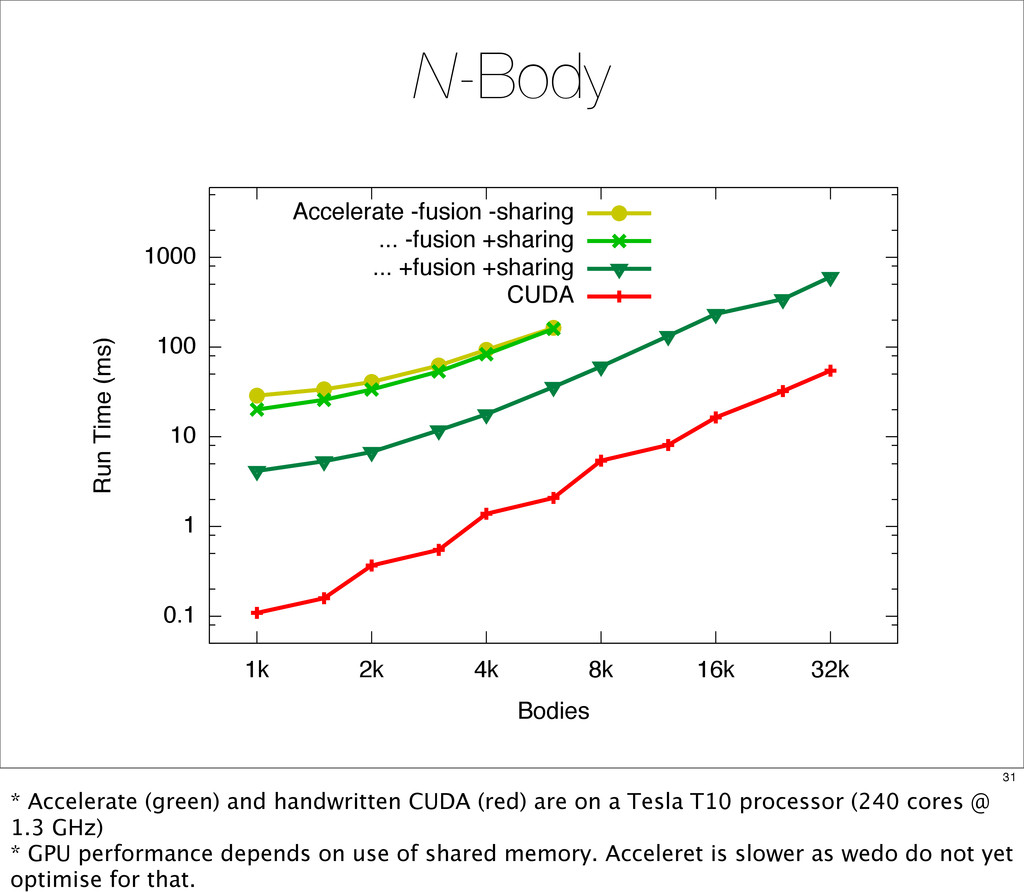{kind=link}
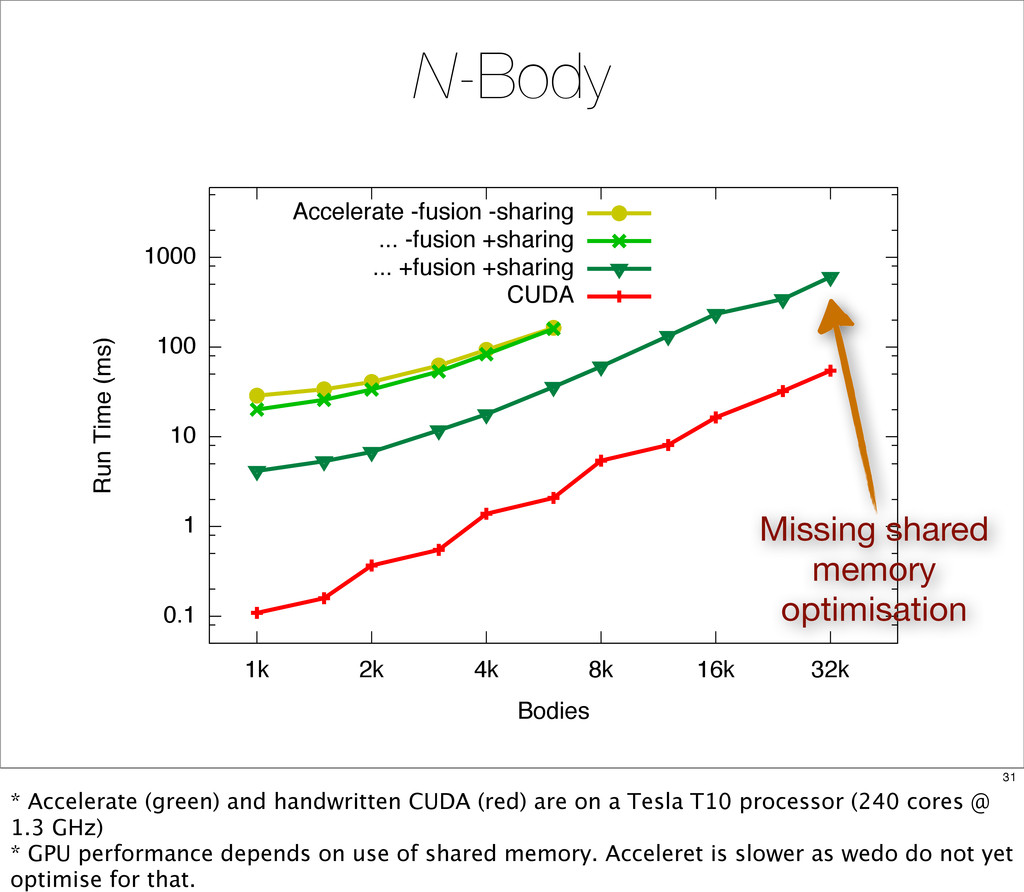{kind=link}
{kind=link}
{kind=link}