In this course, we will explain incident management in Mercari and its best practices of it. We share a complete incident journey, including three phases "before, during, and after the incident." We also cover how we conduct incident reviews and improve retrospective qualities throughout the company.
{kind=link}
{kind=link}
{kind=link}
{kind=link}
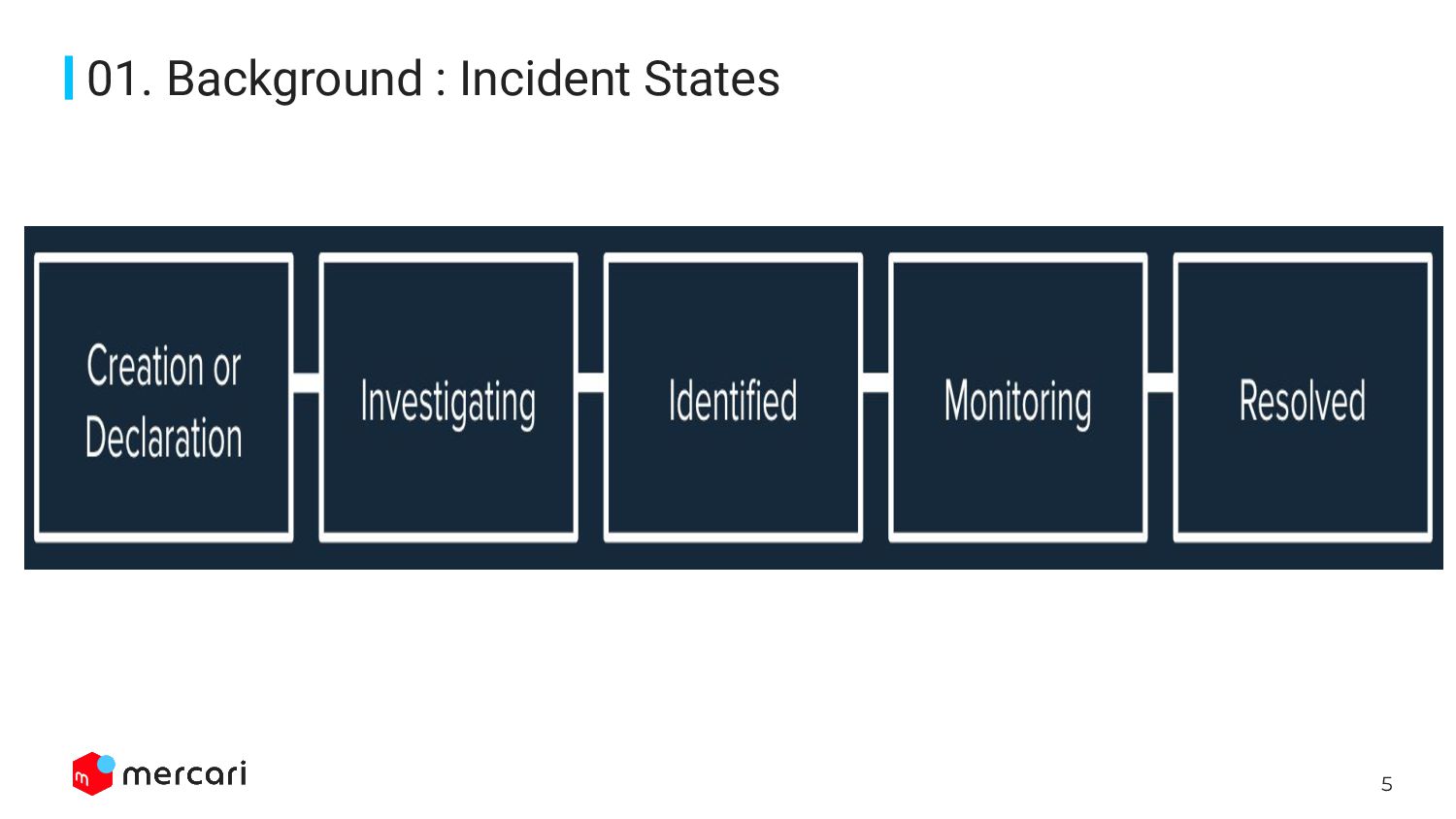{kind=link}
{kind=link}
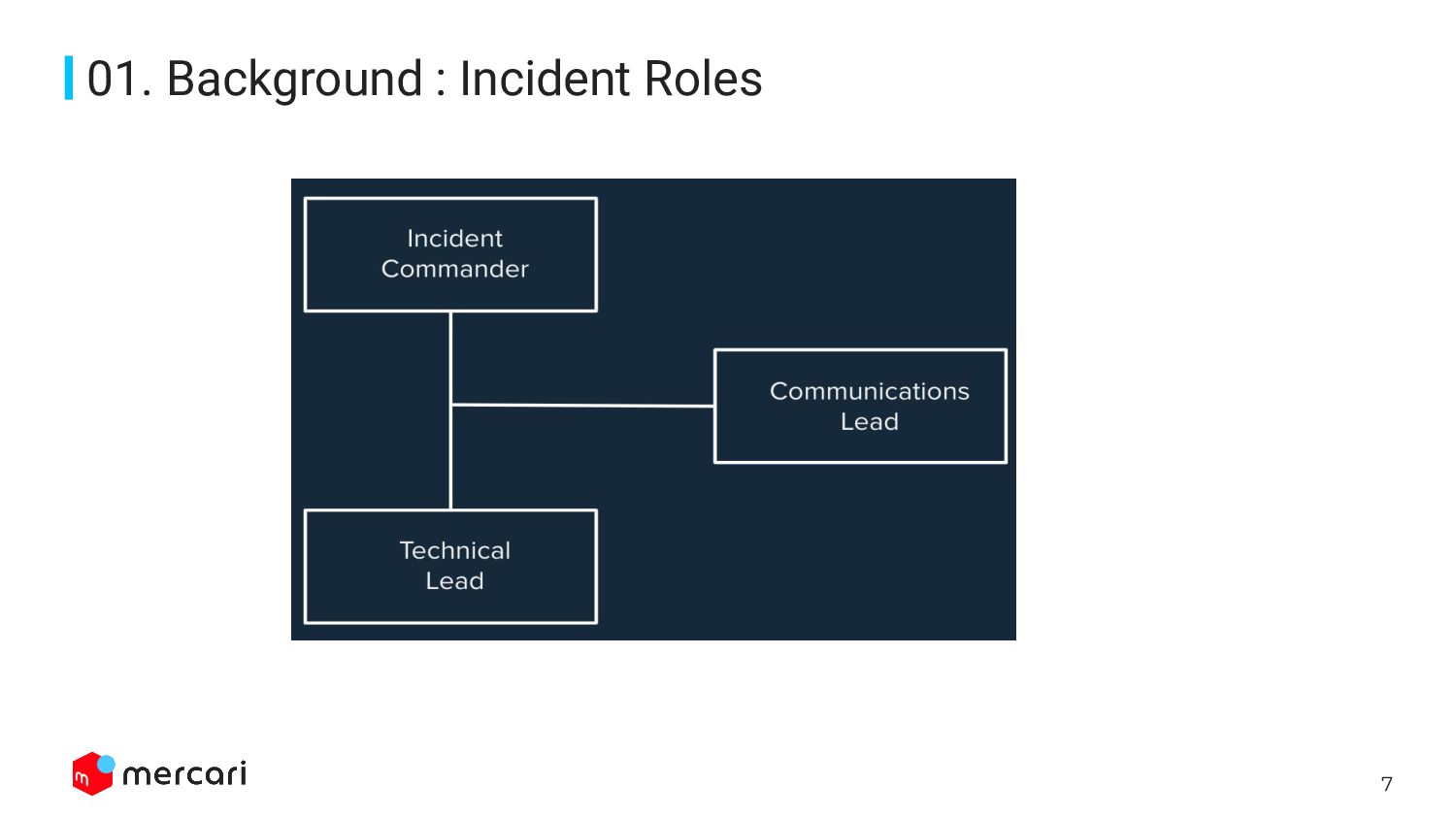{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
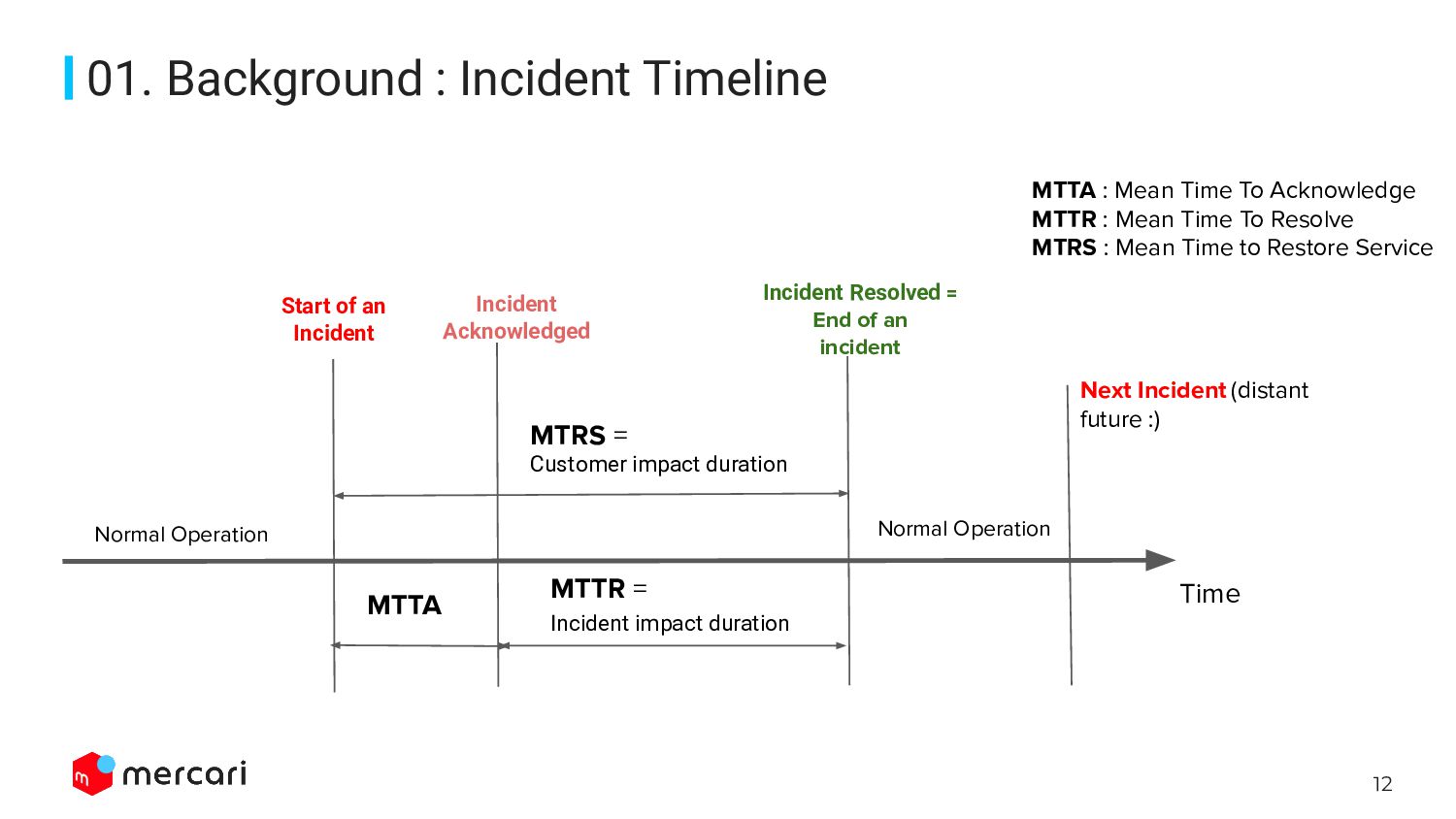{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}