• etc... など,様々なデータセットを作成可能 ただ規模が大きければいいという訳ではなく 数十億規模のものは現状利用していない 大規模データセット 将来的には,巨大なデータを活用する意気込み (捨てるか使うかしなければただの無駄なコスト) オープンデータセット ・ ImageNet (ILSVRC 2012): 1.2百万画像 / 1000クラス ・ Open Images V4: 9百万画像 / 2万クラス ・ YouTube-8M Dataset: 8百万動画 / 4千クラス ・ Amazon Product Reviews: 8千万件レビュー メルカリの画像系プロジェクト ・ クラス識別用: 8.5百万画像 / 1.4万クラス ・ 出品時の画像認識用 : 5千万画像 As a matter of fact, ImageNet is relatively small by today’s standards; it “only” contains a million images that cover the specific domain of object classification https://arxiv.org/abs/1807.05520, Facebook AI Research
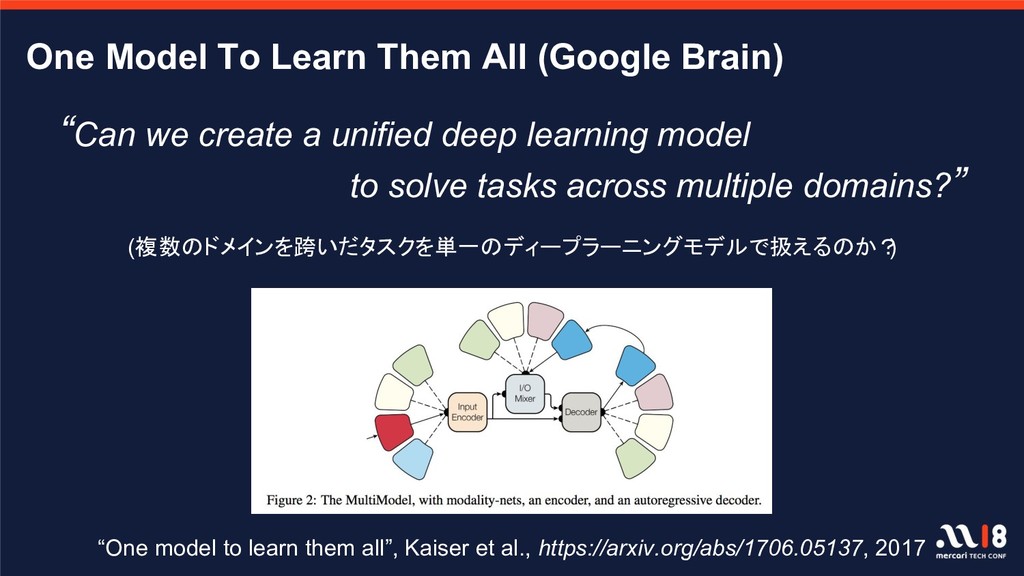
create a unified deep learning model to solve tasks across multiple domains?” (複数のドメインを跨いだタスクを単一のディープラーニングモデルで扱えるのか? ) “One model to learn them all”, Kaiser et al., https://arxiv.org/abs/1706.05137, 2017
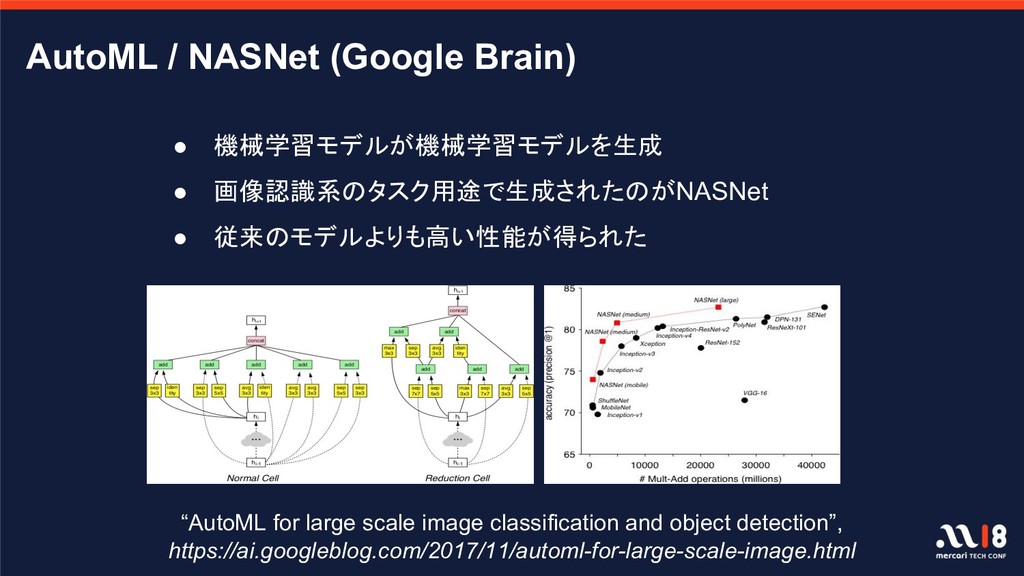
Software 2.0 ◦ One Model To Learn Them All ◦ AutoML ◦ etc... • 公開・提供される学習済み汎用モデルの転移学習がどこまでうまくいくのか? ◦ 規模の大きいモデルを最初から学習するのはコストが高すぎる • 大規模(数億〜)データセットであれば, 汎用的な機械学習モデル >> タスクに特化した機械学習モデル を本当に実現できるのかもしれない
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
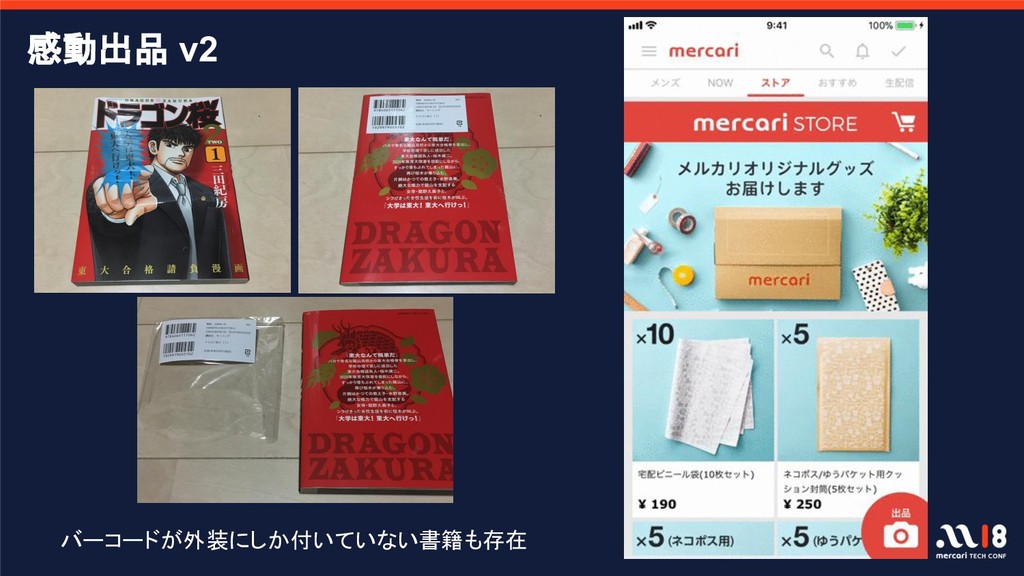{kind=link}
{kind=link}
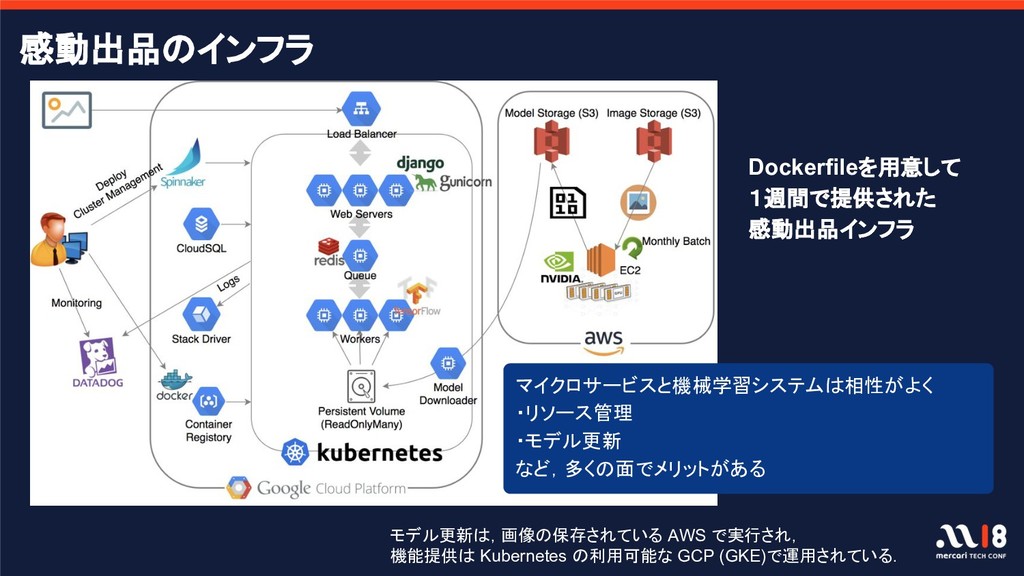{kind=link}
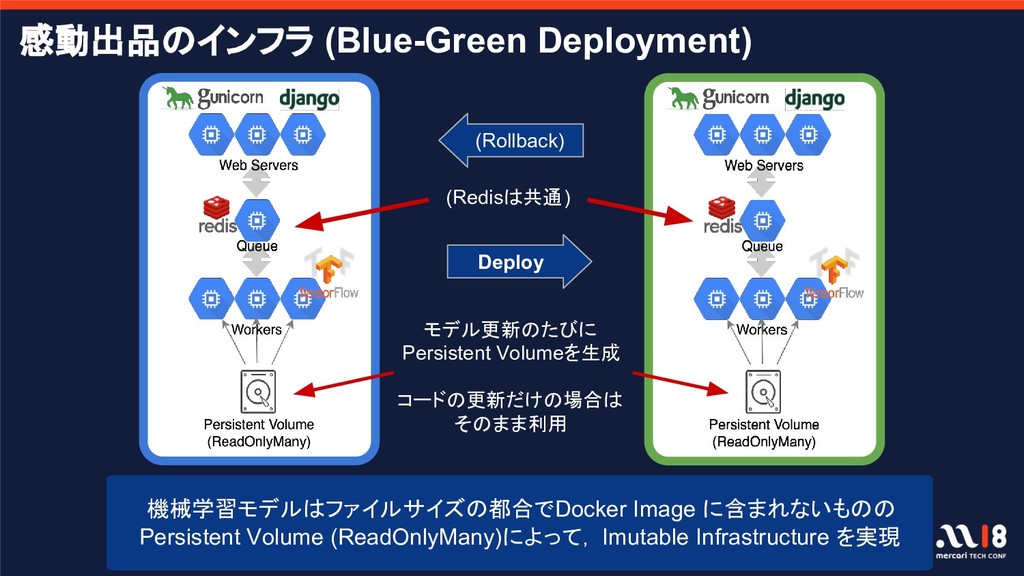{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}