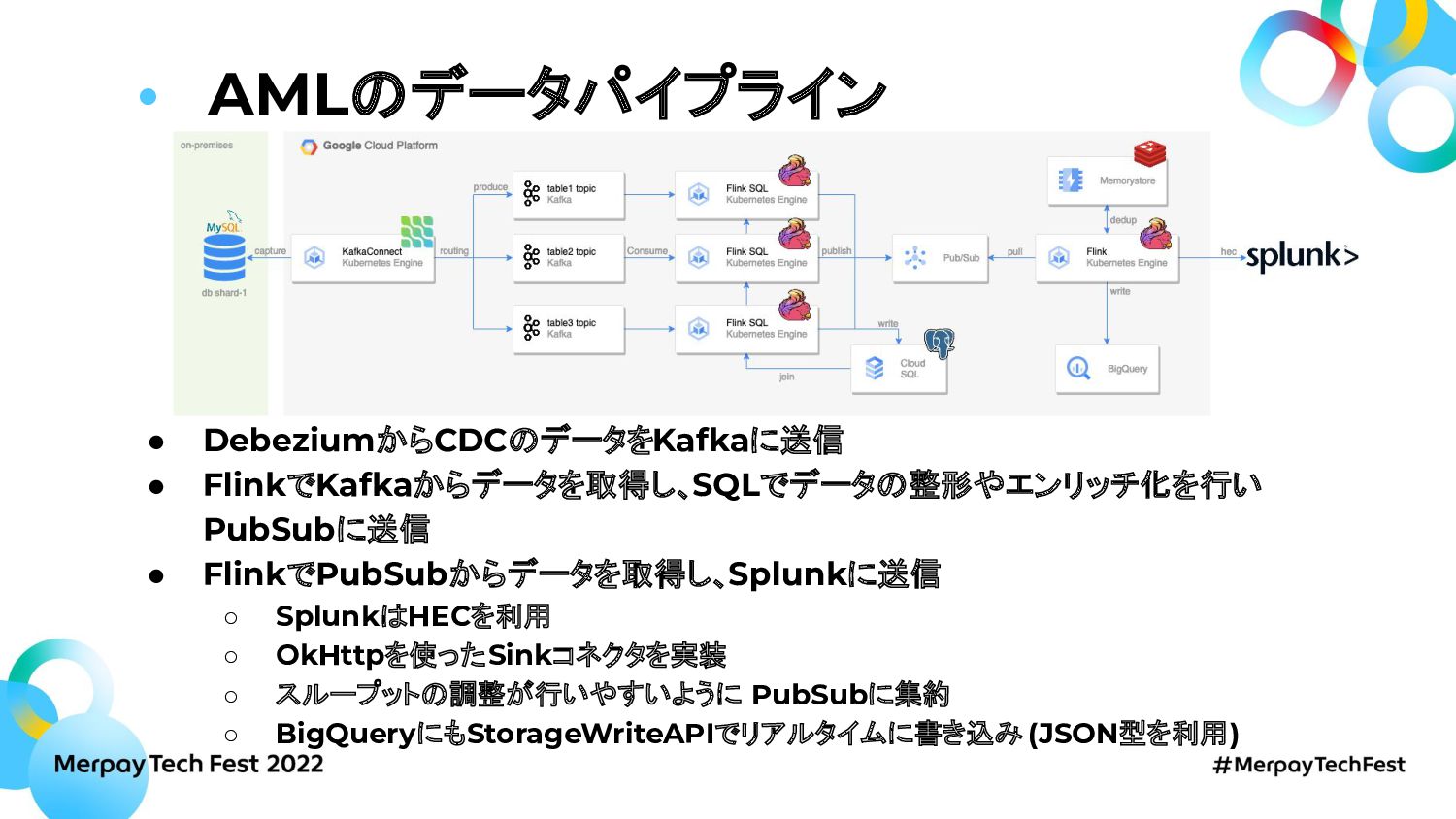
メルペイではKafkaとFlinkを使ったストリーミング処理の基盤を構築しています。AMLやCRM、マーケティング用の広告データのニアリアルタイム連携や分析用データのデータウェアハウスへのCDC連携等で利用しています。
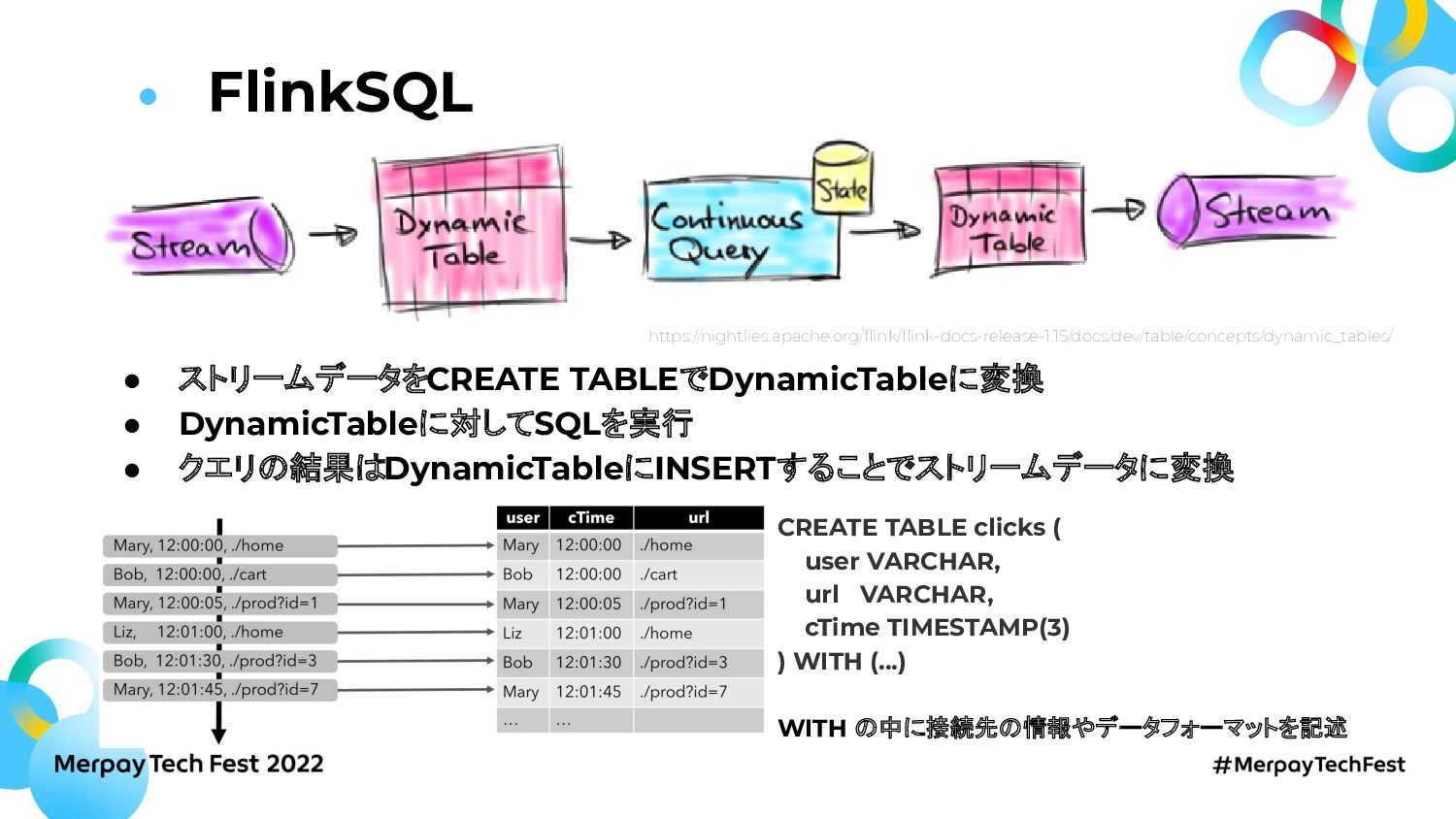
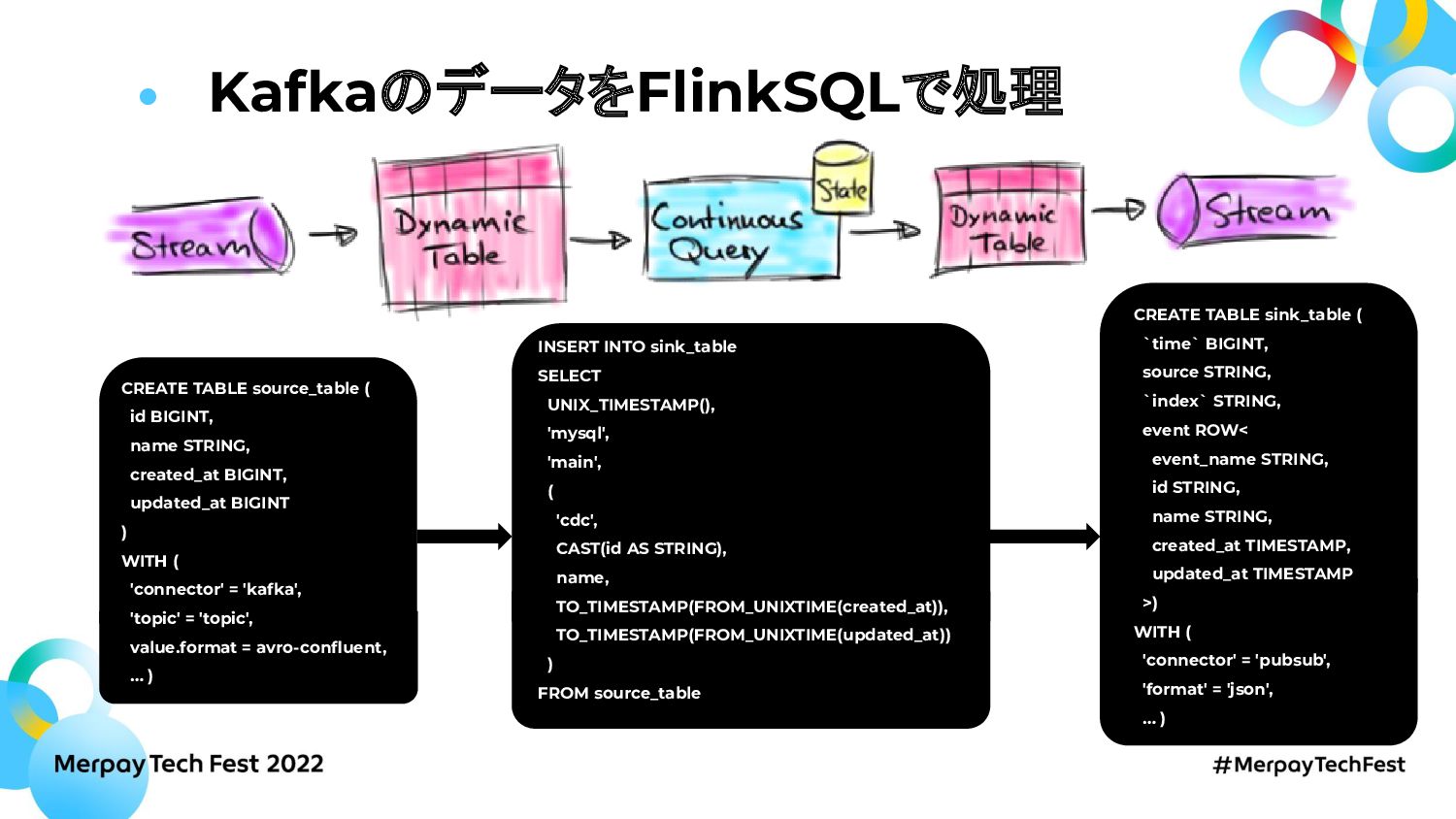
このセッションではDebeziumとConfluent Cloudを使ったCDC基盤とFlink SQL on k8sで構築したストリーミング処理基盤についてお話します。
------
Merpay Tech Fest 2022は3日間のオンライン技術カンファレンスです。
IT企業で働くソフトウェアエンジニアおよびメルペイの技術スタックに興味がある方々を対象に2022年8月23日(火)から8月25日(木)までの3日間、開催します。 Merpay Tech Festは事業との関わりから技術への興味を深め、プロダクトやサービスを支えるエンジニアリングを知れるお祭りです。 セッションでは事業を支える組織・技術・課題などへの試行錯誤やアプローチを紹介予定です。お楽しみに!
■イベント関連情報
- 公式ウェブサイト:https://events.merpay.com/techfest-2022/
- 申し込みページ:https://mercari.connpass.com/event/249428/
- Twitterハッシュタグ: #MerpayTechFest
■リンク集
- メルカリ・メルペイイベント一覧:https://mercari.connpass.com/
- メルカリキャリアサイト:https://careers.mercari.com/
- メルカリエンジニアリングブログ:https://engineering.mercari.com/blog/
- メルカリエンジニア向けTwitterアカウント:https://twitter.com/mercaridevjp
- 株式会社メルペイ:https://jp.merpay.com/
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}