I work as an Enabler (Engineer) in the UX/Creative field at the AI Task Forces. I originally worked as a backend engineer for Merpay's deferred payment service. My hobby is creating things using AI, and I'm active in a variety of activities including illustrations, singing, and novels.
to maximize the potential of both creators and customers. The UX AI project has been underway since 2024. The goal is to enable anyone to create a Mercari-like UX.
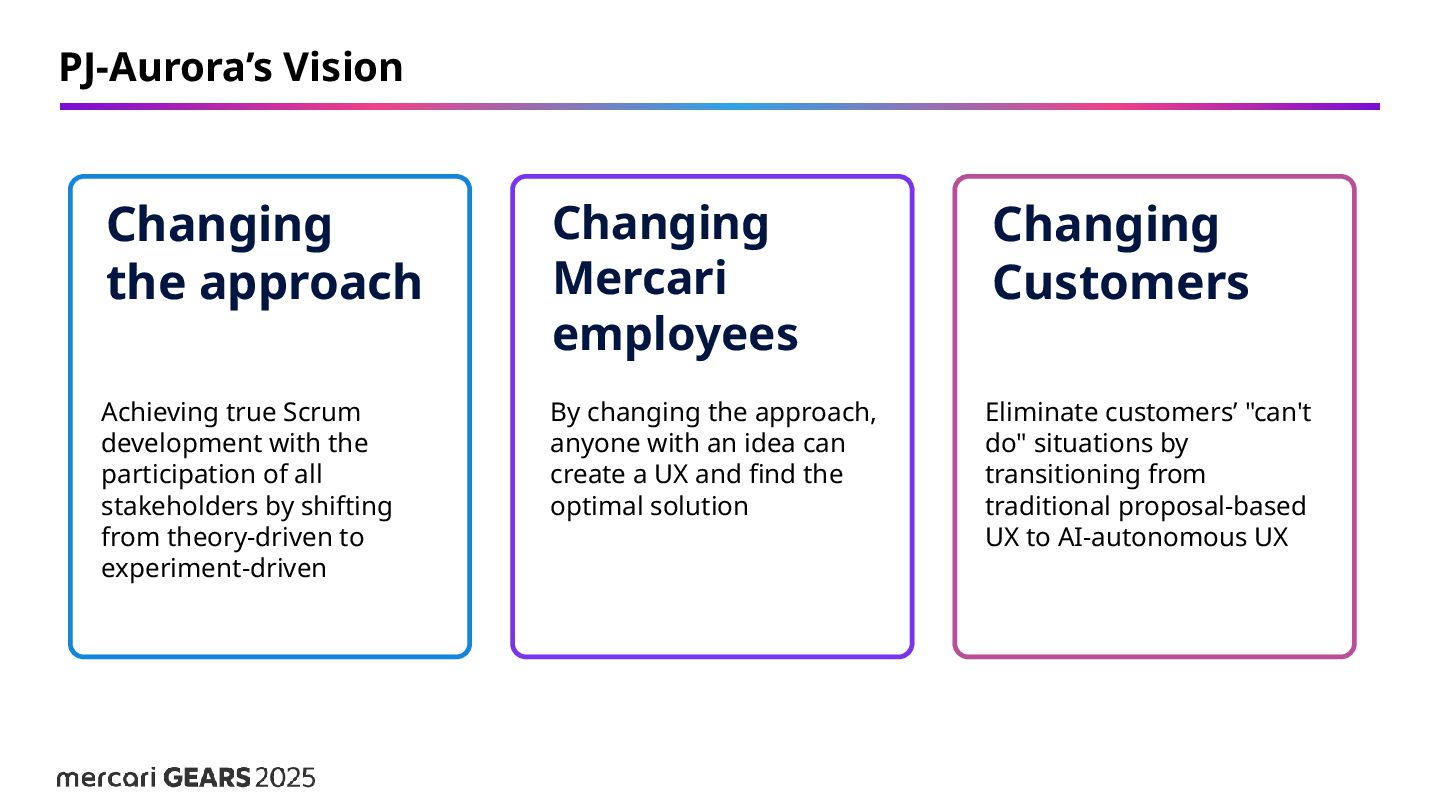
the participation of all stakeholders by shifting from theory-driven to experiment-driven Changing Mercari employees By changing the approach, anyone with an idea can create a UX and find the optimal solution Changing Customers Eliminate customers’ "can't do" situations by transitioning from traditional proposal-based UX to AI-autonomous UX
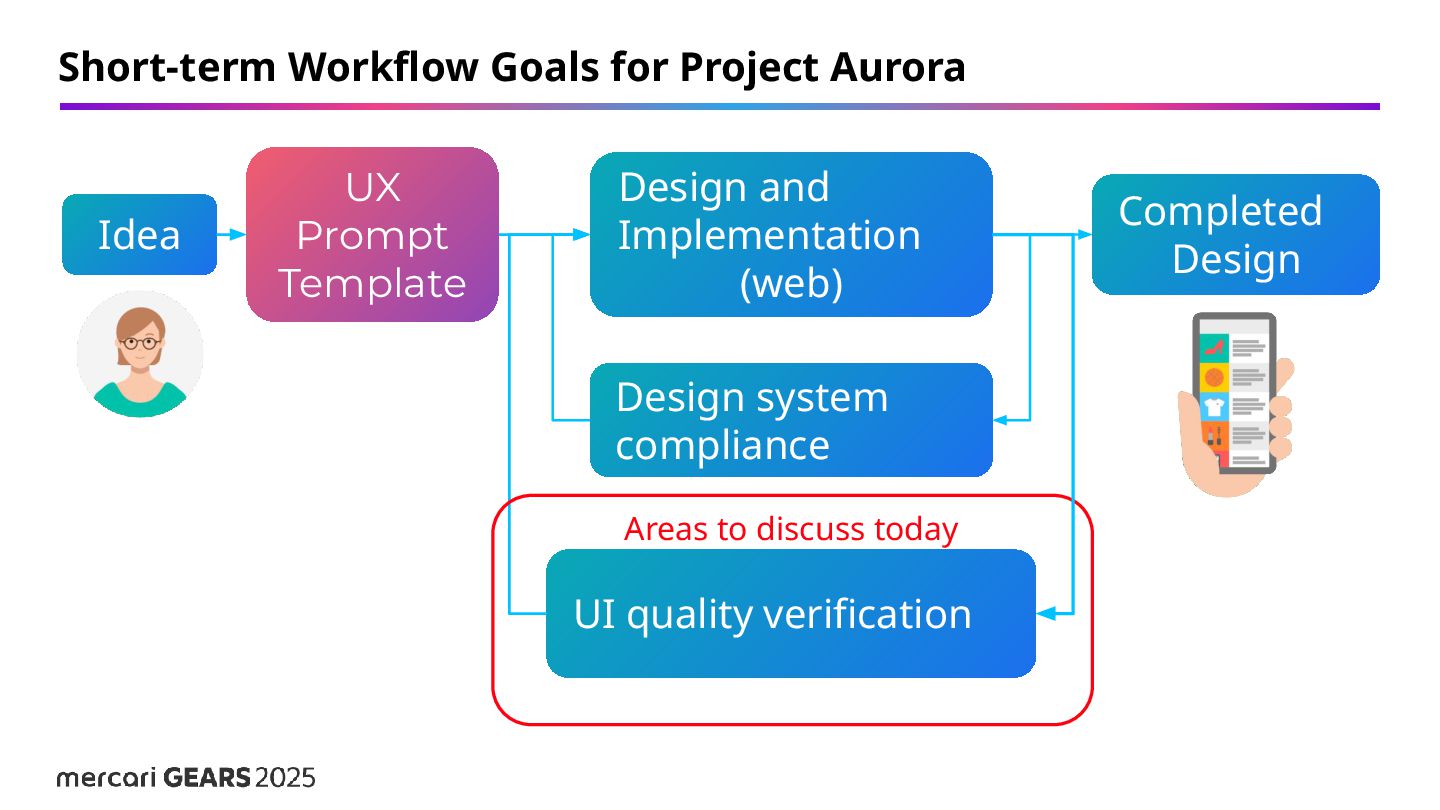
UI generation allows us to stand on the shoulders of giants. ◦ Examples: Figma Make, Coding Agent. • However, only Mercari can evaluate the “Mercari-ness.” (=Uniqueness as Mercari) ◦ Unique context ◦ Unique evaluation criteria ◦ Unique design philosophy
a Brand QA Agent to review the massively generated UI and content for Mercari-ness. • We believe that by interacting with the UI generation agent in the future, we will be able to continuously improve the accuracy of generation.
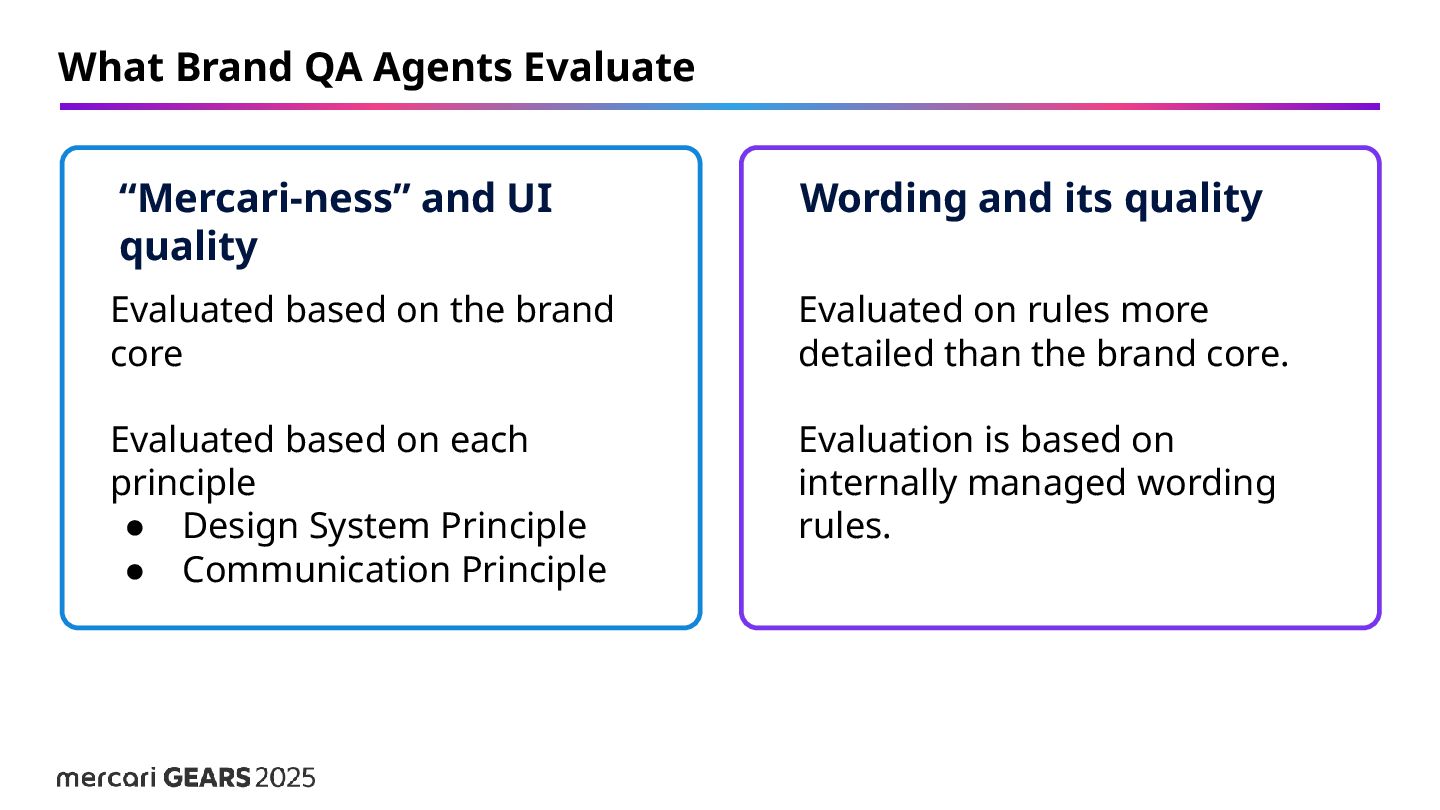
on the Brand Core that should be observed in daily customer communications • Communication Principle • Design System Principle Defining Mercari-ness: How do we measure “Mercari-ness”? Brand Core Personality "Mercari-ness" is defined by three personalities. These are the guidelines that serve as the starting point for creating all brand experiences. Sincerity
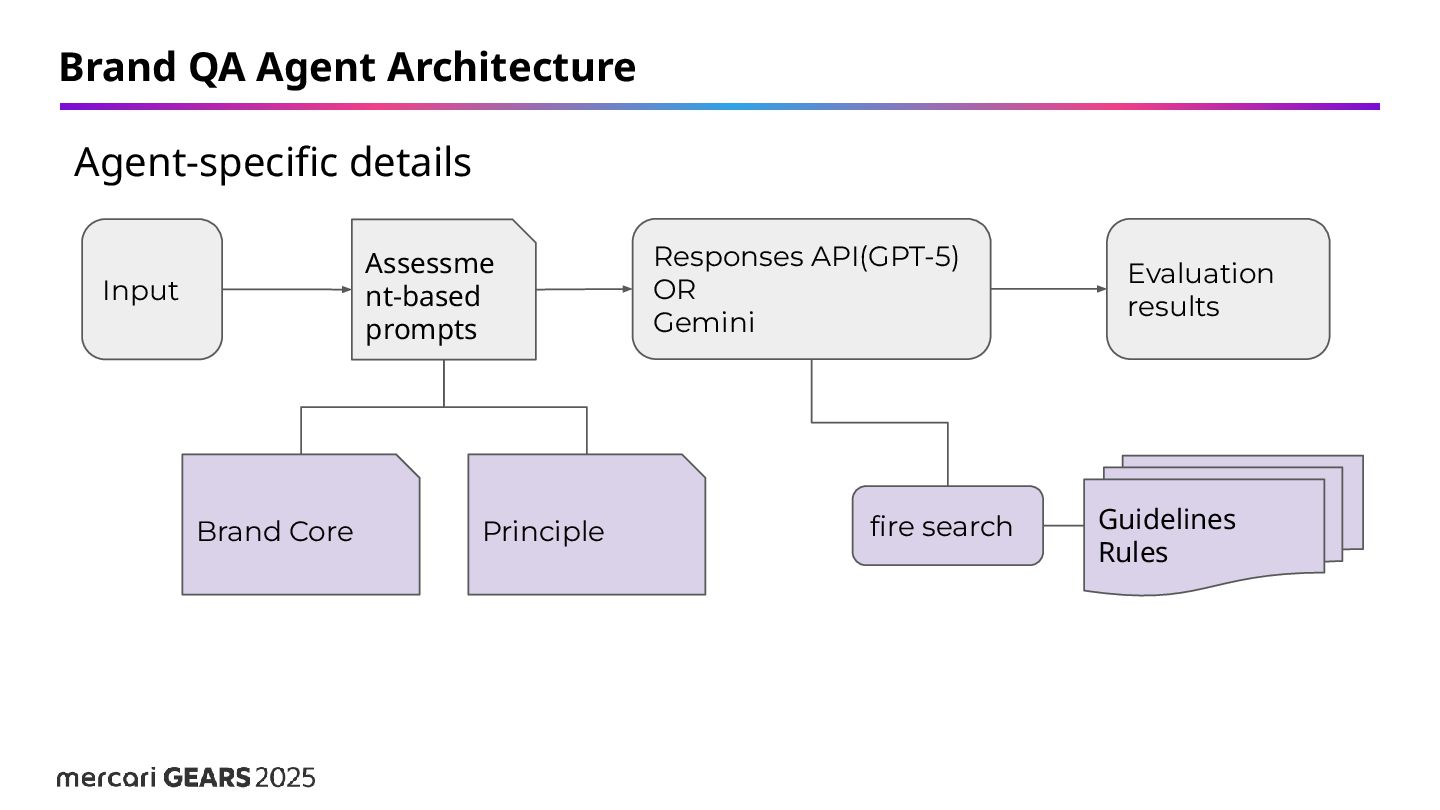
and its quality Evaluated based on the brand core Evaluated based on each principle • Design System Principle • Communication Principle Evaluated on rules more detailed than the brand core. Evaluation is based on internally managed wording rules.
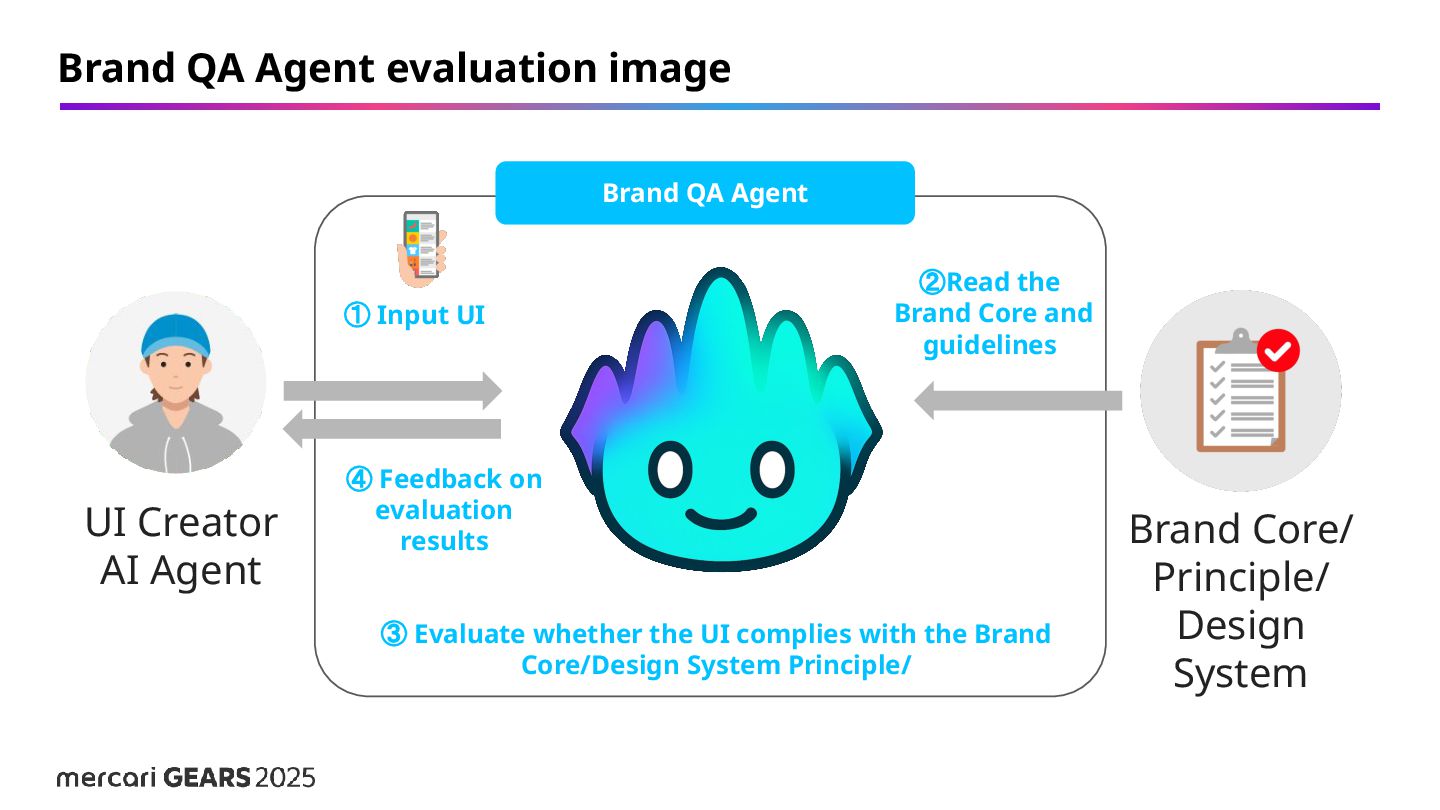
QA Agent ① Input UI ②Read the Brand Core and guidelines ④ Feedback on evaluation results ③ Evaluate whether the UI complies with the Brand Core/Design System Principle/ Brand QA Agent evaluation image
• Provides feedback on 21 items, including strengths, areas for improvement, and the severity of violations for each principle • Supports UI display of evaluation results and downloads in Markdown format
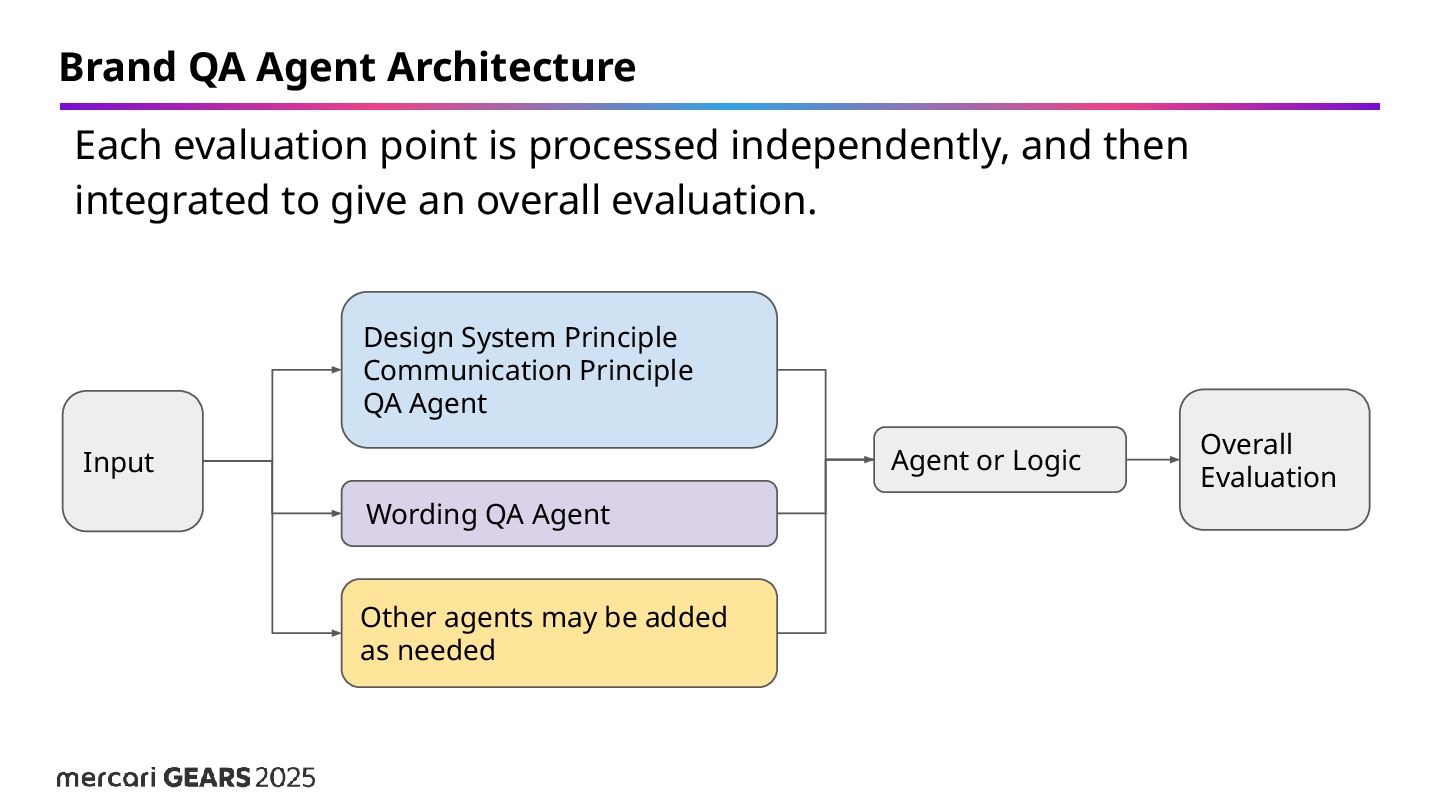
added as needed Input Wording QA Agent Agent or Logic Design System Principle Communication Principle QA Agent Each evaluation point is processed independently, and then integrated to give an overall evaluation.
Brand QA Agent • The brand core, principles, and guidelines are abstract and broad concepts. • We need to ensure that AI can correctly understand and evaluate them. • It's important that all Mercari UIs can be correctly evaluated using the same standards. Input UI Evaluation results Designer Review
core: Highly accurate and appropriate understanding • Presentation of evidence: Sufficient and specific • Clarity of comments: Some room for improvement, but generally understandable • Comprehensiveness: Covers almost all necessary aspects, with occasional omissions • Overall evaluation: The AI evaluation is already "fairly good" for practical use • Errors are at a level that a human could easily pick out and discard • Rated "good enough to be incorporated into a design review flow"
cannot be used for business purposes. • GPT-5 systems do not support temperature. • Accuracy must be maintained continuously even after agent updates. • A dedicated agent will be developed to compare consistency and perform continuous automatic evaluations.
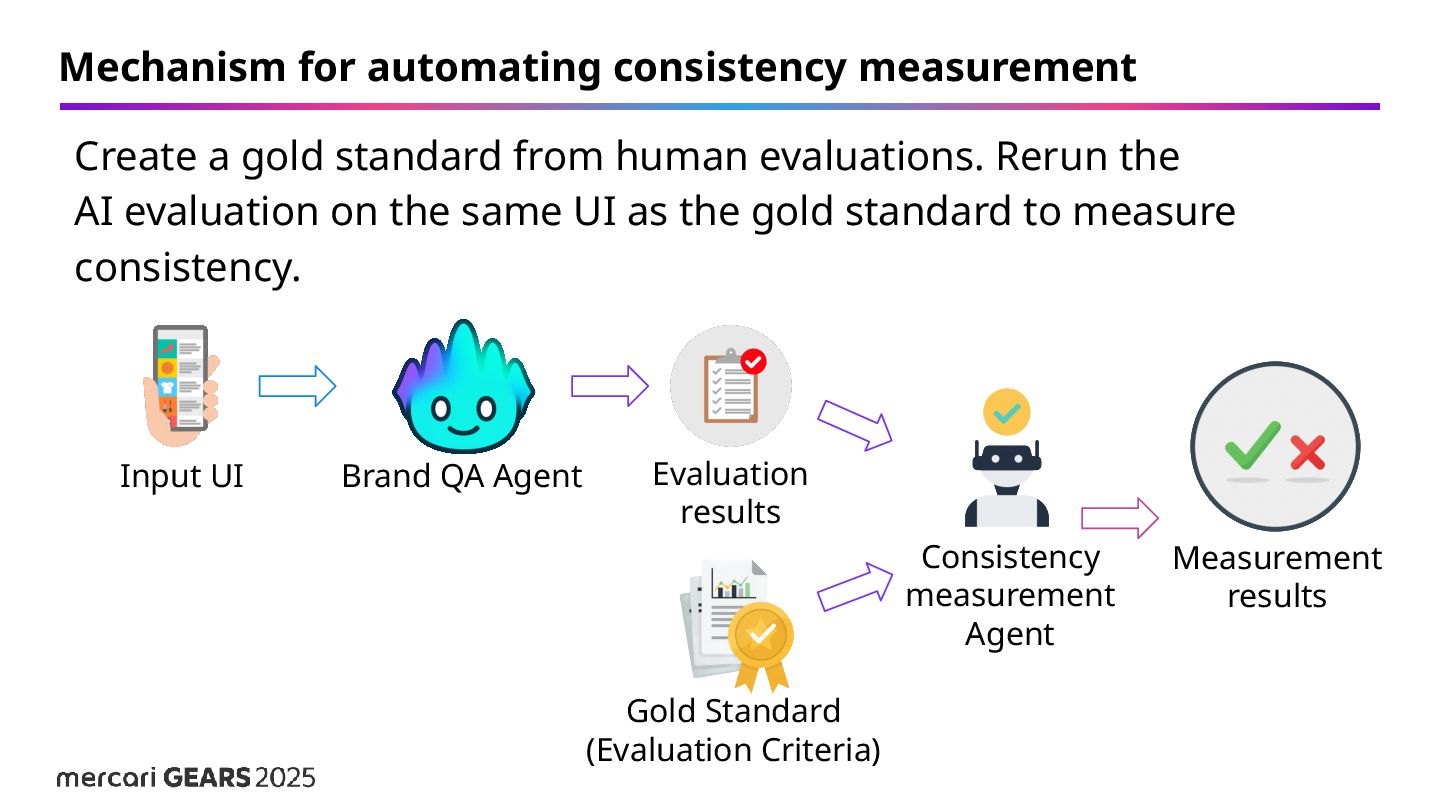
human evaluations. Rerun the AI evaluation on the same UI as the gold standard to measure consistency. Brand QA Agent Input UI Evaluation results Gold Standard (Evaluation Criteria) Consistency measurement Agent Measurement results
Standard (Evaluation Criteria) • First Test - 62% Consistency (After several iterations and refinements) • Seventh Test - 76% Consistency • Eighth Test - 79.5% Consistency • Ninth Test - 87% Consistency Consistency has steadily improved through model changes, prompt adjustments, and improvements to the comparison agent itself. We ultimately aim for a 95% consistency rate!
We've built a prototype of the evaluation agent! • The initial evaluation design is complete! • The validity of human-based AI quality evaluation has been completed! • The consistency evaluation match rate is good! What we'll do next • We'll design the system for actual use! • And now, feedback, improvements, and operation await! In other words...
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}