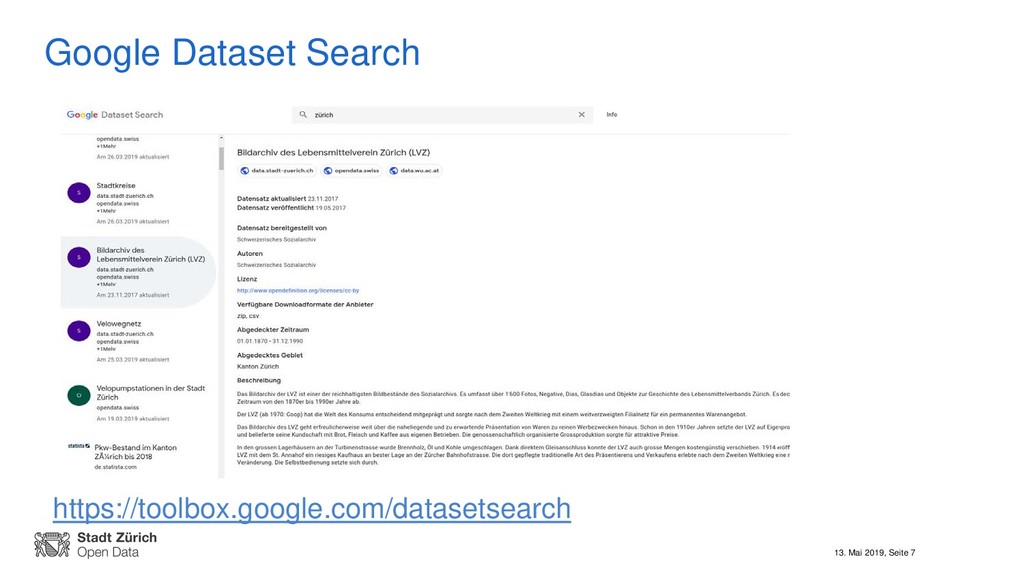
Einblick in die Google-Indexierung von Datasets – Dataset Search ist Beta – Keine Mehrsprachigkeit – Fehler beim crawlen (z.B. mehrere Quellen für ein Dataset, Umlaute falsch)
Suchmaschine? – Strukturierte Daten werden in Webseite des Datensatzes integriert Suchmaschinen-Crawler <scr i pt t ype=" appl i cat i on/ l d+j son" > { " @ gr aph" : [ { " @ i d" : " ht t ps: / / dat a. st adt - zuer i ch. ch/ dat aset / pd_st apo_hundenam en/ r esour ce/ 54bf 65f 9- ce69- 43de- a51a- 176d5d341071" , " @ t ype" : " schem a: Dat aDownl oad" , " schem a: cont ent Ur l " : " ht t ps: / / dat a. st adt - zuer i ch. ch/ dat aset / pd_st apo_hundenam en/ r esour ce/ 54bf 65f 9- ce69- 43de- a51a- 176d5d341071/ downl oad/ 20180305_hundenam en. csv" , " schem a: descr i pt i on" : " <p>Com m a- Separ at ed Val ues. W ei t er e I nf or m at i onen zu CSV f i nden Si e i n unser er Rubr i k W er kst at t unt er <a hr ef =\ " ht t ps: / / www. st adt - zuer i ch. ch/ por t al / de/ i ndex/ ogd/ wer kst at t / csv. ht m l \ " >I nf or m at i onen zu Dat enf or m at en. </ a></ p>" , " schem a: encodi ngFor m at " : " CSV" ,
können auch direkt Primärdaten angegeben werden (“Linked Data”) – Google hat experimentellen Support für CSVW (“CSV on the Web”) für tabellarische Daten
habe ich in der Extension ckanext-dcat implementiert – CSVW fehlt noch (!) – Aktivierung: – Evtl. Mapping für eigene Felder anpassen – Plugin “structured_data” aktivieren – Profit!
mit den Metadaten? – Die Bereitstellung als schema.org/Dataset hilft nicht nur Google (!) – Integration in klassische Suche ist nur eine Frage der Zeit – Implementation ist sehr einfach – Geringes Risiko – Daten werden potentiell besser gefunden und genutzt
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}