pd.DataFrame({ 'sentence1': ["A plane is taking off.", "A man is playing a large flute."], 'sentence2': ["An air plane is taking off.", "A man is playing a flute."], 'score': [5.00, 3.80] # 0から5の類似度スコア }) # 目的変数がfloatなので回帰問題と自動推論される predictor_similarity = MultiModalPredictor(label='score').fit(train_df_similarity) predictor_similarity.predict({ 'sentence1': ["A woman is playing the piano."], 'sentence2': ["A man is playing the guitar."] }) # > 2.35 同じAPIで分類と回帰の両方に対応できる柔軟性が魅力です。 46
Accurate AutoML for Structured Data." arXiv preprint arXiv:2003.06505 (2020). AutoGluon-TimeSeries: Shchur, Oleksandr, et al. "AutoGluon-TimeSeries: AutoML for Probabilistic Time Series Forecasting." The International Conference on Automated Machine Learning (AutoML), 2023. AutoGluon-Multimodal (AutoMM): Zhiqiang, Tang, et al. "AutoGluon-Multimodal (AutoMM): Supercharging Multimodal AutoML with Foundation Models", The International Conference on Automated Machine Learning (AutoML), 2024. 71
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
![画像分類 ( 続き) ステップ3: 予測と特徴量抽出 予測: 学習済みモデルで新しい画像のクラスを予測します。 image_path = test_data.iloc[0]['image']](https://files.speakerdeck.com/presentations/358495e56f4c4ad8904e18ca06d3f9b0/slide_43.jpg){kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
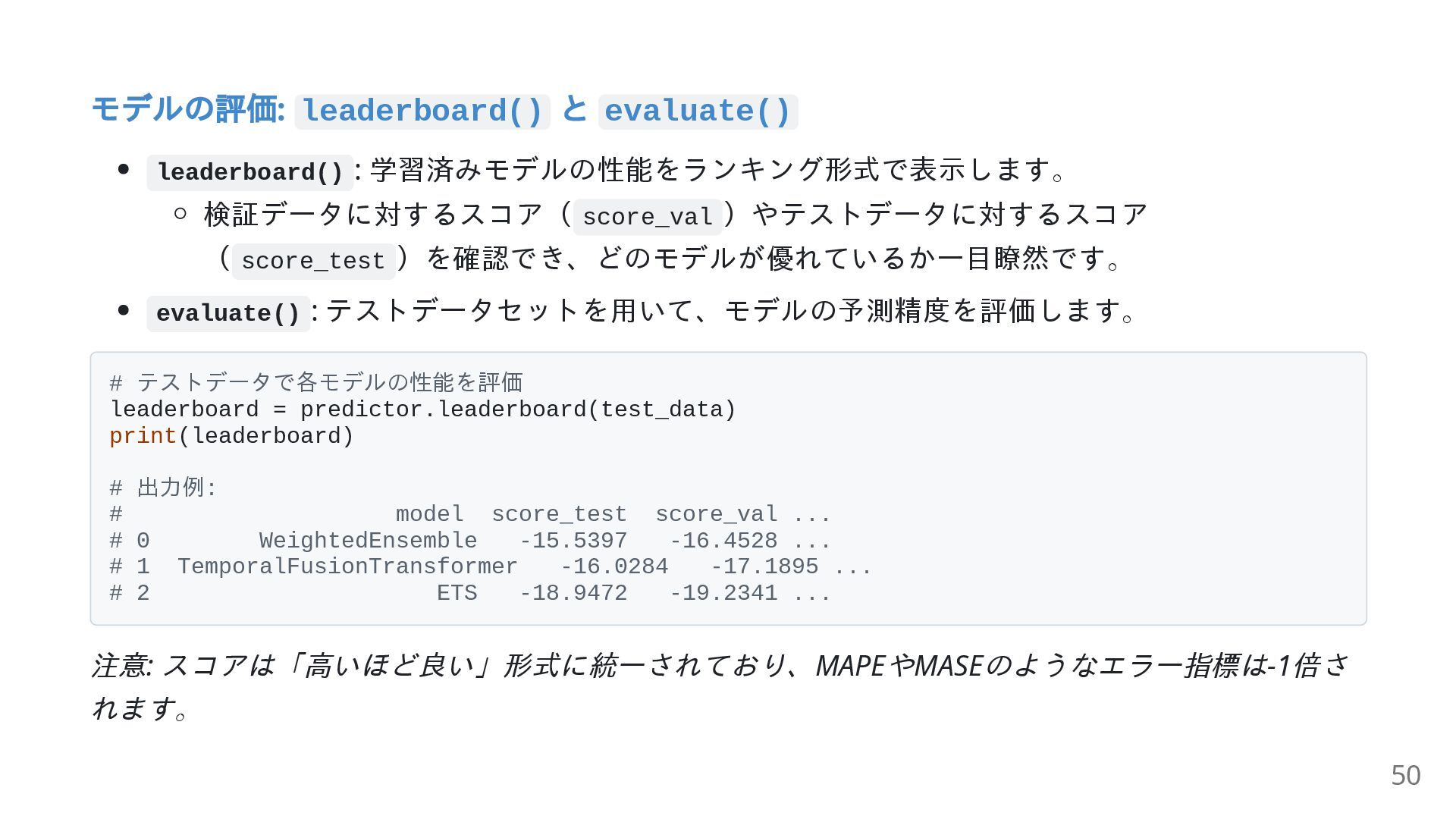{kind=link}
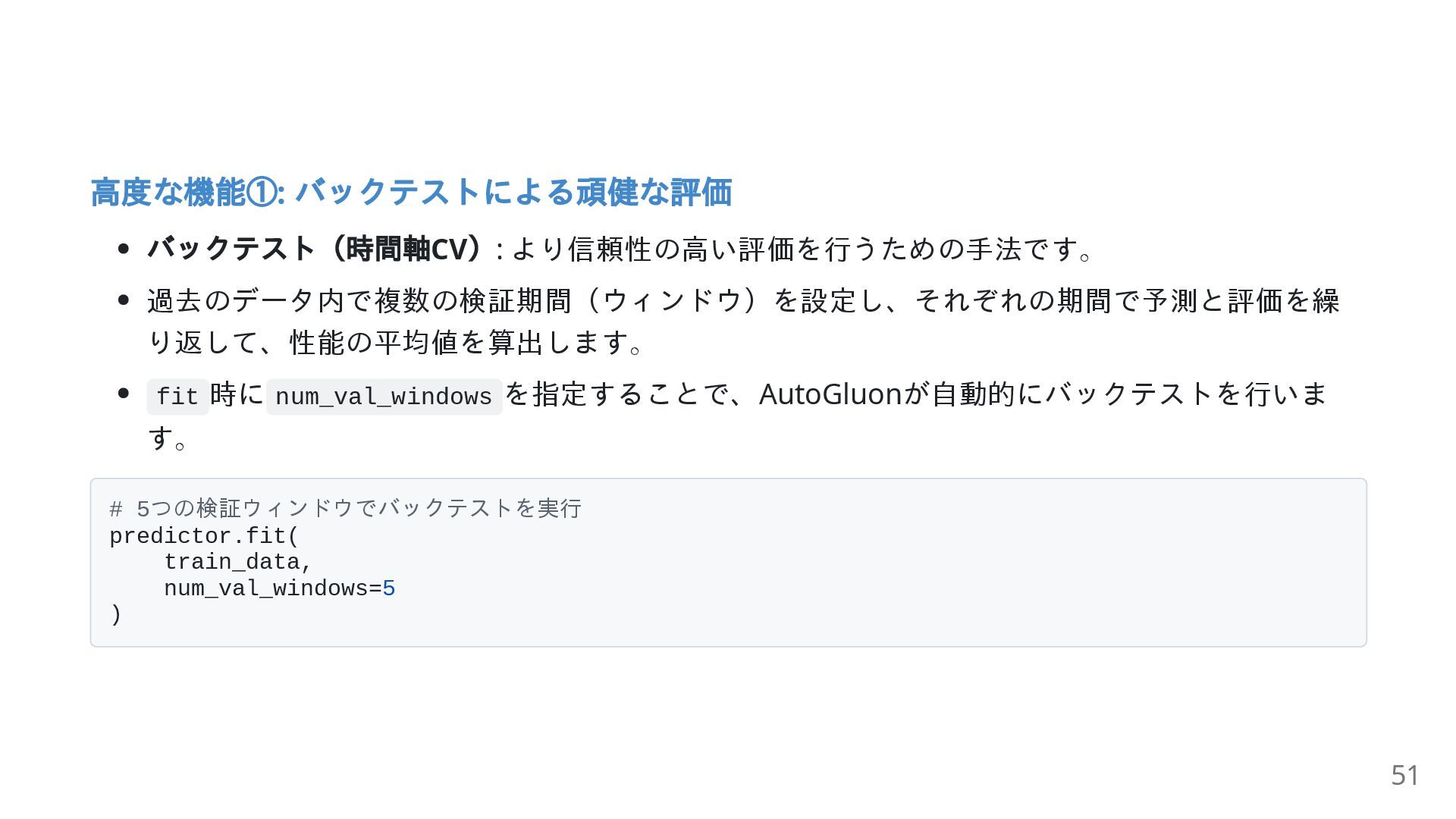{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
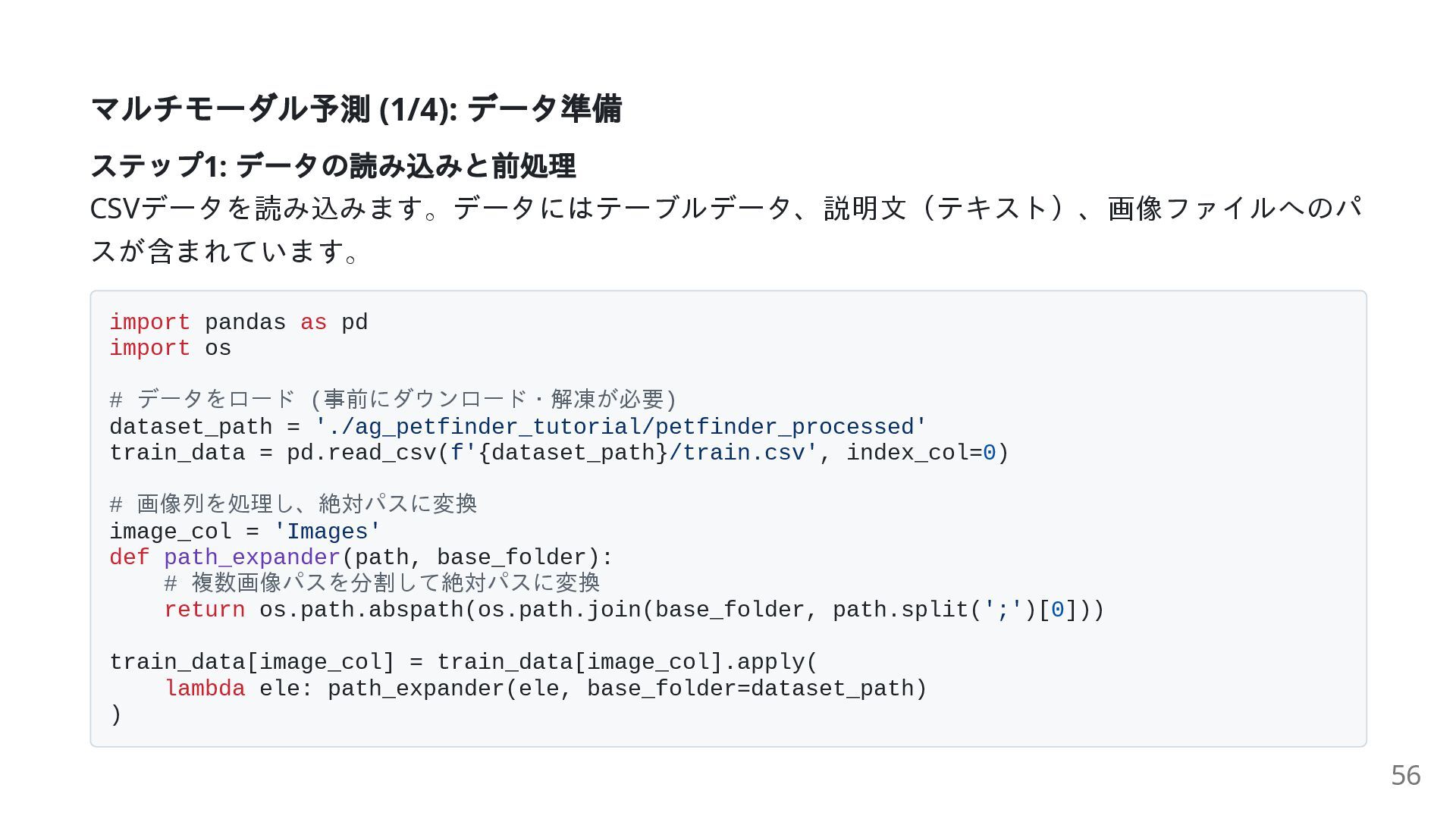{kind=link}
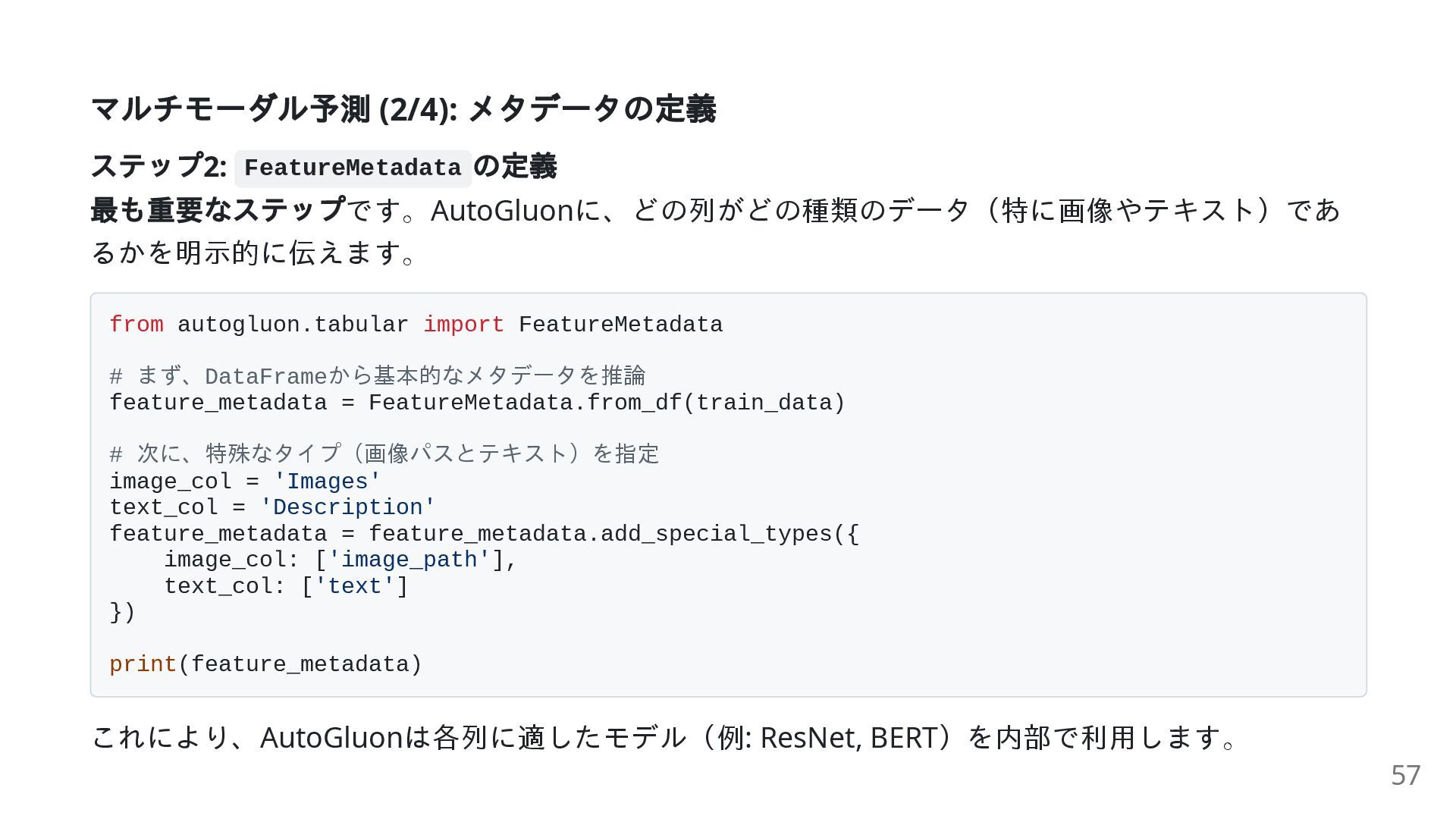{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}