Upgrade to Pro
— share decks privately, control downloads, hide ads and more …
Speaker Deck
Features
Speaker Deck
PRO
Sign in
Sign up for free
Search
Search
2024 眼科AIコンテスト手法解説スライド 第5回日本眼科AI学会総会
Search
Makoto Koyama
December 03, 2024
Technology
900
0
Share
Embed
Copy iframe code
Copy JS code
Copy link
Start on current slide
2024 眼科AIコンテスト手法解説スライド 第5回日本眼科AI学会総会
少しでも皆様のお役に立てる部分がありましたら幸いです。
Makoto Koyama
December 03, 2024
Other Decks in Technology
See All in Technology
事業価値を⽣み出すSREへ SREが担うべき意思決定の5層
kenta_hi
2
2.2k
「ちゃんとやっている」は独りよがりだった ― 不安に寄り添うインシデント対応へ / Towards incident response that addresses anxieties
chmikata
1
3.7k
小さいから、全部わかる。— 常駐AI "xangi" のすすめ
sugupoko
0
270
金融の未来を考える / Thinking About the Future of Finance
ks91
PRO
0
180
そのタスクオンスケですか?
poropinai1966
0
140
End-to-Endで考える信頼性 — LINEアプリにおける クライアント開発×SRE連携の実践
maruloop
4
3.1k
ヘルスケア領域における AI 活用と その安全性担保のための取り組み (Leveraging AI in Healthcare and Our Efforts to Ensure Its Safety) - Google I/O Extended Tokyo 2026, July 11, 2026
zettaittenani
0
180
CSに"SLO"は要らない、経営層に"99.9%"は伝わらない - SREを全社に"翻訳"する3原則
cscengineer
PRO
1
3.6k
オブザーバビリティ、本当に活用できてる? 〜API連携×生成AIで成熟度を自動評価〜
dmmsre
1
2.2k
AIと共生する開発者プラットフォーム:バクラクのモノレポ×マイクロサービス基盤
sakajunquality
2
2.6k
Zoom2Youtube.Claude
kawaguti
PRO
3
460
依頼文化をやめる日 EM視点で語るPlatform EngineeringとInclusive SRE / Discussing Platform Engineering and Inclusive SRE from an EM's Perspective
shin1988
4
4.2k
Featured
See All Featured
Crafting Experiences
bethany
1
210
Building a Scalable Design System with Sketch
lauravandoore
463
34k
Data-driven link building: lessons from a $708K investment (BrightonSEO talk)
szymonslowik
1
1.2k
Rails Girls Zürich Keynote
gr2m
96
14k
Odyssey Design
rkendrick25
PRO
2
730
Discover your Explorer Soul
emna__ayadi
2
1.2k
Paper Plane (Part 1)
katiecoart
PRO
0
9.5k
Highjacked: Video Game Concept Design
rkendrick25
PRO
1
400
Navigating Team Friction
lara
192
16k
The Spectacular Lies of Maps
axbom
PRO
1
850
More Than Pixels: Becoming A User Experience Designer
marktimemedia
3
460
Facilitating Awesome Meetings
lara
57
7k
Transcript
古山誠(南子安眼科) E-mail:
[email protected]
眼科AIコンテスト 手法解説 Makoto Koyama (Minamikoyasu Eye Clinic) 第5回
日本眼科AI学会 (2024.12) 本資料には学会発表時の内容に加え、時間の関係で発表できなかった補足事項も含まれています
前処理 眼底写真の周辺の黒: モデルから見ると外れ値で 望ましくない 周辺の黒を中間色で 埋めて学習 • 写真を正方形に切り抜き • 画像もラベル側も全てz-score
normalization
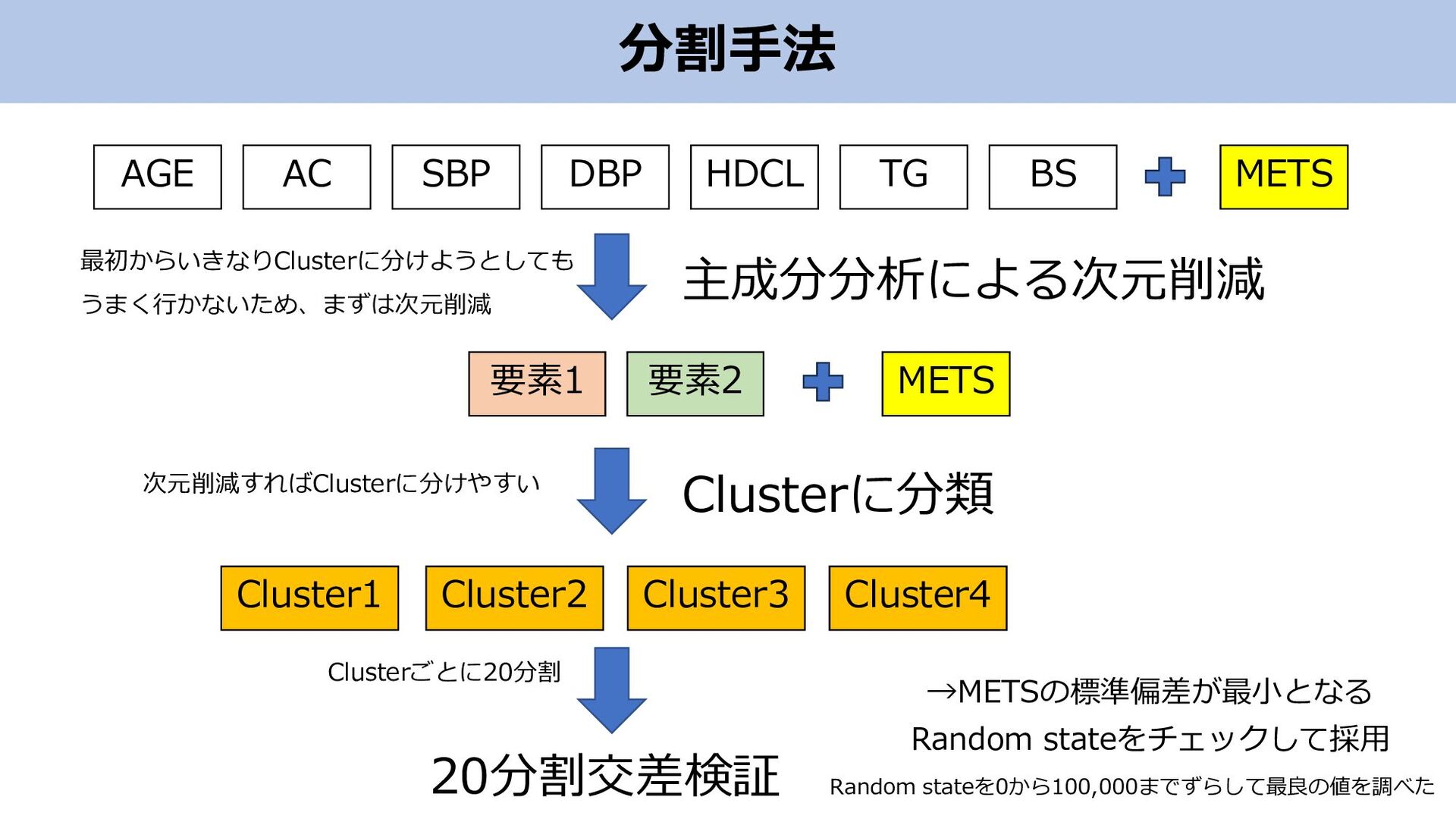
分割手法 • Train : Testを均一に分割することは大切 • METSだけでなく、他の要素も均等に分割したい
分割手法 AGE AC SBP DBP HDCL TG BS 主成分分析による次元削減 要素1
要素2 METS METS Clusterに分類 Cluster1 Cluster2 Cluster3 Cluster4 20分割交差検証 →METSの標準偏差が最小となる Random stateをチェックして採用 最初からいきなりClusterに分けようとしても うまく行かないため、まずは次元削減 次元削減すればClusterに分けやすい Clusterごとに20分割 Random stateを0から100,000までずらして最良の値を調べた
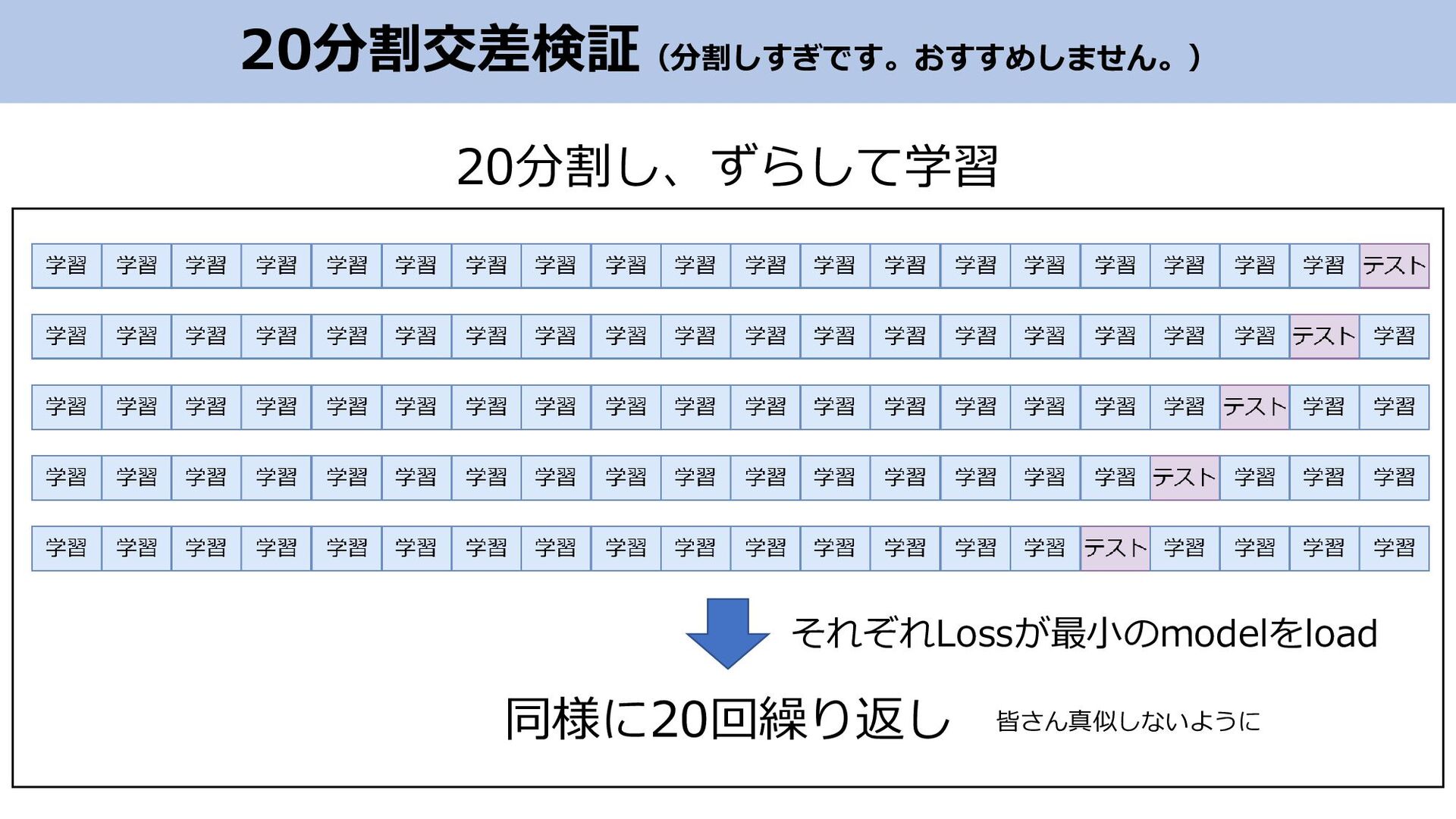
20分割交差検証(分割しすぎです。おすすめしません。) 同様に20回繰り返し 20分割し、ずらして学習 それぞれLossが最小のmodelをload 皆さん真似しないように
注意点 • 本来はTest結果による介入行為はご法度 (Test結果による早期終了や加重平均はダメです) • 実際の精度よりも見かけ上良くなってしまう • Validationを別に作成すればOK • でも今回はコンテストのため、Validation・Testを兼用
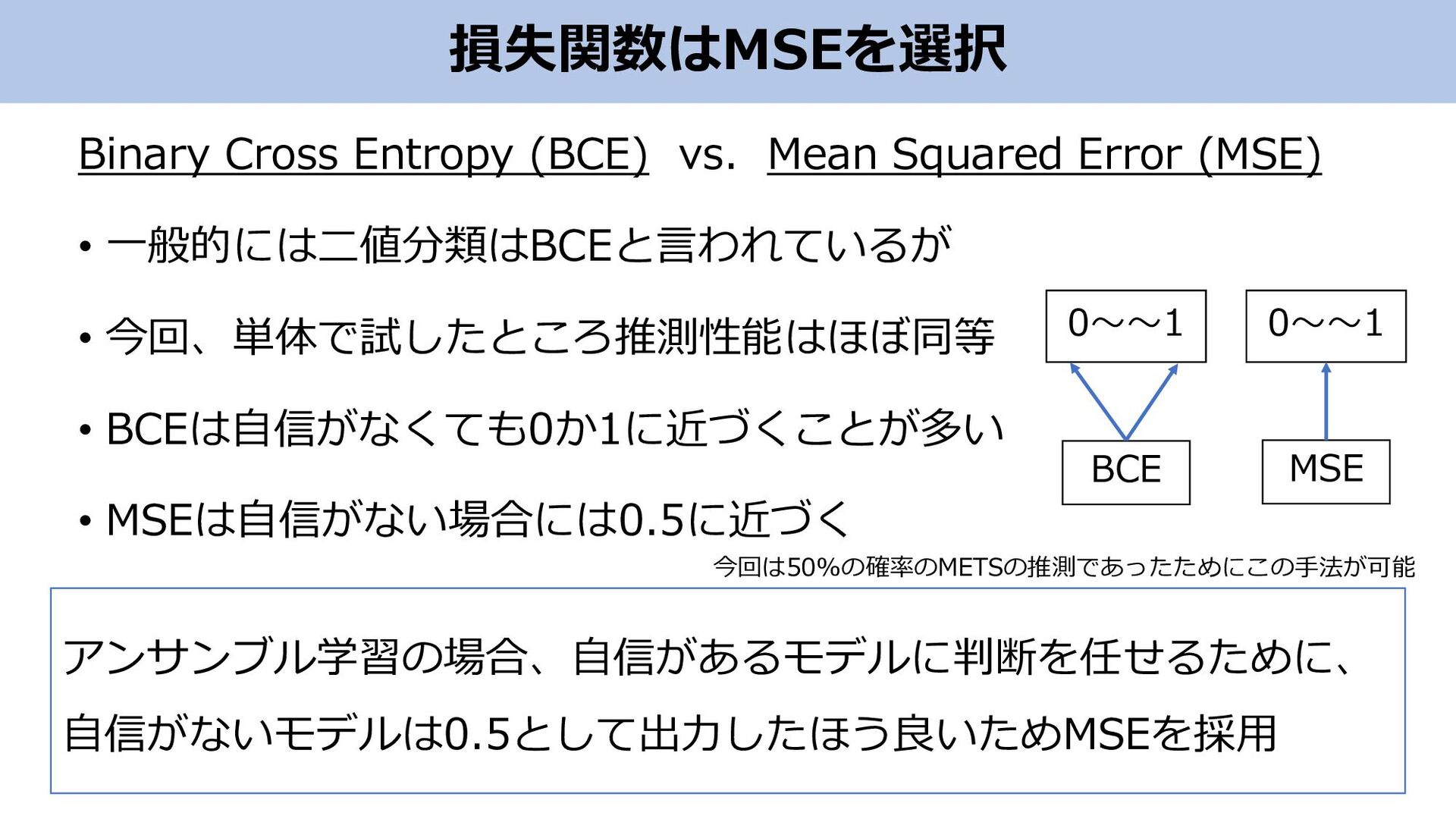
損失関数はMSEを選択 Binary Cross Entropy (BCE) vs. Mean Squared Error (MSE)
• 一般的には二値分類はBCEと言われているが • 今回、単体で試したところ推測性能はほぼ同等 • BCEは自信がなくても0か1に近づくことが多い • MSEは自信がない場合には0.5に近づく BCE MSE 0~~1 0~~1 アンサンブル学習の場合、自信があるモデルに判断を任せるために、 自信がないモデルは0.5として出力したほう良いためMSEを採用 今回は50%の確率のMETSの推測であったためにこの手法が可能
水増し •回転 •縮小拡大 •ランダムクロップ •上下反転 (学習時だけでなくTest時にも上下反転して平均値を算出)
アンサンブル学習 ブースティング(直列)+ バギング(並列)を複数採用
バギングのmix手法 • 推測性能の高いデータの比率を上げたい → 指数による加重平均を採用 NumPyを使用すれば少ない計算コスト&簡単 • 指数はMSE, MAE, Accuracy,
AUC score, Kappaをtry → Kappaにて最も良い値が得られた AUC scoreではなかったのは意外 • Kappaが最良となるn乗をn=1から100までtestし採用 バギング毎にn=1から100までずらして計算しmix
ハイパーパラメータの探索 • ハイパーパラメータの探索は自作プログラムを使用 • 自分の好きなように自由にいじくり回せるのが良い • 自分でいじっていると、このパラメータがどのような感じ なのかという感覚が徐々に養われていく • 全て自動で探索してしまうと、なかなか理解が深まらない
• でもRay Tuneなどのツールを使うのが普通かも これぞ機械学習の醍醐味 ツールを何度か使用してみましたが、面白くないので結局使わなくなってしまいました
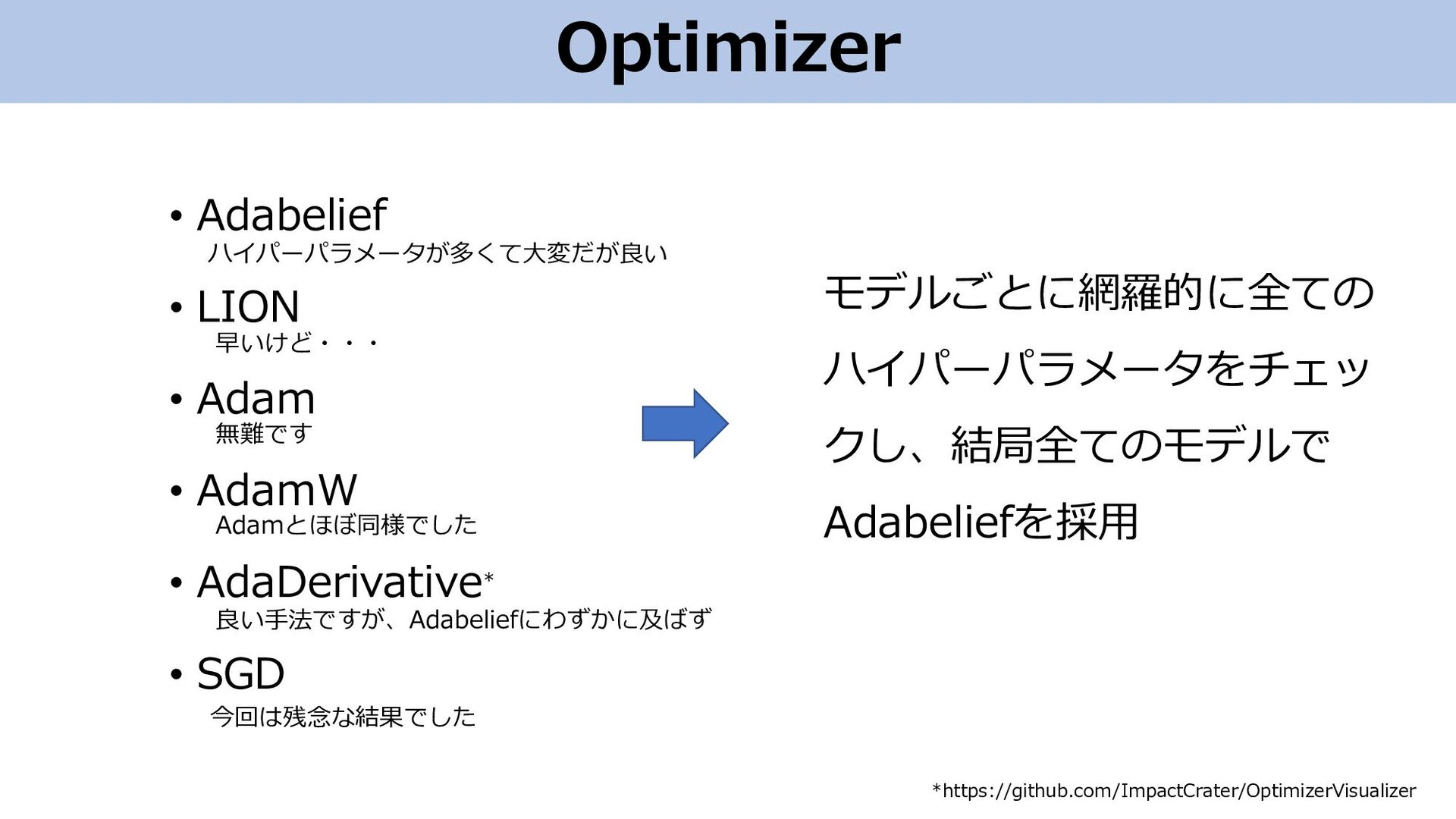
Optimizer • Adabelief • LION • Adam • AdamW •
AdaDerivative* • SGD モデルごとに網羅的に全ての ハイパーパラメータをチェッ クし、結局全てのモデルで Adabeliefを採用 無難です *https://github.com/ImpactCrater/OptimizerVisualizer 今回は残念な結果でした 良い手法ですが、Adabeliefにわずかに及ばず Adamとほぼ同様でした 早いけど・・・ ハイパーパラメータが多くて大変だが良い
Learning rate (LR) • 最初から大きな学習率だと、局所的な最適解に陥るriskあり • 最初は小さな学習率から開始し、徐々に学習率を上げる(up) • その後さらに学習率を下げて仕上げ(down) •
まずはLRを固定して最小値と最大値の適切な値を探索 • 次にupとdownのepoch数の最適な値を探索 • LRのcontrolはCyclicLRが便利
Early stopping • モデルごとに、最適なepoch数を検索 • Testの性能による早期終了(early stopping)を使用 • Epochごとにモデルを保存 •
Testで最良のKappaが得られたモデルを読み込み使用 注意:本来はvalidationとtestに分ける必要があります
モデル選択 PyTorchのtimmを使用し、SOTAの上位モデルを一通りチェック • eva02_base_patch14_448.mim_in22k_ft_in22k_in1k ( ) • swinv2_large_window12to16_192to256.ms_in22k_ft_in1k ( )
• tf_efficientnet_b5.ns_jft_in1k ( ) の3つを主モデルとして採用 eva swin eff RETFoundやRET-CLIPも採用すべきでした サンプル数の関係か、さらに大きいモデルでも同様の結果
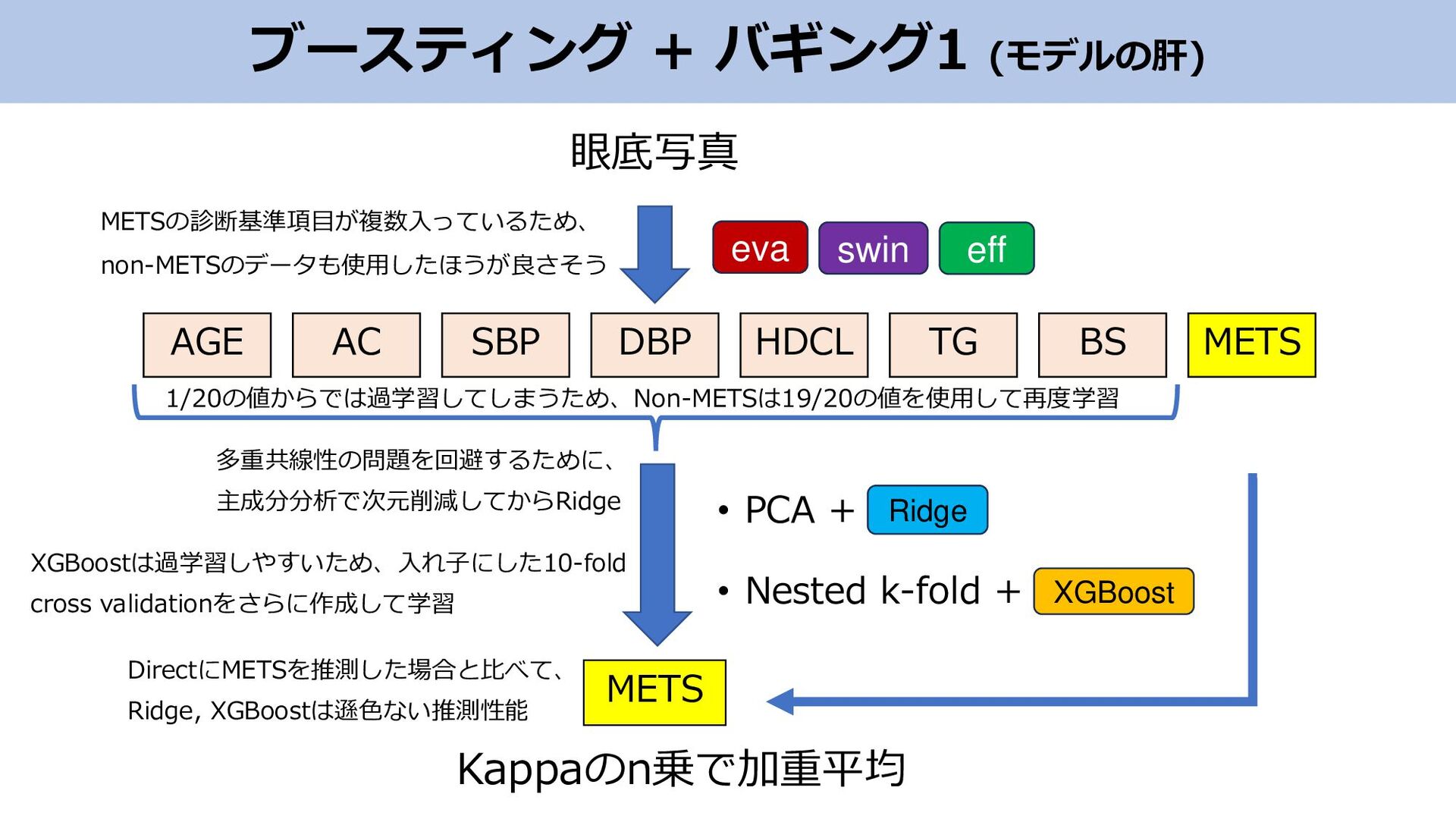
ブースティング + バギング1 (モデルの肝) • PCA + • Nested k-fold
+ AGE AC SBP DBP HDCL TG BS METS METS Kappaのn乗で加重平均 swin eva eff Ridge XGBoost 眼底写真 多重共線性の問題を回避するために、 主成分分析で次元削減してからRidge XGBoostは過学習しやすいため、入れ子にした10-fold cross validationをさらに作成して学習 1/20の値からでは過学習してしまうため、Non-METSは19/20の値を使用して再度学習 METSの診断基準項目が複数入っているため、 non-METSのデータも使用したほうが良さそう DirectにMETSを推測した場合と比べて、 Ridge, XGBoostは遜色ない推測性能
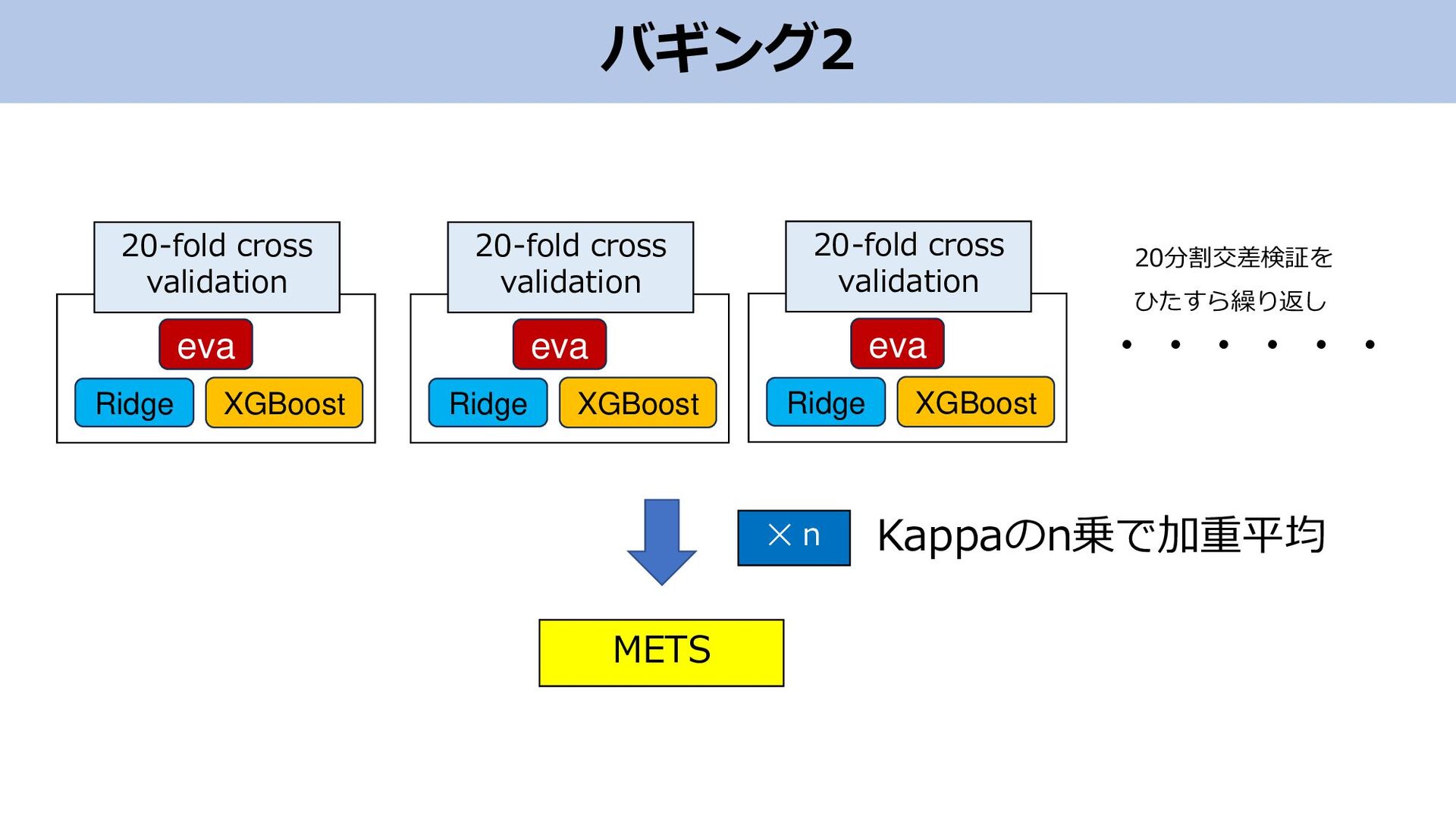
バギング2 Kappaのn乗で加重平均 ・・・・・・ eva Ridge XGBoost 20-fold cross validation ✕
n METS eva Ridge XGBoost 20-fold cross validation eva Ridge XGBoost 20-fold cross validation 20分割交差検証を ひたすら繰り返し
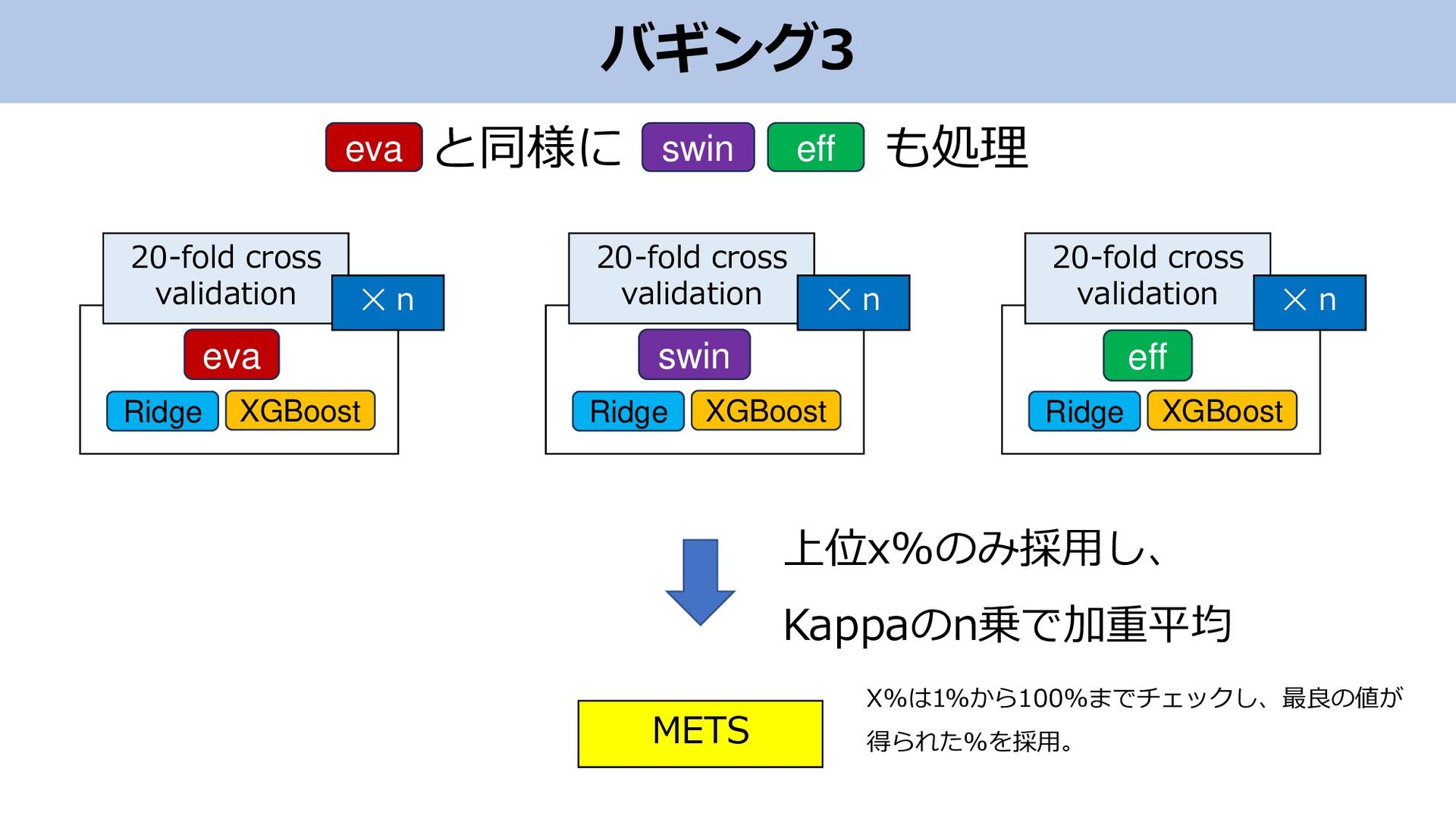
バギング3 METS 上位x%のみ採用し、 Kappaのn乗で加重平均 eva Ridge XGBoost 20-fold cross validation
✕ n Ridge XGBoost 20-fold cross validation ✕ n swin Ridge XGBoost 20-fold cross validation ✕ n eff と同様に も処理 eva swin eff X%は1%から100%までチェックし、最良の値が 得られた%を採用。
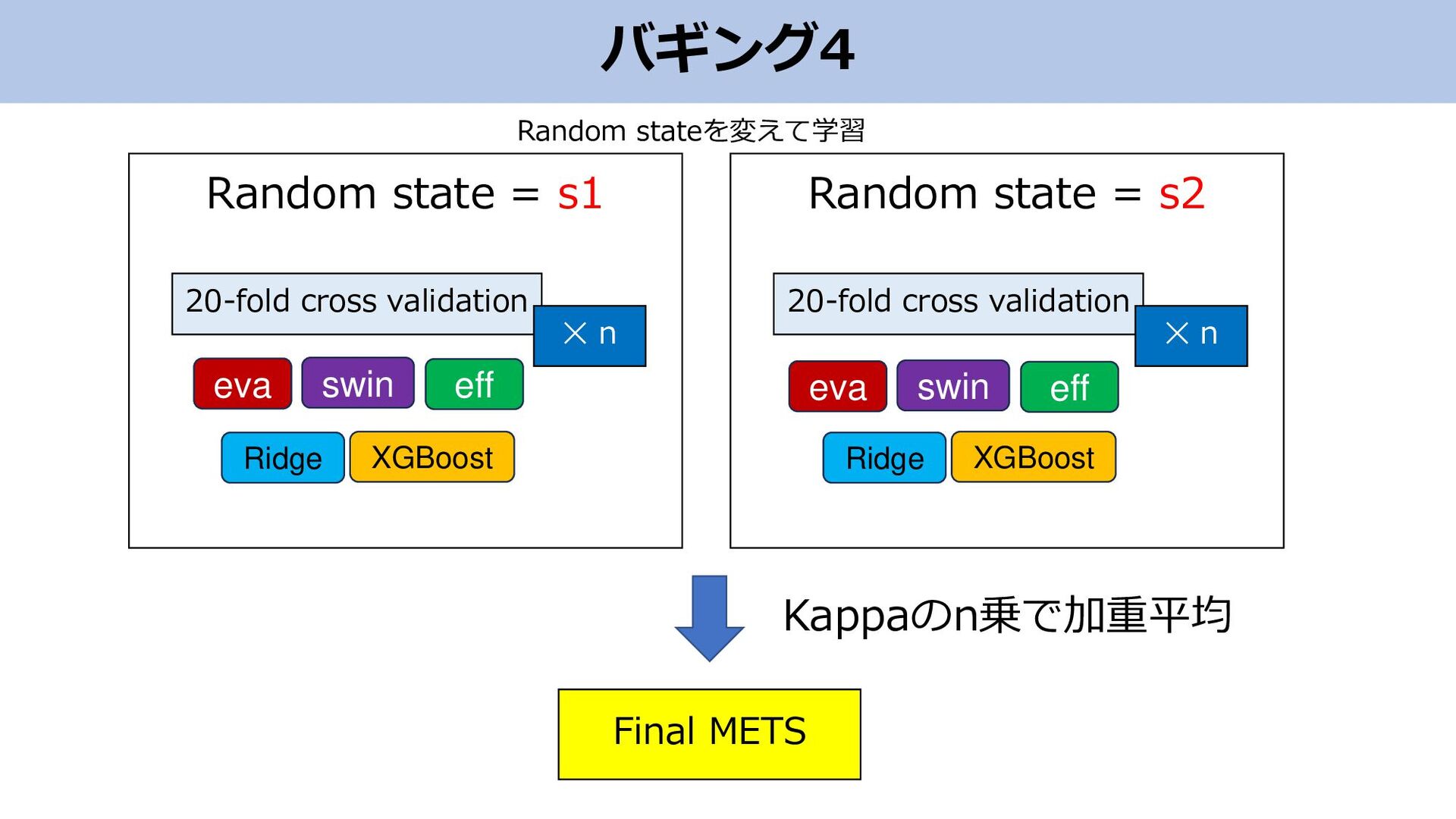
バギング4 Final METS Random state = s1 Kappaのn乗で加重平均 swin eva
eff Ridge XGBoost 20-fold cross validation ✕ n Random state = s2 Ridge XGBoost 20-fold cross validation ✕ n swin eva eff Random stateを変えて学習
反省点 • 手元の試算では正答率80% → 実際は67% (驚きでした) • 20分割交差検証で、分割に偏りが生じた可能性が高い • 分割しすぎて自滅した感じ
• ValidationとTestに分けていれば気付いたはず • まだまだ未熟であることを痛感 → この経験を次に活かしていきます
最後に • 私にAIの世界へ入るきっかけを与えて頂いたのは、前回の眼科AIコンテストでした。 • 単なるコンピュータ大好き開業医から、コンピュータとAIいじりが大好きな開業医へと 変化しました。 • AIを利用したシステムを開発し、より良い緑内障診療ができるように試行錯誤中です。 • 共同研究を行って頂いておられる先生や関係者の方々にはいつも感謝しております。
• また、このような大変貴重な学習の機会を与えて頂きました、眼科AI学会の関係者の皆 様方には深く感謝をいたします。
![古山誠(南子安眼科) E-mail:[email protected] 眼科AIコンテスト 手法解説 Makoto Koyama (Minamikoyasu Eye Clinic) 第5回](https://files.speakerdeck.com/presentations/9dccae496a664af990da4bb40a0e094c/slide_0.jpg){kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}