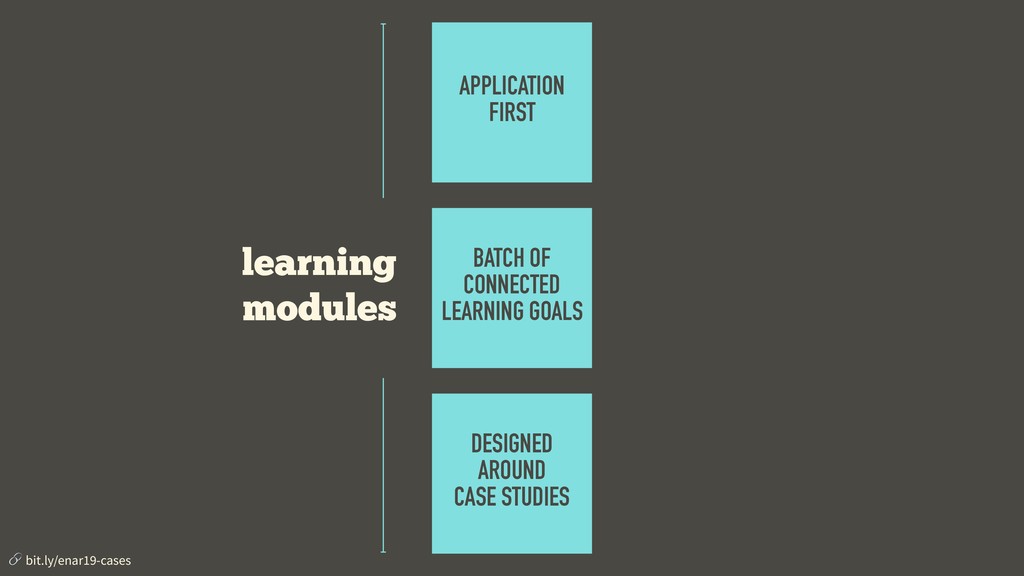
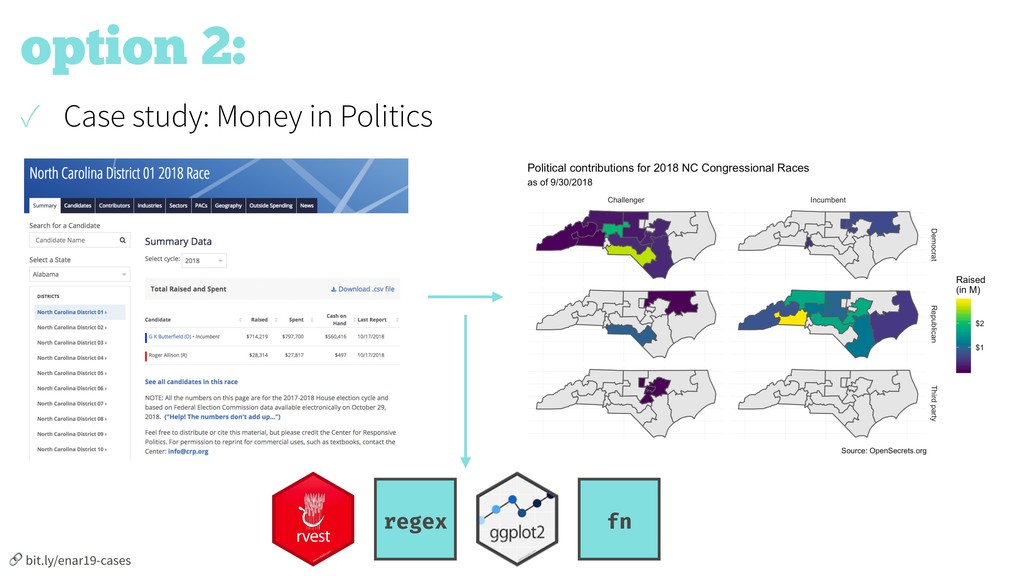
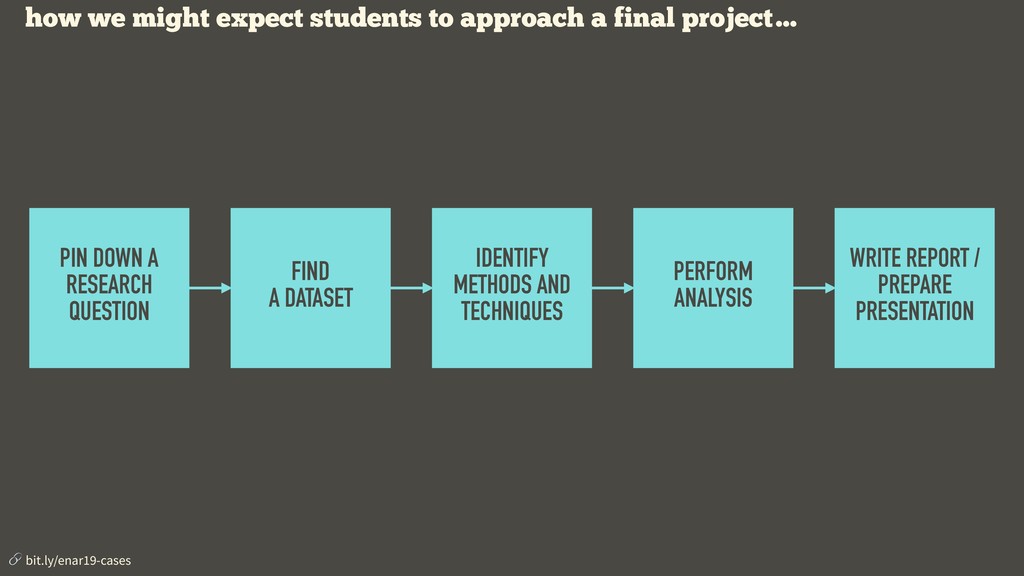
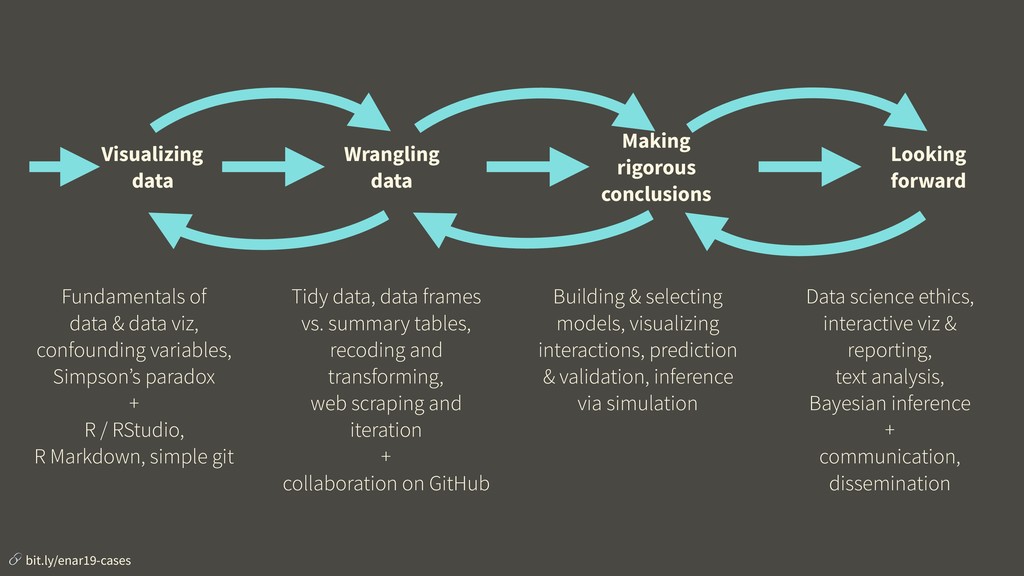
Interest in data science is surging, which means nowadays it’s pretty easy to fill the seats in an introductory data science class. But how do we effectively take the students through a challenging curriculum once they are in the class? We argue that the answer is an application first approach where the curriculum is divided into learning modules, each covering a batch of connected learning goals and designed around a case study. In this talk we present the curriculum for such a course intended for an audience of Duke University students with little to no computing or statistical background, and focuses on data wrangling, exploratory data analysis, data visualization, and effective communication. This course serves not as a first and thorough exposure to computing essentials for data science (including programming with R, reproducibility with R Markdown, and version control and collaboration with git/GitHub) but also as a gateway for the statistical science major. We will discuss in detail the course design philosophy and pedagogical considerations as well as give examples from the case studies used in the course.
![mine-cetinkaya-rundel [email protected] @minebocek mine çetinkaya-rundel duke university + rstudio intro](https://files.speakerdeck.com/presentations/395d6f44ec9b40ee9713eeb17fe15616/slide_0.jpg){kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
![mine-cetinkaya-rundel [email protected] @minebocek mine çetinkaya-rundel duke university + rstudio intro](https://files.speakerdeck.com/presentations/395d6f44ec9b40ee9713eeb17fe15616/slide_31.jpg){kind=link}