22新卒技術研修で実施したAI研修の講義資料(data & training編)です。
ハンズオン用リポジトリ
https://github.com/nami73b/machine-learning-notebooks
<<AI研修資料一覧>>
#01 イントロダクション
https://speakerdeck.com/mixi_engineers/2022-ai-training-number-01-introduction
#02 data & training編
https://speakerdeck.com/mixi_engineers/2022-ai-training-number-02-data-and-training
#03 Deployment編
https://speakerdeck.com/mixi_engineers/2022-ai-training-number-03-deployment
#04 サービスへの導入編
https://speakerdeck.com/mixi_engineers/2022-ai-training-number-04-service
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
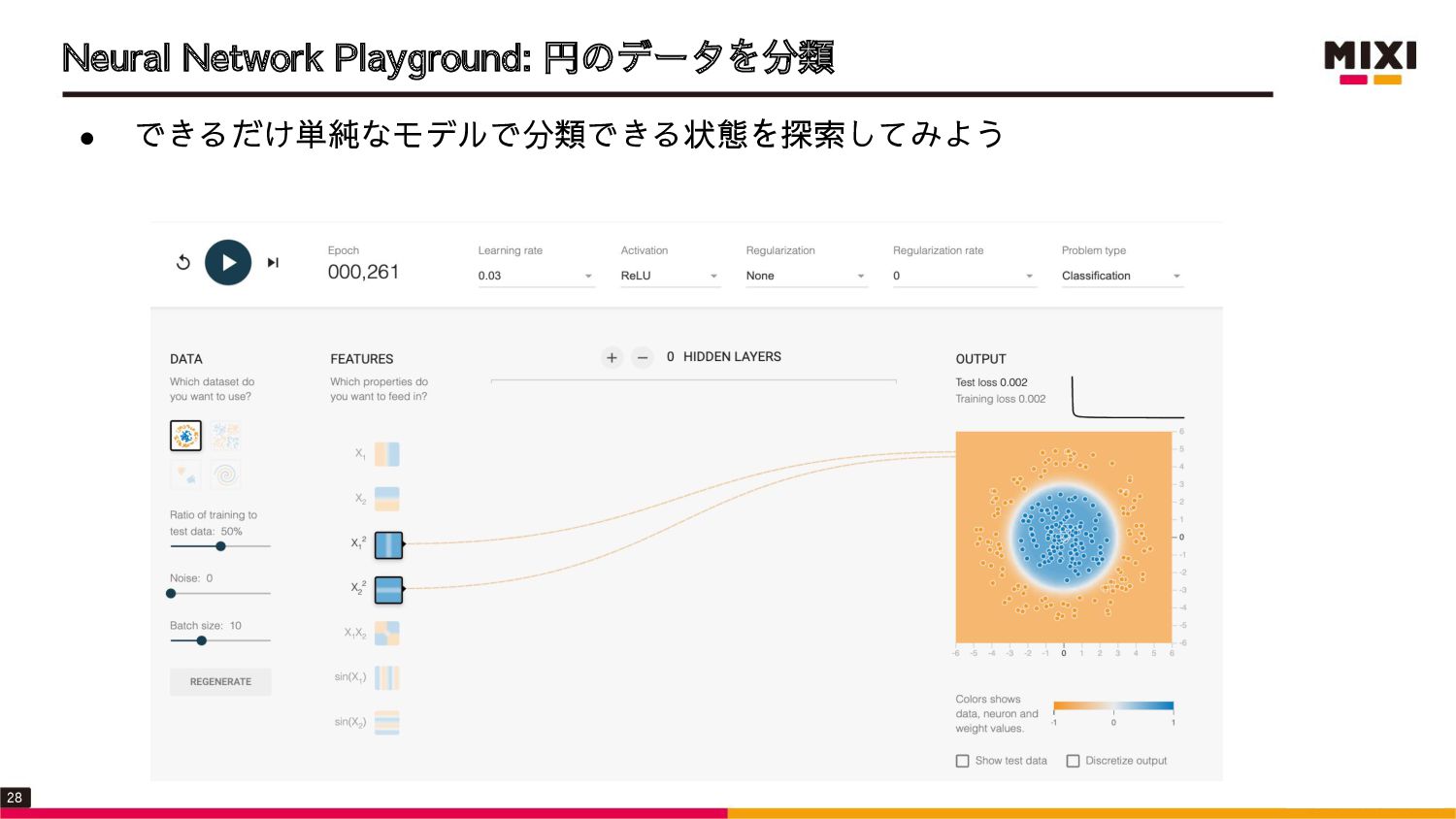{kind=link}
{kind=link}
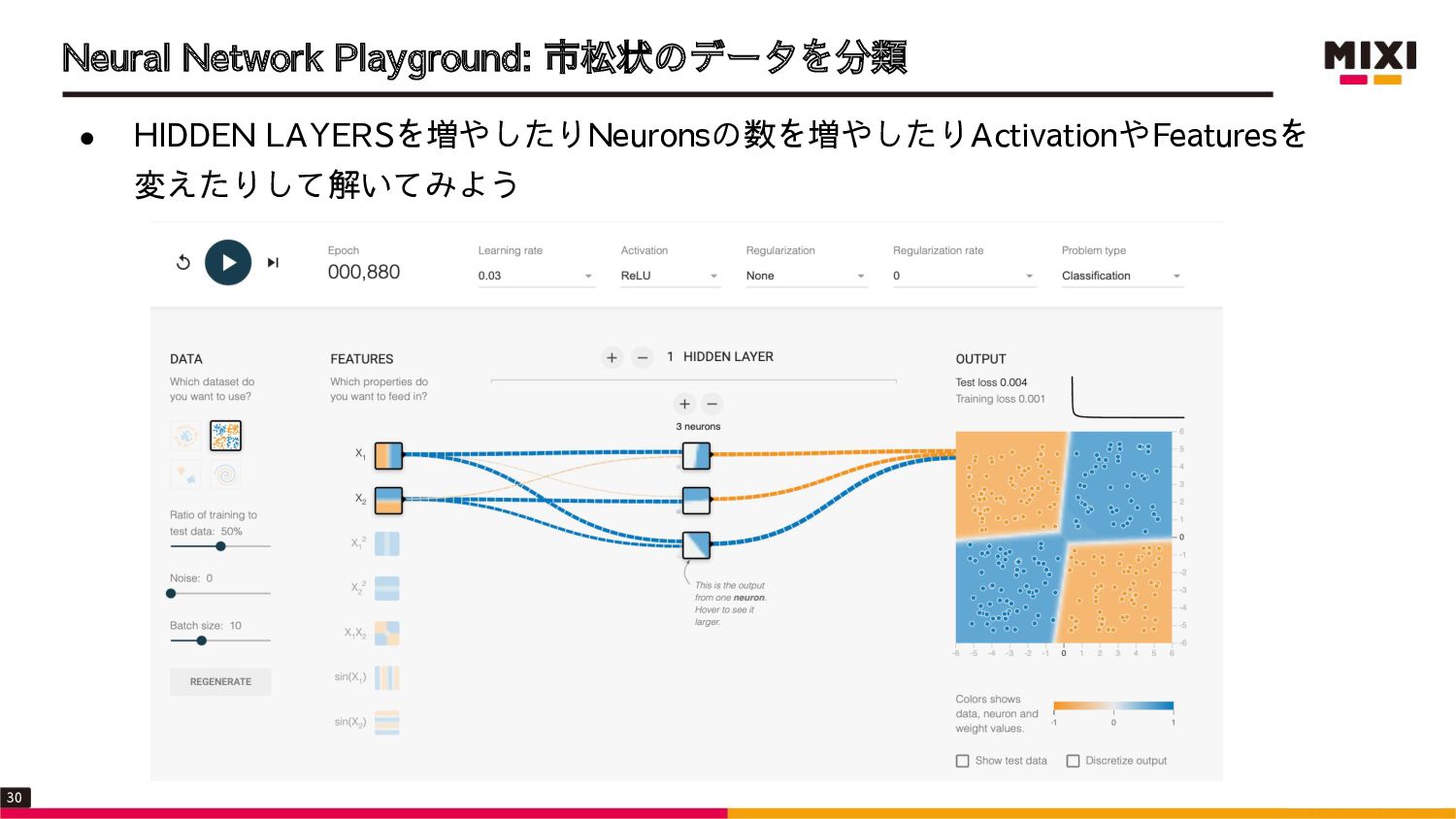{kind=link}
{kind=link}
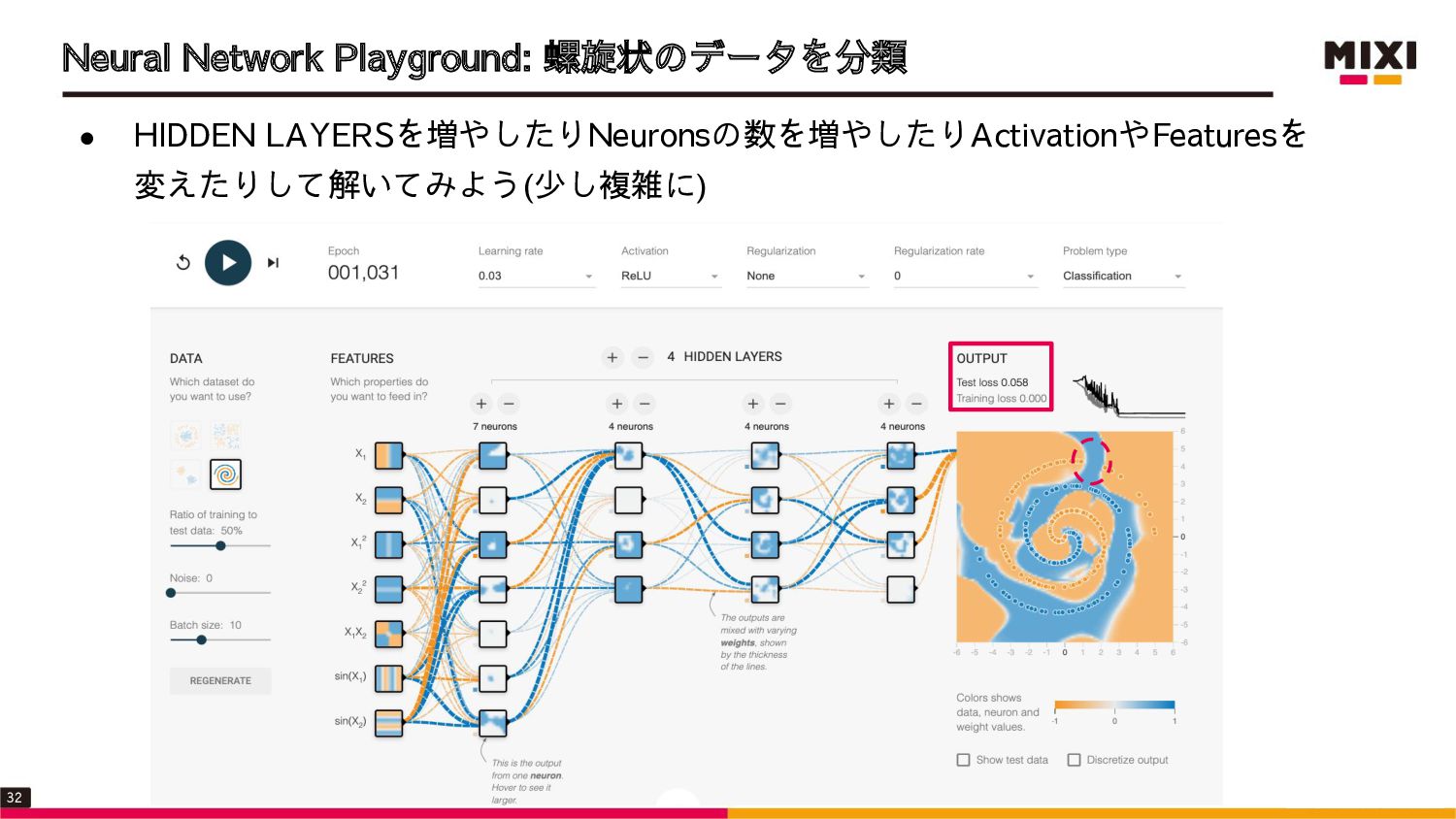{kind=link}
{kind=link}
{kind=link}
{kind=link}
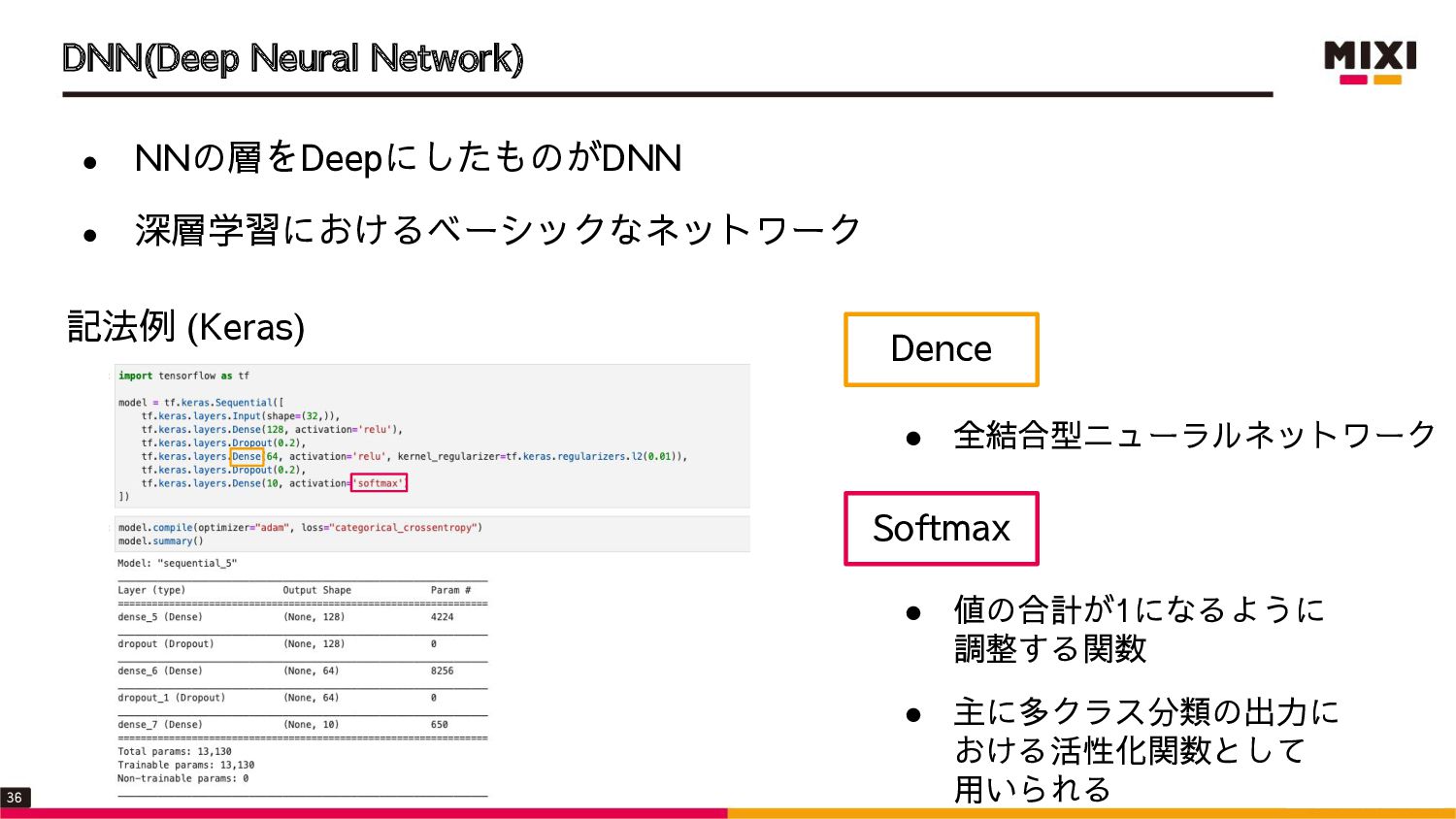{kind=link}
{kind=link}
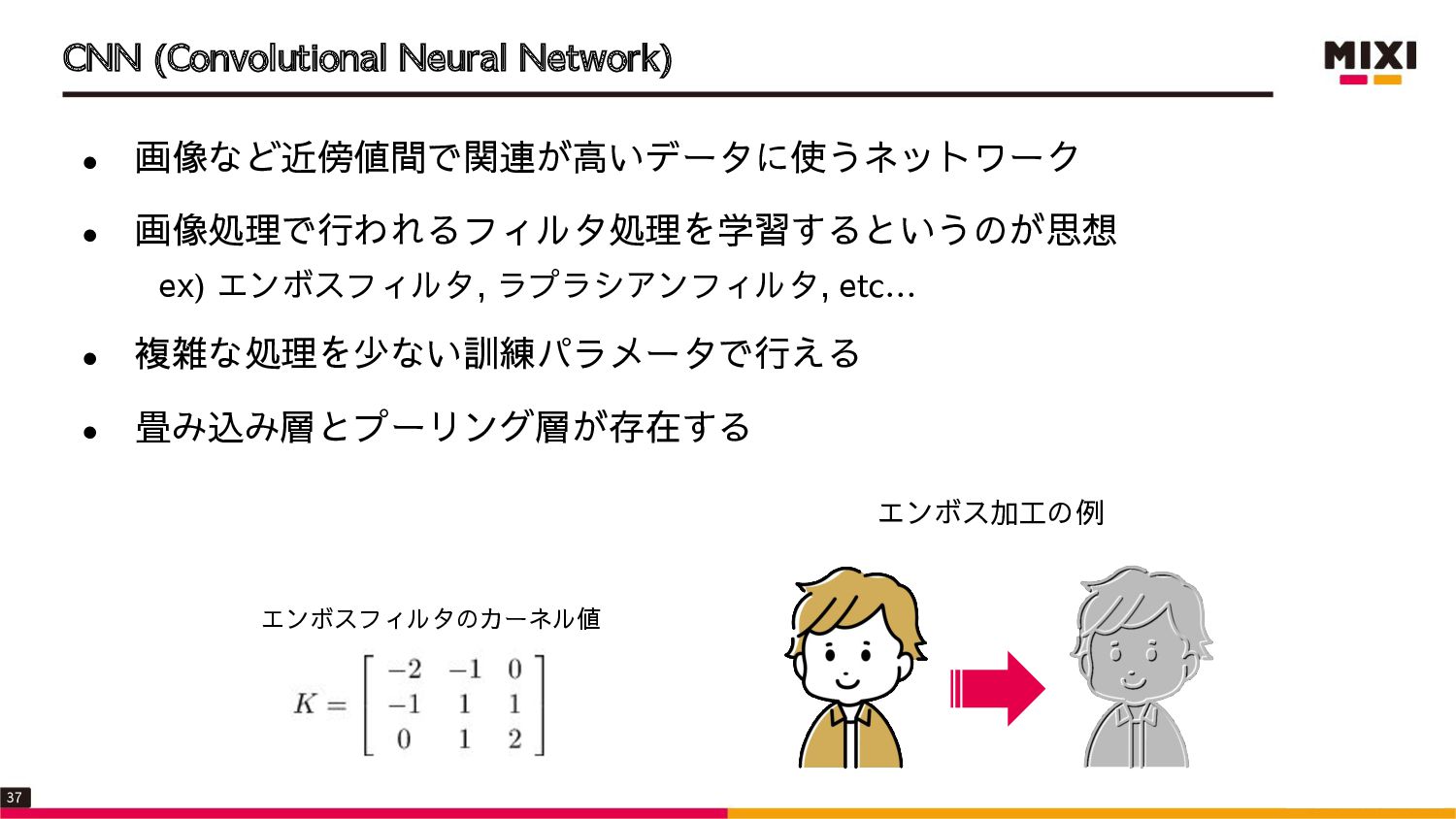
![CNN: 画像と行列 • 白黒画像は、2次元行列で表現できる ➢ SVGAサイズの場合、[800, 600]の行列に0〜255の数値が入る • カラー画像の場合、カラーモードの次元を含めた3次元行列で表現できる ➢](https://files.speakerdeck.com/presentations/47ff8ea20bbf4dfba1a4e923186c165c/slide_37.jpg){kind=link}
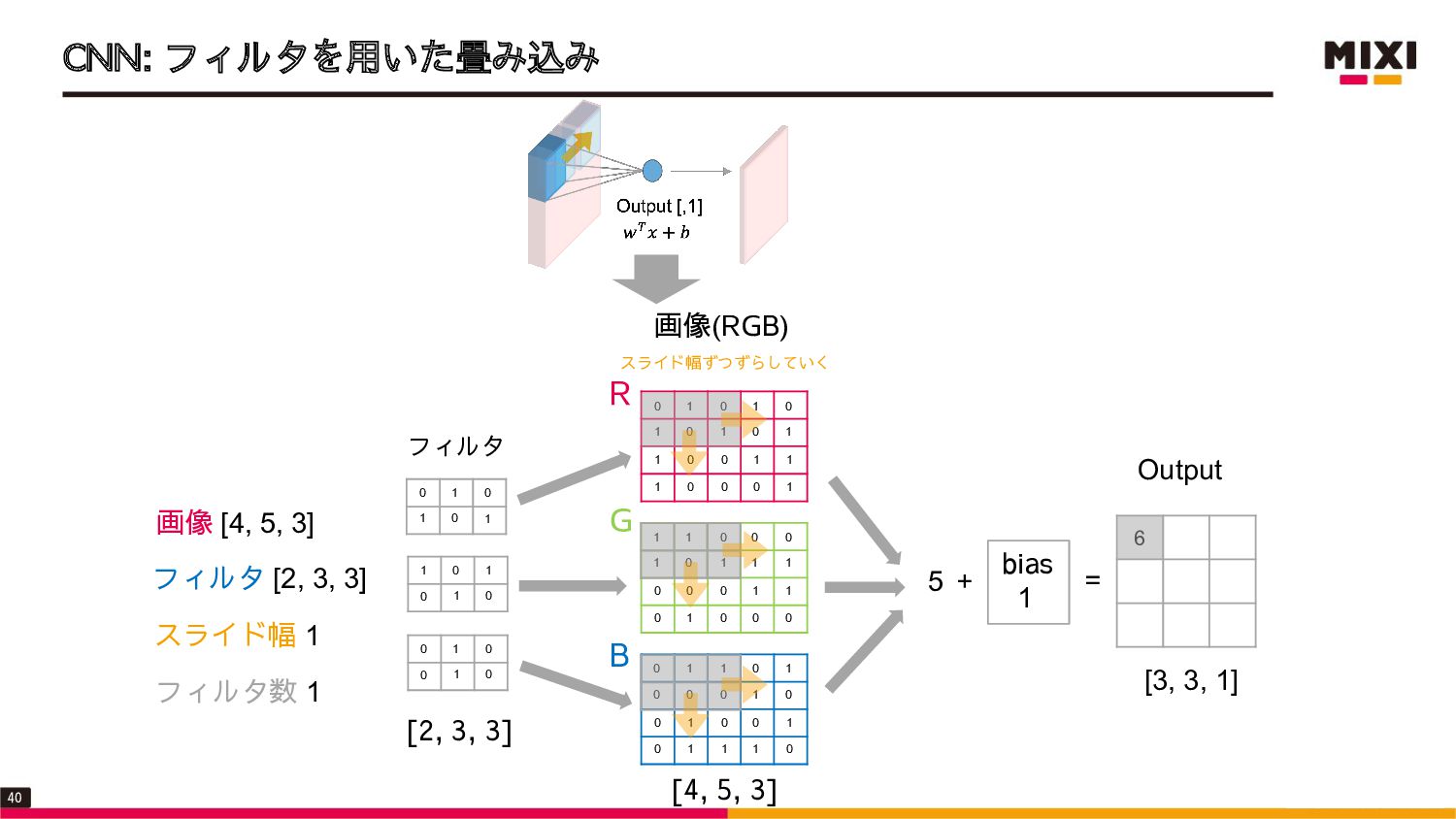
![CNN: フィルタを用いた畳み込み • CNNでは、画像の行列に対してフィルタをかけることで畳み込みを行う • フィルタの大きさは[縦, 横, カラーモード]で、縦と横はハイパーパラメータ ➢ カラーモードはInputの画像で決めるため、実装では指定しなくて良い](https://files.speakerdeck.com/presentations/47ff8ea20bbf4dfba1a4e923186c165c/slide_38.jpg){kind=link}
{kind=link}
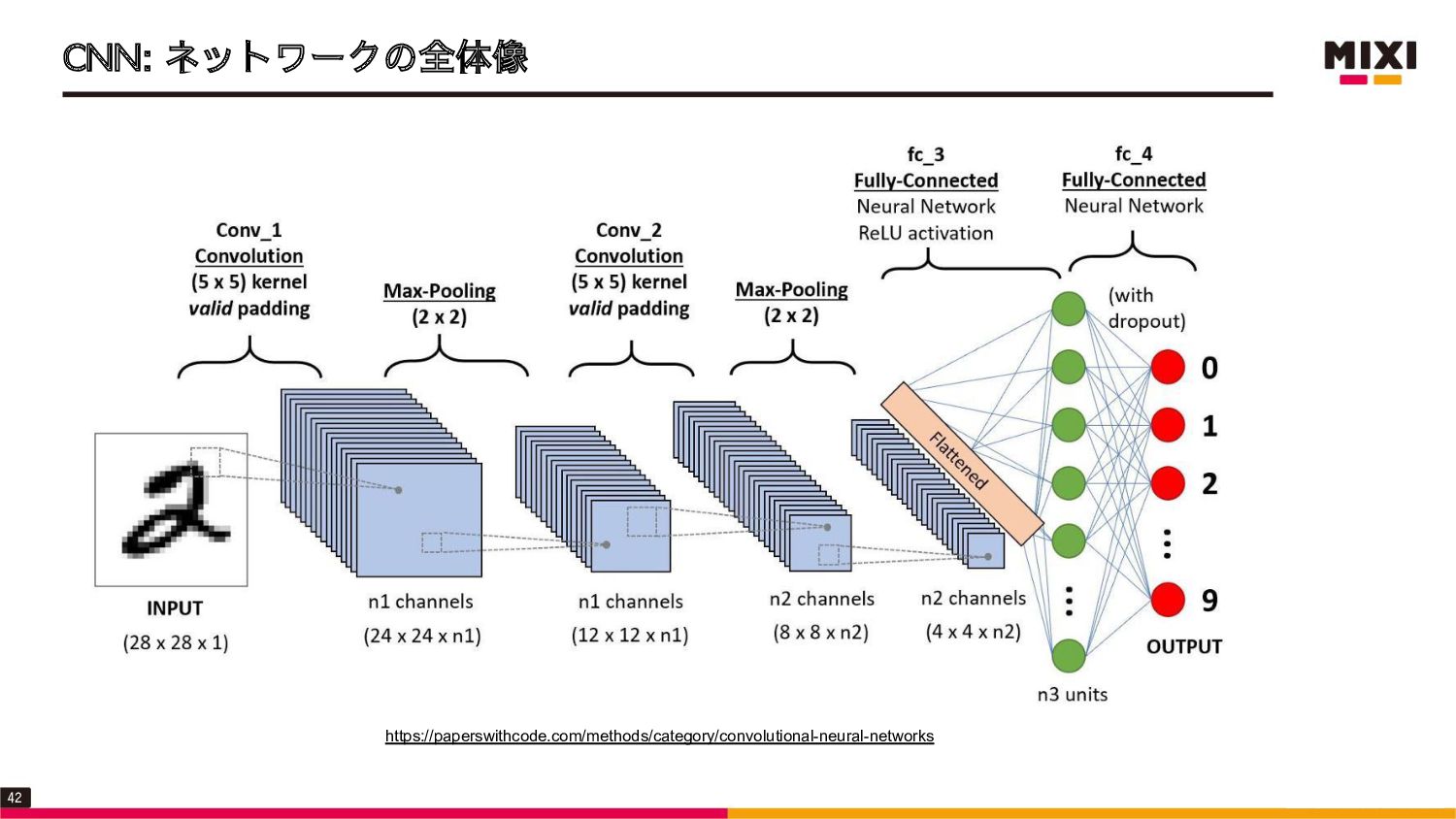
![CNN: プーリング • 畳み込み後に、行列を圧縮するために用いられる手法 • プーリング幅として[縦, 横, フィルタ数]の行列を指定 ➢ フィルタ数は畳み込み時に指定するので、実装では指定しなくて良い](https://files.speakerdeck.com/presentations/47ff8ea20bbf4dfba1a4e923186c165c/slide_40.jpg){kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
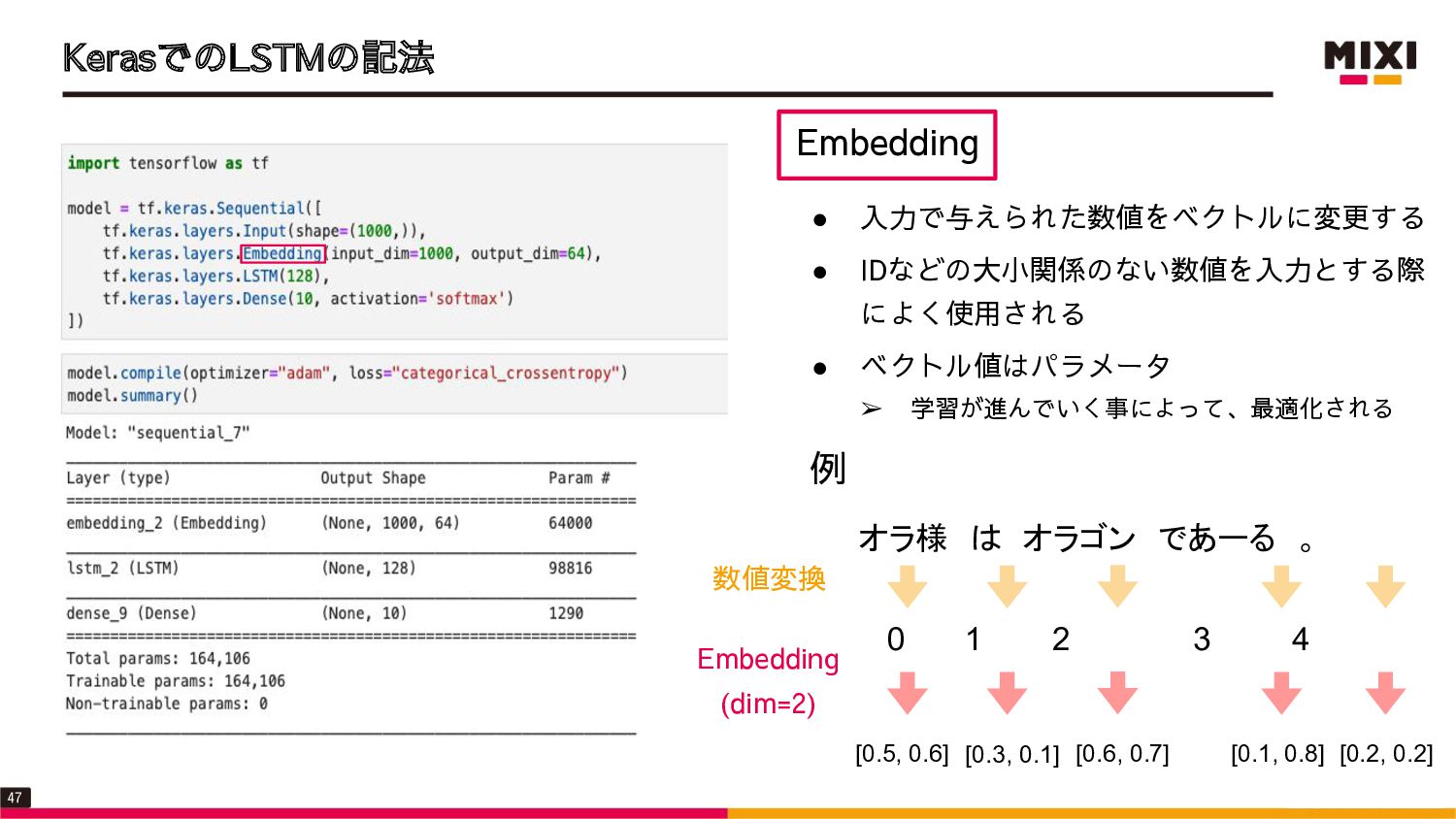{kind=link}
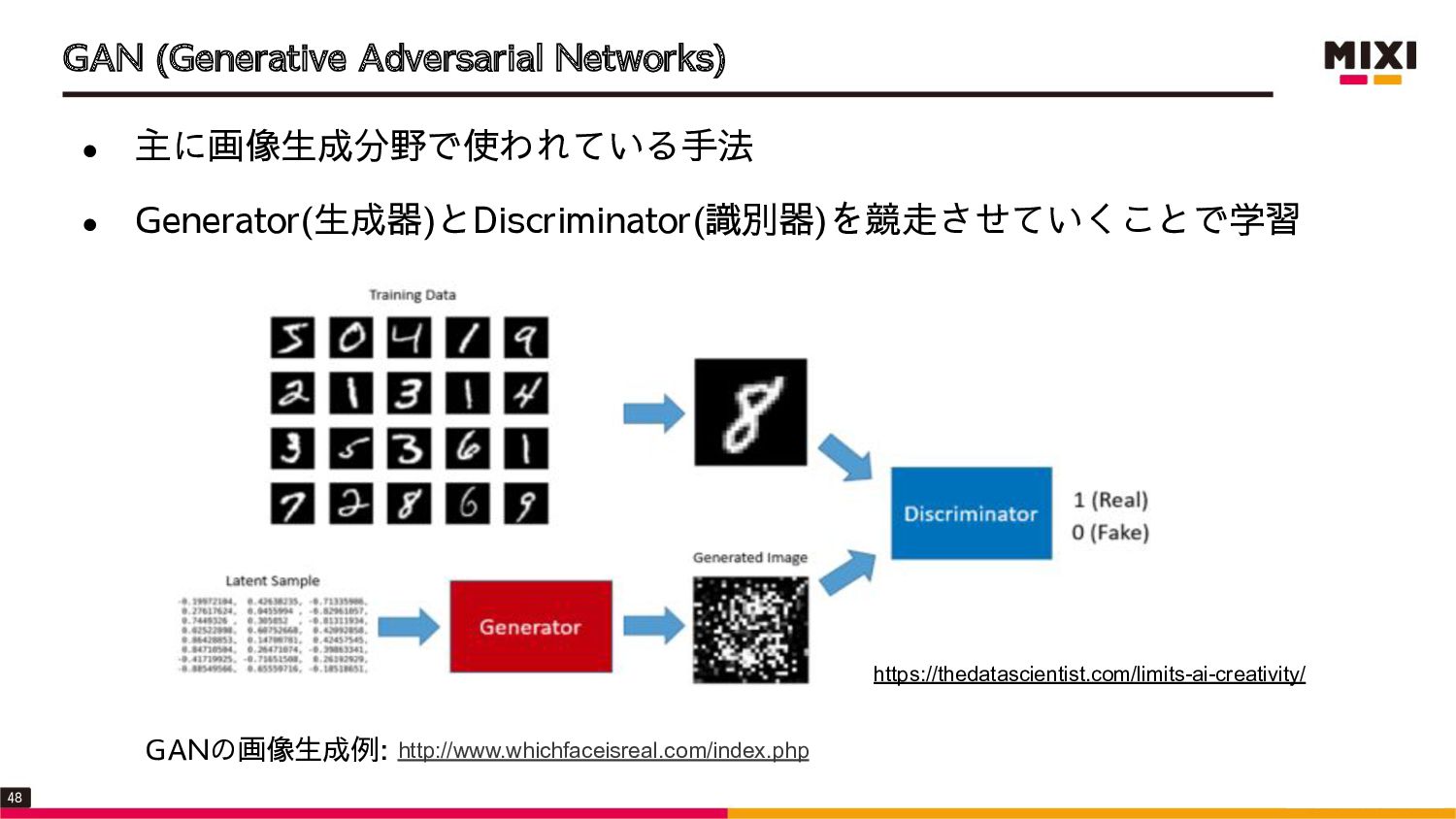{kind=link}
{kind=link}
{kind=link}
{kind=link}
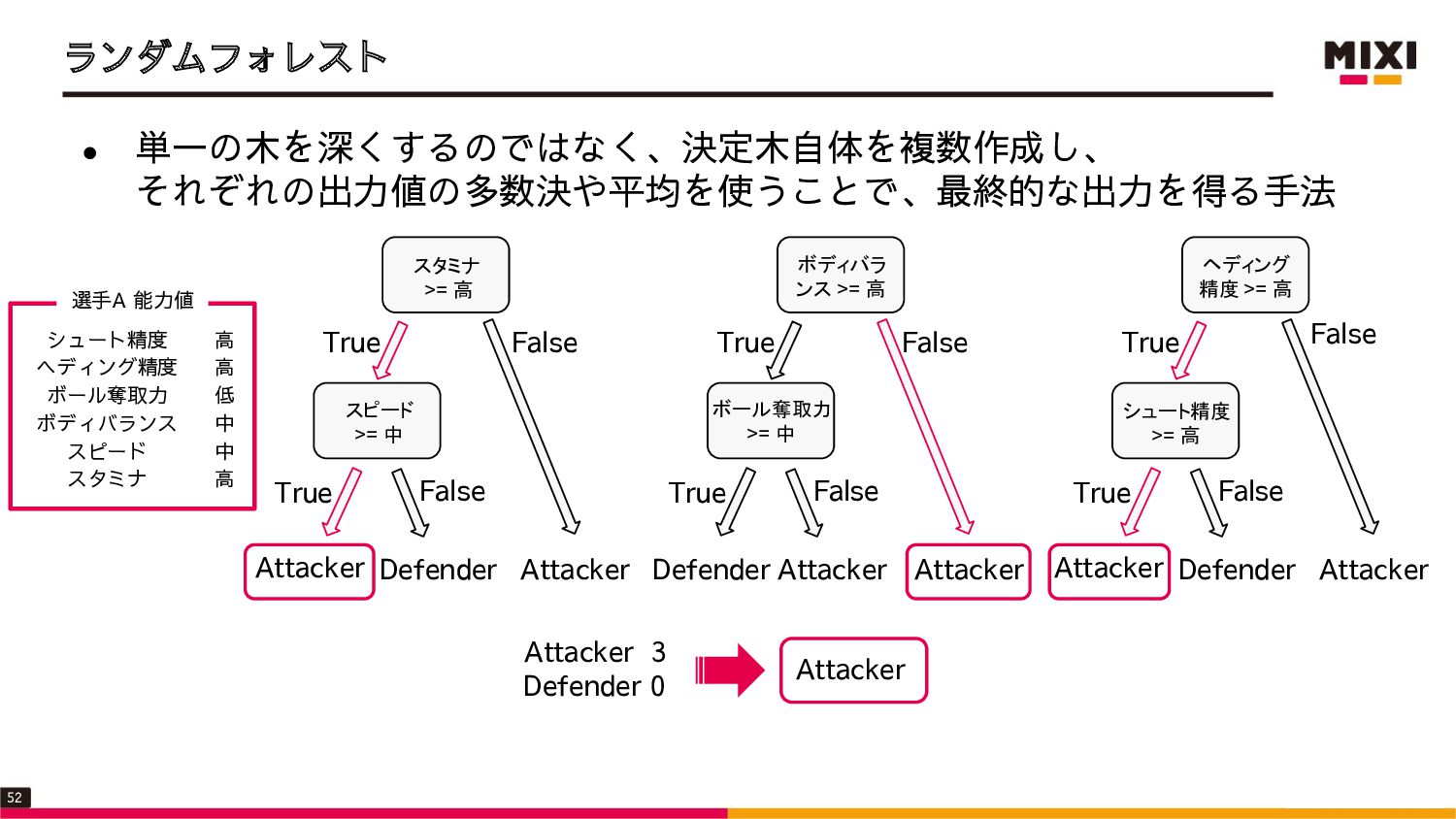{kind=link}
{kind=link}
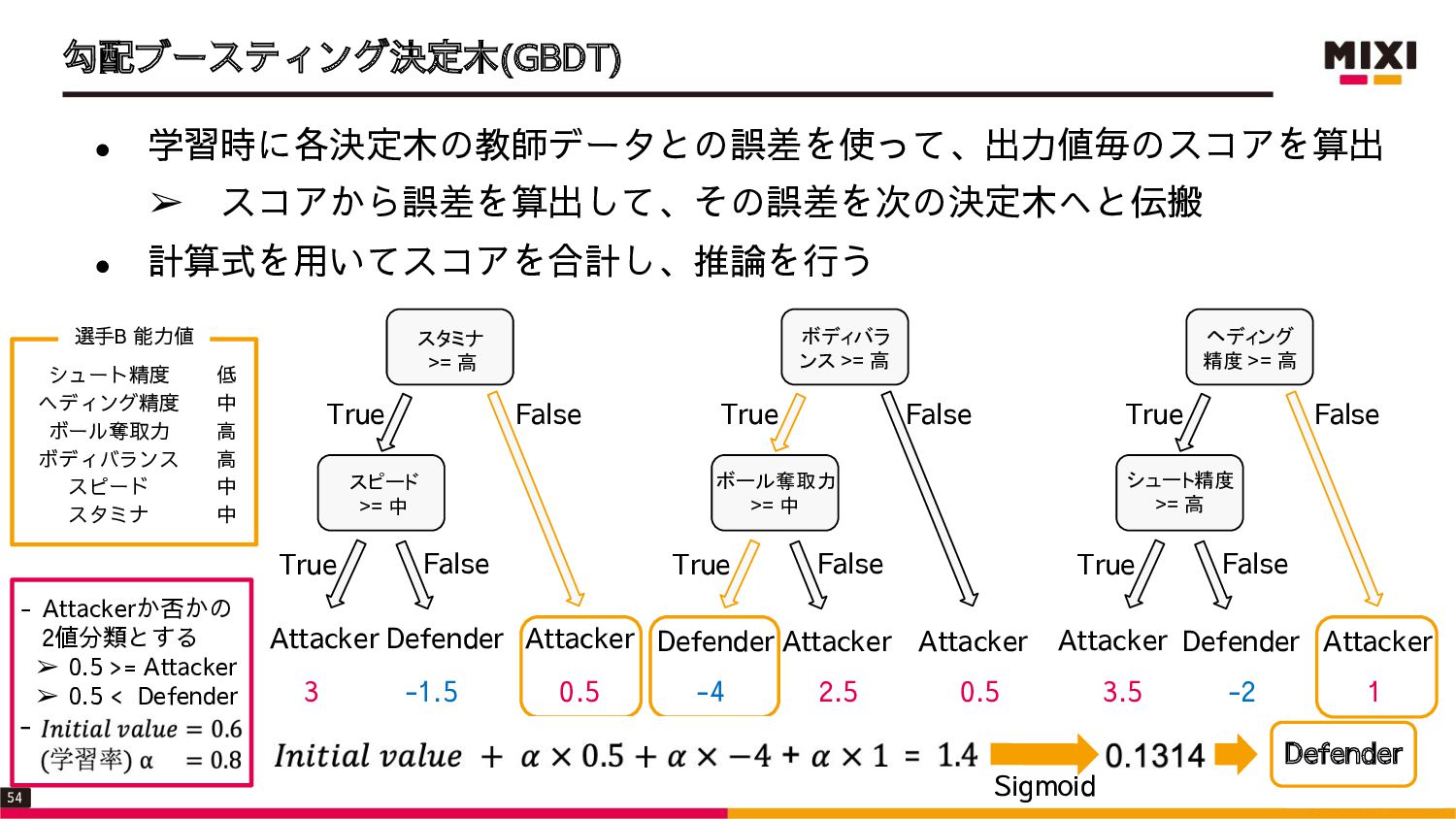{kind=link}
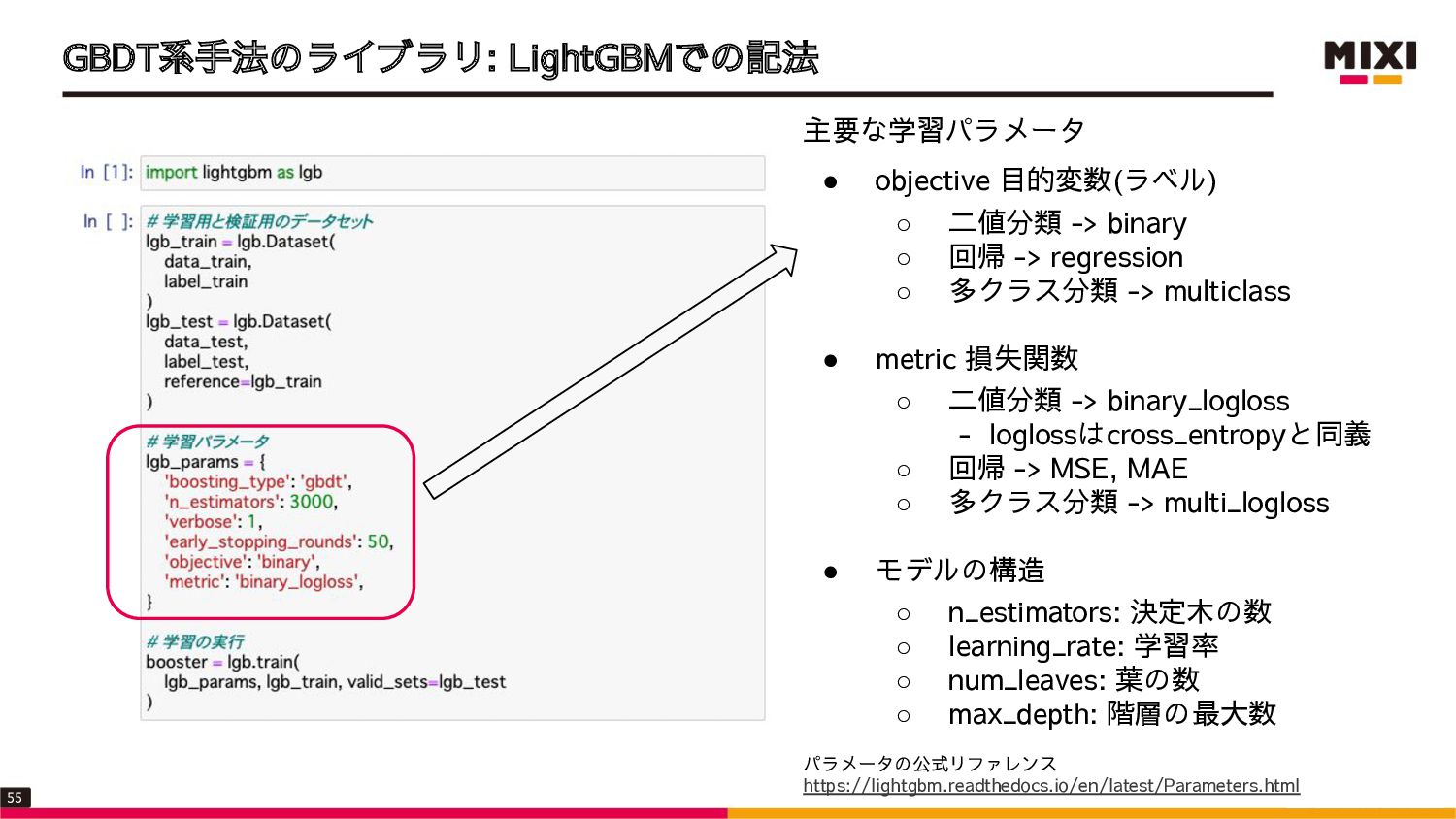{kind=link}
{kind=link}
{kind=link}