This talk has been presented at iPRES2017, Kyoto and wants to raise awareness about possible risks associated with the PDF/A file format within digital preservation. Please check the paper at https://ipres2017.jp/wp-content/uploads/15Marco-Klindt.pdf .
{kind=link}
{kind=link}
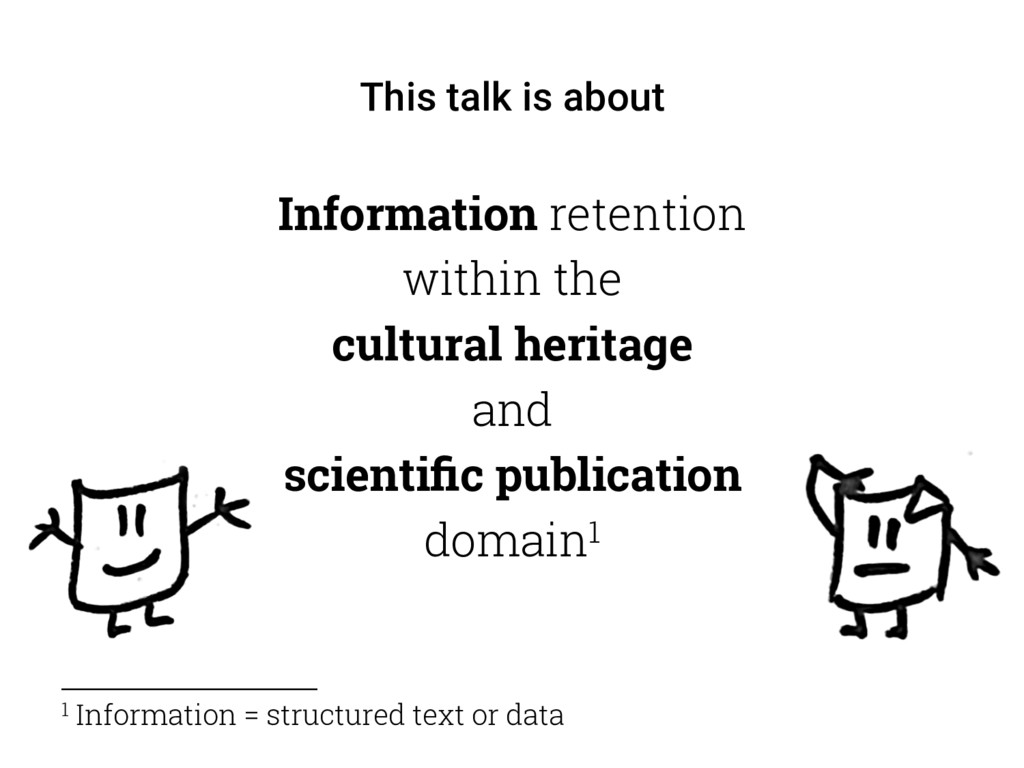{kind=link}
{kind=link}
{kind=link}
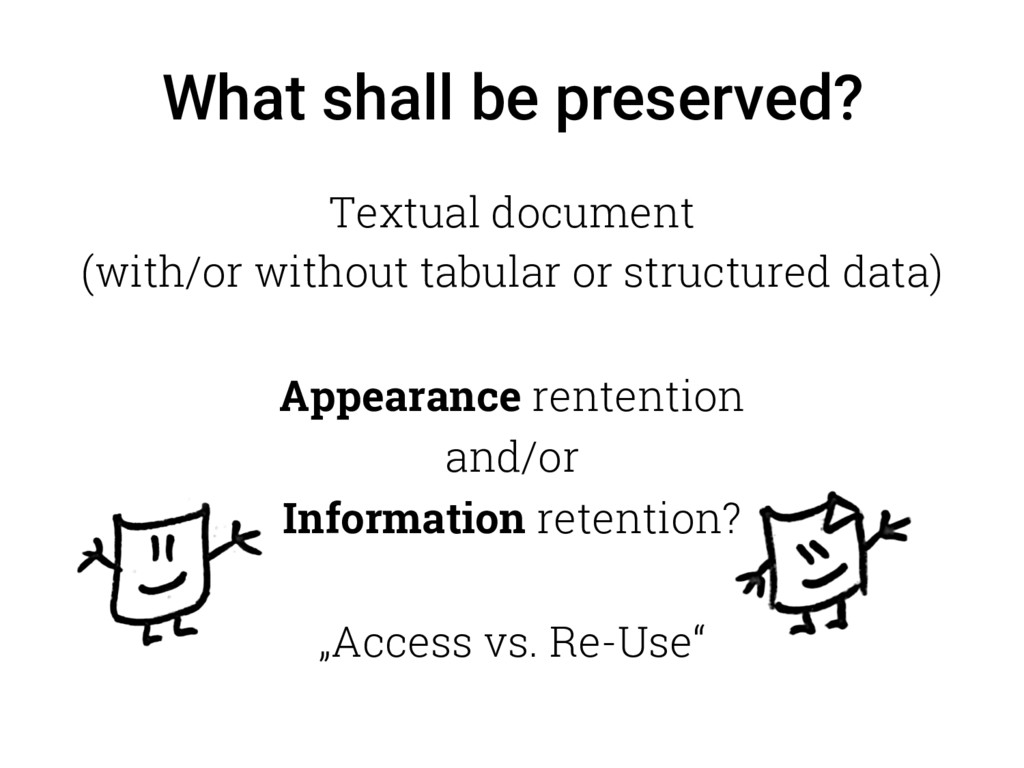{kind=link}
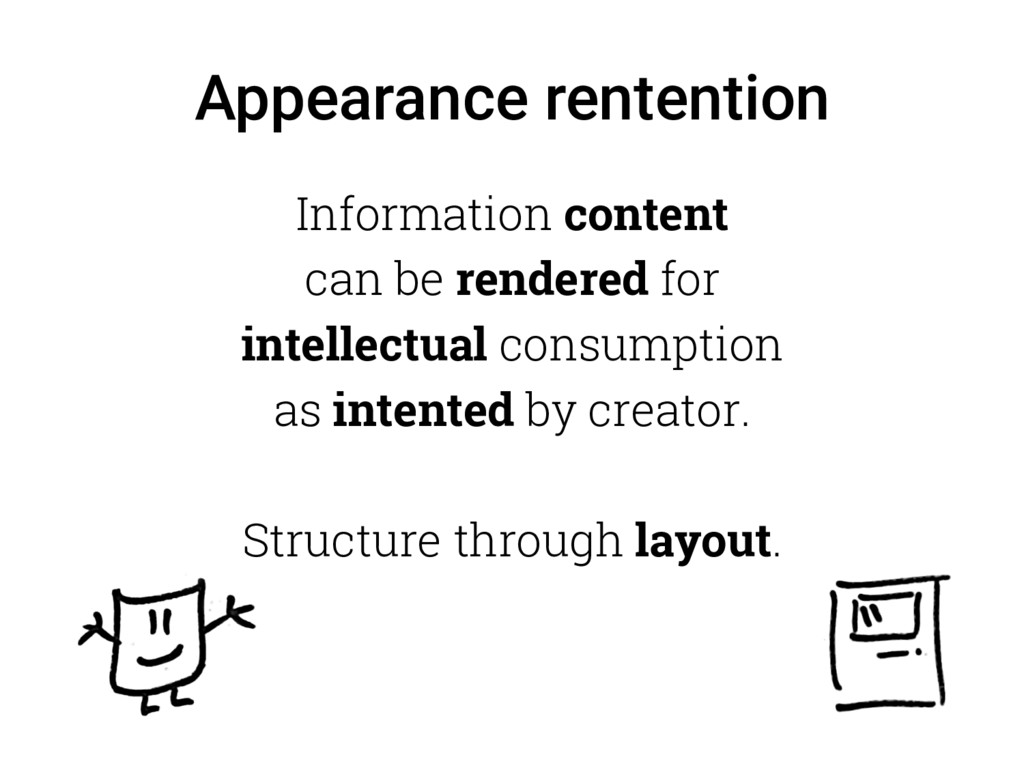{kind=link}
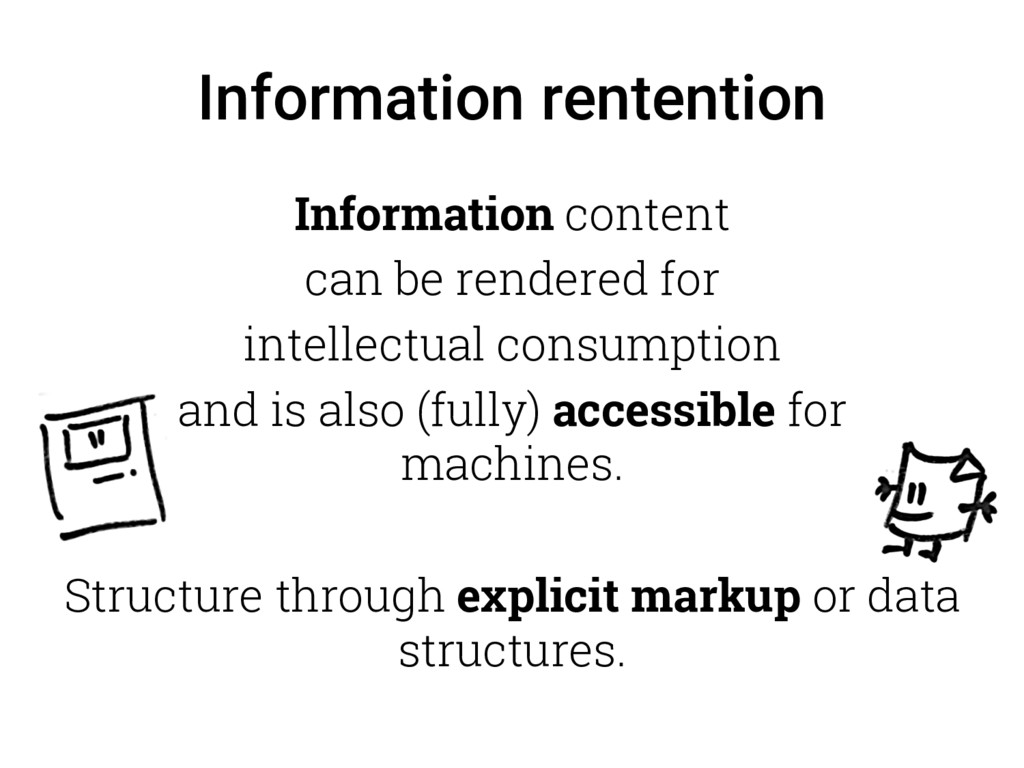{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
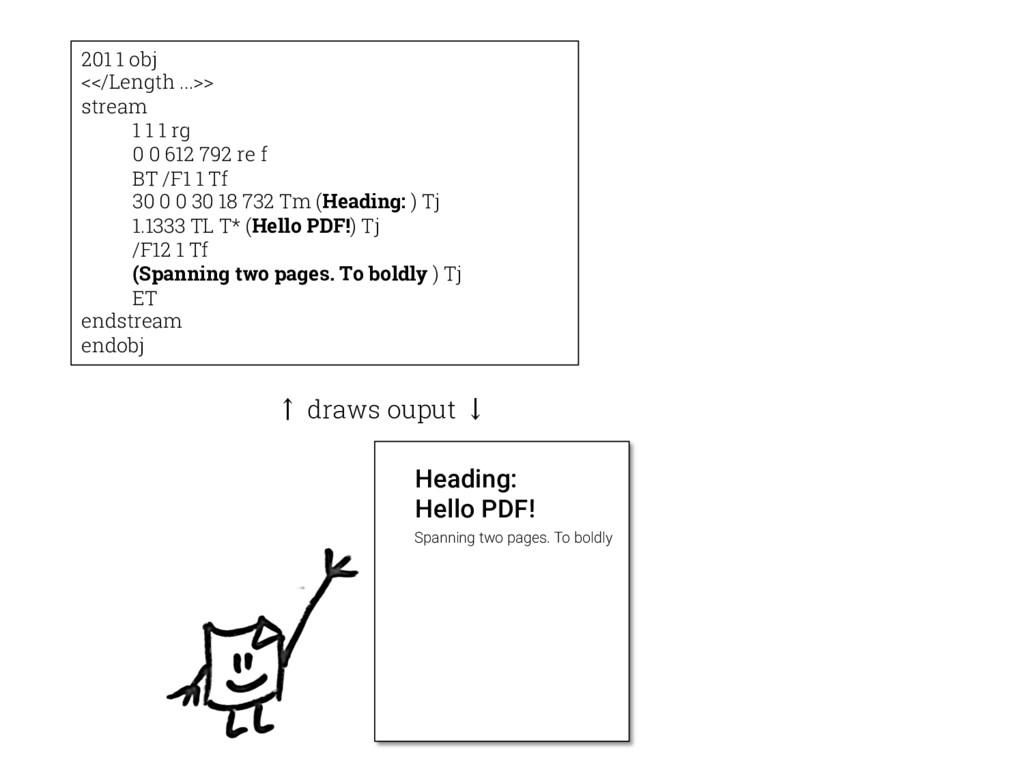
![101 1 obj <</Type /Page [...] /Contents 201 0 R](https://files.speakerdeck.com/presentations/1e8336ee7e5f4d2fab5d64c6a1a0884c/slide_17.jpg){kind=link}
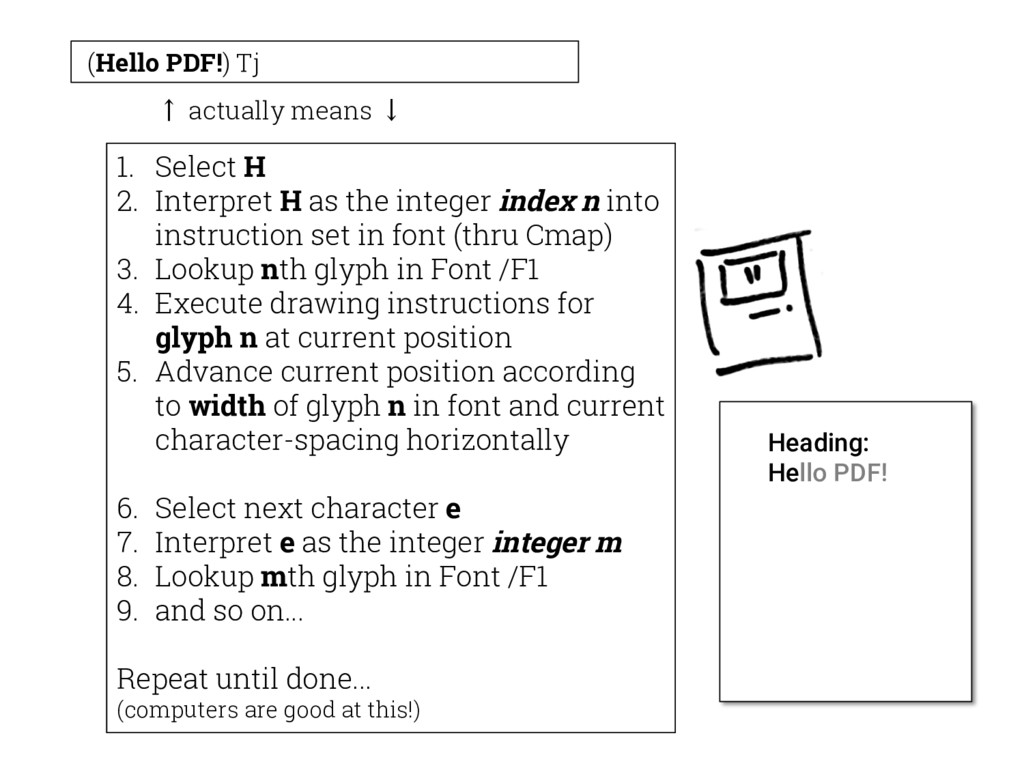
{kind=link}
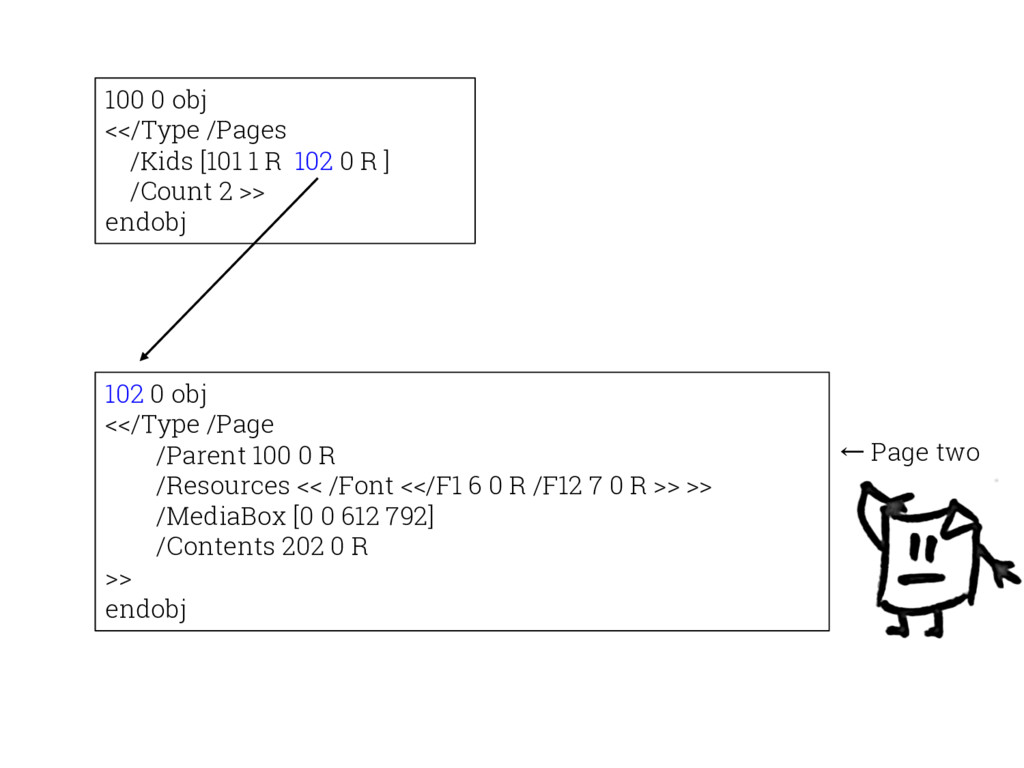
{kind=link}
{kind=link}
{kind=link}
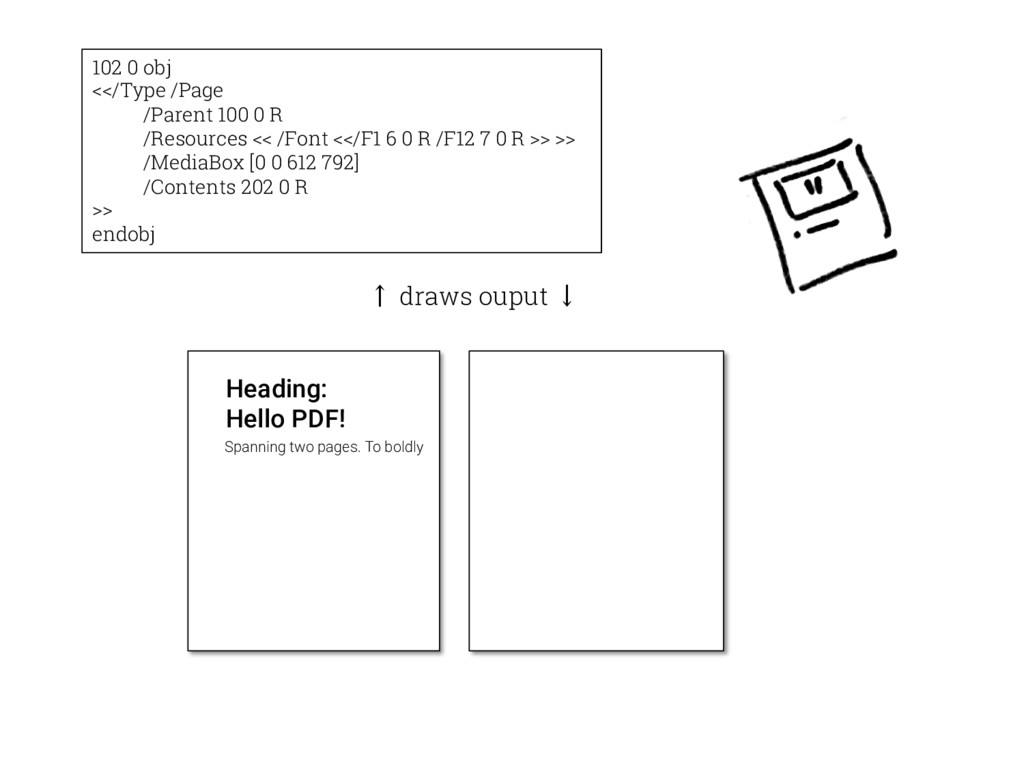
![102 1 obj <</Type /Page [...] /Contents 202 0 R](https://files.speakerdeck.com/presentations/1e8336ee7e5f4d2fab5d64c6a1a0884c/slide_22.jpg){kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
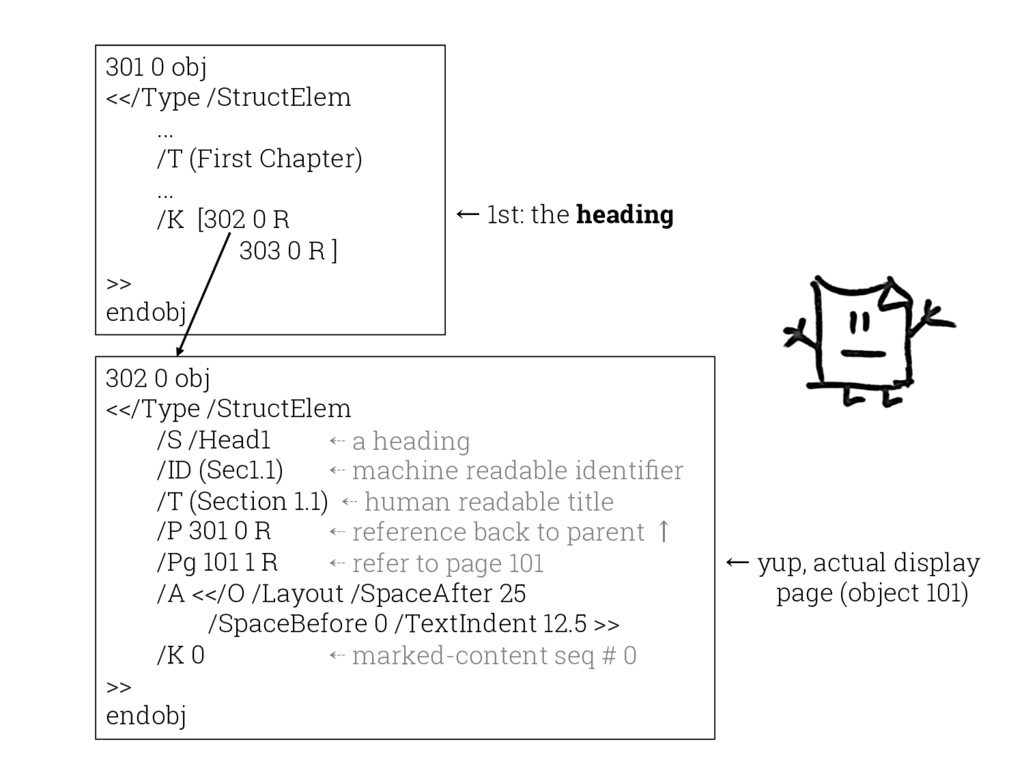{kind=link}
![101 1 obj <</Type /Page [...] /Contents 201 0 R](https://files.speakerdeck.com/presentations/1e8336ee7e5f4d2fab5d64c6a1a0884c/slide_33.jpg){kind=link}
{kind=link}
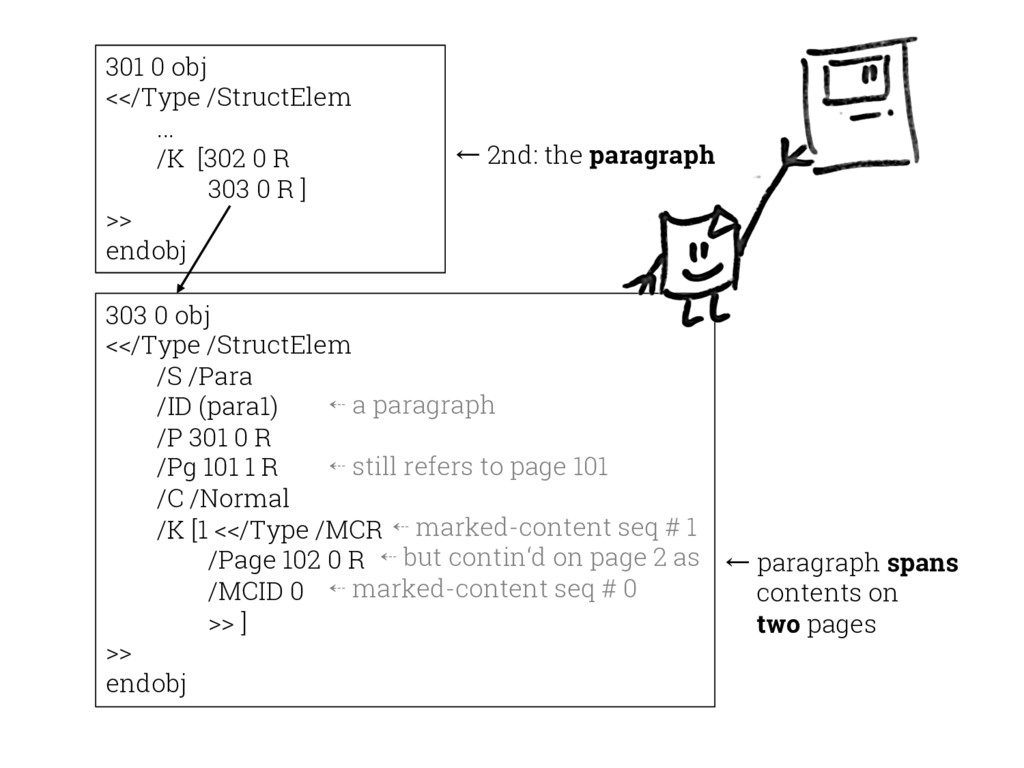{kind=link}
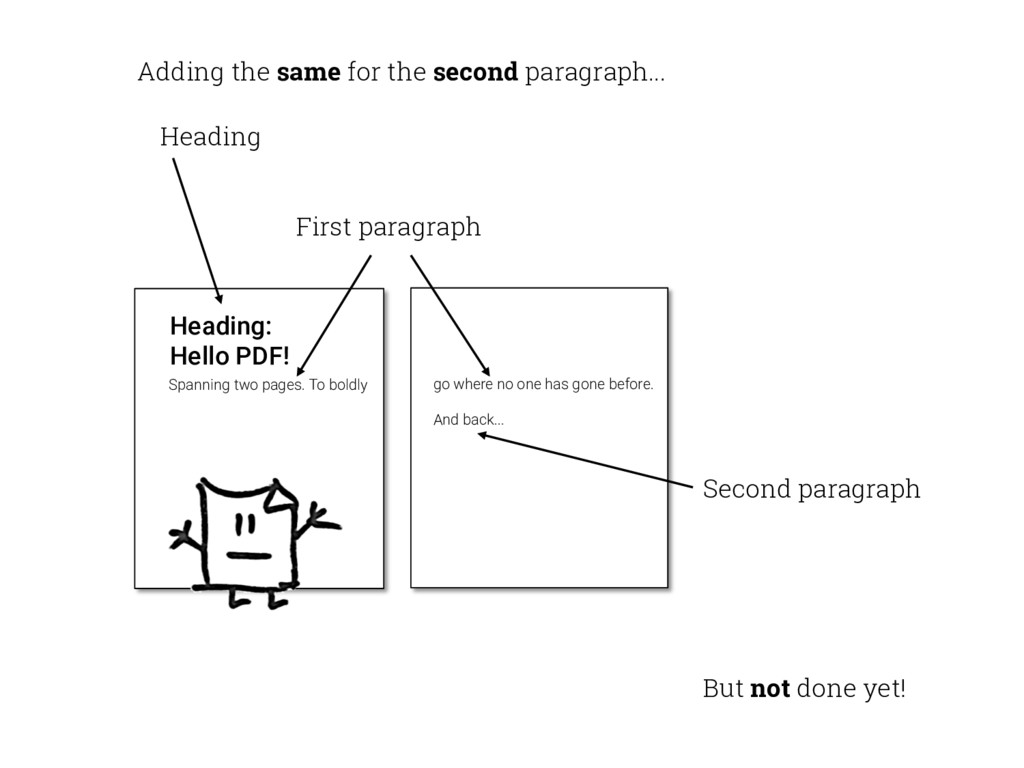{kind=link}
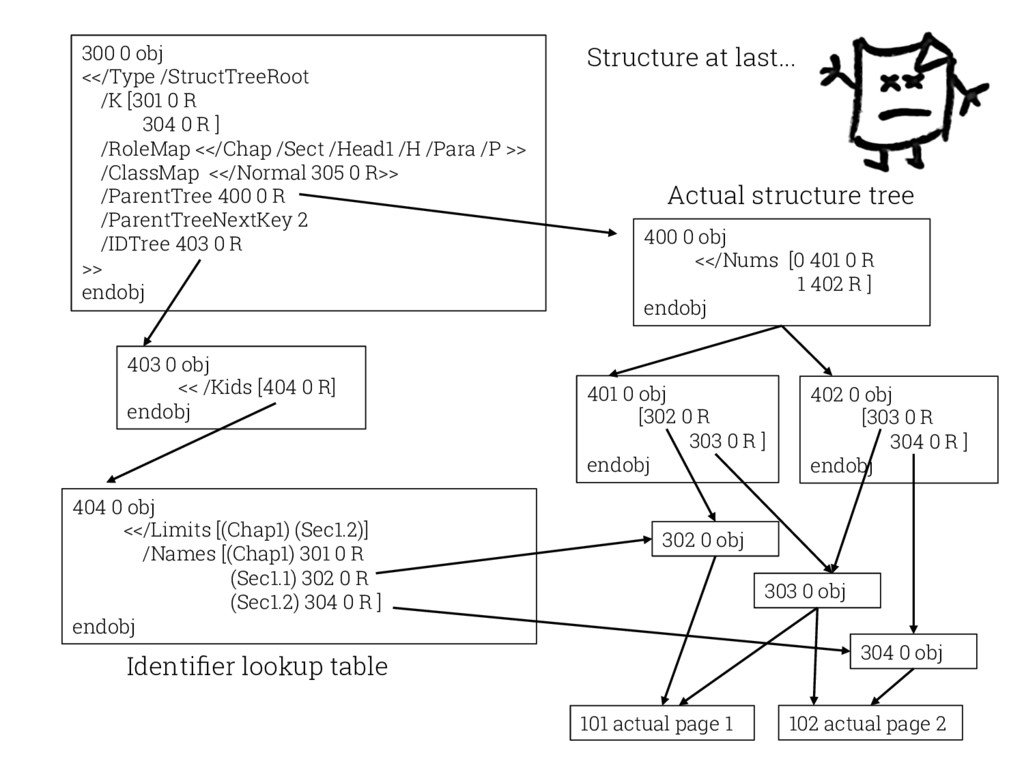{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}