Upgrade to Pro
— share decks privately, control downloads, hide ads and more …
Speaker Deck
Features
Speaker Deck
PRO
Sign in
Sign up for free
Search
Search
【2026年版】 ベクトル検索とEmbedding最前線
Search
Tomoko Uchida
June 22, 2026
Technology
9.2k
28
Share
Embed
Copy iframe code
Copy JS code
Copy link
Start on current slide
【2026年版】 ベクトル検索とEmbedding最前線
Encraft #25 生成AI時代の検索設計
https://knowledgework.connpass.com/event/393625/
の登壇資料です。
Tomoko Uchida
June 22, 2026
More Decks by Tomoko Uchida
See All by Tomoko Uchida
Lucene Kuromoji のコードを読む会 (辞書ビルダー編)
mocobeta
1
340
Pythonで作って学ぶ形態素解析
mocobeta
1
110
Other Decks in Technology
See All in Technology
LLMリーダーボードアップデートに向けたAgentic Math_SWEのトレースについて
nejumi
0
190
なぜ、あなたのAPIは使われないのか? AX時代の設計原則、ガードレール、運用体制
yokawasa
1
1.2k
AIがコードを書く時代、人間は何を保証するのか———馬場さんと考える、開発者に求められる新しい責任と価値 - TECH PLAY
netmarkjp
0
1k
QAと開発の両側から進める AI活用 -QAプロセスAI支援ツールキットと Inner Loop / Outer Loopの取り組み-
legalontechnologies
PRO
2
400
Data Hubグループ 紹介資料
sansan33
PRO
0
3.1k
個人OSSが、机の上から世界に広がるまでの話
shinyasaita
1
200
データと地図で読む 大井町の「かわるもの、かわらないもの」
yoshiyama_hana
0
890
MIRU 2026 チュートリアル
keisuke198619
0
350
AI Agent を本番環境へ―― Microsoft Foundry × Azure Serverless で作る Enterprise-Ready な基盤
shibayan
PRO
1
1k
なぜ、あなたのエージェントは言うことを聞かないのか
segavvy
1
610
【5分でわかる】セーフィー エンジニア向け会社紹介
safie_recruit
0
53k
もう一度考える SRE チームの作り方・育て方 / Rethinking SRE #1: Building and Growing SRE Teams
rrreeeyyy
4
530
Featured
See All Featured
AI Search: Implications for SEO and How to Move Forward - #ShenzhenSEOConference
aleyda
1
1.3k
Efficient Content Optimization with Google Search Console & Apps Script
katarinadahlin
PRO
1
750
Applied NLP in the Age of Generative AI
inesmontani
PRO
4
2.4k
Easily Structure & Communicate Ideas using Wireframe
afnizarnur
194
17k
Raft: Consensus for Rubyists
vanstee
141
7.6k
Leveraging Curiosity to Care for An Aging Population
cassininazir
1
440
The Curse of the Amulet
leimatthew05
2
13k
SEOcharity - Dark patterns in SEO and UX: How to avoid them and build a more ethical web
sarafernandez
0
230
Test your architecture with Archunit
thirion
1
2.3k
Creating an realtime collaboration tool: Agile Flush - .NET Oxford
marcduiker
35
2.5k
Design of three-dimensional binary manipulators for pick-and-place task avoiding obstacles (IECON2024)
konakalab
0
500
Leadership Guide Workshop - DevTernity 2021
reverentgeek
1
330
Transcript
【2026年版】 ベクトル検索と Embedding最前線 Encraft #25 生成AI時代の検索設計 @mocobeta
自己紹介 打田智子 株式会社LegalOn Technologies WorkOn事業部 AIエージェント基盤チームリーダー @mokobeta @mocobeta.dev Janome開発者/Luceneコミッタ/ 「検索システム(ラムダノート)」著者
2
この発表で想定するオーディエンス • ベクトル検索やEmbeddingが何かふんわり知っていて,歴史と背 景を知りたい人 • セマンティック検索システムやRAGを作っていて仕組みが説明でき るようになりたい人 が,2026年に知っておきたいトピックをコンパクトにまとめました。 精通している方は復習に使ってもらえると幸いです 🙏
3
目次 1. イントロ:ベクトル検索とは 2. 埋め込みモデル 3. 近似最近傍探索 4. 最適化テクニック a.
次元削減 b. 量子化 4
ベクトル検索とは 5
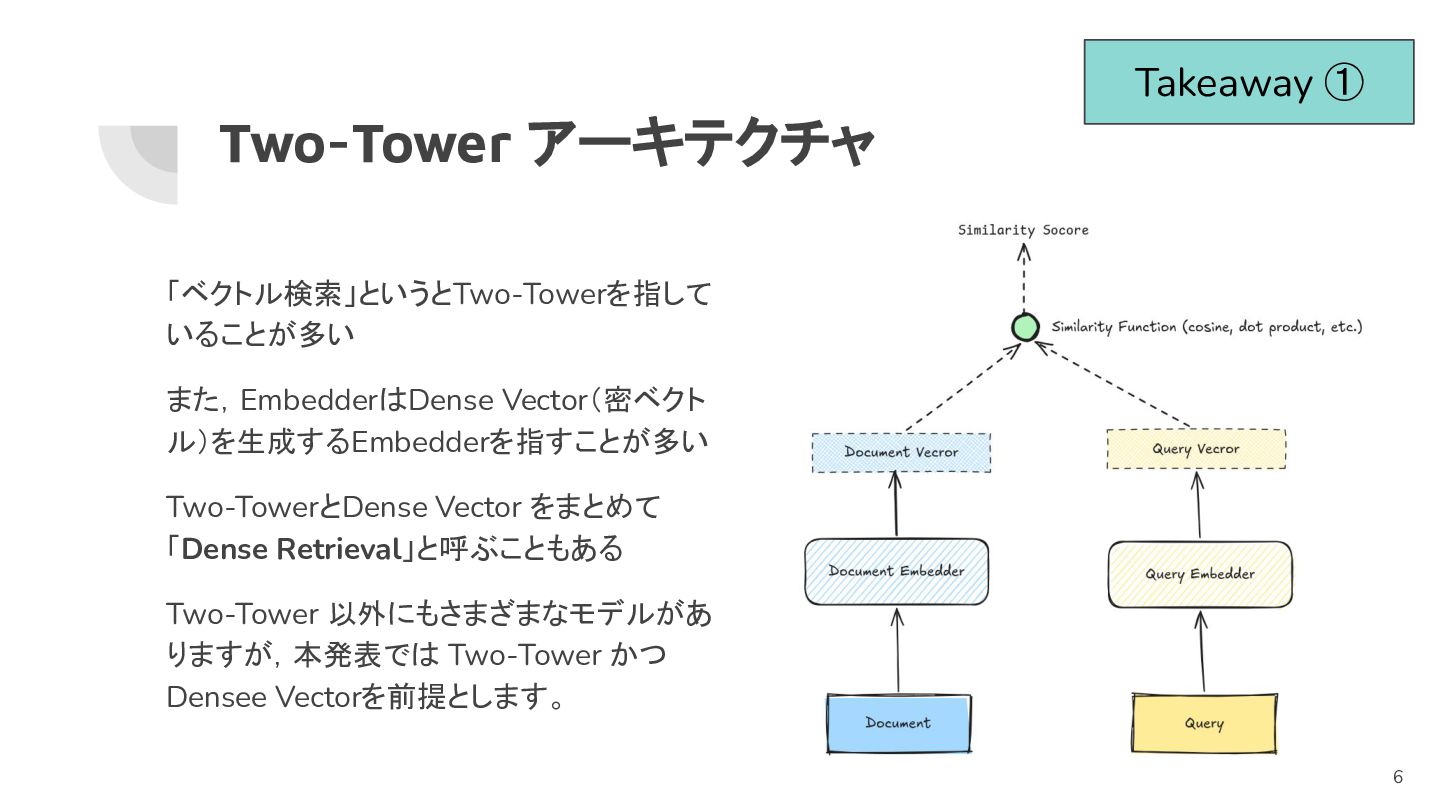
Two-Tower アーキテクチャ 「ベクトル検索」というとTwo-Towerを指して いることが多い また,EmbedderはDense Vector(密ベクト ル)を生成するEmbedderを指すことが多い Two-TowerとDense Vector をまとめて
「Dense Retrieval」と呼ぶこともある Two-Tower 以外にもさまざまなモデルがあ りますが,本発表では Two-Tower かつ Densee Vectorを前提とします。 Takeaway ① 6
Two-Tower, Dense Embedding以外のモデル Two-Tower, Dense Embedding以外にも,以下のようなアーキテクチャ ,モデルがある。 • Cross Encoder
(Full-Interaction) ◦ BERT, RoBERTが使われる • Multi-vector (Late-Interection) ◦ 代表的なモデルは ColBERT (2020) • Sparse Embedder ◦ 代表的なモデルはSPLADE (2021) 本発表では割愛 Advanced 7
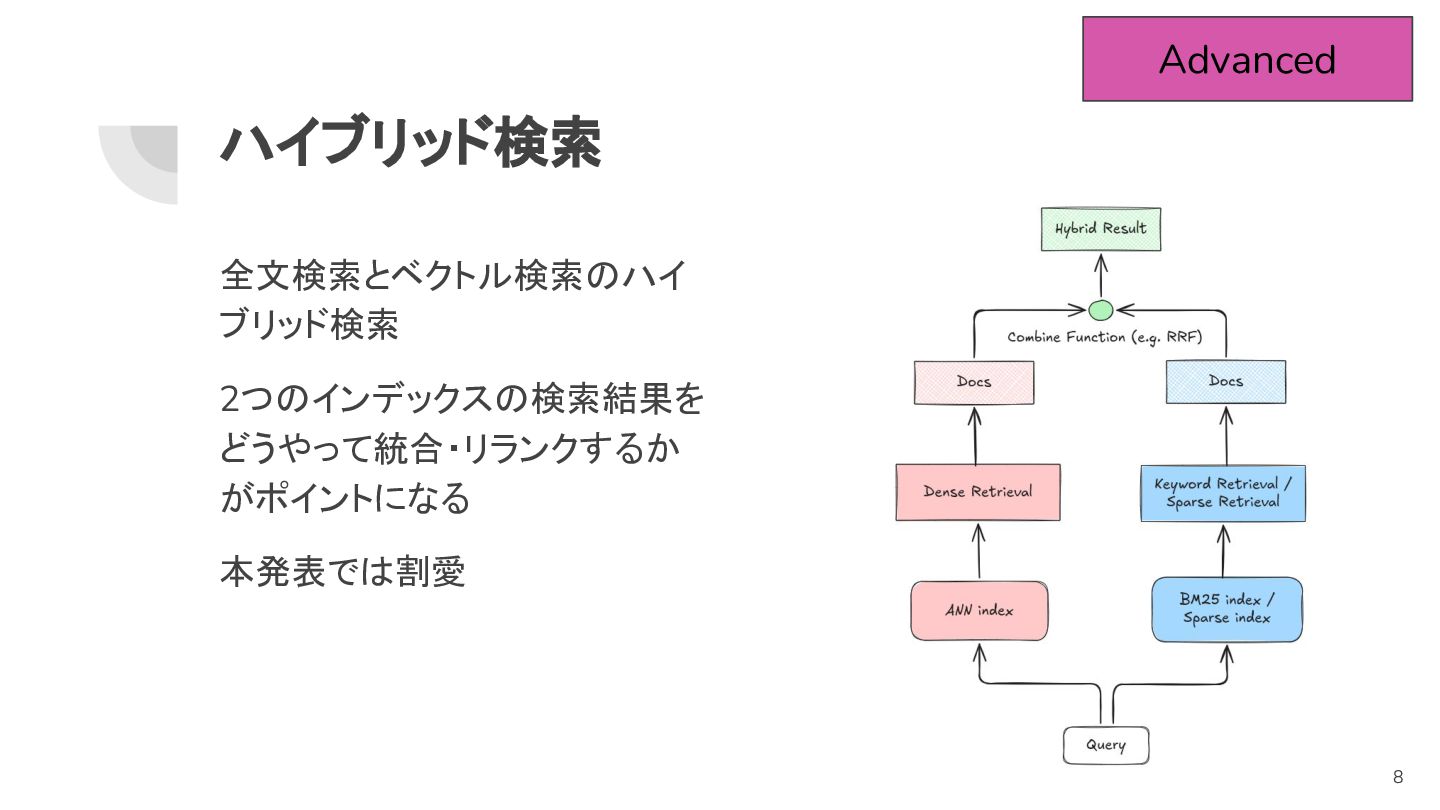
ハイブリッド検索 全文検索とベクトル検索のハイ ブリッド検索 2つのインデックスの検索結果を どうやって統合・リランクするか がポイントになる 本発表では割愛 Advanced 8
埋め込みモデル Embedder 9
テキスト埋め込みモデルの進化を駆け足で When Text Embedding Meets Large Language Model: A Comprehensive
Survey (2024) Zhijie Nie, Zhangchi Feng, Mingxin Li, Cunwang Zhang, Yanzhao Zhang, Dingkun Long, Richong Zhang https://arxiv.org/abs/2412.09165 10
Shallow Neural Networksの時代 2013年頃〜 単語埋め込みの登場 代表的な手法・モデル • Word2Vec (CBOW, Skip-Gram)
• GloVe • FastText 実用性は低いものの “king - man + woman = queen” には Wow! が あった 11
Deep Neural Networkの時代 2015年頃〜 LSTMやGRUを使ったセンテンス埋め込みの登場 代表的な手法・モデル • Skip-Thoughts • USE
(Universal Sentence Encoder) 12
Pre-trained Language Modelsの時代 2019年〜 Encoder-only事前学習モデル(BERT)をfine-tuneした高性能なセンテンス埋 め込みモデルが登場 Contrastive Learningが特に重要なパラダイム 代表的な手法・モデル •
Sentense-BERT • ANCE • SimCSE このあたりからText Embeddingが実用的になり始めた(ように思う) 13
Large Language Modelの時代 2020年代 論文では,Encoder-DecoderまたはDecoder-onlyアーキテクチャかつ パラメータ数1B以上をLLMと定義している。 代表的な手法・モデル • T5 •
LLaMAシリーズ • Qwenシリーズ • GPTシリーズ • Geminiシリーズ 14
おまけ The 1950-2024 Text Embeddings Evolution Poster by Jina AI
https://jina.ai/news/the-1950-2024-text-embeddin gs-evolution-poster/ 15
LLM以降のEmbeddingのトレンド • 高次元 • 多目的 • 多言語 • マルチモーダル Takeaway
② 16
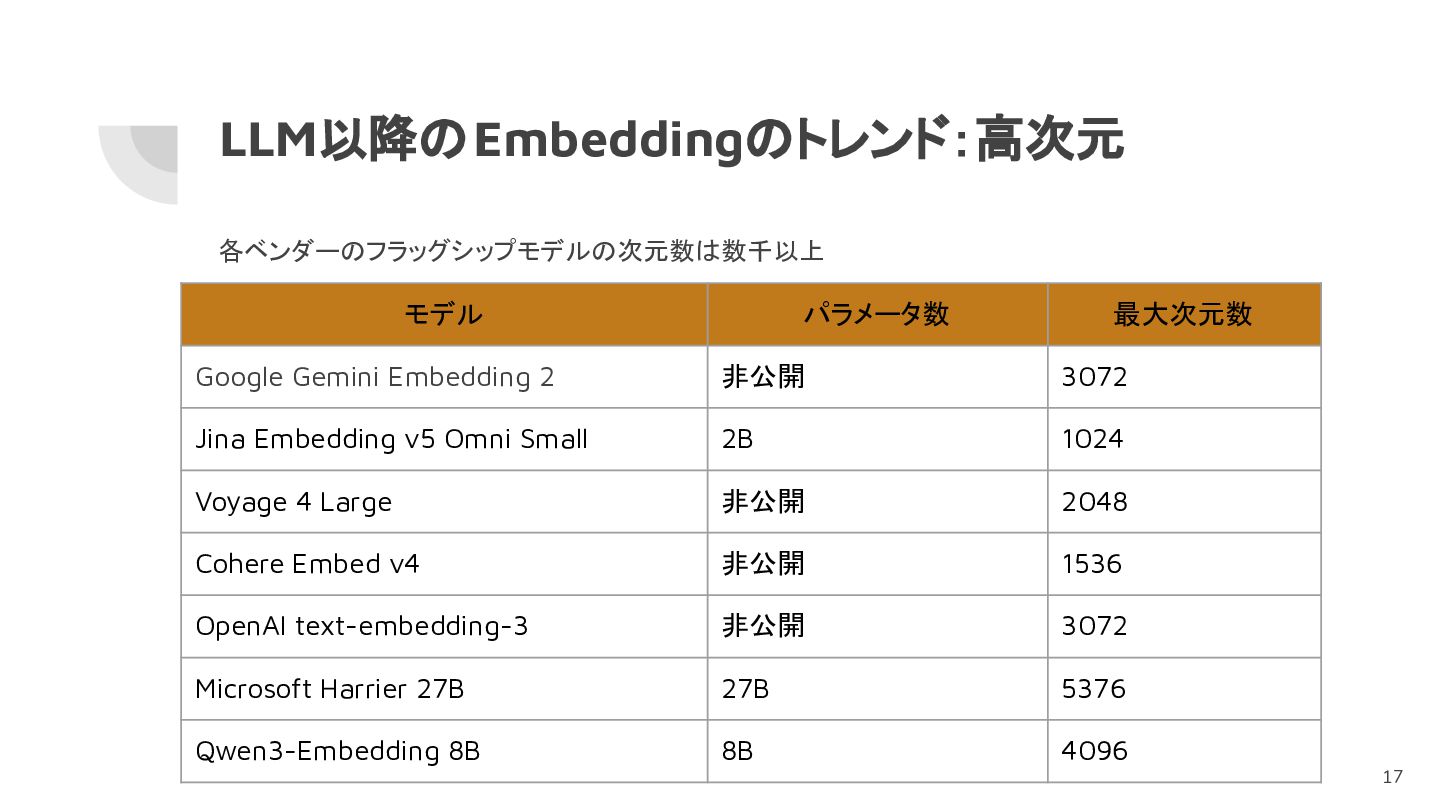
LLM以降のEmbeddingのトレンド:高次元 モデル パラメータ数 最大次元数 Google Gemini Embedding 2 非公開 3072
Jina Embedding v5 Omni Small 2B 1024 Voyage 4 Large 非公開 2048 Cohere Embed v4 非公開 1536 OpenAI text-embedding-3 非公開 3072 Microsoft Harrier 27B 27B 5376 Qwen3-Embedding 8B 8B 4096 各ベンダーのフラッグシップモデルの次元数は数千以上 17
LLM以降のEmbeddingのトレンド:多目的 モデルシリーズ サポートしているタスク Google Gemini Embedding 2 classification, clustering, retrieval,
similarity Jina Embedding v5 Omni classification, clustering, retrieval, text match Voyage 4 retrieval Cohere Embed v4 classification, clustering, retrieval OpenAI text-embedding-3 汎用 (非公開) Microsoft Harrier 汎用 (非公開) Qwen3-Embedding 汎用 (非公開) 1つのモデルでさまざまなタスク(ダウンストリームアプリケーション)に対応する 18
LLM以降のEmbeddingのトレンド:多言語 モデルシリーズ サポートしている言語数 Google Gemini Embedding 2 100+ Jina Embedding
v5 Omni 100+ Voyage 4 非公開 Cohere Embed v4 100+ OpenAI text-embedding-3 非公開 Microsoft Harrier 94 Qwen3-Embedding 100+ 1つのモデルで多数の言語に対応する 19
LLM以降のEmbeddingのトレンド:マルチモーダル モデルシリーズ サポートしているモダリティ Google Gemini Embedding 2 テキスト・画像・PDF・動画・音声 Jina Embedding
v5 Omni テキスト・画像・PDF・動画・音声 Voyage Multimodal 3.5 テキスト・画像・PDF・動画 Cohere Embed v4 テキスト・画像 OpenAI text-embedding-3 テキスト Microsoft Harrier テキスト Qwen3-Embedding テキスト 1つのモデルで複数のモダリティに対応する 20
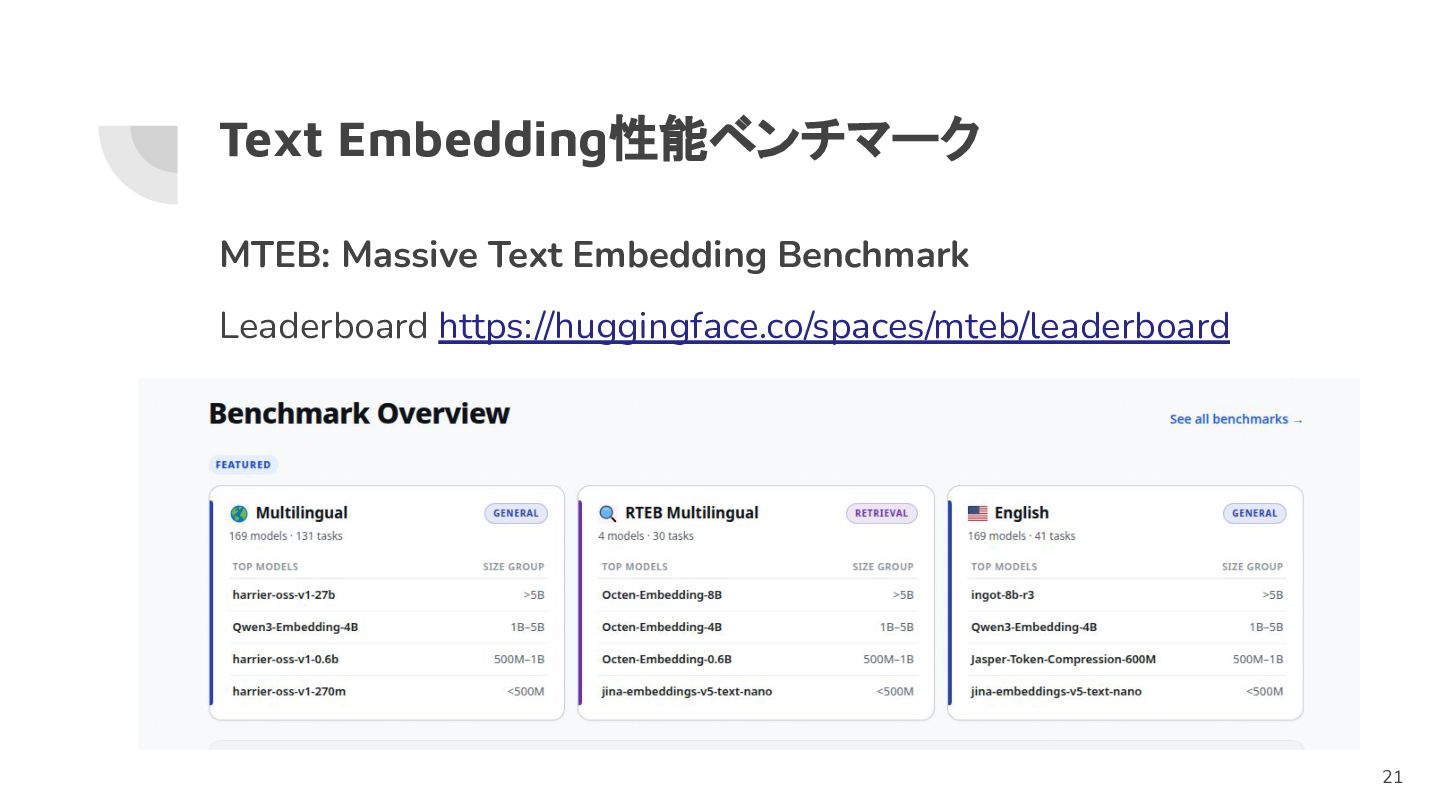
Text Embedding性能ベンチマーク MTEB: Massive Text Embedding Benchmark Leaderboard https://huggingface.co/spaces/mteb/leaderboard 21
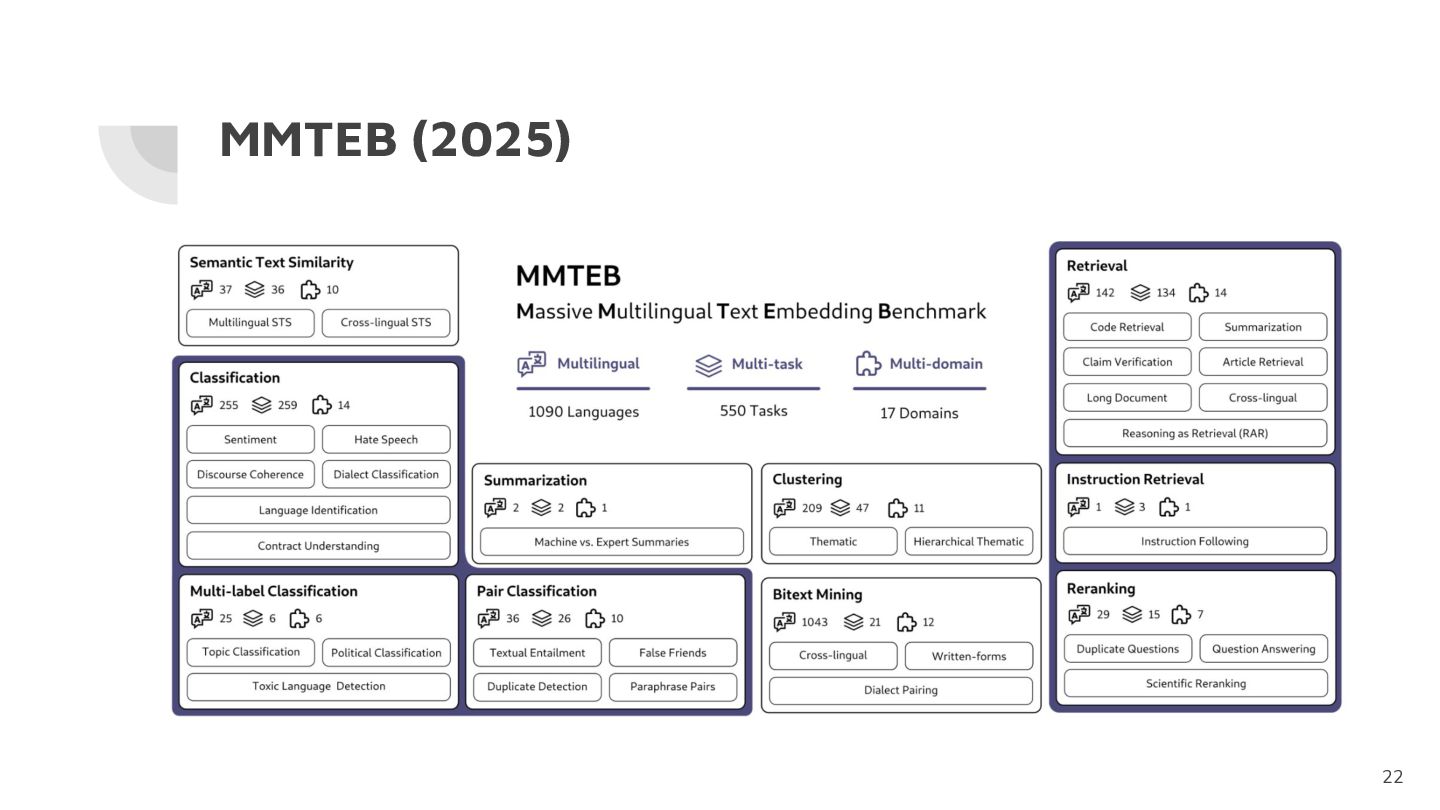
MMTEB (2025) 22
著名なプロプライエタリモデル (MTEB Multilingualリーダーボードから) • 👑 Google Gemini Embedding 2 •
Voyage 4 ◦ Voyage AIは MongoDB の系列会社 • Cohere Embed v4 ◦ Cohere は Oracle が支援している会社 • OpenAI text-embedding-3 23
著名なOSSモデル (MTEB Multilingualリーダーボードから) • 👑 Microsoft Harrier 27B • Qwen3-Embedding
8B • Jina Embedding v5 omni ◦ Jina AI は Elastic の系列会社 24
もっと深く知りたい方へ 直感 LLM ―ハンズオンで動かして学ぶ大規模言語モデル入門 (原題:Hands-On Large Language Models) Jay Alammar、Maarten
Grootendorst著、中山 光樹訳 https://www.oreilly.co.jp/books/9784814401154/ ラフを用いた近似最近傍探索の理論と応用 Advanced 25
近似最近傍探索 Approximate Nearest Neighbor Search 26
類似度計算を速くする 数百次元以上のDense Vectorの類似度計算コストは高い。 クエリベクトルと全てのドキュメントベクトルのコサイン類似度を総当りで 計算していると高コストで遅すぎる。 ⇛ 総当りではなく,近似計算をするのが近似最近傍探索。英語では Approximate Nearest Neighbor
Search (ANN) 27
近似最近傍探索アルゴリズム • クラスタリングベース ◦ IVF-PQ / ScaNN • グラフベース ◦
HNSW, HNSW+PQ / NGT • ディスクフレンドリー ◦ DiskANN / SPANN たくさんあるが,実務上はIVF-PQとHNSWだけ覚えていればOK Takeaway ③ 28
IVF-PQ Product Quantization for Nearest Neighbor Search (2011) Hervé Jégou,
Matthijs Douze, Cordelia Schmid https://inria.hal.science/inria-00514462v2/document アルゴリズムの名前よりも,その実装の「Faissライブラリ」として有名 29
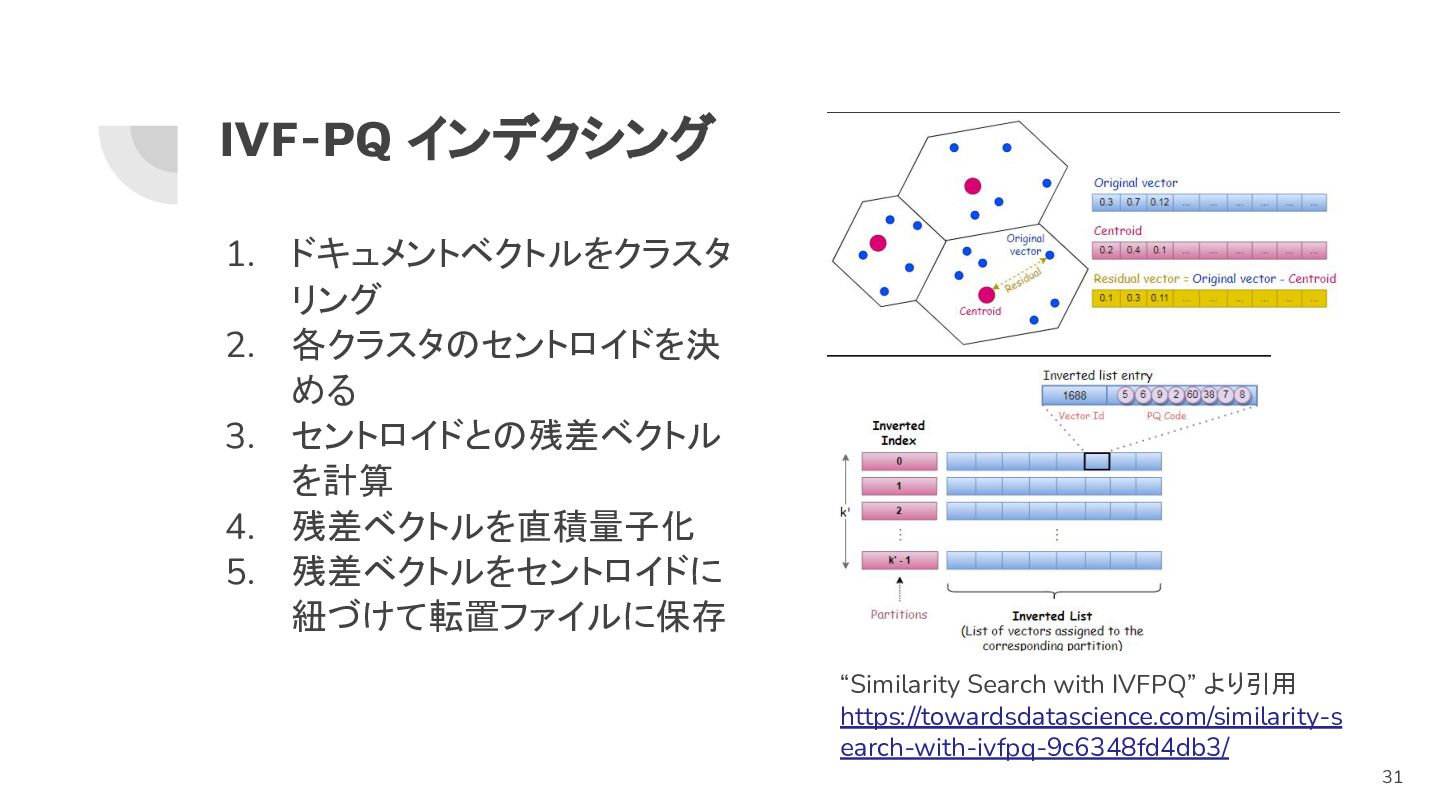
IVF-PQ のアイディア インデクシング時:ドキュメントベク トルをクラスタリングする 検索時:クエリベクトルと近いクラス タを決め,そのクラスタ内で近傍を 決める “Similarity Search with
IVFPQ” より引用 https://towardsdatascience.com/similarity-s earch-with-ivfpq-9c6348fd4db3/ 30
IVF-PQ インデクシング 1. ドキュメントベクトルをクラスタ リング 2. 各クラスタのセントロイドを決 める 3. セントロイドとの残差ベクトル
を計算 4. 残差ベクトルを直積量子化 5. 残差ベクトルをセントロイドに 紐づけて転置ファイルに保存 “Similarity Search with IVFPQ” より引用 https://towardsdatascience.com/similarity-s earch-with-ivfpq-9c6348fd4db3/ 31
IVF-PQ 検索 1. クエリベクトルに近いセントロ イドを探索 2. セントロイドとの残差ベクトル を計算 3. 転置ファイルを辿りクラスタ内
の全ベクトルとの距離を計算 4. クラスタ内でもっとも近いド キュメントベクトル群を再近傍 として返す “Similarity Search with IVFPQ” より引用 https://towardsdatascience.com/similarity-s earch-with-ivfpq-9c6348fd4db3/ 32
HNSW Efficient and robust approximate nearest neighbor search using Hierarchical
Navigable Small World graphs (2016) Yu. A. Malkov, D. A. Yashunin https://arxiv.org/abs/1603.09320 HNSWを置き換えるアルゴリズムは今のところ存在せず,2026現在も デファクトスタンダード 33
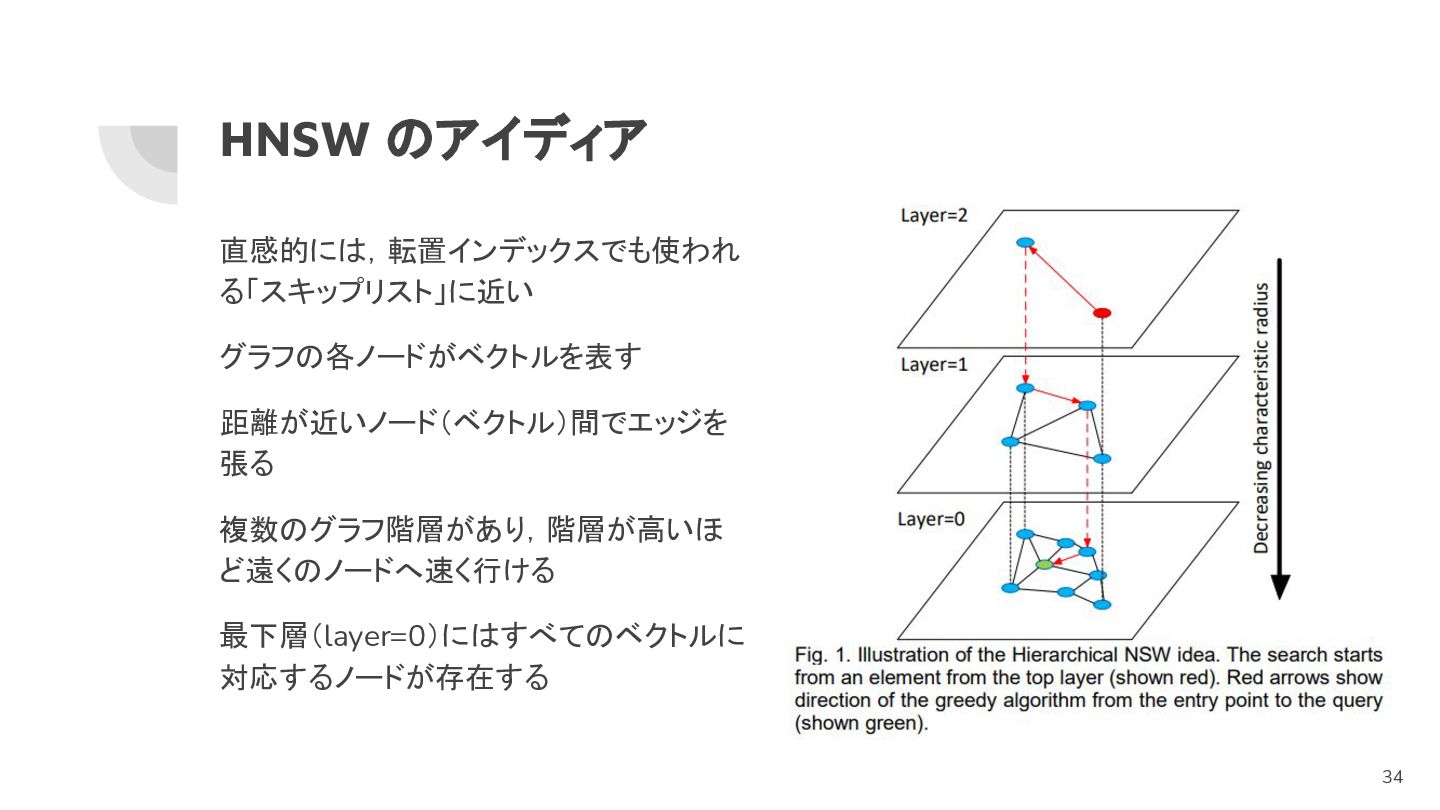
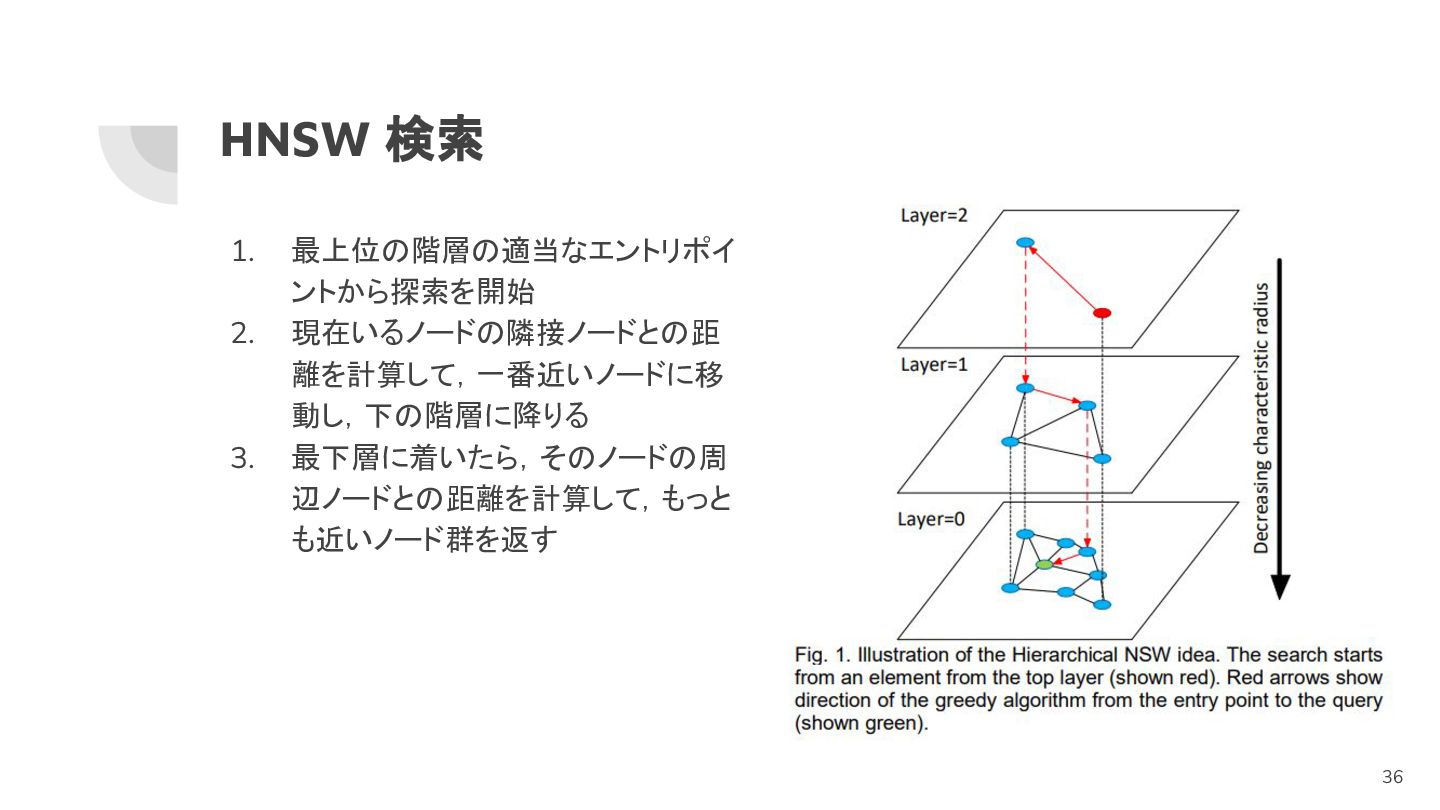
HNSW のアイディア 直感的には,転置インデックスでも使われ る「スキップリスト」に近い グラフの各ノードがベクトルを表す 距離が近いノード(ベクトル)間でエッジを 張る 複数のグラフ階層があり,階層が高いほ ど遠くのノードへ速く行ける 最下層(layer=0)にはすべてのベクトルに
対応するノードが存在する 34
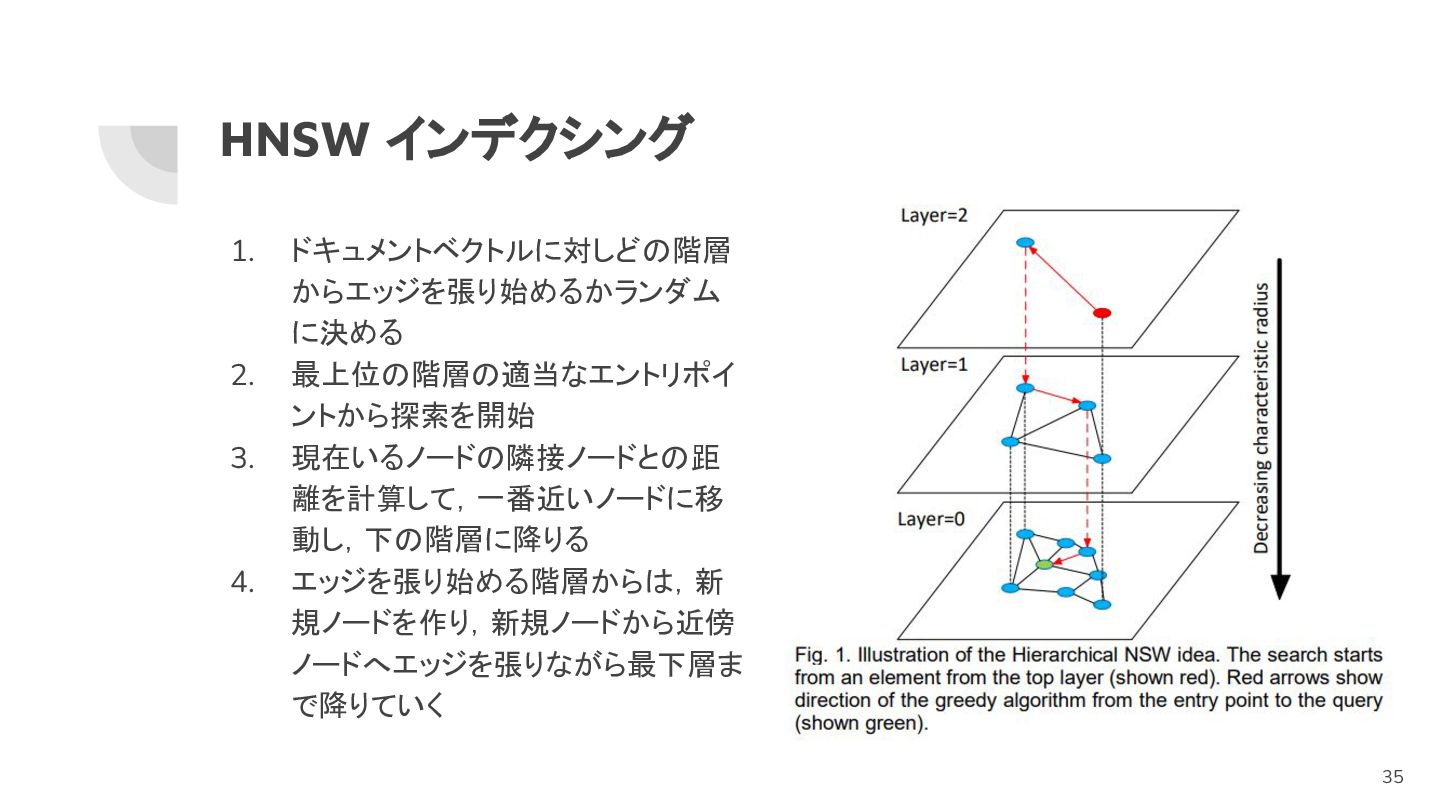
HNSW インデクシング 1. ドキュメントベクトルに対しどの階層 からエッジを張り始めるかランダム に決める 2. 最上位の階層の適当なエントリポイ ントから探索を開始 3.
現在いるノードの隣接ノードとの距 離を計算して,一番近いノードに移 動し,下の階層に降りる 4. エッジを張り始める階層からは,新 規ノードを作り,新規ノードから近傍 ノードへエッジを張りながら最下層ま で降りていく 35
HNSW 検索 1. 最上位の階層の適当なエントリポイ ントから探索を開始 2. 現在いるノードの隣接ノードとの距 離を計算して,一番近いノードに移 動し,下の階層に降りる 3.
最下層に着いたら,そのノードの周 辺ノードとの距離を計算して,もっと も近いノード群を返す 36
もっと深く知りたい方へ NLP若手の会 (YANS) 第18回シンポジウム (2023) チュートリアル グラフを用いた近似最近傍探索の理論と応用 松井 勇佑(東京大学) https://speakerdeck.com/matsui_528/gurahuwoyong-itajin-si-zui-jin-ban
g-tan-suo-noli-lun-toying-yong ラフを用いた近似最近傍探索の理論と応用 Advanced 37
ベクトル検索エンジン(ベクトル DB) IVFPQを実装している検索エンジン • Milvus, LanceDB ScaNNを実装している検索エンジン • Vertex AI
Vector Search, AlloyDB HNSWを実装している検索エンジン • Milvus, Qdrant, Weaviate, LanceDB, Elasticsearch/OpenSearch/Solr (Lucene系) • 他,著名なRDBやKVSにはだいたい実装されている DiskANNを実装している検索エンジン • Milvus, meilisearch, Azure SQL Database, Azure Cosmos DB 38
最適化テクニック① 次元削減 39
高次元Embeddingの問題 • Gemini Embedding 2 の次元数は3072 • 各次元はfloat32 (4 bytes)
• 100万個のドキュメントがあると,ベクトルデータだけで 4 x 3072 x 1,000,000 bytes ≒ 11 GiB ベクトルデータのサイズが増えると何が問題? ベクトル検索エンジンで類似度計算をするときに,ベクトルデータを逐一ディスクから読 んでRAMに載せる ⇨ランダムディスクアクセスが大量発生して検索が遅延 ⇨ベクトルデータを最初から全部 RAMに載せておこうとすると大容量のマシンがいる 40
Embeddingの次元数を減らしたい • ベクトルデータのサイズは次元数に比例するため次元数が半分に なるとデータサイズが単純に半分になる • 次元数が低いとより多くのベクトルデータをページキャッシュに載せ られるため高速に検索できる • 精度と次元数のトレードオフ ◦
精度を落とさずに次元数を減らせるほど良いアルゴリズム 41
Embedding生成後に次元を削減する 主成分分析 (PCA) ベクトルを束ねて行列とし,行列の線形変換で分散が最大となる軸を見 つけて第1主成分とし,以下同様に第2,第3主成分...,とする。適当な 数の主成分を選んで次元削減する MRL(次ページ)以降はEmbeddingの次元削減ではあまり使われない 42
モデルの学習に次元削減を組み込む 🪆Matryoshka Representation Learning (2022) Aditya Kusupati, Gantavya Bhatt, Aniket
Rege, Matthew Wallingford, Aditya Sinha, Vivek Ramanujan, William Howard-Snyder, Kaifeng Chen, Sham Kakade, Prateek Jain, Ali Farhadi https://arxiv.org/abs/2205.13147 新しめのEmbeddingモデルはほぼ全て MRLをサポートしている Takeaway ④ 43
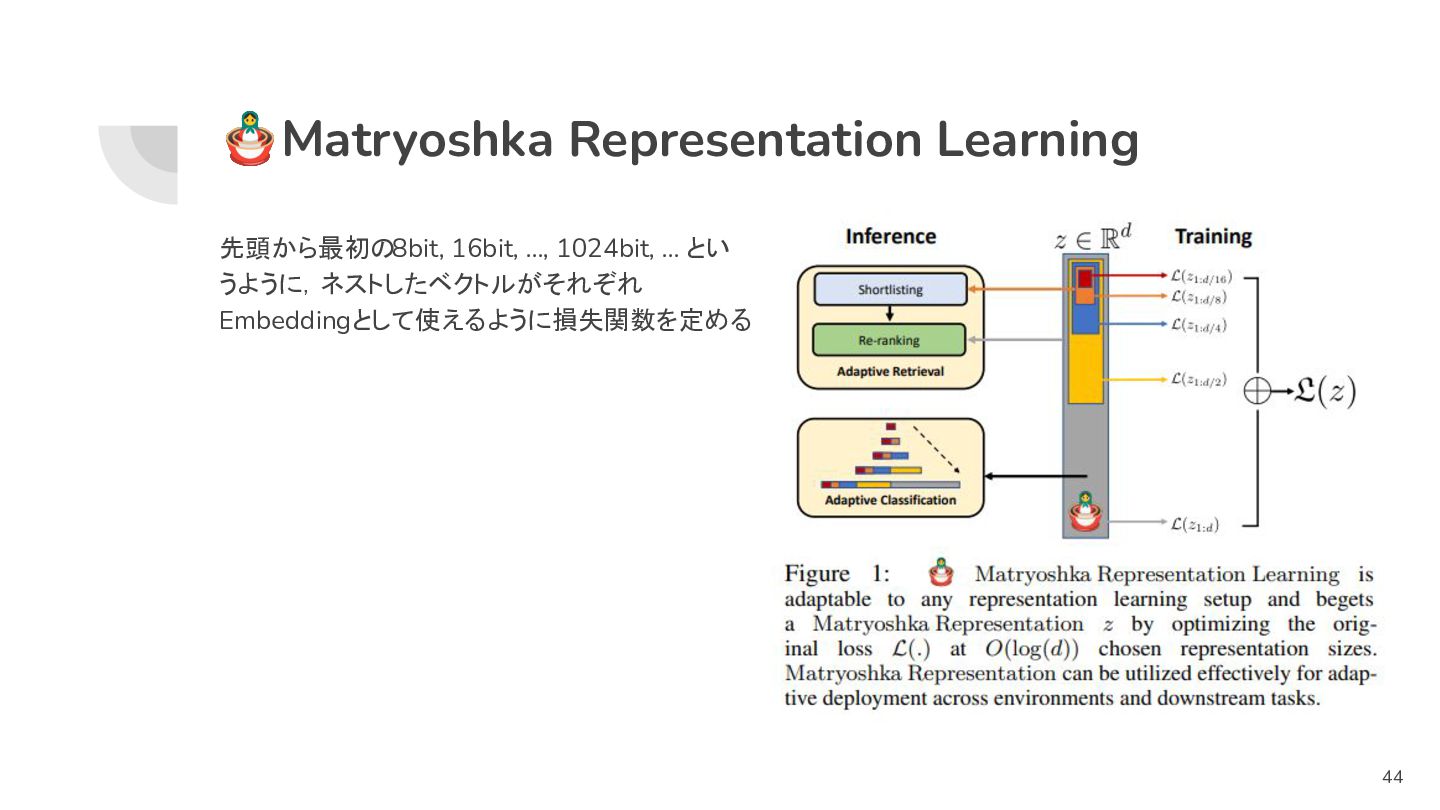
🪆Matryoshka Representation Learning 先頭から最初の8bit, 16bit, …, 1024bit, … とい うように,ネストしたベクトルがそれぞれ
Embeddingとして使えるように損失関数を定める 44
実験:MRL次元削減 データ: Amazon Products Dataset の商品データ10万件 クエリ:LLMで生成した商品検索自然言語クエリ50個 埋め込みモデル:Qwen3-Embedding-4B 次元数:2560 (default),
2048, 1024, 768, 512, 256, 64 評価指標: • nDCG@10 (2560 dimをground truthとする) • Jaccard 係数 (2560 dim との集合類似度) • Kendall's tau (2560 dimとの順位相関) ベクトル検索エンジン:Qdrant 45
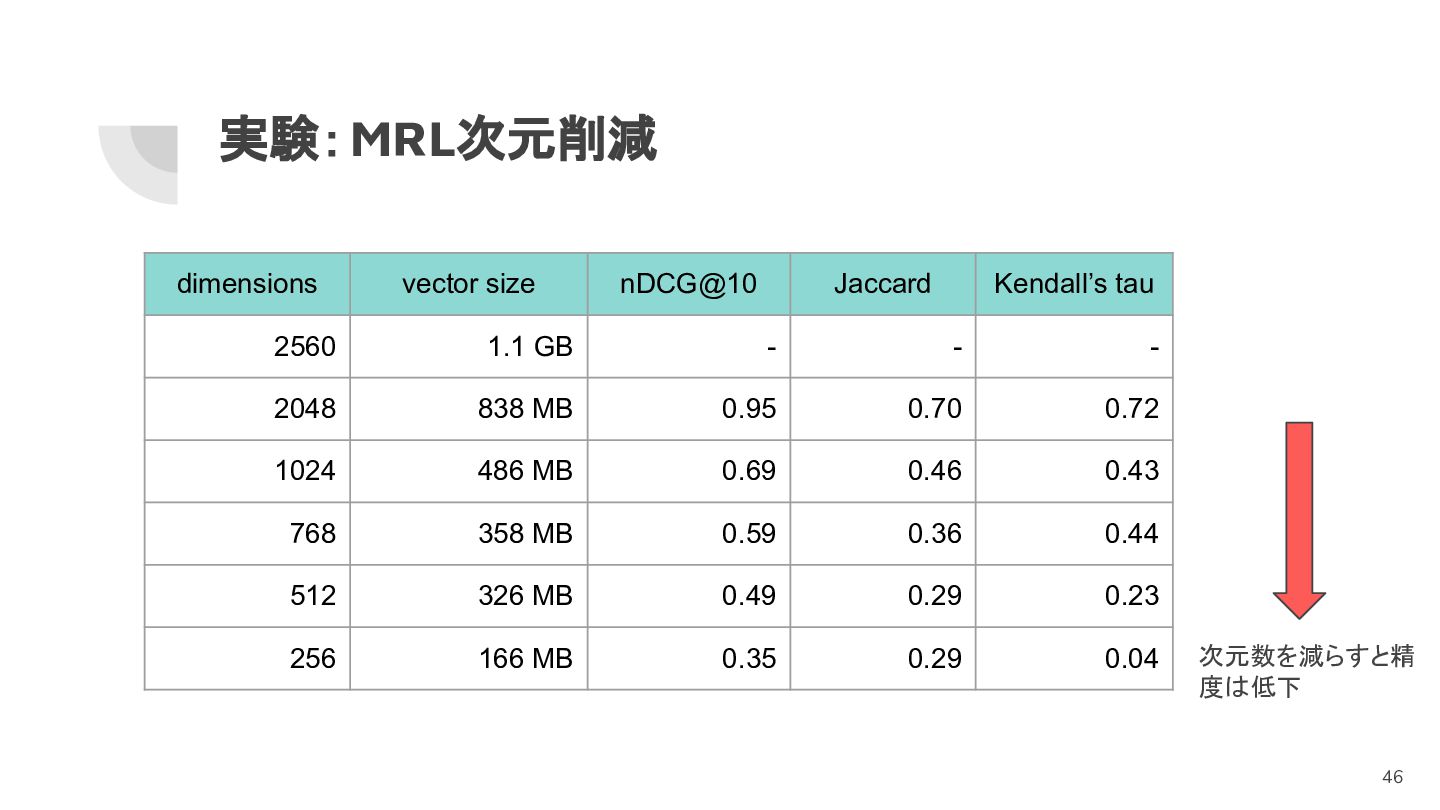
実験:MRL次元削減 dimensions vector size nDCG@10 Jaccard Kendall’s tau 2560 1.1
GB - - - 2048 838 MB 0.95 0.70 0.72 1024 486 MB 0.69 0.46 0.43 768 358 MB 0.59 0.36 0.44 512 326 MB 0.49 0.29 0.23 256 166 MB 0.35 0.29 0.04 次元数を減らすと精 度は低下 46
最適化テクニック② 量子化 47
Embeddingの要素サイズを小さくしたい • Embeddingの各要素は float32 (4 bytes) • 各要素をより小さなバイト(ビット)数で表現するのが量子化テクニッ ク •
圧縮率が高いとより多くのベクトルデータをキャッシュできるため高 速に検索できる • 精度と圧縮率のトレードオフ ◦ 精度を落とさずに圧縮率を高くできるほど良いアルゴリズム 48
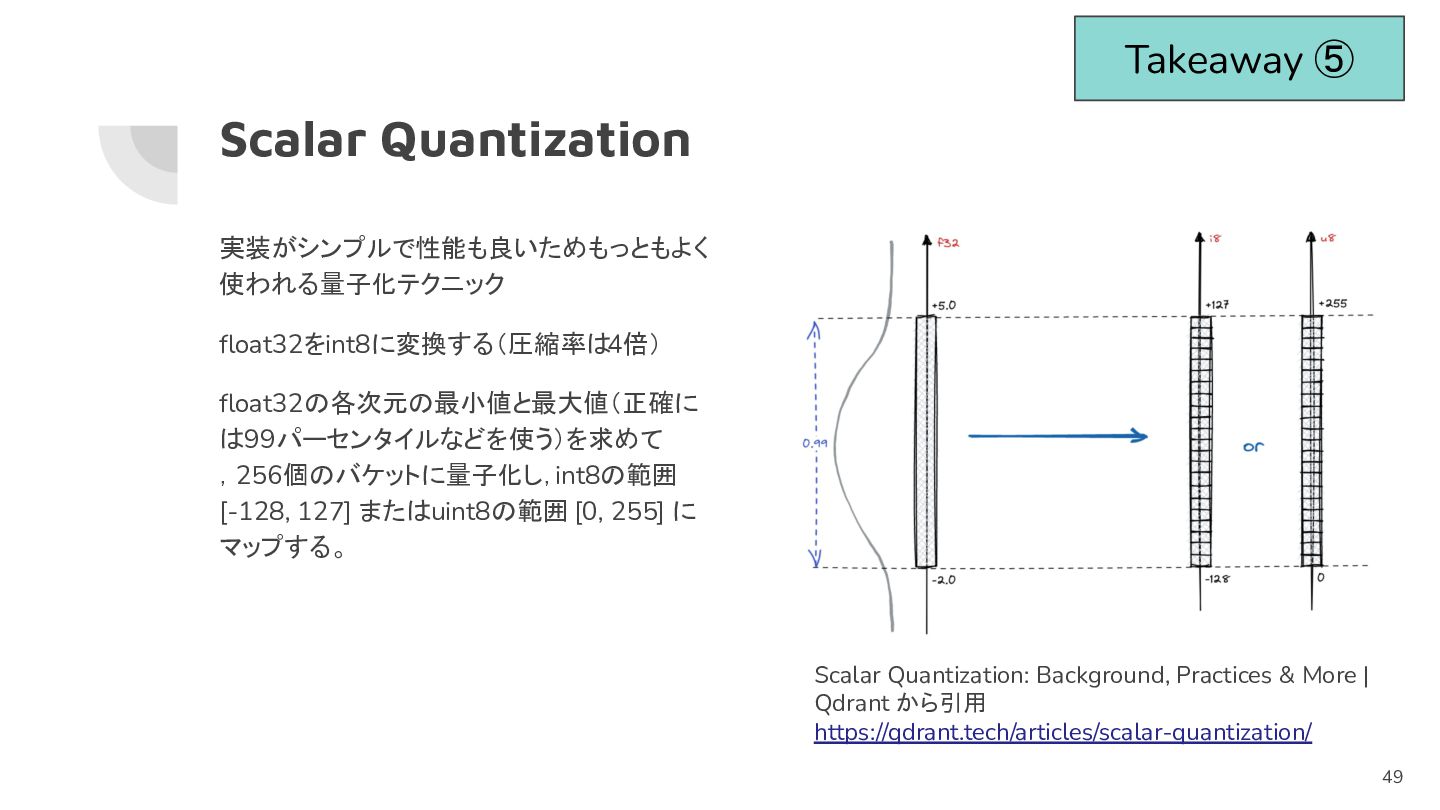
Scalar Quantization 実装がシンプルで性能も良いためもっともよく 使われる量子化テクニック float32をint8に変換する(圧縮率は4倍) float32の各次元の最小値と最大値(正確に は99パーセンタイルなどを使う)を求めて ,256個のバケットに量子化し, int8の範囲 [-128,
127] またはuint8の範囲 [0, 255] に マップする。 Scalar Quantization: Background, Practices & More | Qdrant から引用 https://qdrant.tech/articles/scalar-quantization/ Takeaway ⑤ 49
TurboQuant TurboQuant: Online Vector Quantization with Near-optimal Distortion Rate (2025)
Amir Zandieh, Majid Daliri, Majid Hadian, Vahab Mirrokni https://arxiv.org/abs/2504.19874 2026年3月に発表された時,メモリー関連企業 の株価がなぜか一時パニックになった Advanced 50
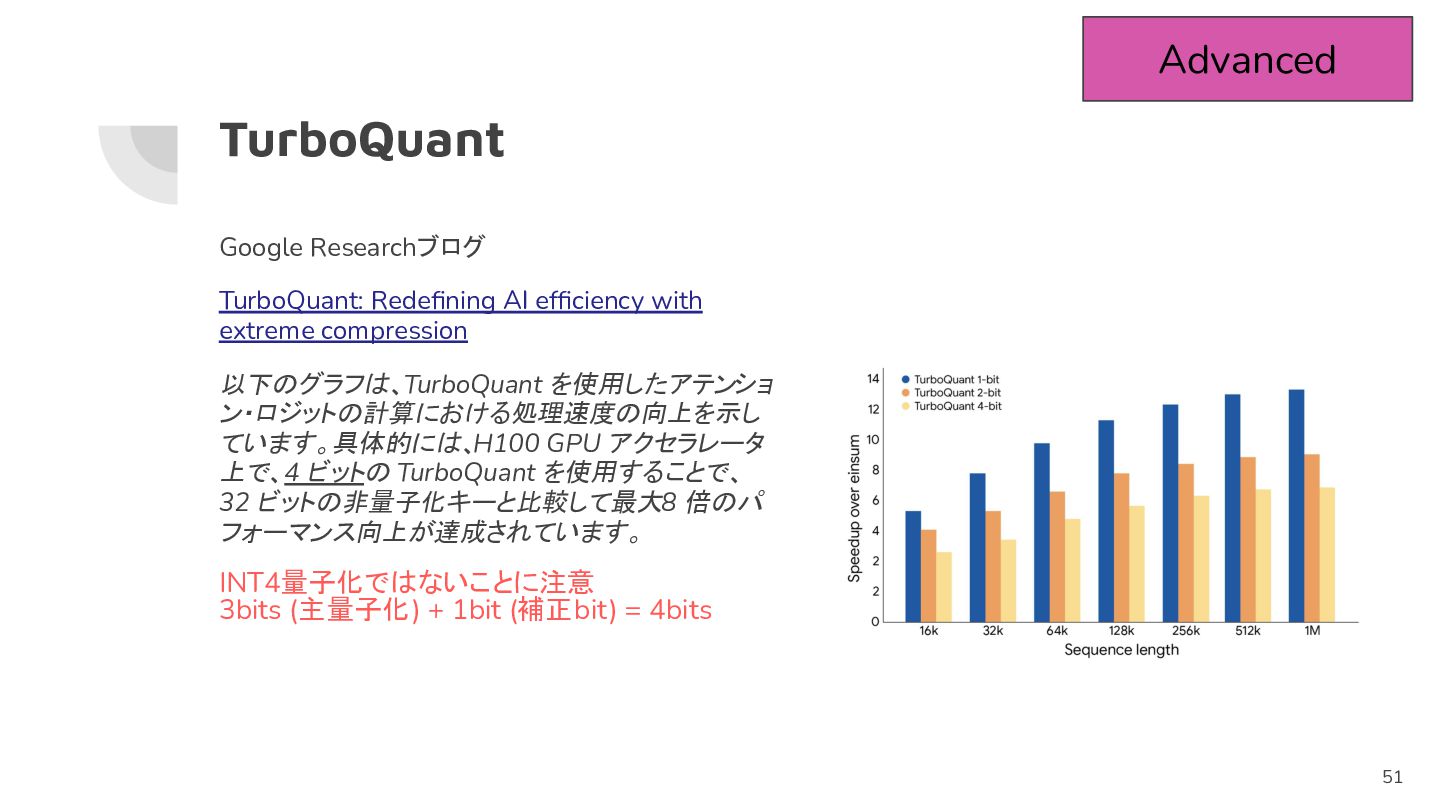
TurboQuant Google Researchブログ TurboQuant: Redefining AI efficiency with extreme compression
以下のグラフは、TurboQuant を使用したアテンショ ン・ロジットの計算における処理速度の向上を示し ています。具体的には、H100 GPU アクセラレータ 上で、4 ビットの TurboQuant を使用することで、 32 ビットの非量子化キーと比較して最大 8 倍のパ フォーマンス向上が達成されています。 INT4量子化ではないことに注意 3bits (主量子化) + 1bit (補正bit) = 4bits Advanced 51
TurboQuant TurboQuantを実装しているベクトル検索エンジンは少ないが Qdrantから利用できる TurboQuant in Qdrant TQ (TurboQuant) 4ビットは、SQ (Scalar
Quantization)と同等の性能を持ちながら、 ストレージ容量は半分で済みます。 52
実験:量子化 データ: Amazon Products Dataset の商品データ10万件 クエリ:LLMで生成した商品検索自然言語クエリ50個 埋め込みモデル:Qwen3-Embedding-4B 次元数:2560 量子化:None,
Scalar, PQ, TurboQuant 評価指標:nDCG@10, Jaccard 係数, Kendall’s tau ベクトル検索エンジン:Qdrant 53
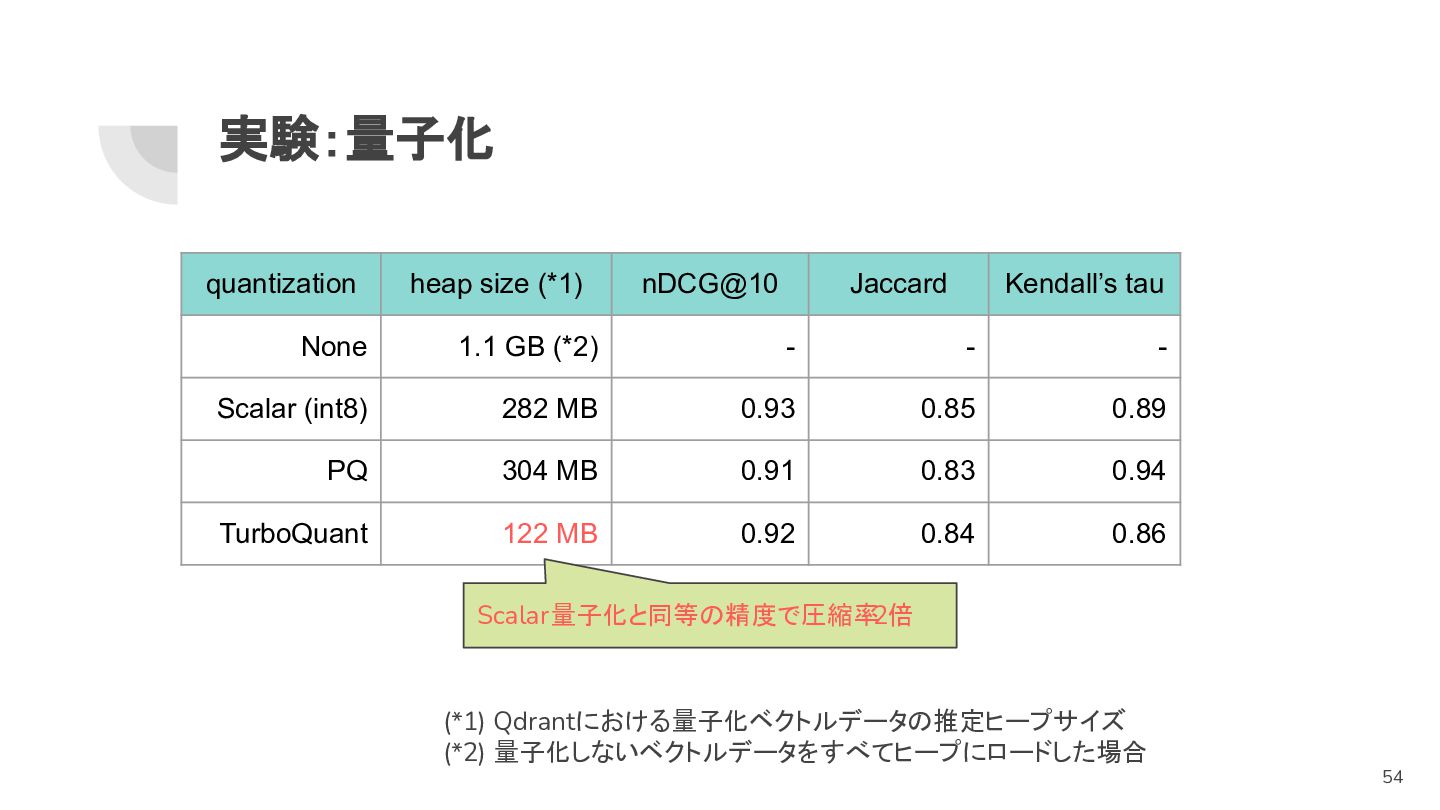
実験:量子化 quantization heap size (*1) nDCG@10 Jaccard Kendall’s tau None
1.1 GB (*2) - - - Scalar (int8) 282 MB 0.93 0.85 0.89 PQ 304 MB 0.91 0.83 0.94 TurboQuant 122 MB 0.92 0.84 0.86 (*1) Qdrantにおける量子化ベクトルデータの推定ヒープサイズ (*2) 量子化しないベクトルデータをすべてヒープにロードした場合 Scalar量子化と同等の精度で圧縮率 2倍 54
ご静聴ありがとうございました Happy Searching! 🔎 55
We Are Hiring! LegalOn Technologiesでは一緒に働く仲間を募集しています! • Software Engineer- WorkOn
◦ https://herp.careers/v1/legalforce/KIK9kjM-0W2o • Software Engineer - AI Agent & Search ◦ https://herp.careers/v1/legalforce/ks1PLdpASjby その他オープン中の開発職JDはこちら https://herp.careers/v1/legalforce/requisition-groups/d2e157cc-12 0b-4ade-8879-0326c32127bd 56
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}