supported by OSM-aware tools ORC - supported by the Hadoop ecosystem OSM data model - (partially) supported by OSM-aware tools OGC data model - supported by everything else
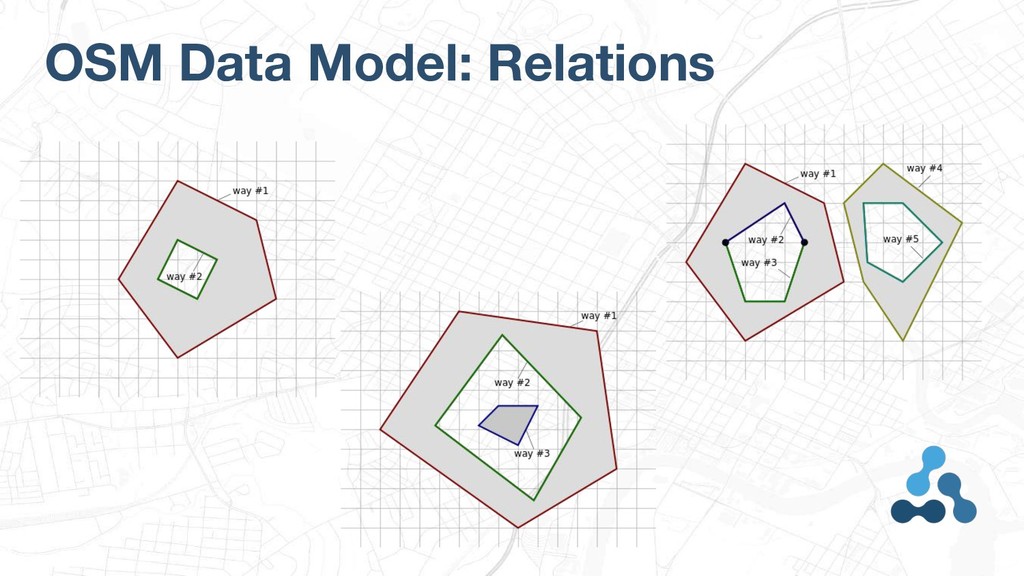
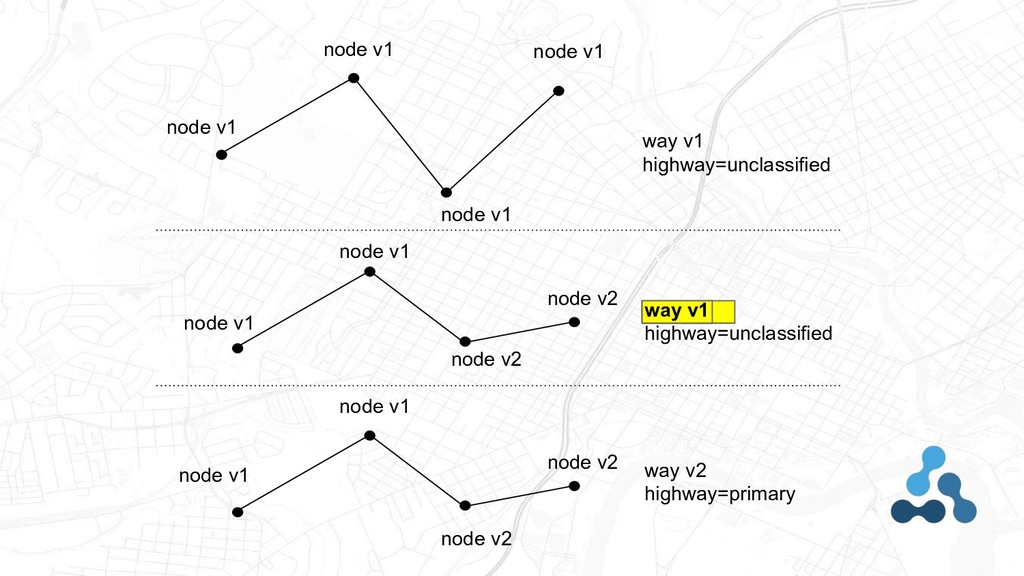
3 elements: • Nodes - Points • Ways - LineStrings, Polygons • Relations - GeometryCollections, Polygon with holes, MultiPolygons As well as the tag-based metadata that applies to each elements, and changesets grouping edits
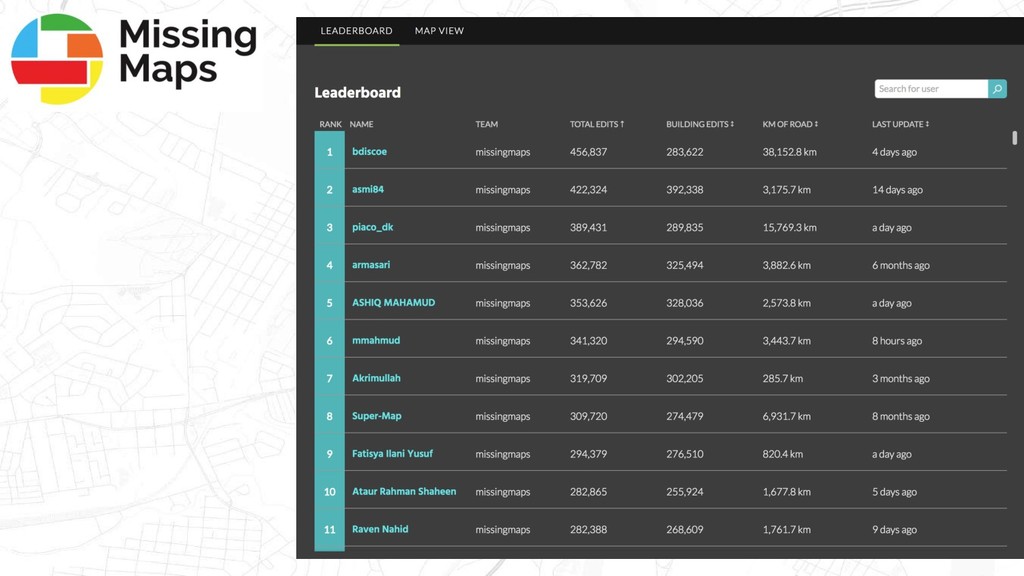
which have their own metadata such as use comments (for developers, think commit messages) • Adding hashtags to user comments allows downstream processing to group changes - for example, #HOTLunch
To do this, we need needed to create a concept of “minor versions” of geometries • We converted timestamp to an update date that propagates up to the way or relation • We added a “valid_until” tag on elements that tells when an element is no longer valid (either replaced or deleted) Creating features from History
that contain geometries of every element in OSM history, with ways/relations representing every edit to the element as well as elements that they contain • Then, we compute statistics per changeset based on geometries, and roll up the statistics per user and hashtag Full historical geometries
minutes (cluster of 255 m3.2xlarge nodes) • This is not a small cluster ( ≈$65/hour). YMMV with smaller clusters. • We are building update mechanisms to avoid refreshing the entire dataset • Produces 600GB of ORC Processing OSM data at scale
is a big question in the OSM community right now (according to SOTM US 2017) • HOT Tasking manager does some; we can do better • One way to improve validation workflows is to suggest validation be done by veteran mappers, validation be suggested for more junior mappers (“reputations core”) • Development Seed, who contribute & uses OSMesa work, have great ideas in this space.
geospatial imagery and OSM into training chips - a distributed label-maker • Managing data into and out of Raster Vision • Post-processing by cleaning the model output, matching to OSM or other vector data to remove duplicates, conflation workflows • Matching OSM to imagery dates: e.g. pre- and post- disaster.
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}