Upgrade to Pro
— share decks privately, control downloads, hide ads and more …
Speaker Deck
Features
Speaker Deck
PRO
Sign in
Sign up for free
Search
Search
ニコニコ大百科と日本語情報抽出方法の検当
Search
Mokke Meguru
March 30, 2020
Research
0
2.5k
ニコニコ大百科と日本語情報抽出方法の検当
サイボウズ・ラボユース第9期成果発表会
Mokke Meguru
March 30, 2020
Tweet
Share
Other Decks in Research
See All in Research
データサイエンティストの業務変化
datascientistsociety
PRO
0
330
競合や要望に流されない─B2B SaaSでミニマム要件を決めるリアルな取り組み / Don't be swayed by competitors or requests - A real effort to determine minimum requirements for B2B SaaS
kaminashi
0
1.2k
生成AI による論文執筆サポート・ワークショップ データ分析/論文ドラフト編 / Generative AI-Assisted Paper Writing Support Workshop: Data Analysis and Drafting Edition
ks91
PRO
0
110
2026.01ウェビナー資料
elith
0
330
製造業主導型経済からサービス経済化における中間層形成メカニズムのパラダイムシフト
yamotty
0
540
svc-hook: hooking system calls on ARM64 by binary rewriting
retrage
2
180
都市交通マスタープランとその後への期待@熊本商工会議所・熊本経済同友会
trafficbrain
0
180
「車1割削減、渋滞半減、公共交通2倍」を 熊本から岡山へ@RACDA設立30周年記念都市交通フォーラム2026
trafficbrain
1
840
Self-Hosted WebAssembly Runtime for Runtime-Neutral Checkpoint/Restore in Edge–Cloud Continuum
chikuwait
0
430
Dwangoでの漫画データ活用〜漫画理解と動画作成〜@コミック工学シンポジウム2025
kzmssk
0
190
2026 東京科学大 情報通信系 研究室紹介 (大岡山)
icttitech
0
1.2k
2026-01-30-MandSL-textbook-jp-cos-lod
yegusa
1
810
Featured
See All Featured
BBQ
matthewcrist
89
10k
Building AI with AI
inesmontani
PRO
1
830
Bridging the Design Gap: How Collaborative Modelling removes blockers to flow between stakeholders and teams @FastFlow conf
baasie
0
490
Chasing Engaging Ingredients in Design
codingconduct
0
150
The State of eCommerce SEO: How to Win in Today's Products SERPs - #SEOweek
aleyda
2
10k
The innovator’s Mindset - Leading Through an Era of Exponential Change - McGill University 2025
jdejongh
PRO
1
140
New Earth Scene 8
popppiees
2
1.9k
RailsConf & Balkan Ruby 2019: The Past, Present, and Future of Rails at GitHub
eileencodes
141
35k
My Coaching Mixtape
mlcsv
0
87
Git: the NoSQL Database
bkeepers
PRO
432
67k
The Hidden Cost of Media on the Web [PixelPalooza 2025]
tammyeverts
2
260
Primal Persuasion: How to Engage the Brain for Learning That Lasts
tmiket
0
300
Transcript
ニコニコ大百科と 日本語情報抽出方法の 検討 サイボウズ・ラボユース 第9期 成果報告会 江畑 拓哉 メンター: 中谷
秀洋 2020.03.30 あ
自己紹介 項目 値 所属 筑波大学大学院CS専攻1年(03/30 現在) サイボウズ・ラボユース第9期 ホームページ https://mokkemeguru.github.io/portfolio/ Github
https://github.com/MokkeMeguru 研究 対話システム / 自然言語処理 / 深層学習一般 開発 Web系一般
動機 ニコニコ大百科の知識を コンピュータに理解させたい コンピュータが知識を獲得すると何が良いのか? - その知識を用いて対話システムを組むことができる ⇒ 知識がないと話ができない、対話システムのコアの一つ - Question-Answering
ができる - 情報検索ができる Copyrights © 2005-2020 AHS Co. Ltd. All rights reserved. 知識 発話 応答
動機 ニコニコ大百科の知識を コンピュータに理解させたい コンピュータが知識を理解させるには? 1. <主語,述語,目的語> のタプルで構成されるDBを作り、その処理系を実装する 2. 何らかの機械学習モデルを用いて、大量のテキストから尤度の高い関連文を抽出する 3.
とても大きな言語モデルに大量のテキストを学習させて、転移学習させる Etc.
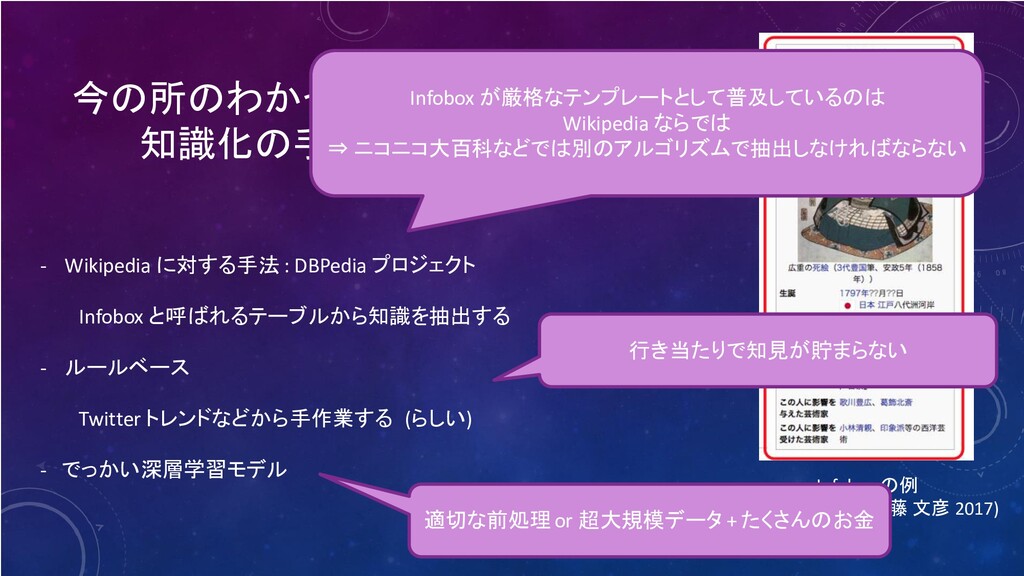
今の所のわかっている 知識化の手法 - Wikipedia に対する手法 : DBPedia プロジェクト Infobox と呼ばれるテーブルから知識を抽出する
- ルールベース Twitter トレンドなどから手作業する (らしい) - でっかい深層学習モデル Infobox の例 (DBpediaの現在 加藤 文彦 2017)
今の所のわかっている 知識化の手法 Infobox の例 (DBpediaの現在 加藤 文彦 2017) Infobox が厳格なテンプレートとして普及しているのは
Wikipedia ならでは ⇒ ニコニコ大百科などでは別のアルゴリズムで抽出しなければならない 行き当たりで知見が貯まらない - Wikipedia に対する手法 : DBPedia プロジェクト Infobox と呼ばれるテーブルから知識を抽出する - ルールベース Twitter トレンドなどから手作業する (らしい) - でっかい深層学習モデル 適切な前処理or 超大規模データ + たくさんのお金
今回やること ニコニコ大百科を 観察 & 調査 + 適切な前処理を 考察する データの観察 データ特徴のまとめ
前処理の提案 前処理実装 前処理実験 前処理効果の考察
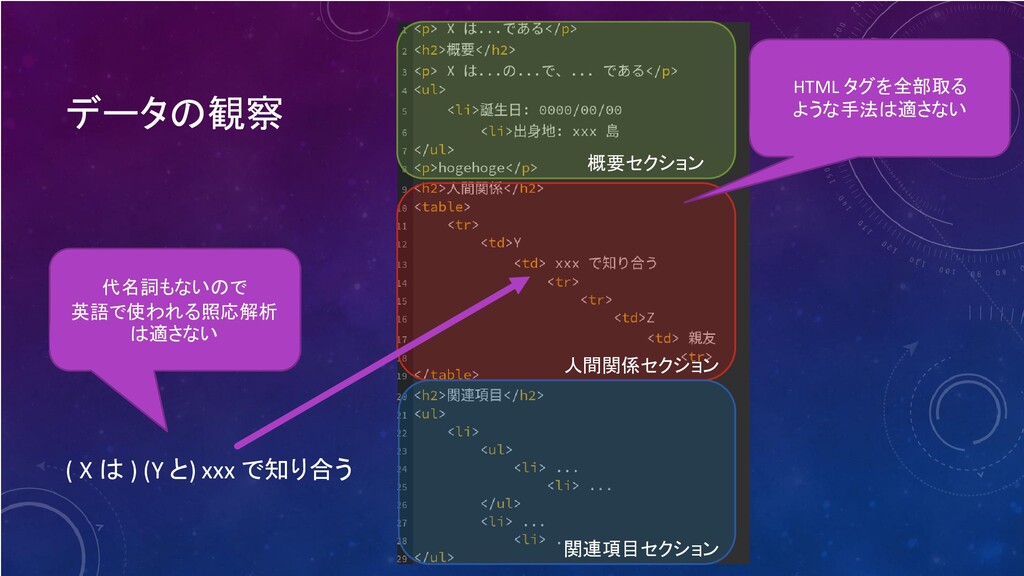
データの観察 わかったこと - 記事が細かくセクション分割されている セパレータは hi (1 ≦ i ≦
4, 5?) タグ ⇒ div タグでも section タグでもない - 主語の省略など、日本人が読める記事になっている - リストやテーブルを多用するが、規約が決まっているわけではない - リンクもたくさんあるが、たまに正しくなさそうなリンクもある - AA (アスキーアート) やスクリプト など、解析が大変になる要素が沢山
データの観察 ( X は ) (Y と) xxx で知り合う 概要セクション
人間関係セクション 関連項目セクション HTML タグを全部取る ような手法は適さない 代名詞もないので 英語で使われる照応解析 は適さない
前処理の提案(1) 記事をセクション分割して、その範囲内でいくつかの処理を行う まずできること ほとんどの記事にある、「概要」セクションについて抜き出し、 主語のない問題(ゼロ主語問題)について考える ↓ 概要部分の文はちゃんと取り出せる? どのくらい主語のない文が含まれている? 欠けている主語の傾向は? 作業レポジトリ
https://github.com/MokkeMeguru/subject-complements/blob/master/評価結果.org
前処理実装 (1) / 前処理実験 調査結果 発表資料 https://www.nii.ac.jp/dsc/idr/userforum/poster/IDR-UF2019_P11.pdf できている 83% できていない
9% 判断できない 8% 概要部分の文抽出精度 タイトル 67% タイトルでない 33% 欠けている主語が 記事タイトルである割合 半分近くが主語が欠けている 欠けている 45% 欠けていない 55% 主語の欠けている文の割合 少なくとも概要部の多くは 主語で記事タイトルを 補完できる
前処理の提案(2) HTML → JSON + Sectionalize もともと HTML を Hiccup
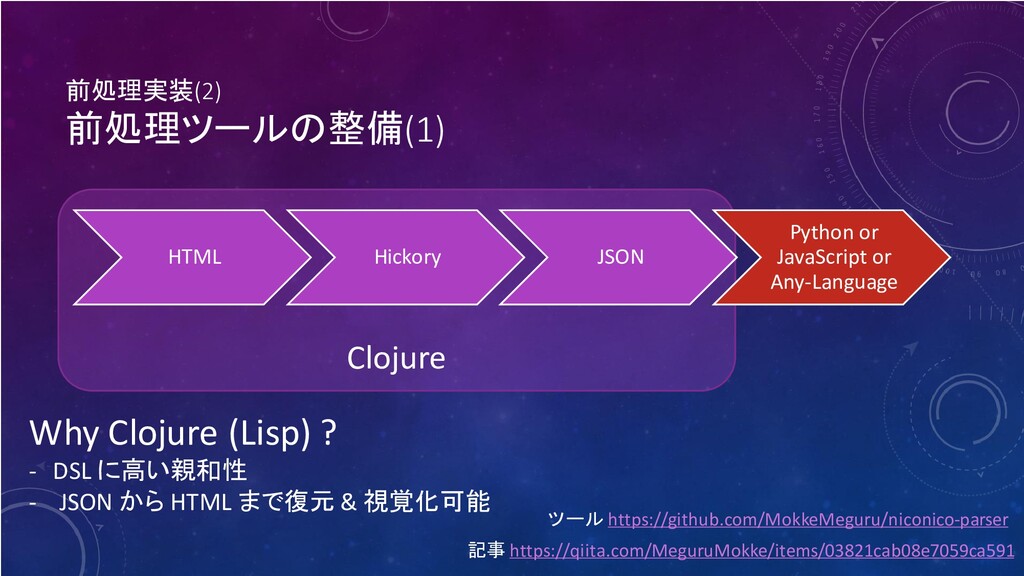
という形式にして処理していた ⇒ 使うことのできる言語が狭められる (Clojure/ClojureScript) もっと汎用的な形式で保存して、解析しやすくする ⇒ JSON 化 Why JSON? - セクションごとの分割が大変(先に分割処理を施したい) - Pythonとの相性 (JSON ↔ Python の辞書構造) - MongoDBとの相性
Clojure 前処理実装(2) 前処理ツールの整備(1) ツール https://github.com/MokkeMeguru/niconico-parser HTML Hickory JSON Python or
JavaScript or Any-Language Why Clojure (Lisp) ? - DSL に高い親和性 - JSON から HTML まで復元 & 視覚化可能 記事 https://qiita.com/MeguruMokke/items/03821cab08e7059ca591
前処理実装(2) 前処理ツールの整備(2) JNMongo の開発 JSON 化した記事を読み込んで、 Python+ MongoDB で解析するツール +
チュートリアル 目的 - 分析する知見を貯める - 今の課題は? - 無駄な再発明の防止 ツール https://github.com/MokkeMeguru/jnmongo
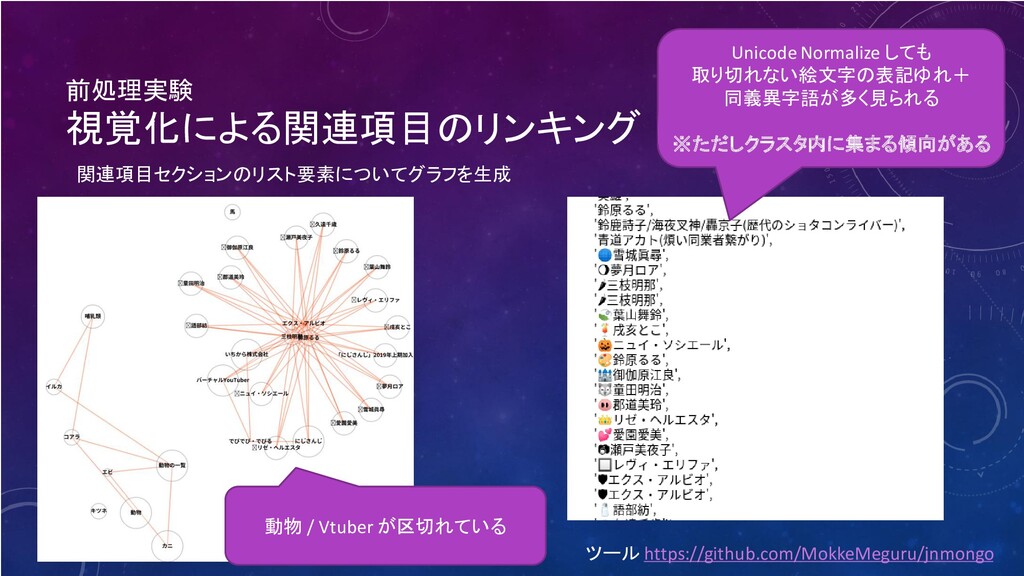
前処理実験 視覚化による関連項目のリンキング 動物 / Vtuber が区切れている Unicode Normalize しても 取り切れない絵文字の表記ゆれ+
同義異字語が多く見られる ※ただしクラスタ内に集まる傾向がある 関連項目セクションのリスト要素についてグラフを生成 ツール https://github.com/MokkeMeguru/jnmongo
前処理効果の考察・今後の課題 • ニコニコ大百科 / 日本語ならではの課題を洗い出すことができた • 特にニコニコ大百科についての特徴である、「セクション分割」という特徴を生か した前処理をいくつか提案し、実装、試験し、特にゼロ主語の問題については有 意な解決策を提案できた •
Pixiv大百科や Wikipedia についても同様のことが言えるのかを調査をしたい • 他研究者のために、より定量的な評価を導入したい
まとめ • ニコニコ大百科について、知識化をするための前処理について実験、 考察、ツールの開発を行った • 特に「ゼロ主語」、「セクション分割」について注目し、前処理を行った • 今後の研究のためにツールの整備・チュートリアルの作成をした Thank you
for watching
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}