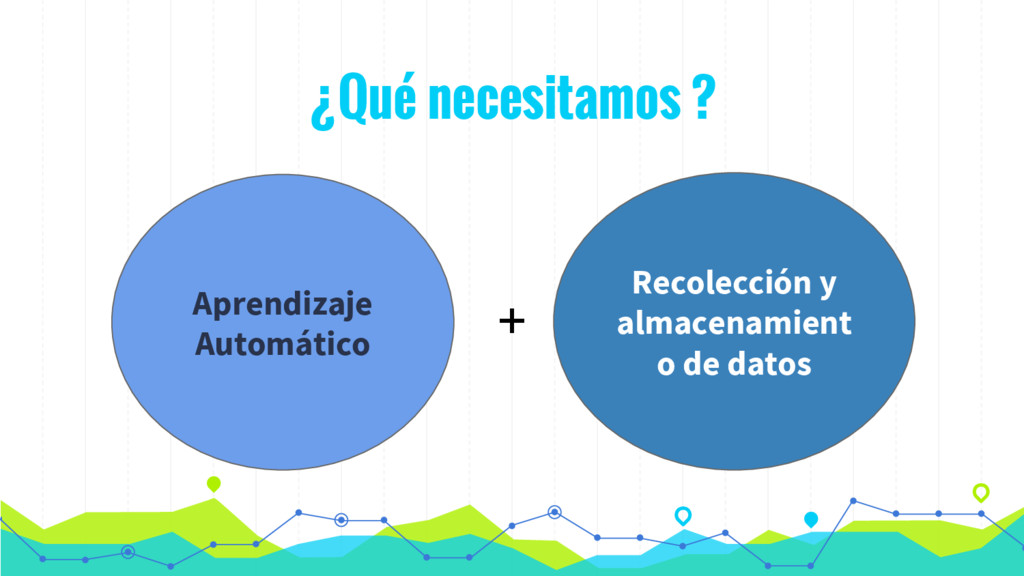
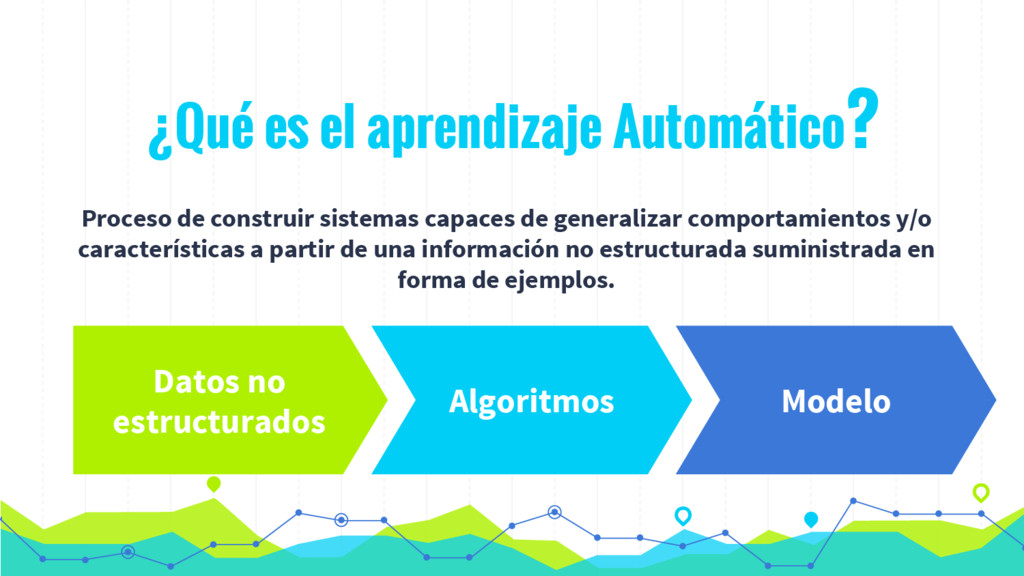
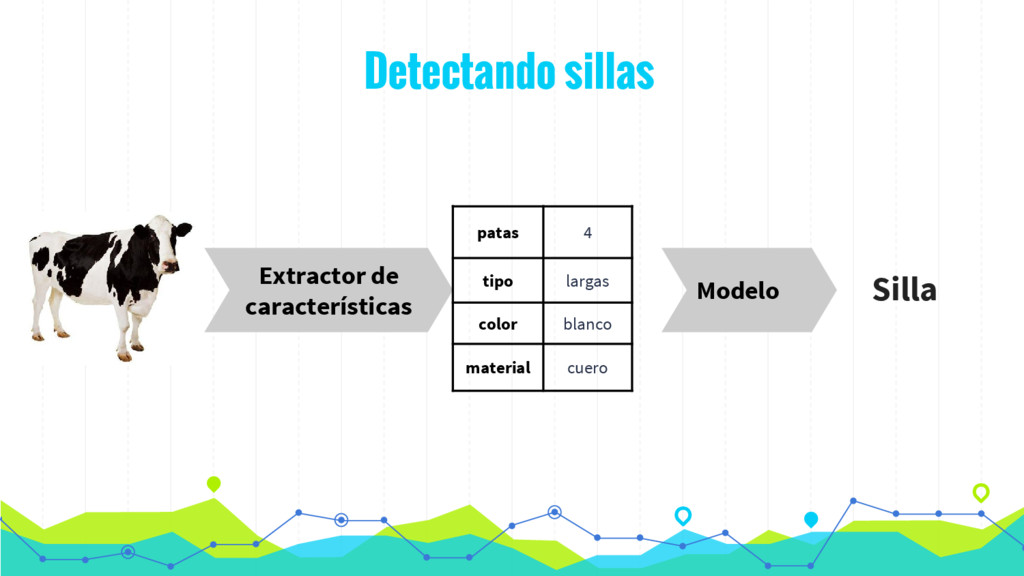
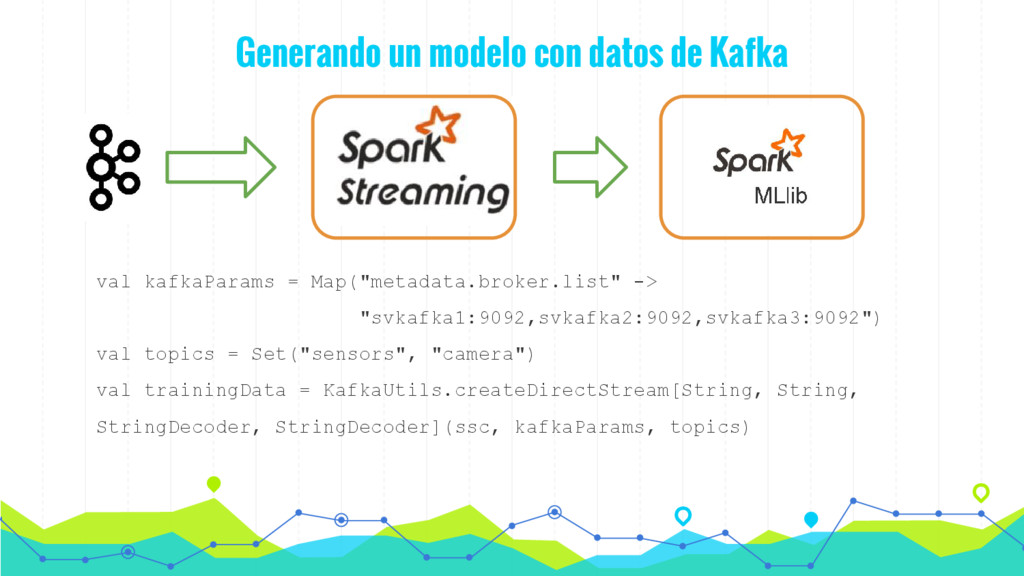
En los últimos años se está produciendo un uso intensivo de las técnicas de aprendizaje automático con el fin de construir sistemas más interactivos que mejoren la experiencia del usuarios. Los algoritmos de aprendizaje automático (ML) nos permiten identificar características o información sobre nuestros usuarios o sobre el comportamiento de nuestros sistemas que sería imposible de forma manual. Aunque el uso de estos algoritmos presenta dos importantes problemas: (1) el coste computacional de construcción del modelo; y (2) la accesibilidad a los datos en tiempo real.
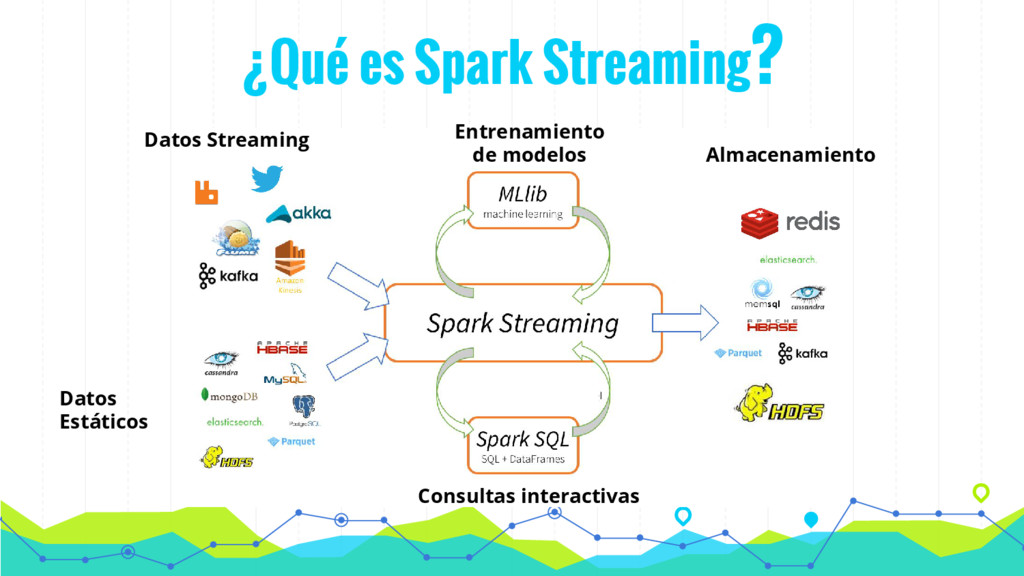
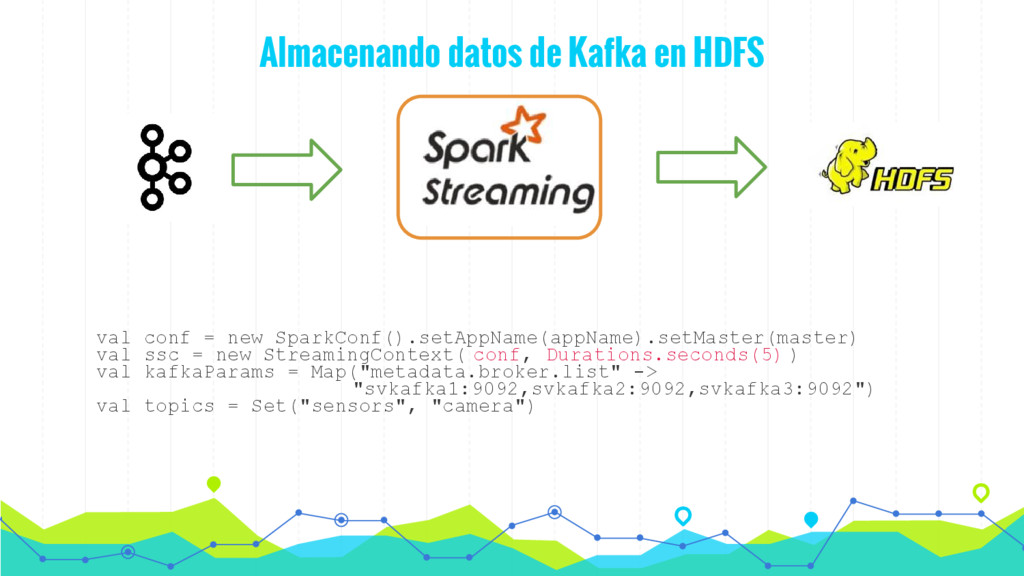
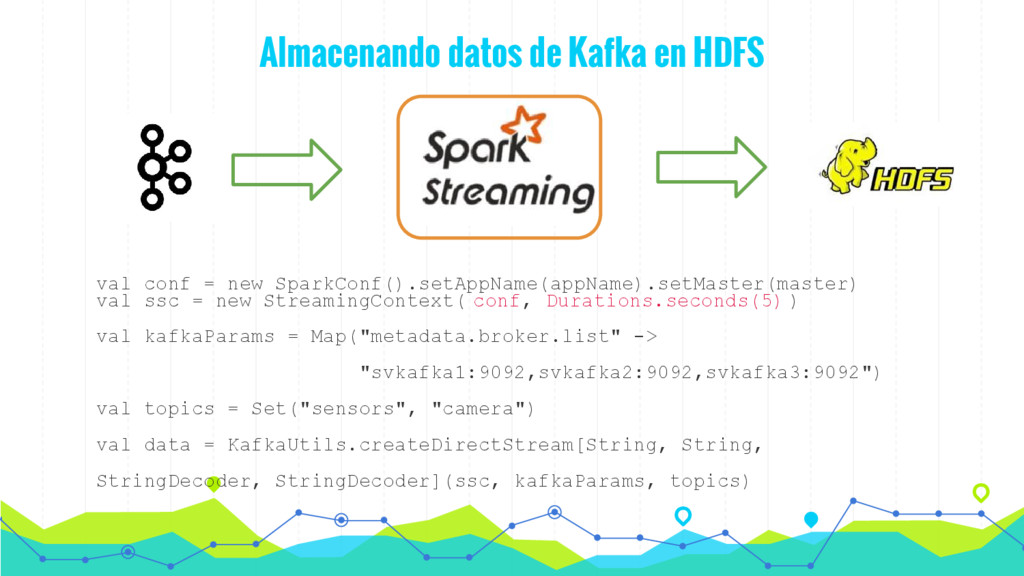
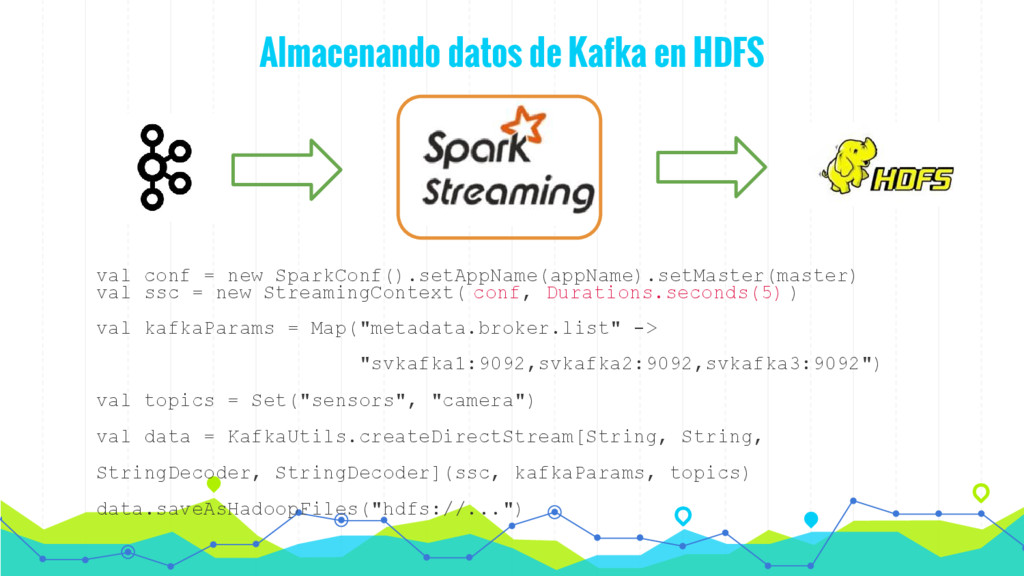
En esta charla presentaremos de forma sencilla como procesar datos en tiempo real (streaming) mediante la utilización de algoritmos de Machine Learning mediante Spark y MLlib. De esta forma podemos hacer evolucionar nuestro modelo en tiempo real de acuerdo con los datos que vamos recibiendo y tomar decisiones en tiempo real.
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
![GRACIAS! Preguntas? Puedes encontrarme en @moisipm / [email protected]](https://files.speakerdeck.com/presentations/8e0defaae73e47bb8b35ba5756084528/slide_50.jpg){kind=link}
{kind=link}