This four hour online conference will introduce you to some MongoDB basics and get you up to speed with why and how you should choose MongoDB for your next project.
Mac OS-X, Solaris Drivers are available in many languages 10gen supported • C, C# (.Net), C++, Erlang, Haskell, Java, JavaScript, Perl, PHP, Python, Ruby, Scala, nodejs! • Multiple community supported drivers The image cannot be displayed. Your computer may not have enough memory to open the image, or the image may have been corrupted. Restart your computer, and then open the file again. If the red x
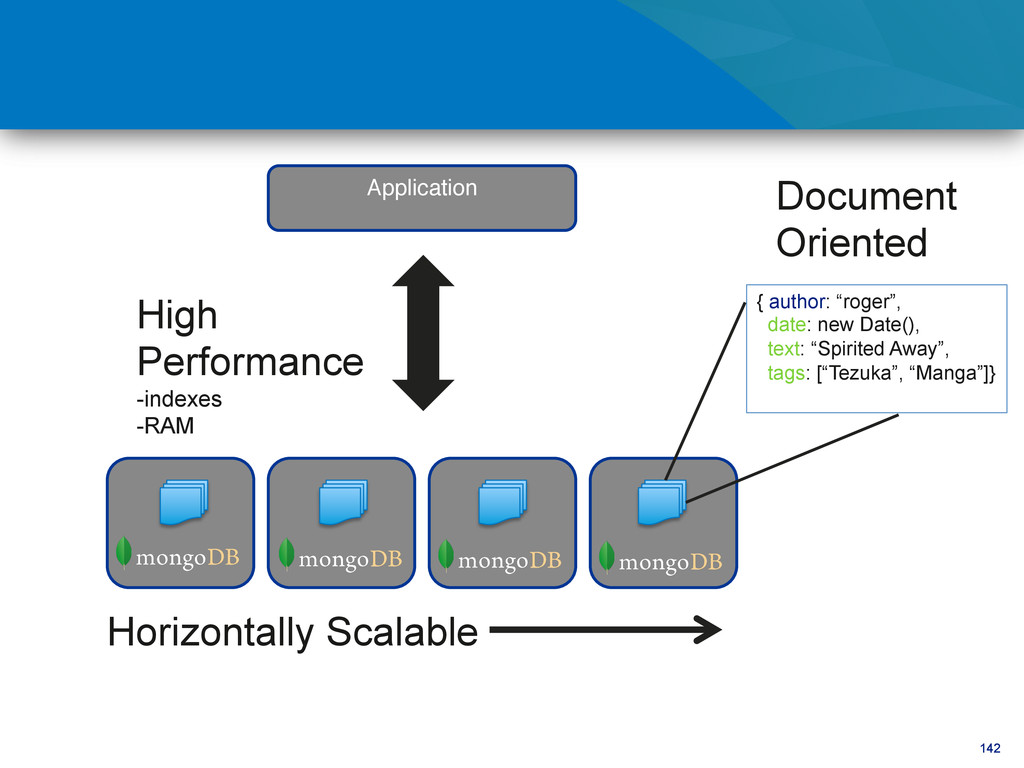
Mongo extends datatypes with Date, Int types, Id, … • MongoDB stores data in BSON • BSON is a binary representation of JSON – Optimized for performance and navigational abilities – Also compression See: bsonspec.org!
Super low latency access to your data • Very little CPU overhead • No additional caching layer required • Built in replication and horizontal scaling support
to find other locations nearby" • Need to store locations (Offices, Restaurants, etc) – name, address, tags – coordinates – User generated content e.g. tips / notes
to 'checkin' to a location" Checkins – User should be able to 'check in' to a location – Want to be able to generate statistics: • Recent checkins • Popular locations
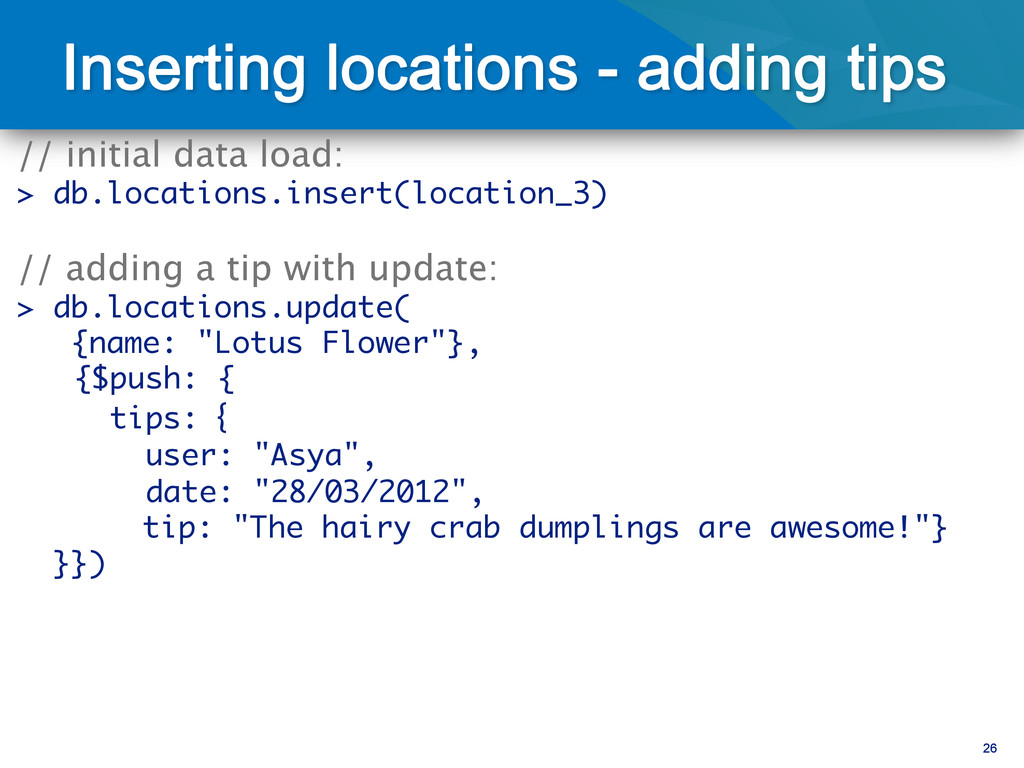
a tip with update: > db.locations.update( {name: "Lotus Flower"}, {$push: { tips: { user: "Asya", date: "28/03/2012", tip: "The hairy crab dumplings are awesome!"} }})
to 'checkin' to a location" Checkins – User should be able to 'check in' to a location – Want to be able to generate statistics: • Recent checkins • Popular locations
> db.users.find({"checkins.location":"Lotus Flower"}) // find the last 10 checkins here: - Warning! > db.users.find({"checkins.location":"Lotus Flower"}) .sort({"checkins.ts": -1}).limit(10) Hard to query for last 10
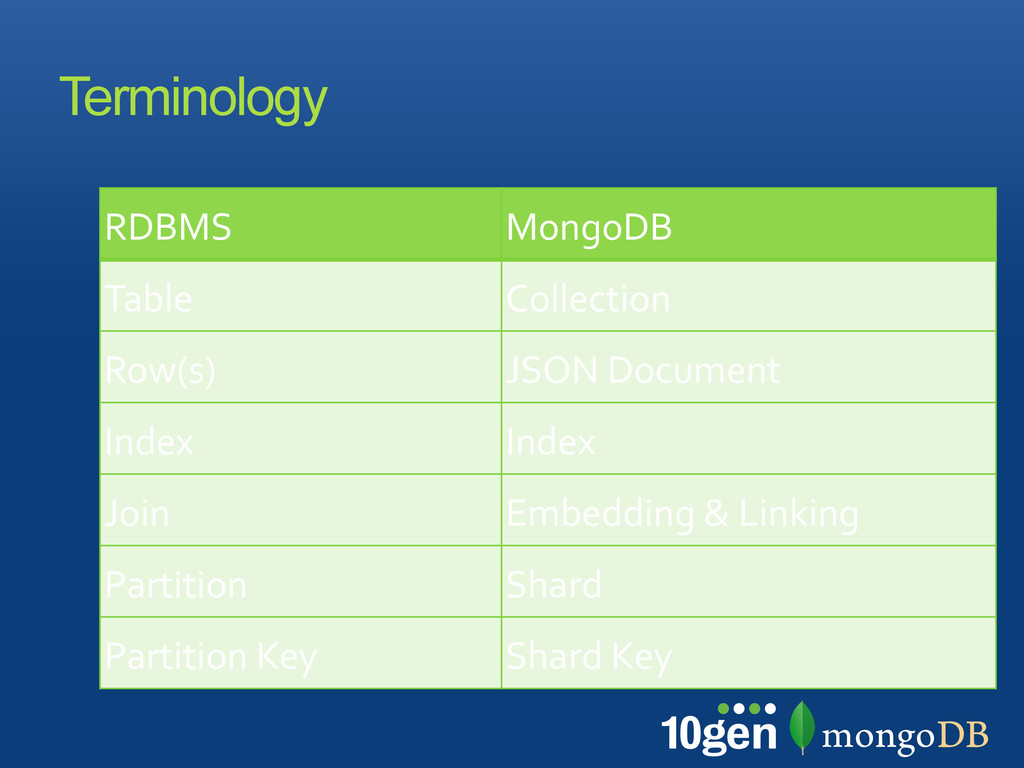
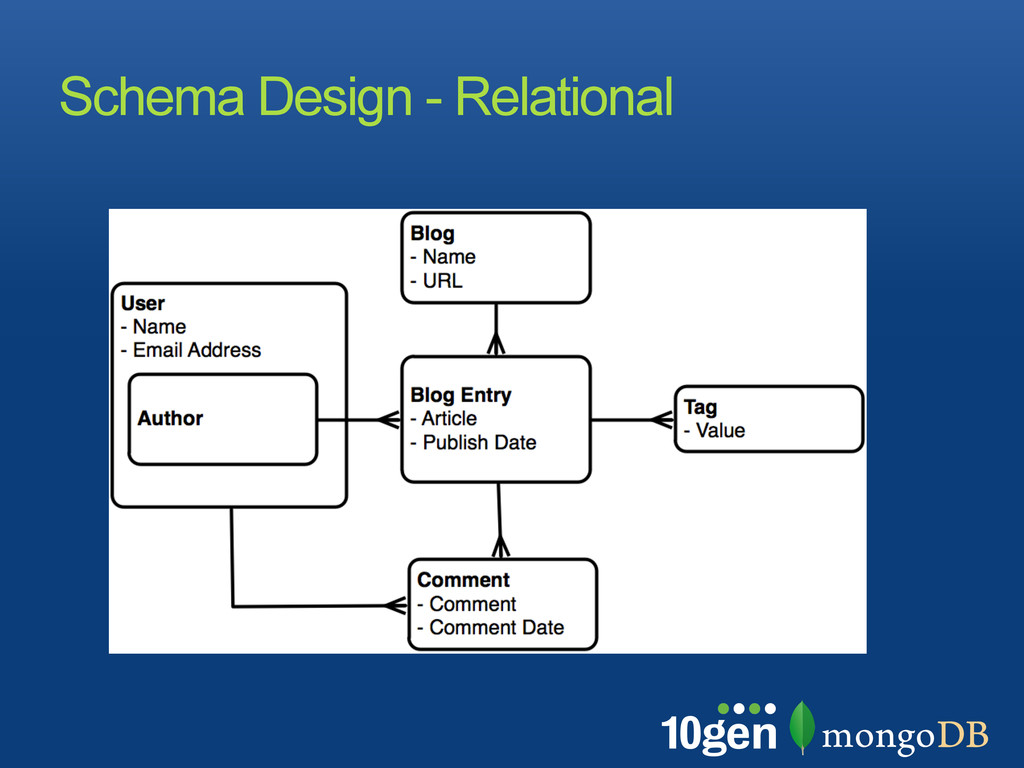
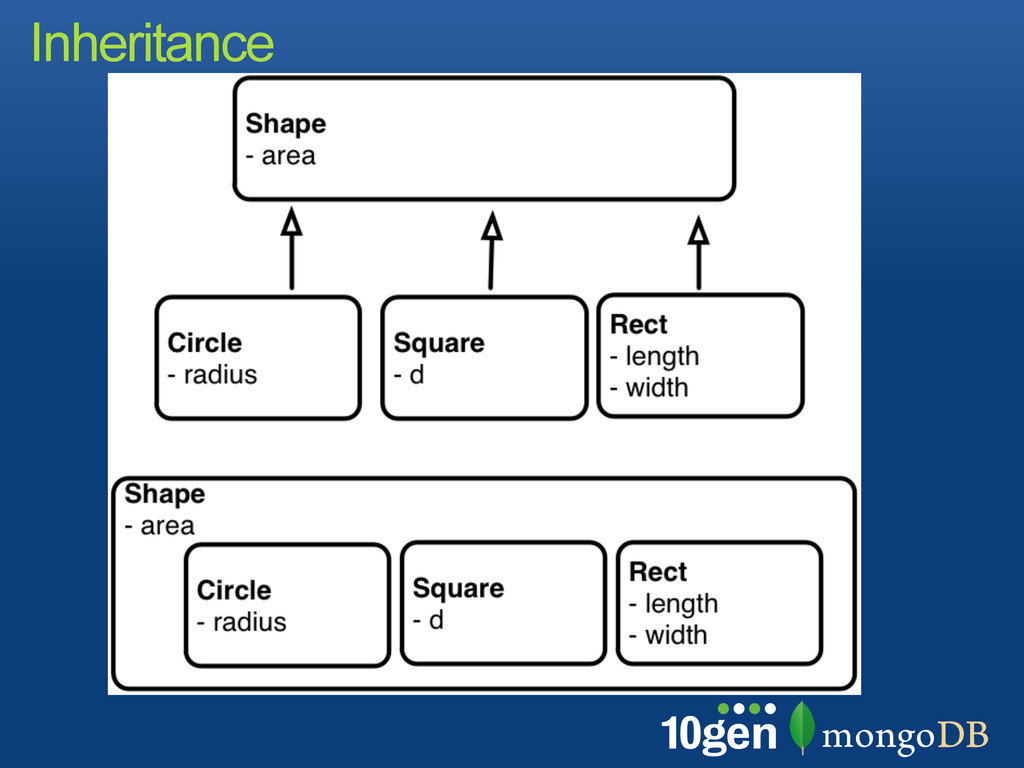
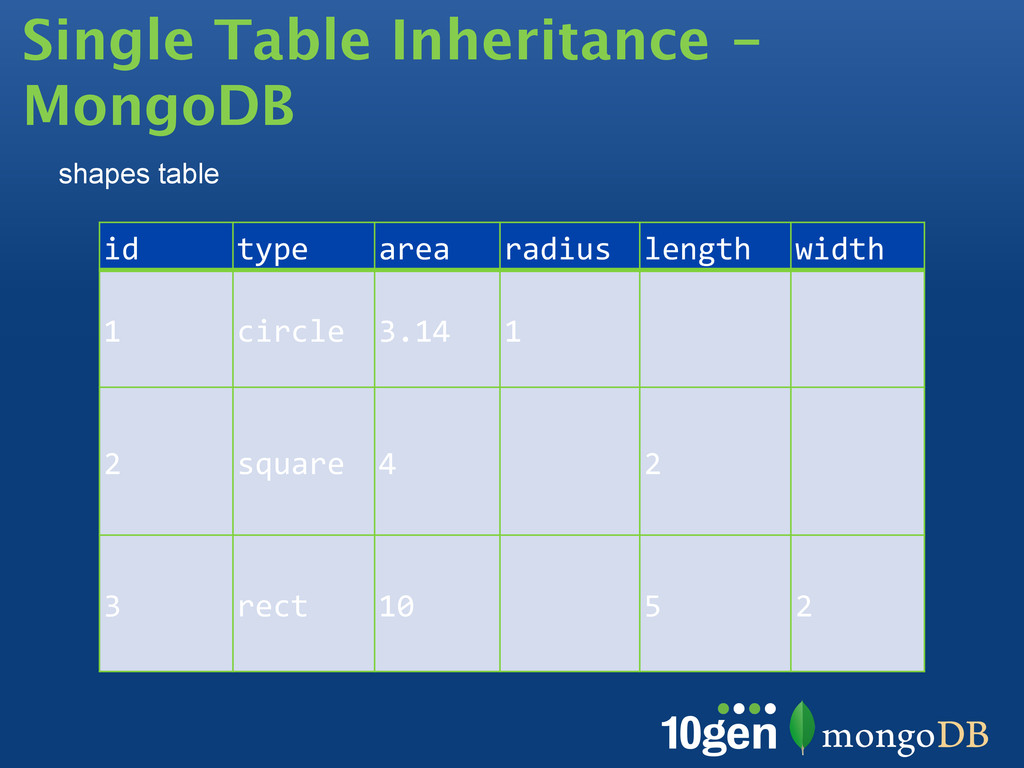
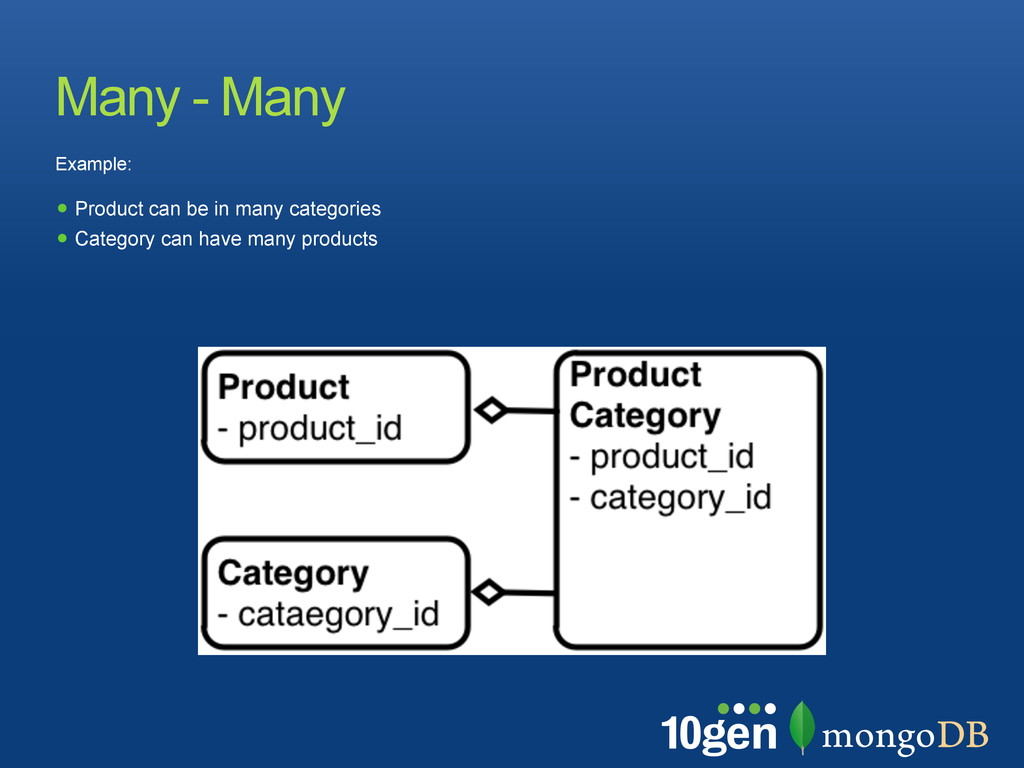
when extending the schema Avoid bias toward a particular query Make use of all SQL features In MongoDB Similar goals apply but rules are different Denormalization for optimization is an option: most features still exist, contrary to BLOBS Normalization
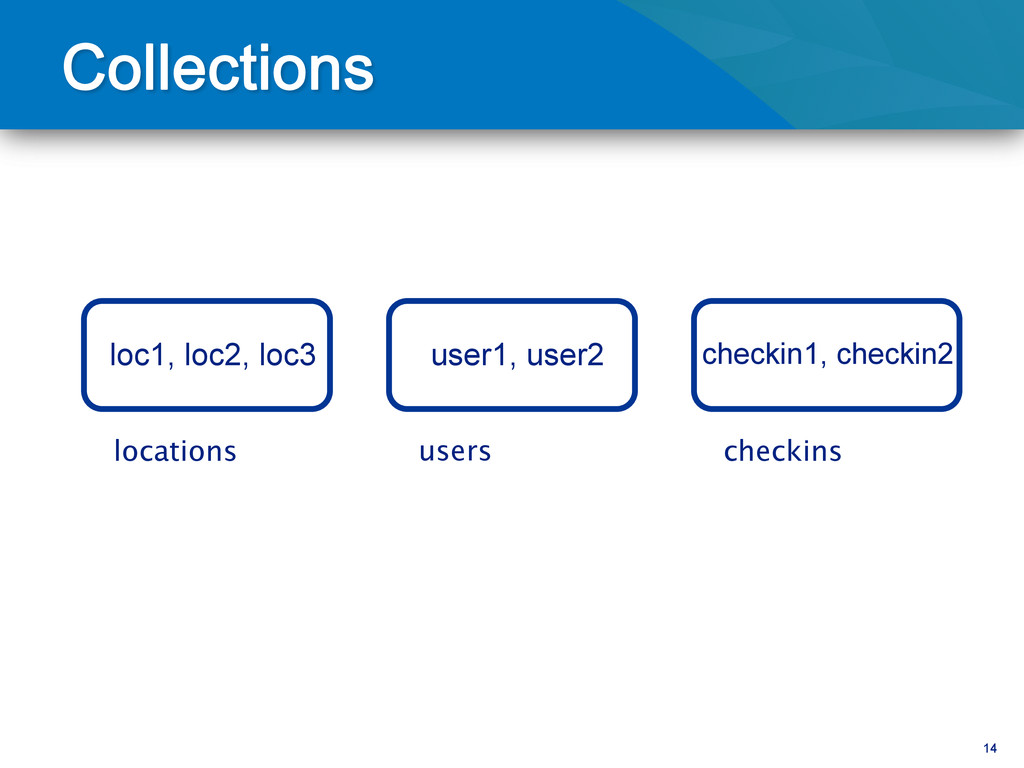
24000) Collections don’t have a fixed schema Common for documents in a collection to share a schema Document schema can evolve Consider using multiple related collections tied together by a naming convention: e.g. LogData-2011-02-08 Collections Basics
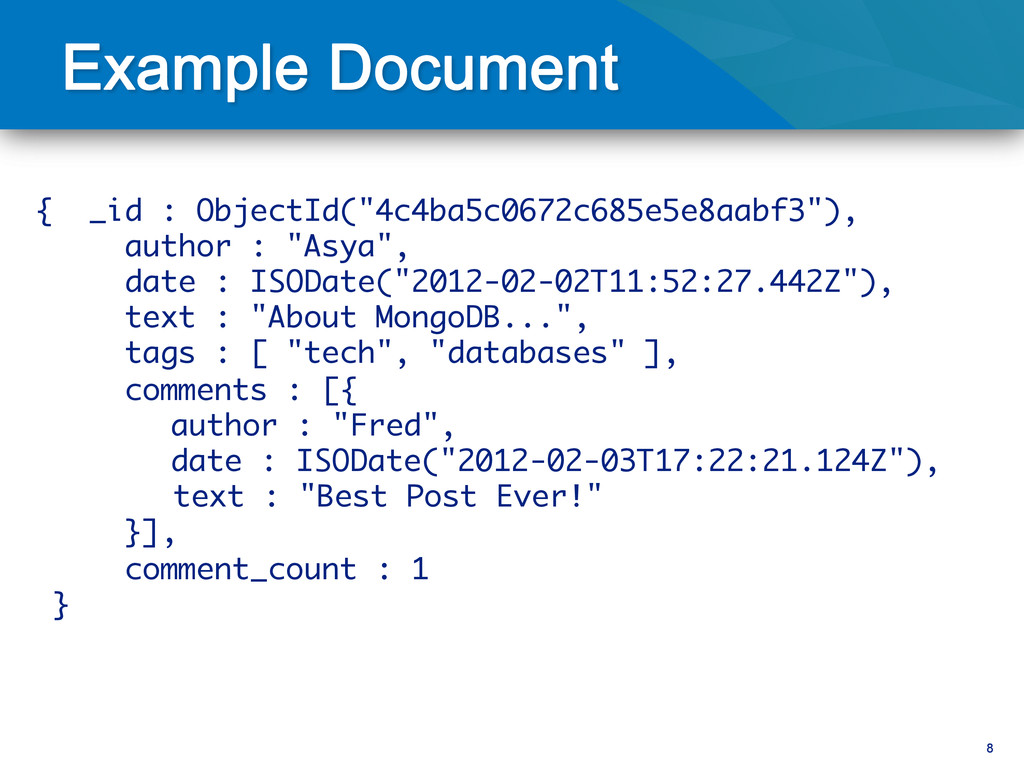
elements can be nested Rich data types for values JSON for the human eye BSON for all internals 16MB maximum size (many books..) What you see is what is stored Document basics
ISODate("2011-09-18T09:56:06.298Z"), ! text: "Destination Moon", ! tags: [ "comic", "adventure" ]! } Notes: • ID must be unique, but can be anything you’d like • MongoDB will generate a default ID if one is not supplied Find the document
1 } ) > db.blogs.find( { "comments.author": "Kyle" } ) // find last 5 posts: > db.blogs.find().sort( { date: -1 } ).limit(5) // most commented post: > db.blogs.find().sort( { comments_count: -1 } ).limit(1) When sorting, check if you need an index Extending the Schema
• improves read speed • simplifies schema • Normalize: • if list grows significantly • if sub items are updated often • if sub items are more than 1 level deep and need updating
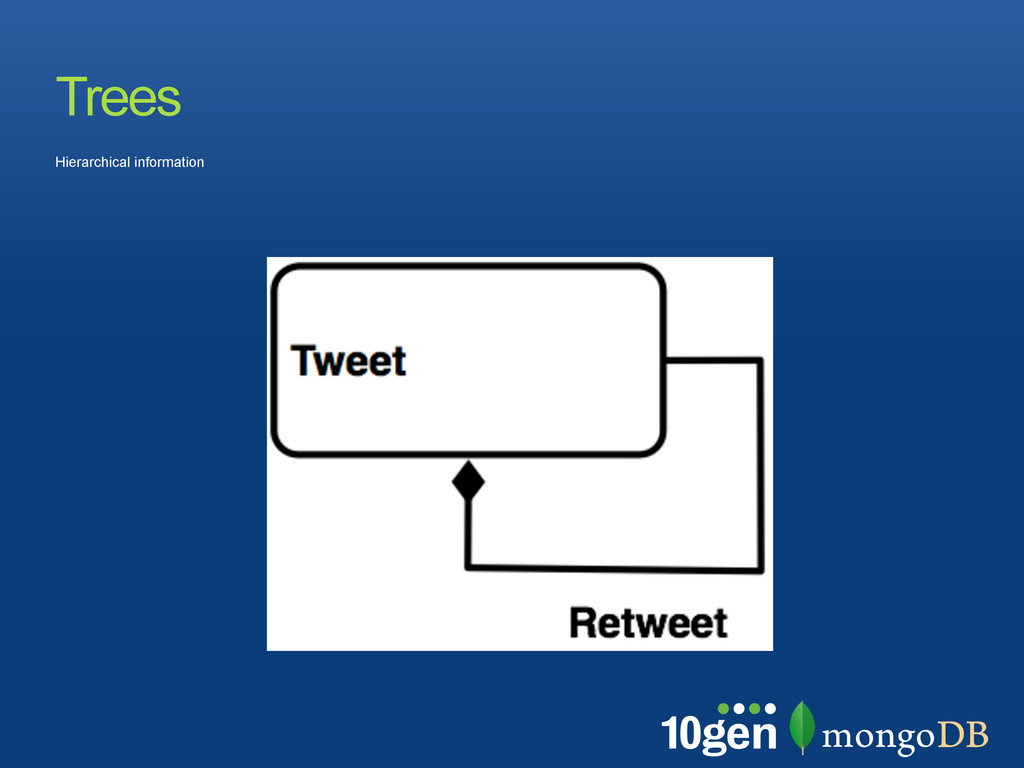
“Kyle”, text: “...”, ! retweet: [! {who: “James”, text: “...”,! retweet: []} ! ]}! ]! }! Pros: Single Document, Performance, Intuitive Cons: Hard to search or update, document can easily get too large Trees
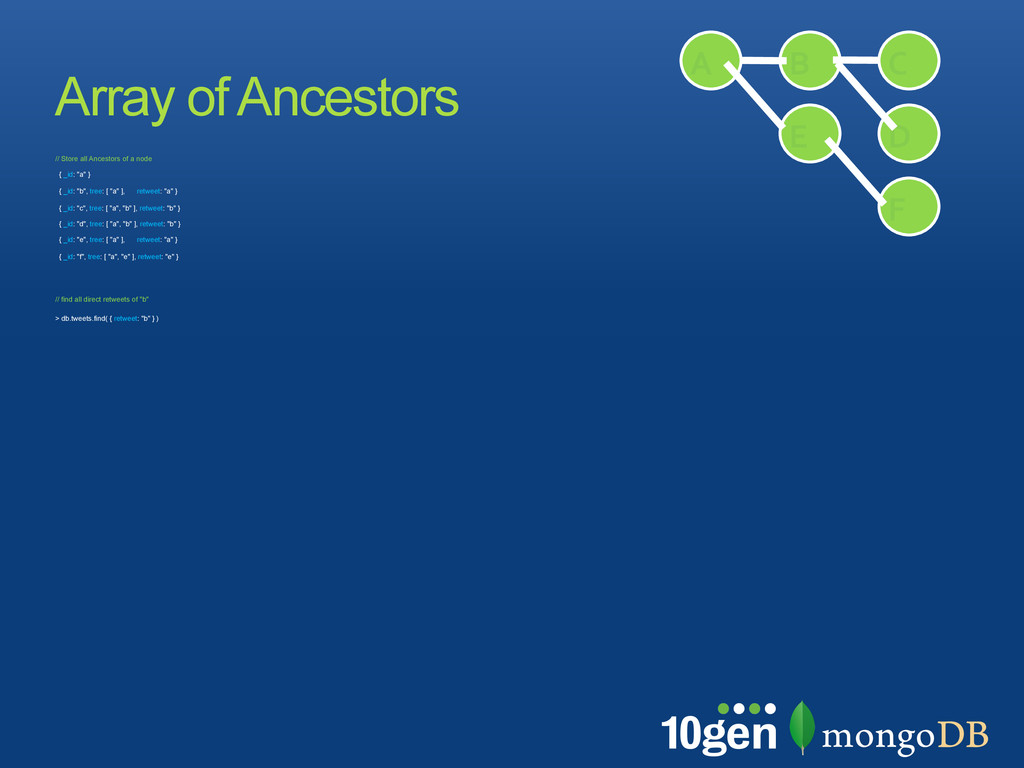
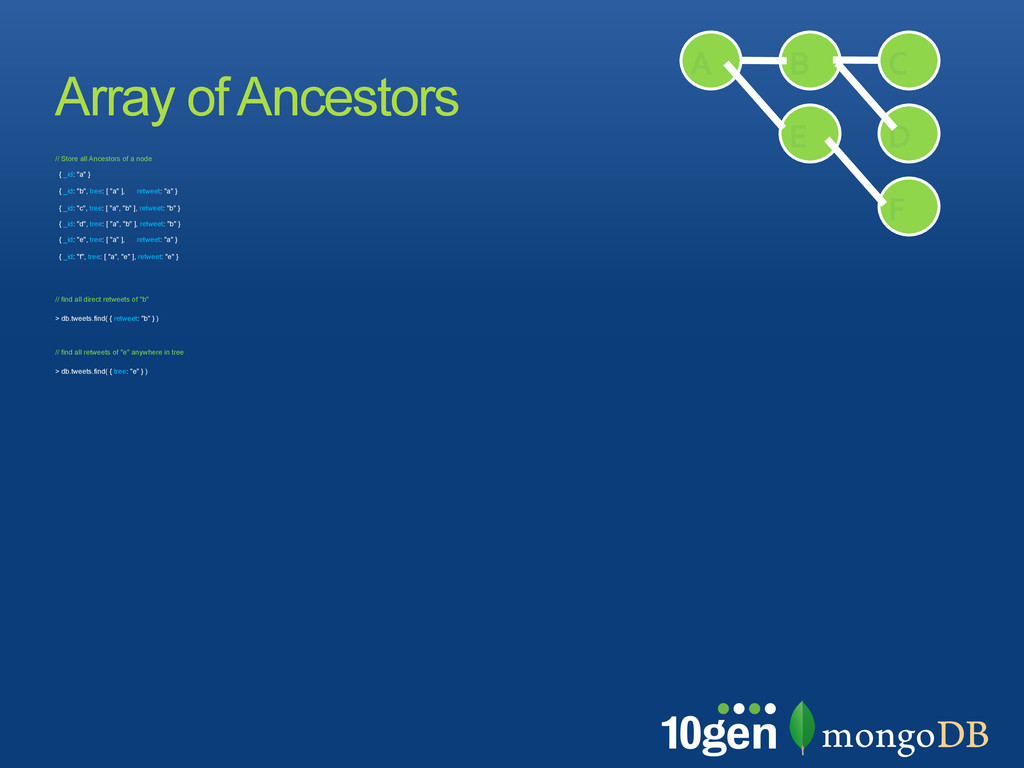
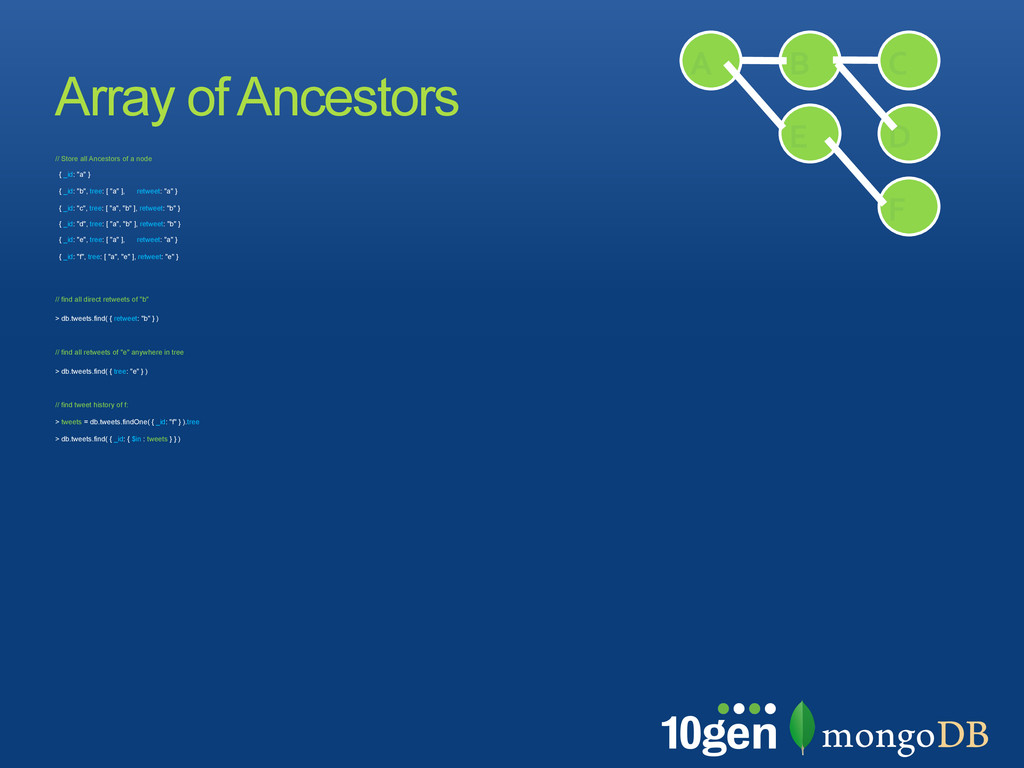
by a delimiter, e.g. “,” • Use text search for find parts of a tree • search must be left-rooted and use an index! { retweets: [! { _id: "a", text: "initial tweet", ! path: "a" },! { _id: "b", text: "reweet with comment",! path: "a,b" },! { _id: "c", text: "reply to retweet",! path : "a,b,c"} ] }! ! // Find the conversations "a" started ! > db.tweets.find( { path: /^a/i } )! // Find the conversations under a branch ! > db.tweets.find( { path: /^a,b/i } )! Trees as Paths A B C D E F
ISODate("2011-12-09T00:00:00.000Z") customerId: 67, total_price: 1050, items: [{ sku: 123, quantity: 2, price: 50, name: “macbook”, thumbnail: “macbook.png” }, { sku: 234, quantity: 1, price: 20, name: “iphone”, thumbnail: “iphone.png” }, ... } } The item information is duplicated in every order that reference it. Mongo’s flexible schema makes it easy! Duplicate data
display the order processing on the db is as fast as a BLOB can achieve much higher performance Cons: more storage used ... cheap enough updates are much more complicated ... just consider fields immutable Duplicate data
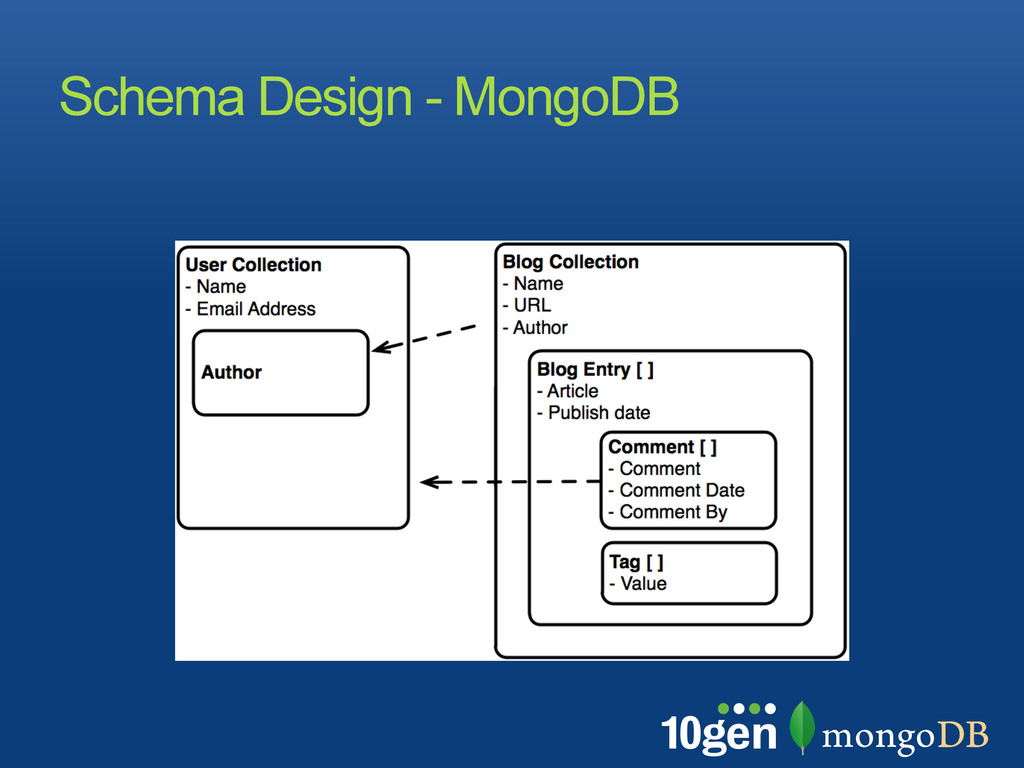
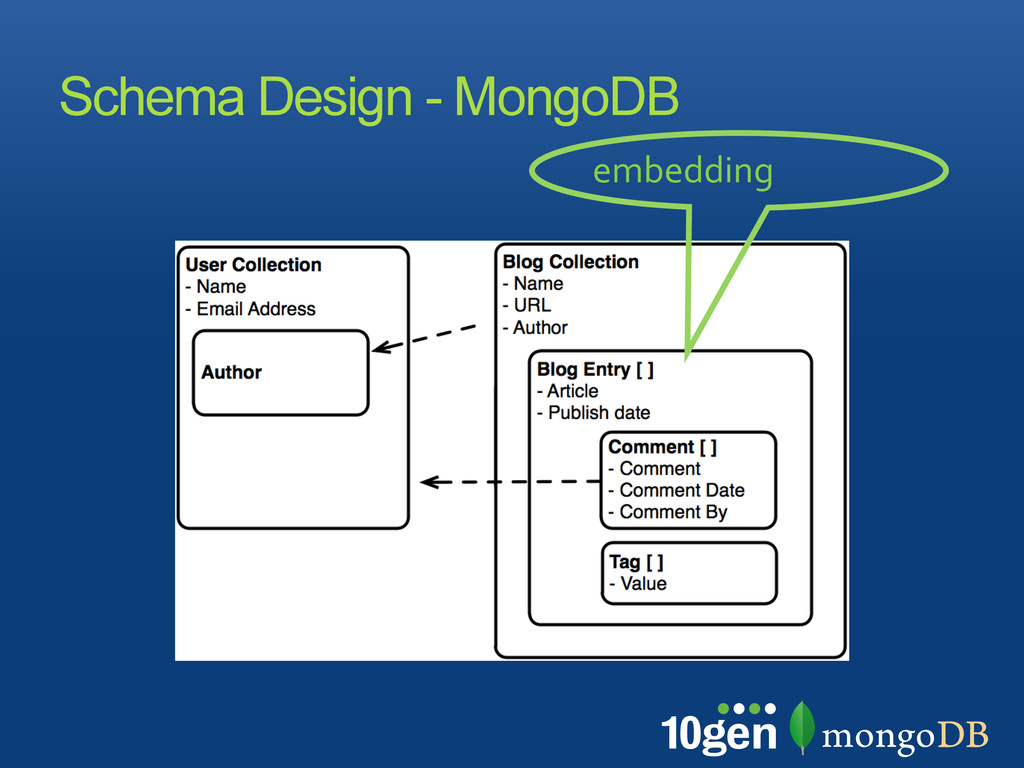
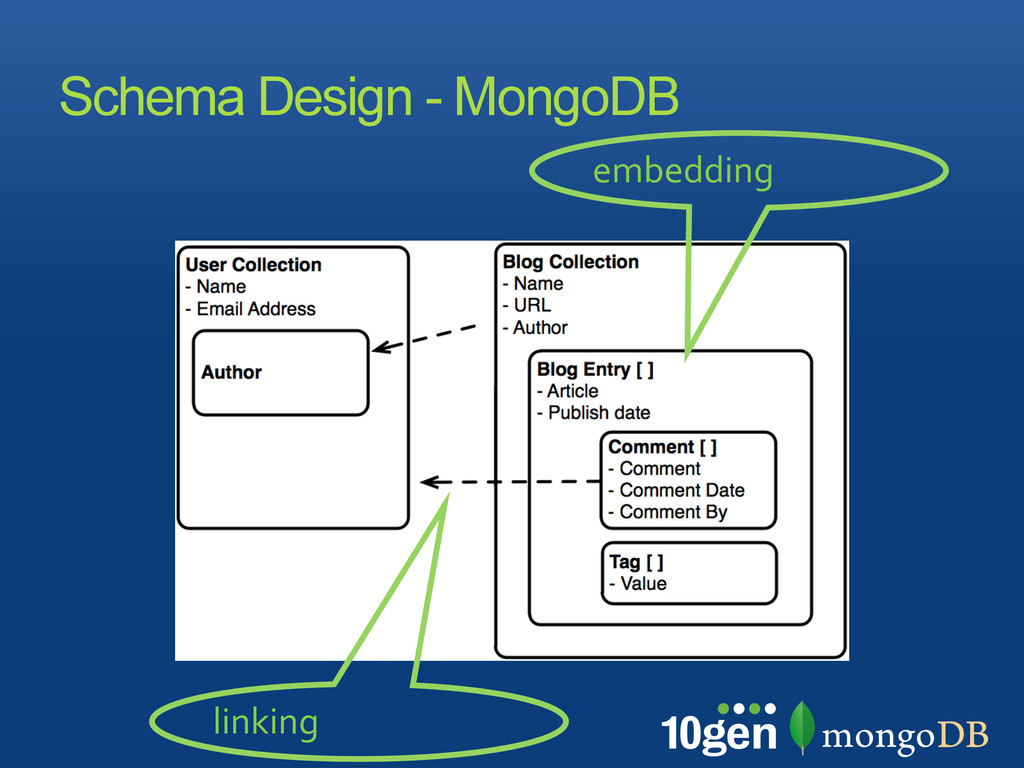
is more flexible and brings possibilities embed or duplicate data to speed up operations, cut down the number of collections and indexes watch for documents growing too large make sure to use the proper indexes for querying and sorting schema should feel natural to your application! Summary
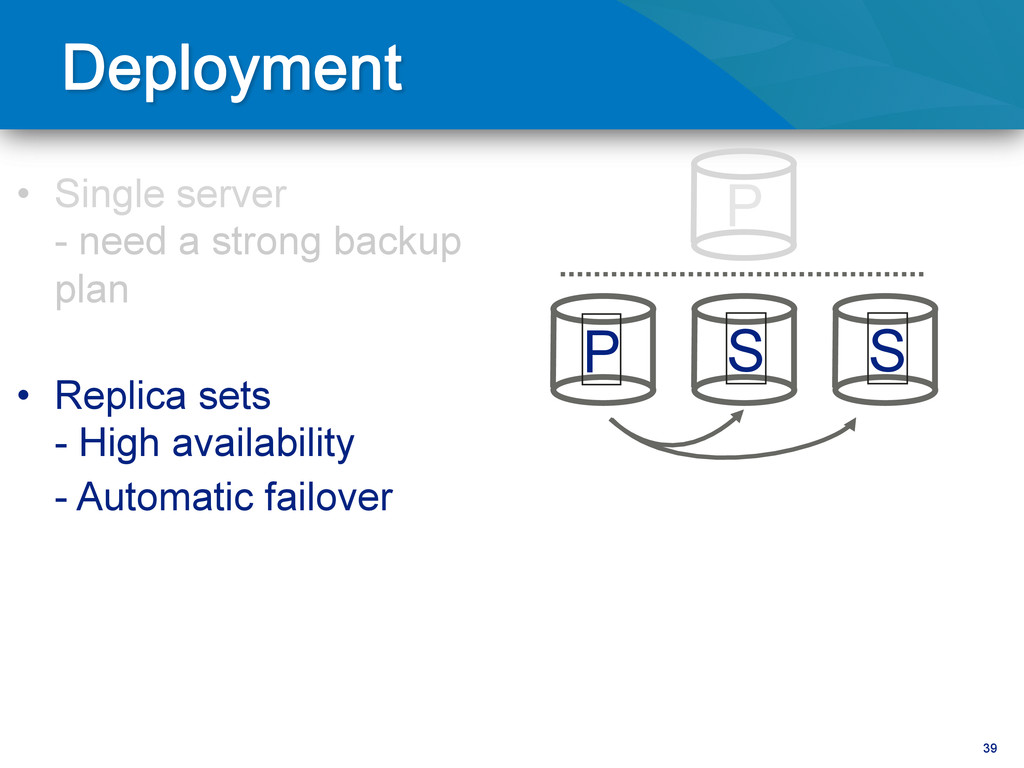
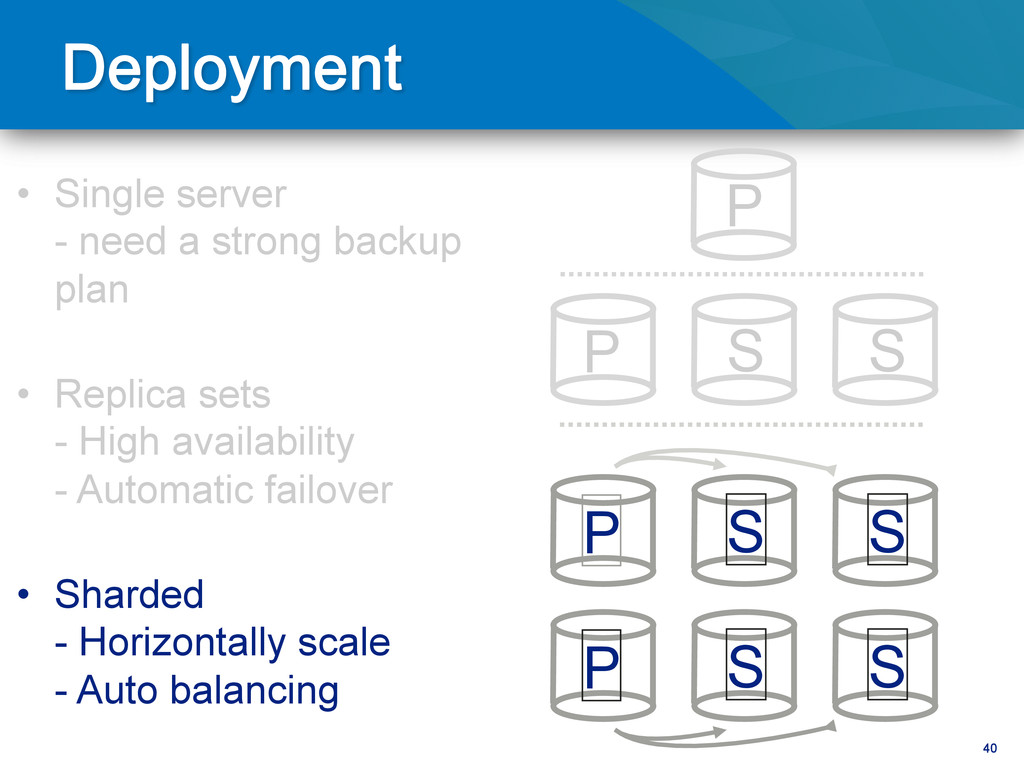
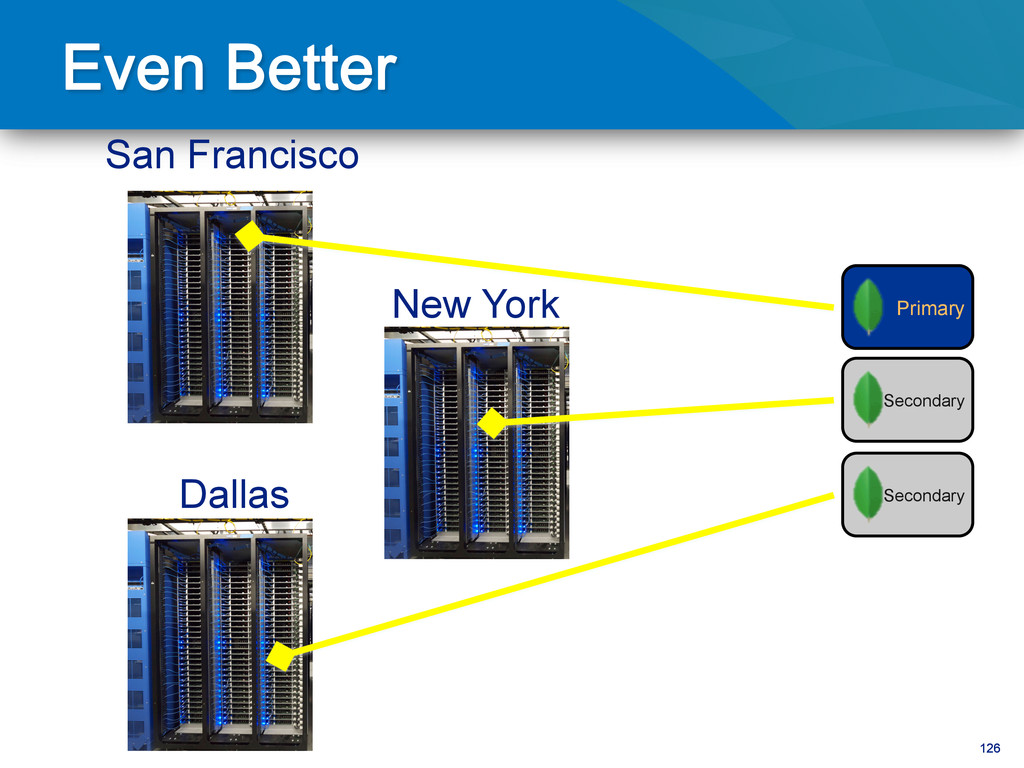
copies to read from) • Backups – Online, Delayed Copy (fat finger) – Point in Time (PiT) backups • Use (hidden) replica for secondary workload – Analytics – Data-processing – Integration with external systems
tuning – Relocation of data to new file-system / storage – Software upgrade Unplanned – Hardware failure – Data center failure – Region outage – Human error – Application corruption
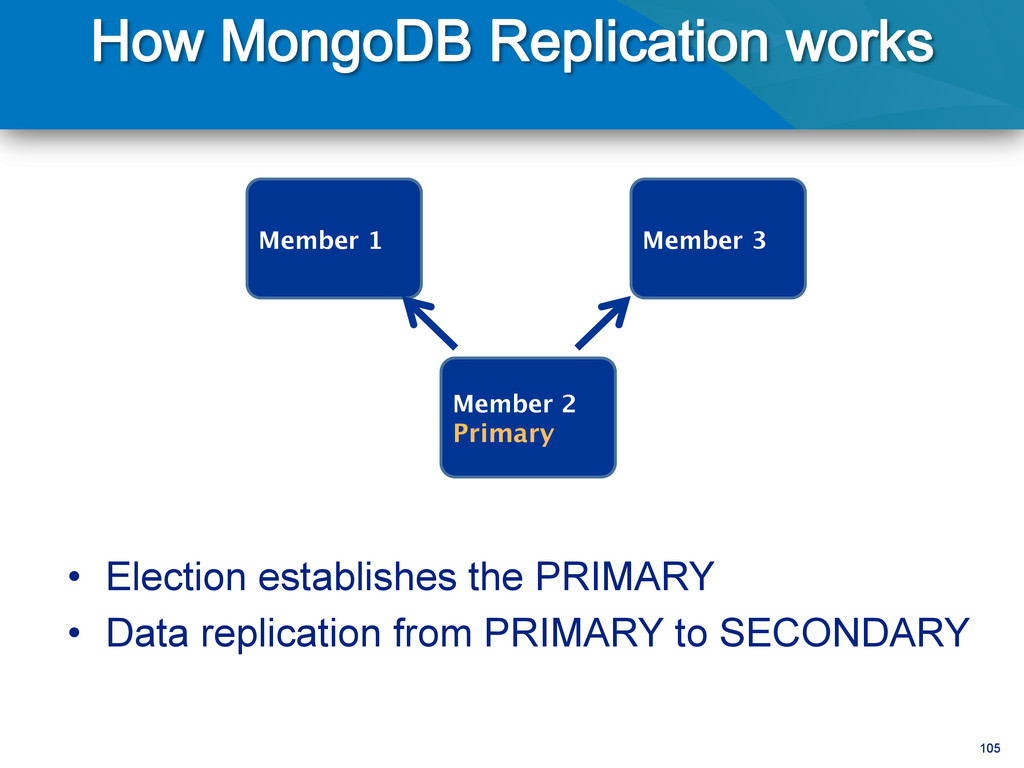
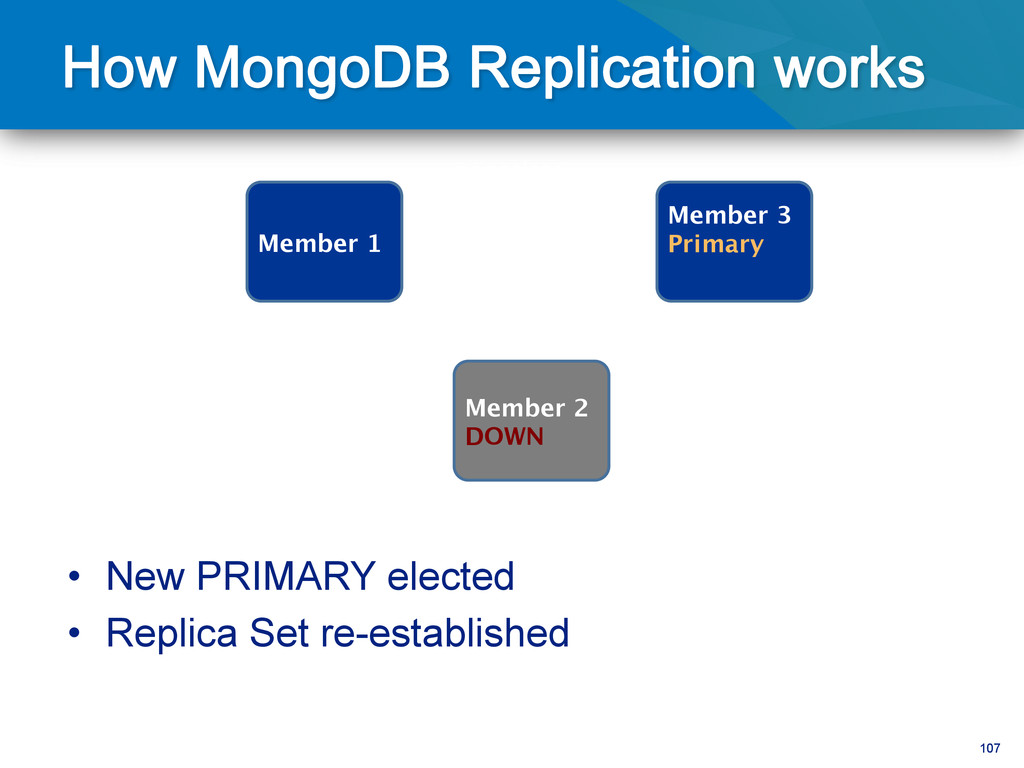
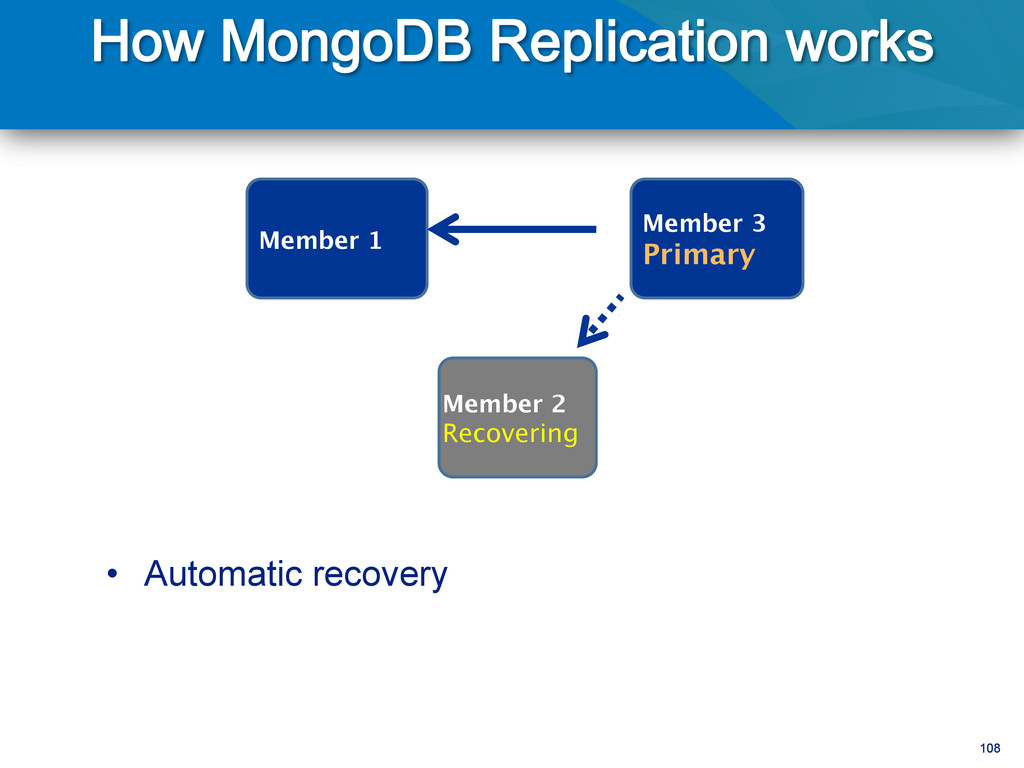
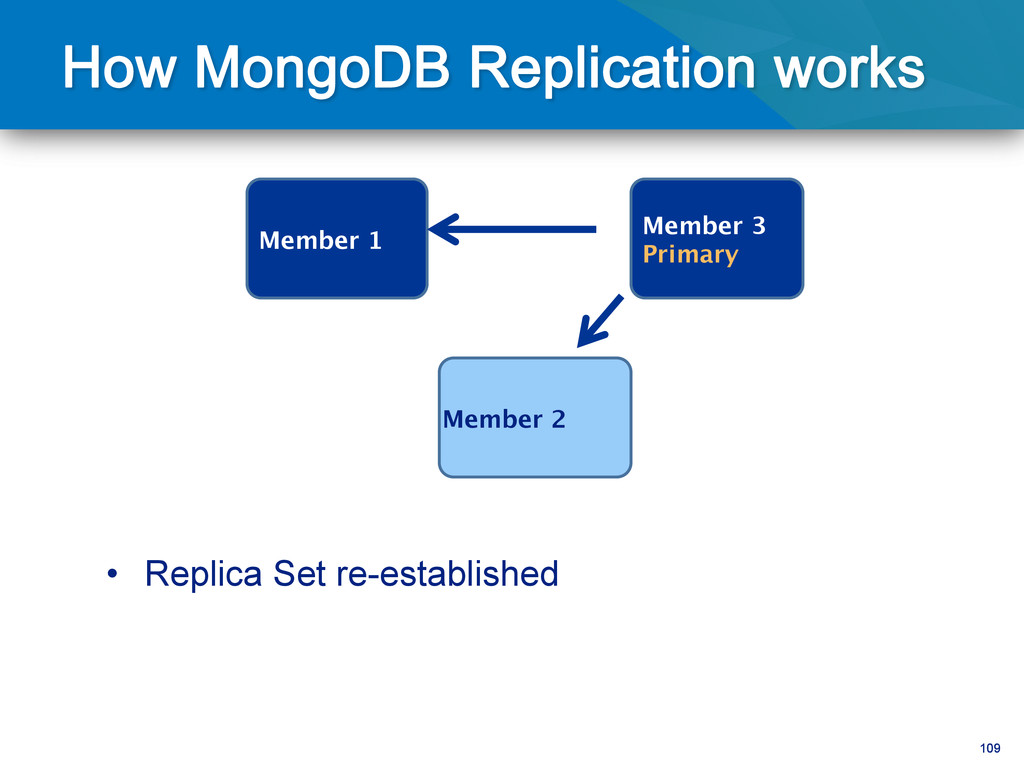
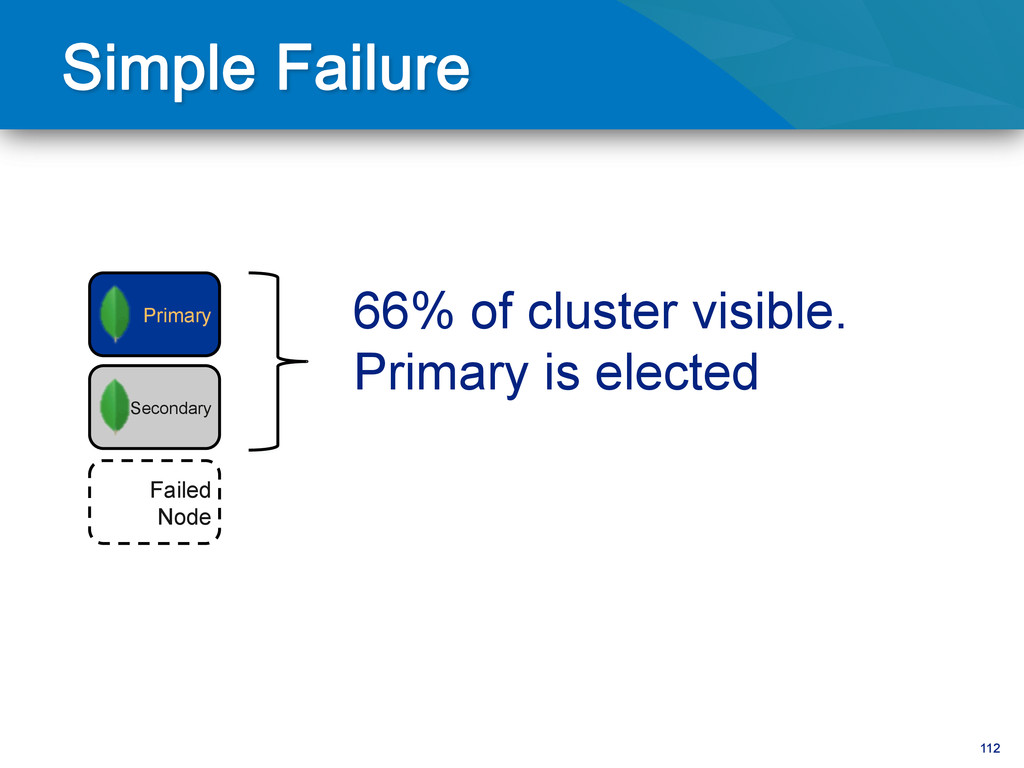
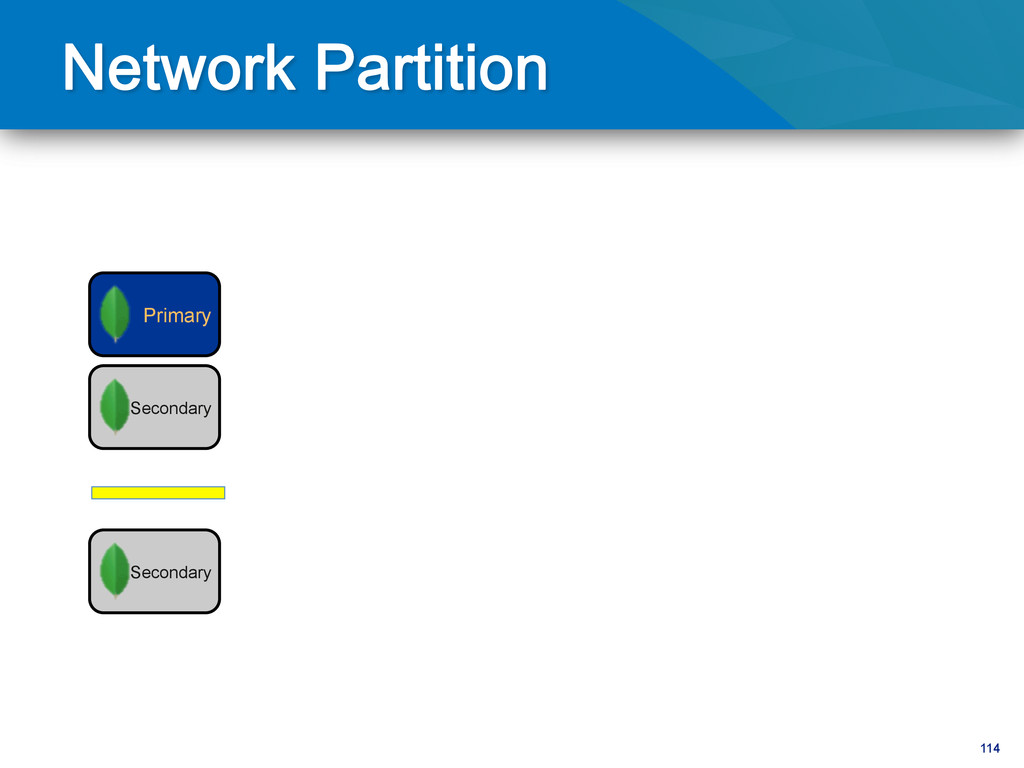
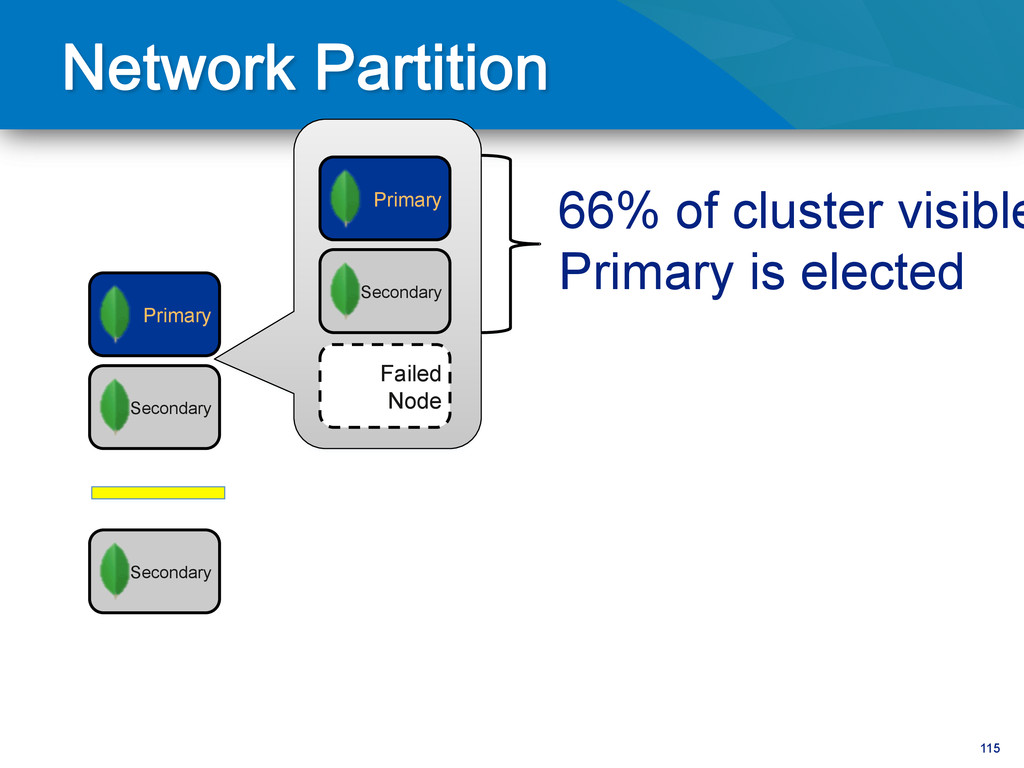
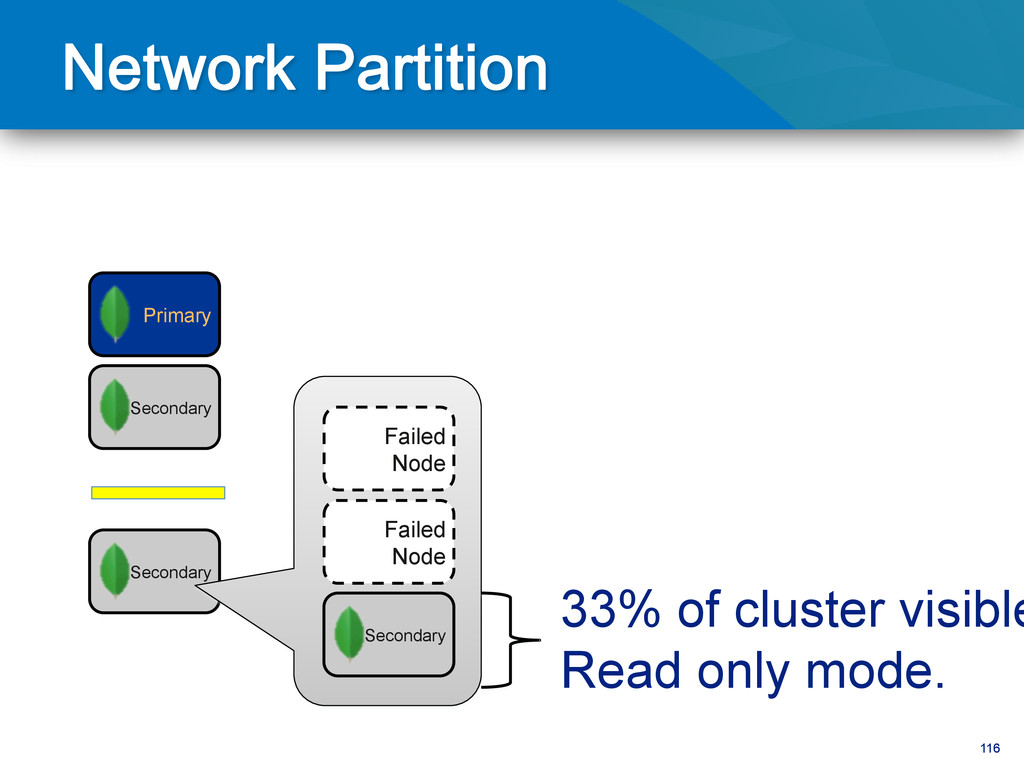
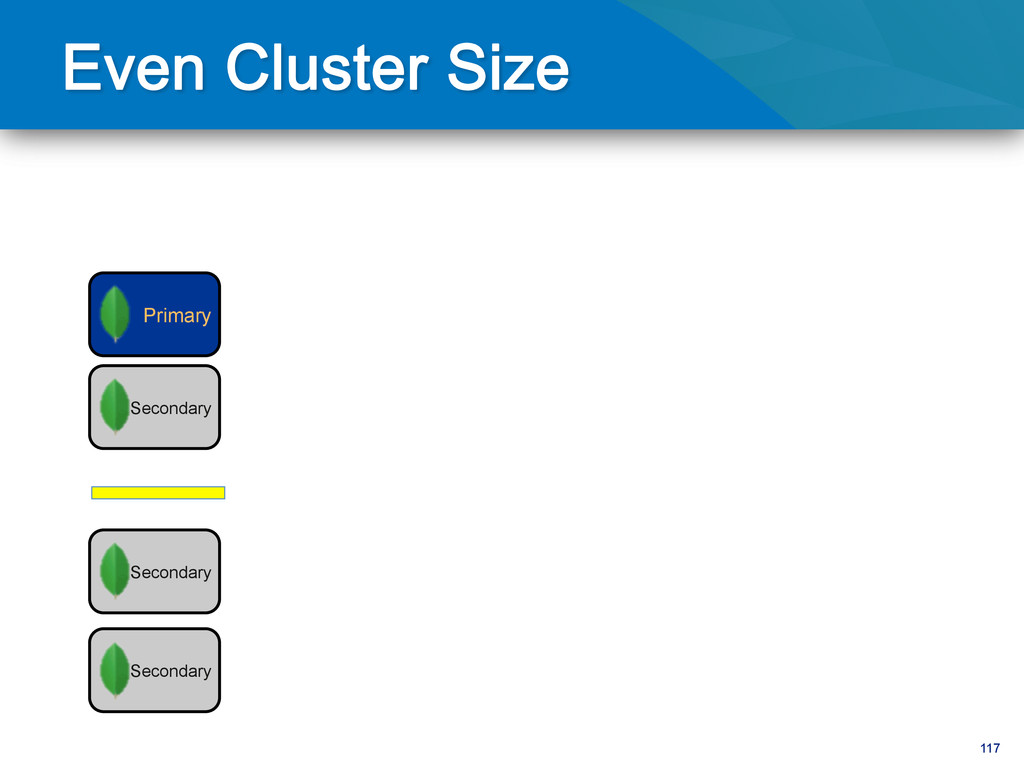
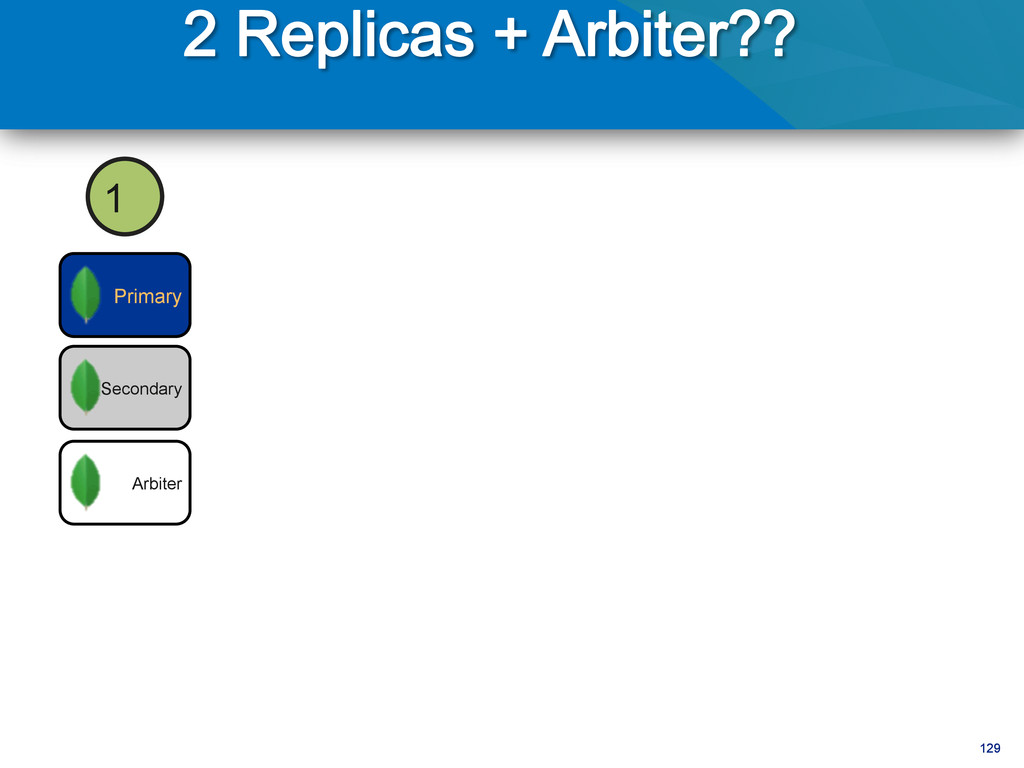
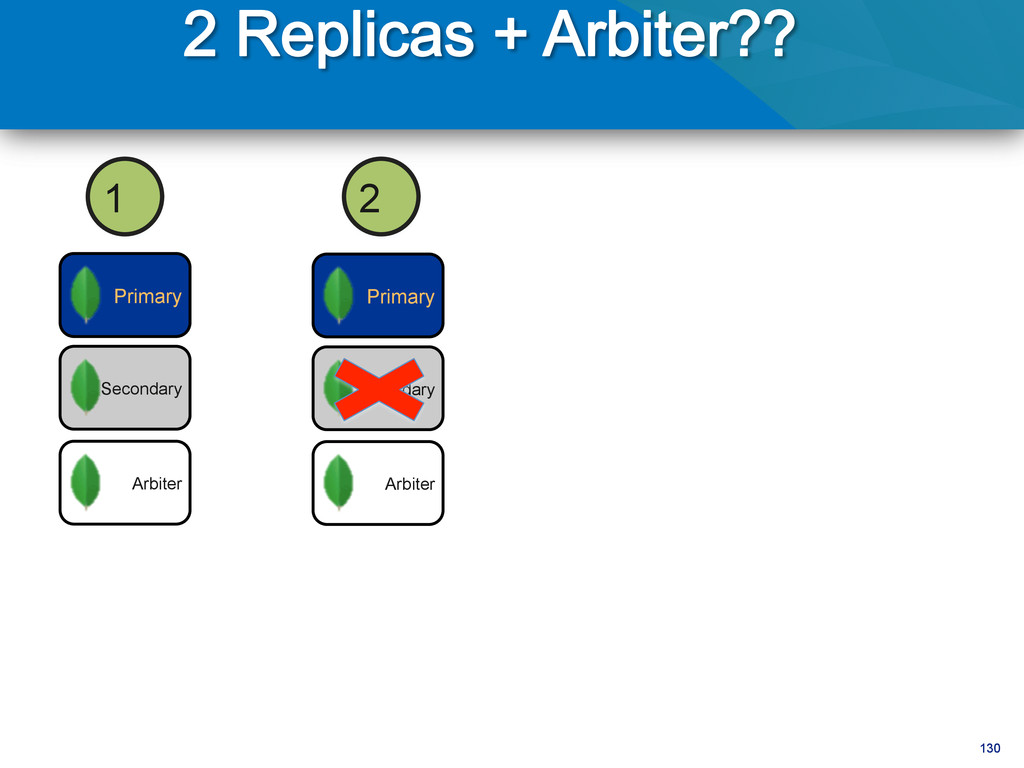
writes to primary • Reads can be to primary (default) or a secondary • Any (one) node can be primary • Consensus election of primary • Automatic failover • Automatic recovery
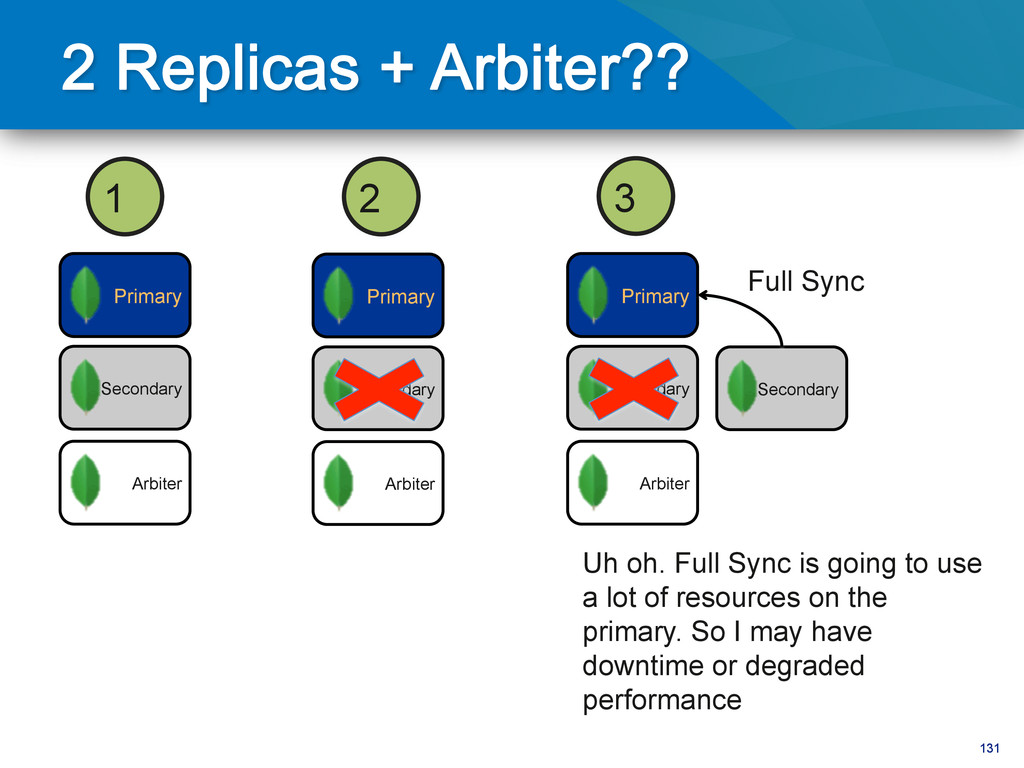
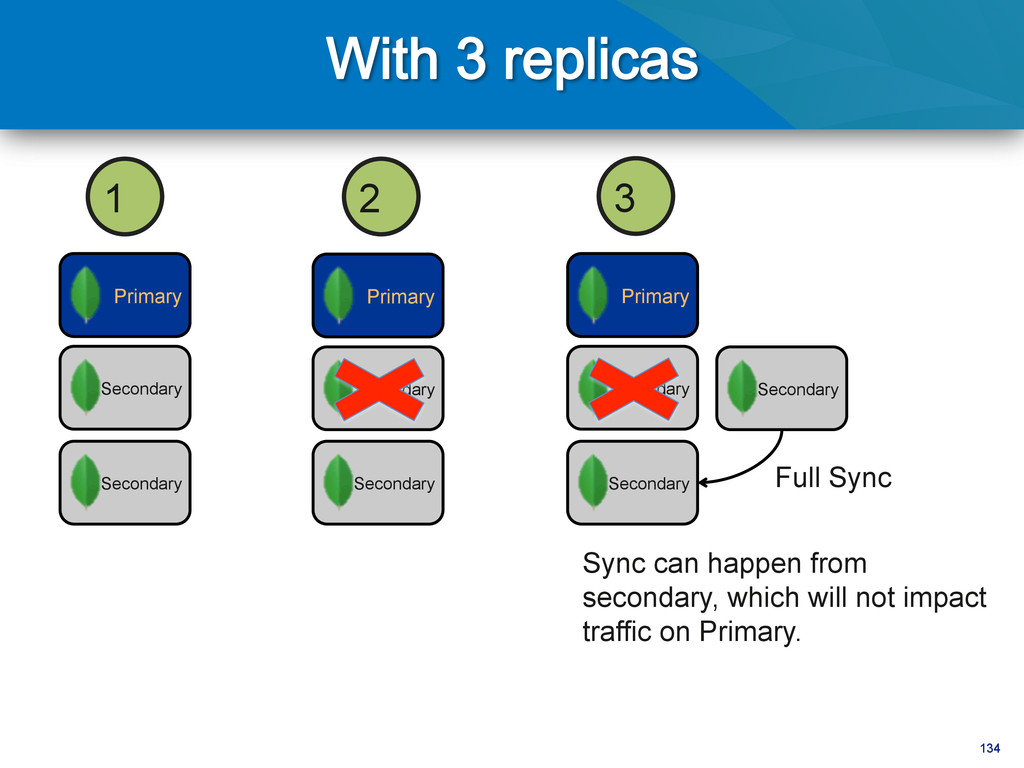
Primary Arbiter Secondary 3 Secondary Full Sync Uh oh. Full Sync is going to use a lot of resources on the primary. So I may have downtime or degraded performance
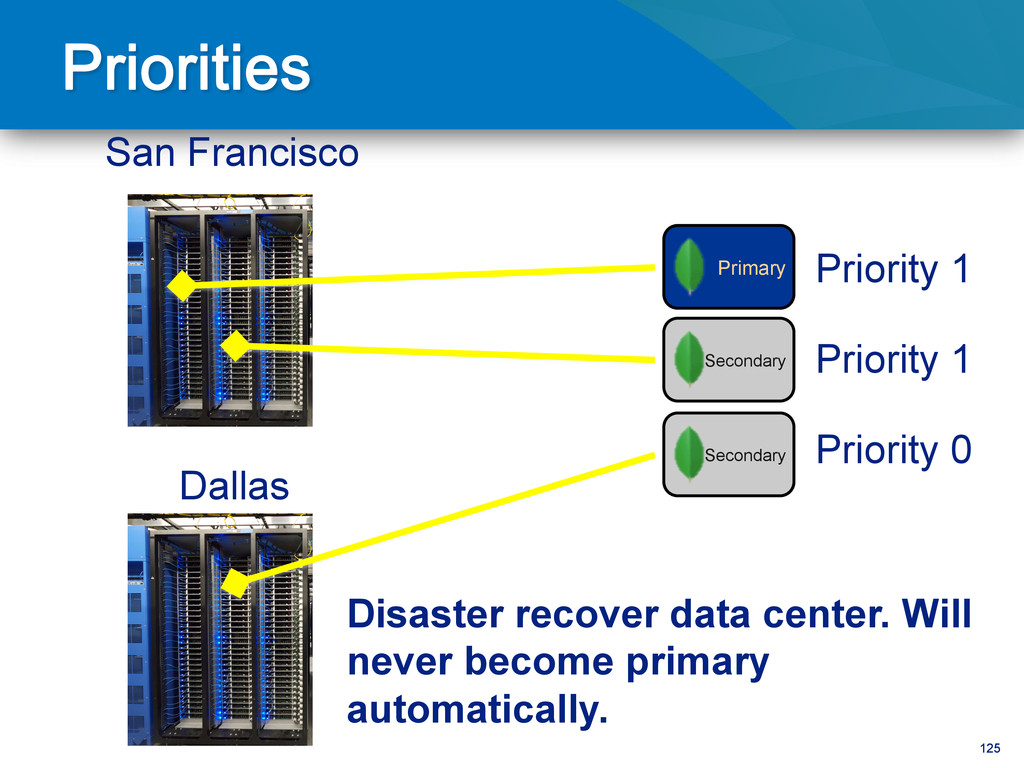
– Separate data centers • Avoid long recovery downtime – Use journaling – Use 3+ replicas • Keep your actives close – Use priority to control where failovers happen
MongoDB – What benefits? – Poten9al Use cases – Steering the adop9on of MongoDB • Why is MongoDB Safe – Execu9on – Opera9onal – Financial • Why 10gen? – People – Company – Future
• Easier to maintain • Con9ngency plans for turnover • Commodity hardware • No upfront license, pay for value over 9me • Cost visibility for growth of usage
for a system build on con9nuous stream of high-‐quality text pulled from online sources § Adding too much data too quickly resulted in outages; tables locked for tens of seconds during inserts § Ini9ally launched en9rely on MySQL but quickly hit performance road blocks Problem Life with MongoDB has been good for Wordnik. Our code is faster, more flexible and drama?cally smaller. Since we don’t spend ?me worrying about the database, we can spend more ?me wri?ng code for our applica?on. § Migrated 5 billion records in a single day with zero down9me § MongoDB powers every website requests: 20m API calls per day § Ability to eliminated memcached layer, crea9ng a simplified system that required fewer resources and was less prone to error. Why MongoDB § Reduced code by 75% compared to MySQL § Fetch 9me cut from 400ms to 60ms § Sustained insert speed of 8k words per second, with frequent bursts of up to 50k per second § Significant cost savings and 15% reduc9on in servers Impact Wordnik uses MongoDB as the foundation for its “live” dictionary that stores its entire text corpus – 3.5T of data in 20 billion records Tony Tam, Vice President of Engineering and Technical Co-founder
Shireson – President! COO MarkLogic" 9 Years at Oracle" Eliot Horowitz – CTO ! Co-founder of Shopwiki, DoubleClick Erik Frieberg – VP Marketing! HP Software, Borland, BEA Ben Sabrin – VP of Sales ! VP of Sales at Jboss, over 9 years of Open Source experience
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
![29 29 > user_1 = { _id: "[email protected]", name: "Asya",](https://files.speakerdeck.com/presentations/4ffdb2423b87dd00010061bb/slide_28.jpg){kind=link}
{kind=link}
{kind=link}
{kind=link}
![33 33 > user_2 = { _id: "[email protected]", name: "Asya",](https://files.speakerdeck.com/presentations/4ffdb2423b87dd00010061bb/slide_32.jpg){kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
![Schema Design with MongoDB Antoine Girbal [email protected] @antoinegirbal](https://files.speakerdeck.com/presentations/4ffdb2423b87dd00010061bb/slide_44.jpg){kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
![165 165 [email protected] Easy to start Easy to develop Easy](https://files.speakerdeck.com/presentations/4ffdb2423b87dd00010061bb/slide_164.jpg){kind=link}