Ling Zhang (Software Engineer @ Aiden.ai) @ Moscow Python Conf 2017
"Spelling is hard, really hard. It's an everyday user frustration to try to search for a friend's name or the name of a restaurant that they heard but end up writing it wrong. In this talk, we will cover a python implementation of a single fast algorithm that can recover from spelling errors, typing errors, and even transliteration mistakes! We will also integrate this with a language model to make it context aware. With this technique, you can build powerful fuzzy text searchers and spell checkers".
Video: https://conf.python.ru/building-fast-fuzzy-searcher-and-spell-checker/
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
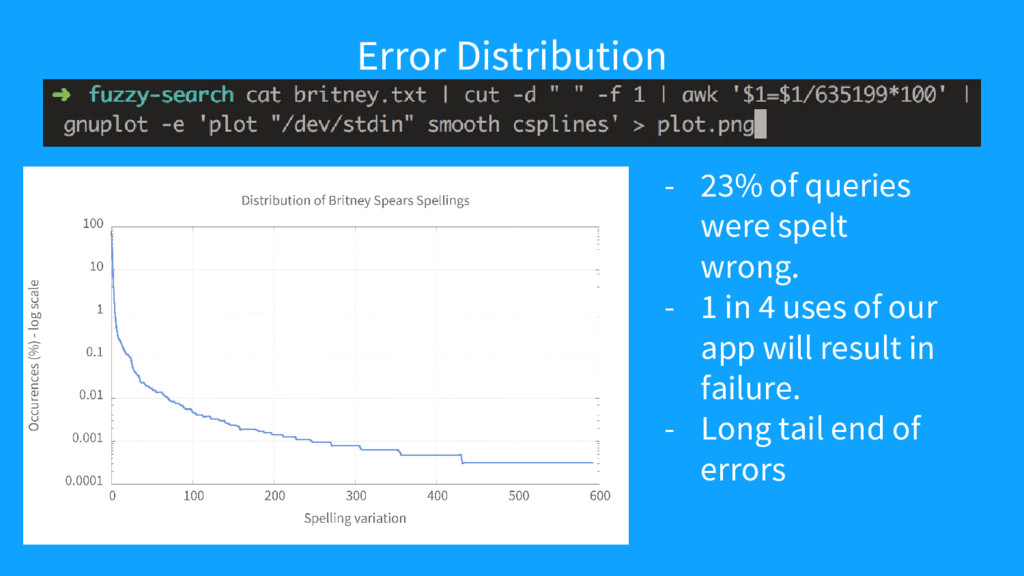{kind=link}
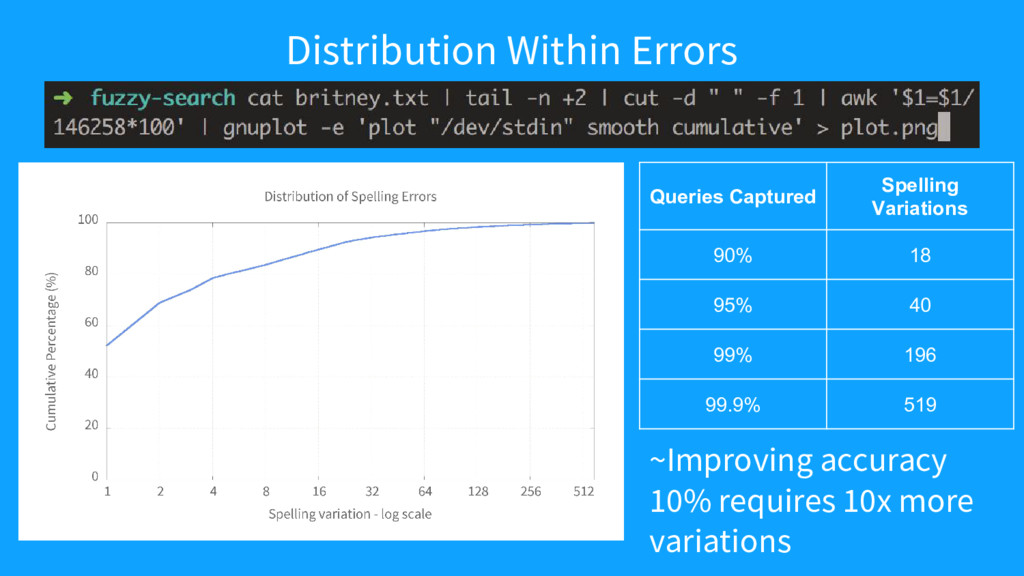{kind=link}
{kind=link}
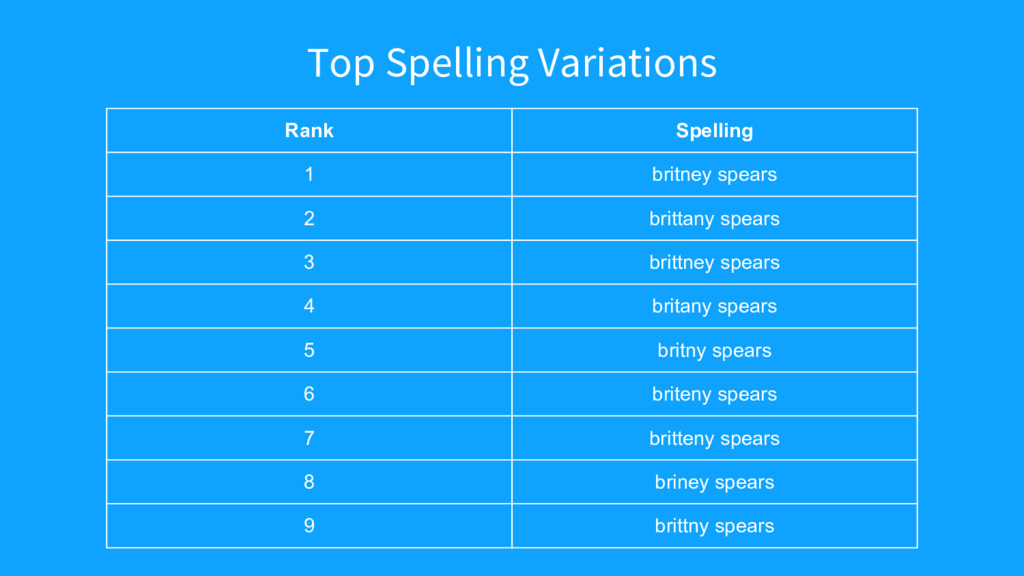{kind=link}
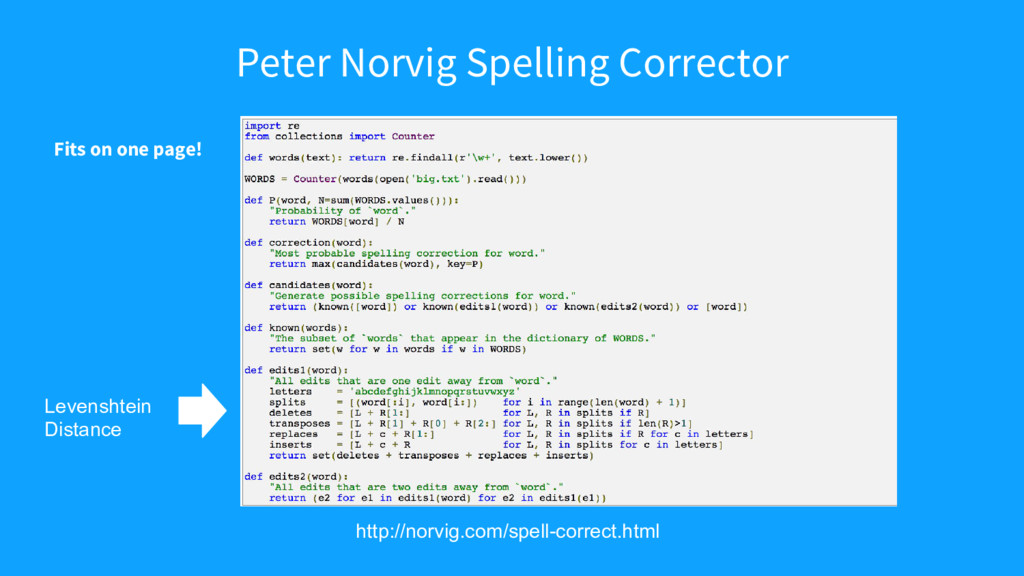{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
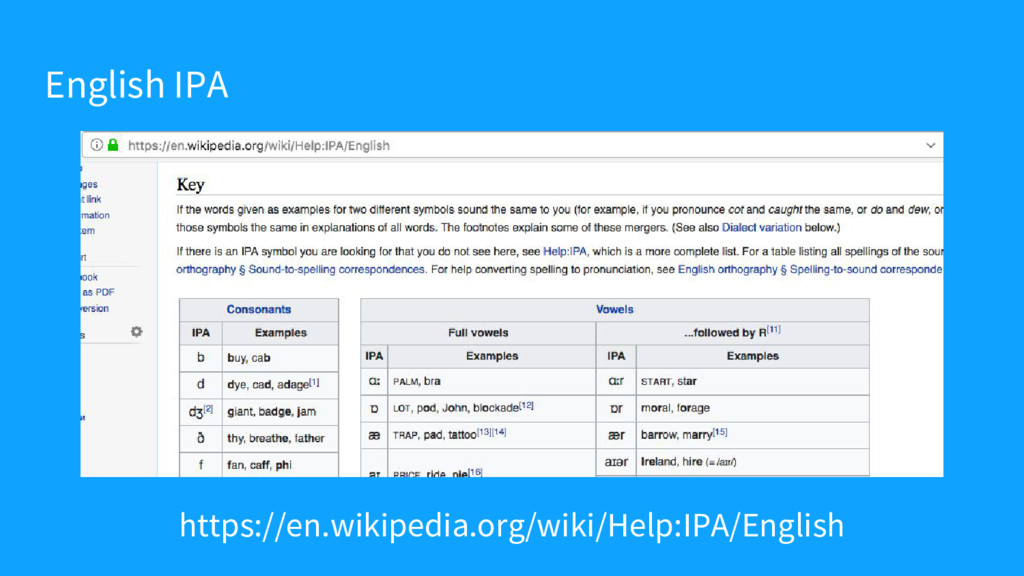{kind=link}
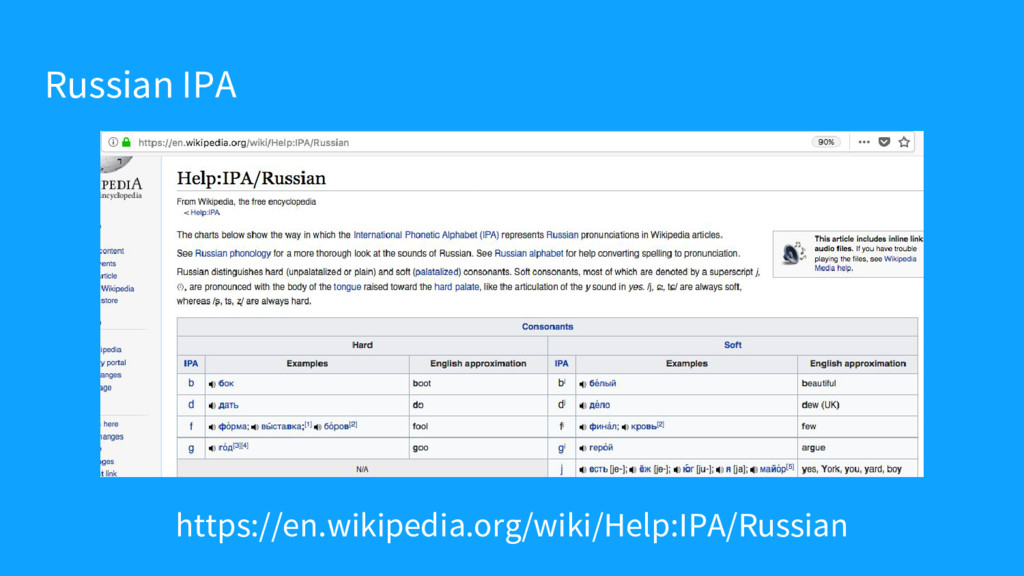{kind=link}
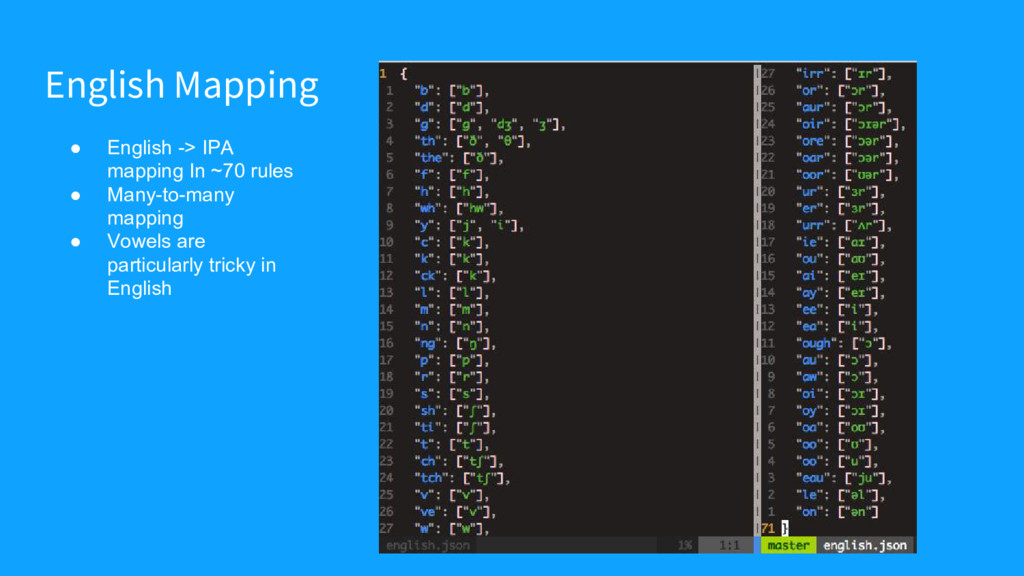{kind=link}
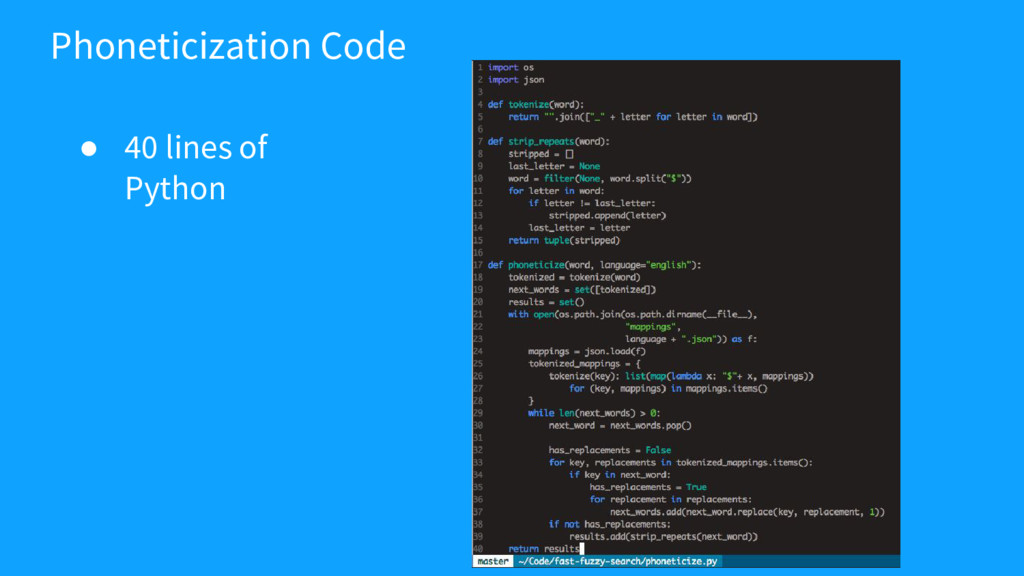{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
![Questions? [email protected]](https://files.speakerdeck.com/presentations/2c28ad7e30424556a606ef287de94e2b/slide_48.jpg){kind=link}