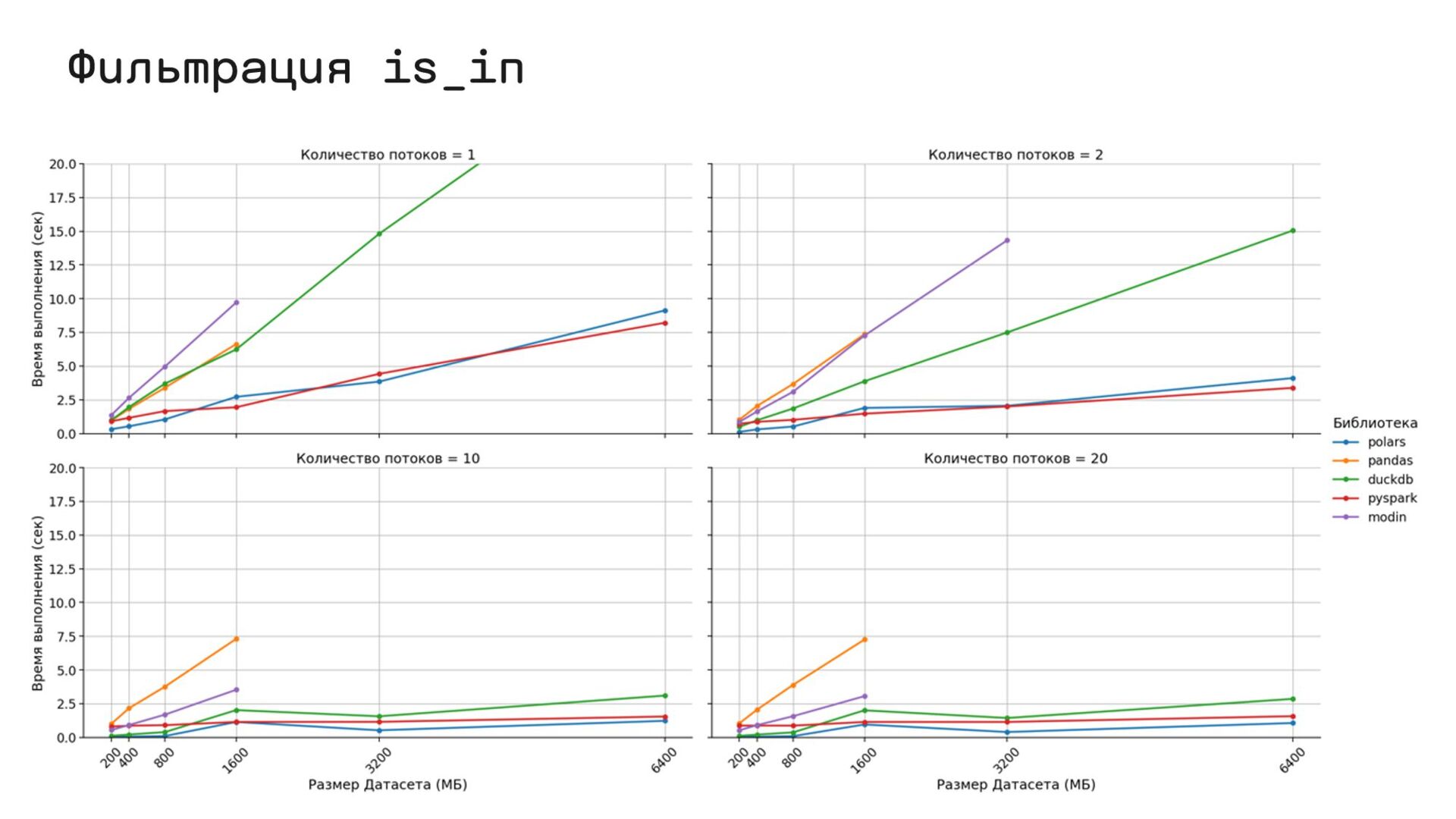
Расскажу про успешный опыт ускорения многопоточного приложения написанного на pandas. Покажу сравнение синтаксиса и производительности polars с другими решениями. Дам полезные советы по миграции.
Видео: https://moscowpython.ru/meetup/96/pandas-to-polaris/
Расскажу про успешный опыт ускорения многопоточного приложения написанного на pandas. Покажу сравнение синтаксиса и производительности polars с другими решениями. Дам полезные советы по миграции.
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
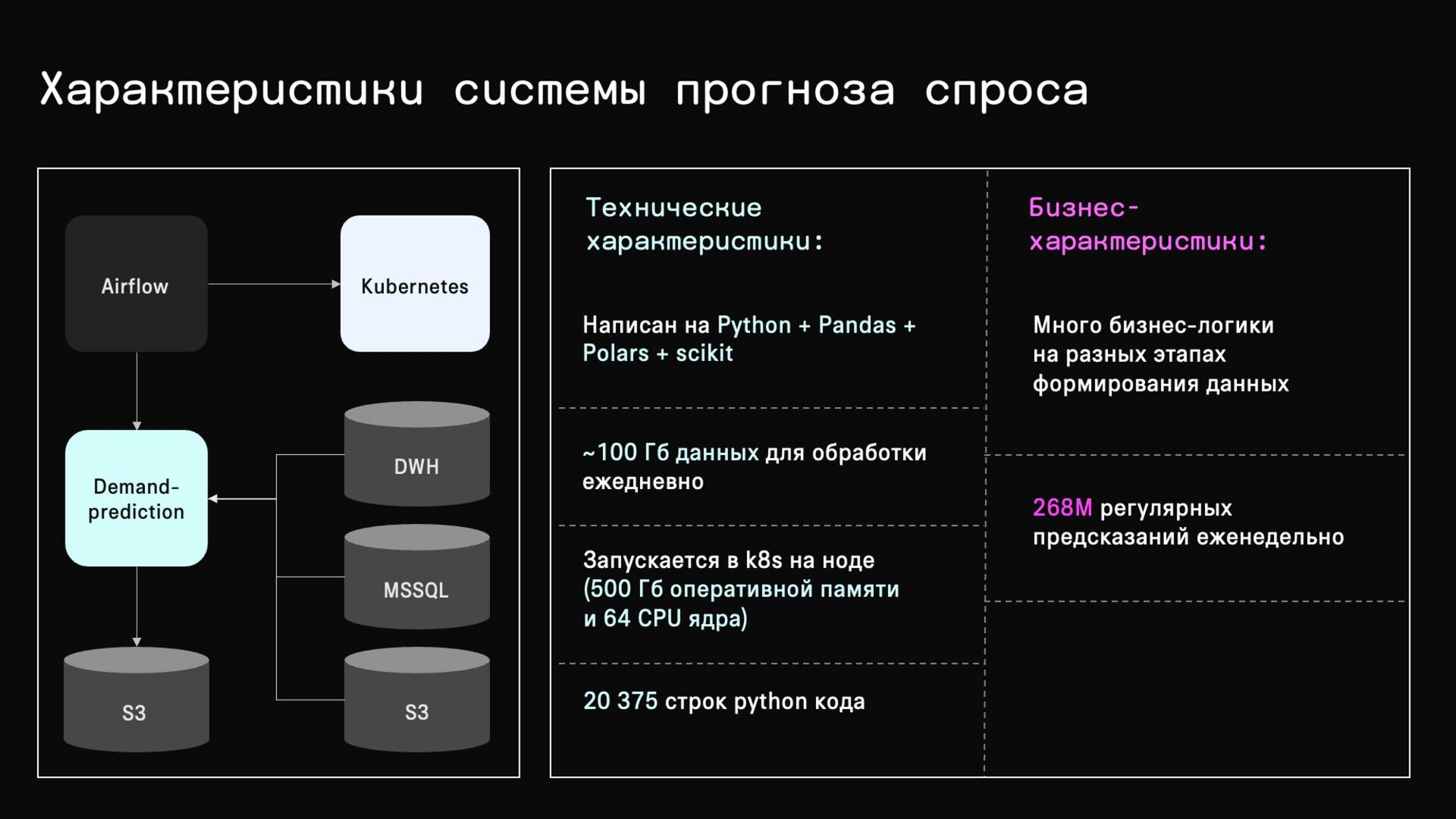{kind=link}
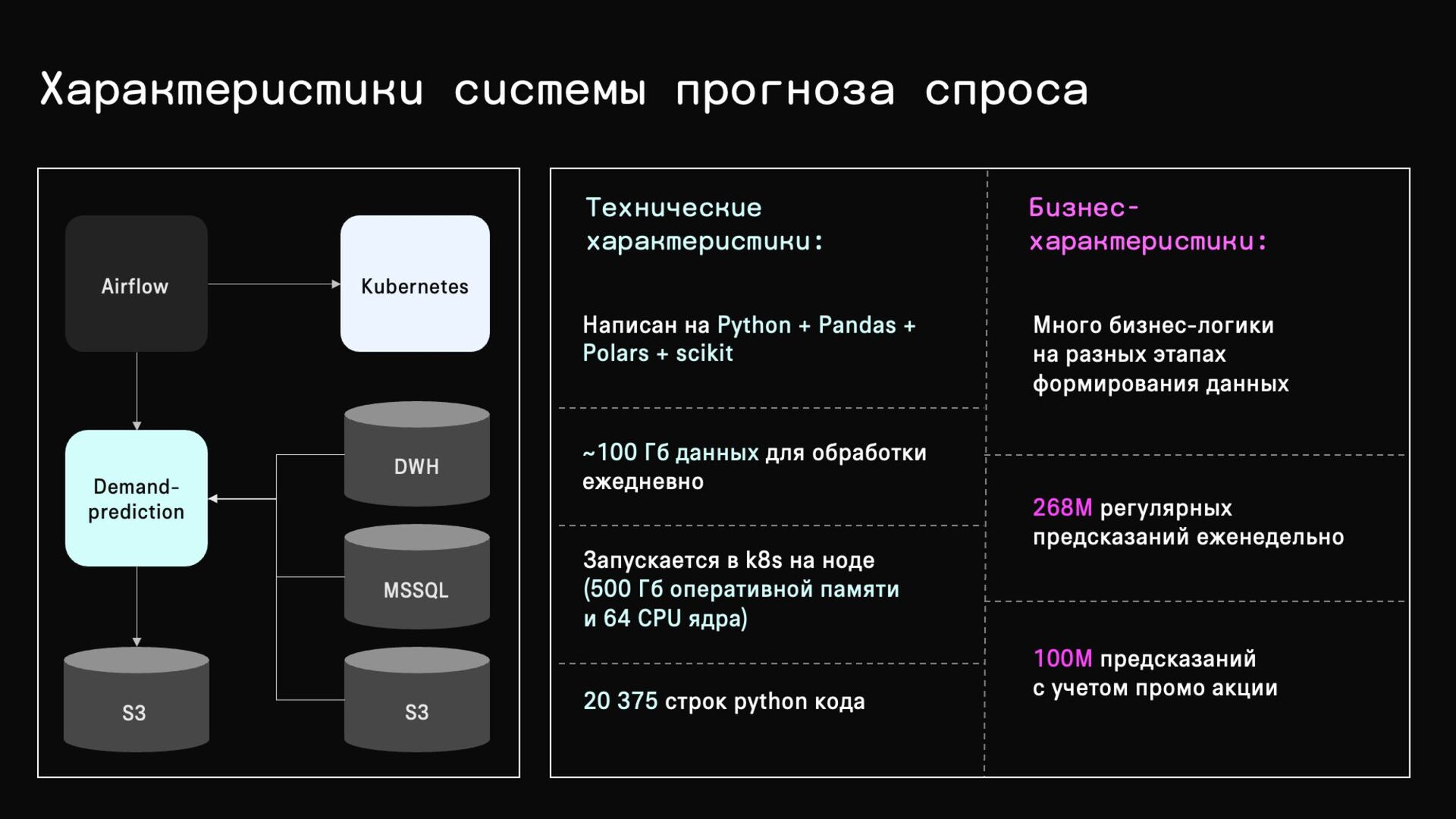{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
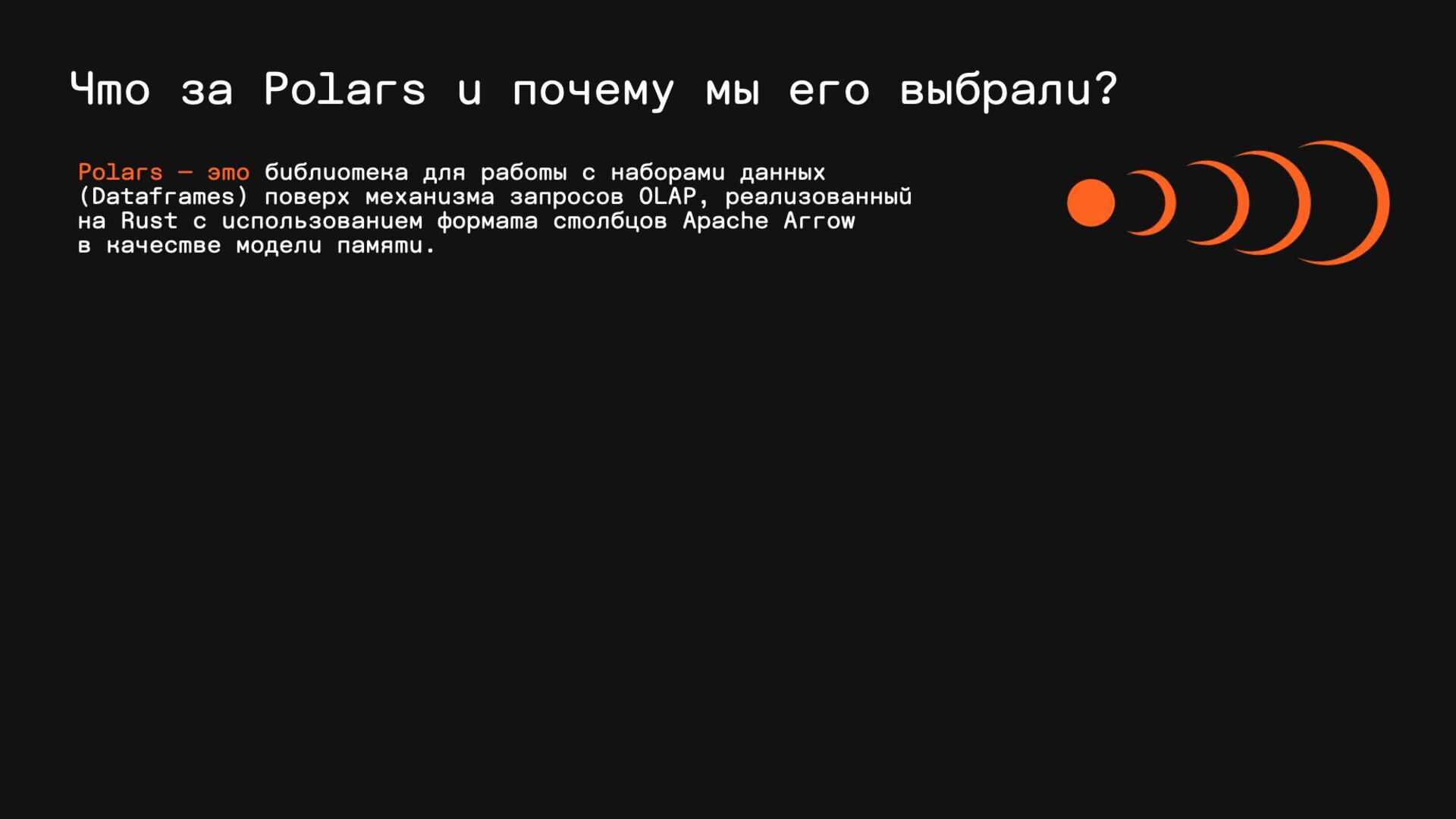{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
![Ленивая оптимизация запросов WITH COLUMNS [col(“Fare”).round()] WITH COLUMNS](https://files.speakerdeck.com/presentations/9d2aebb2b3854436943f18049f9439c9/slide_47.jpg){kind=link}
{kind=link}
{kind=link}
{kind=link}
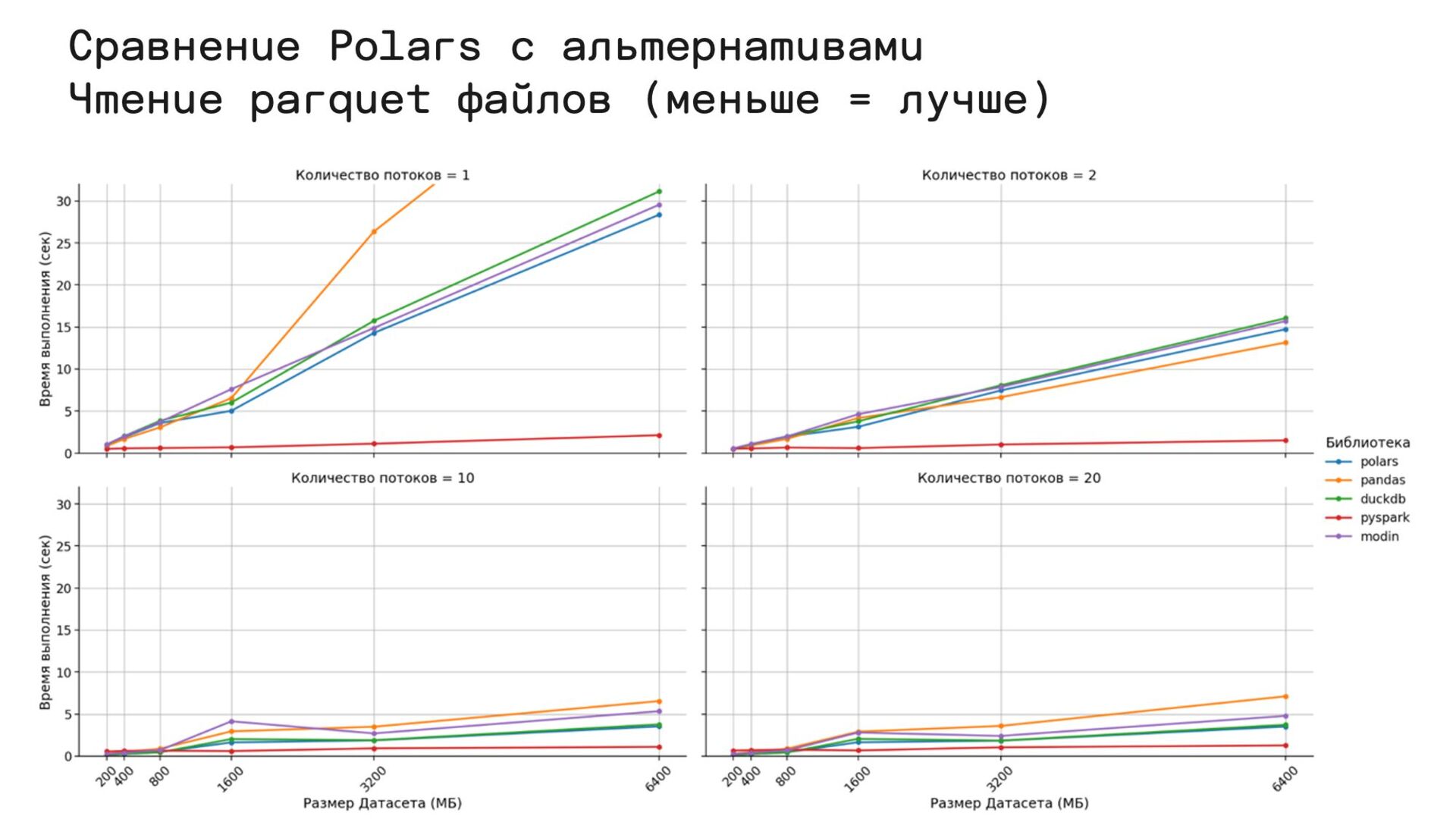{kind=link}
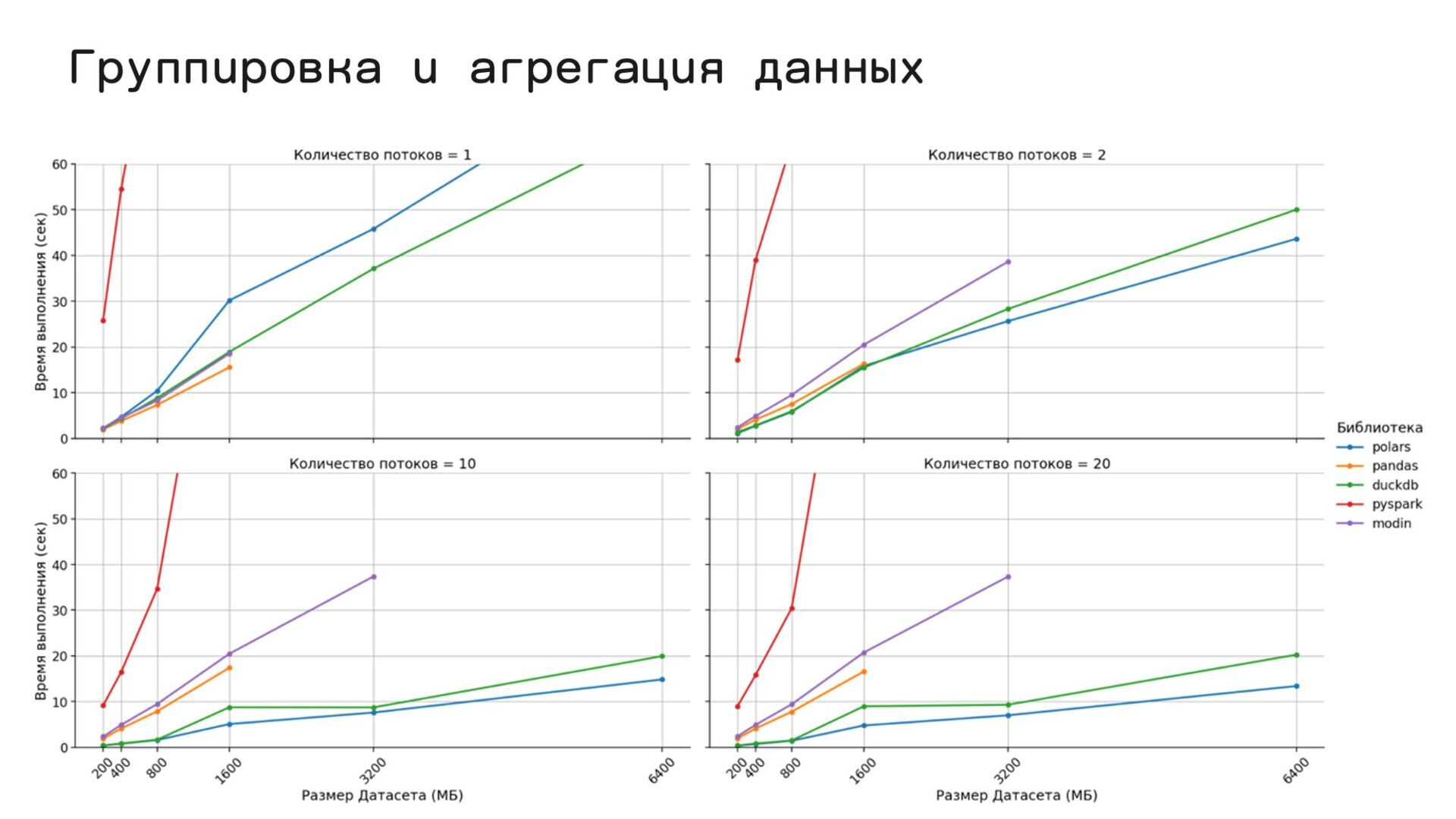{kind=link}
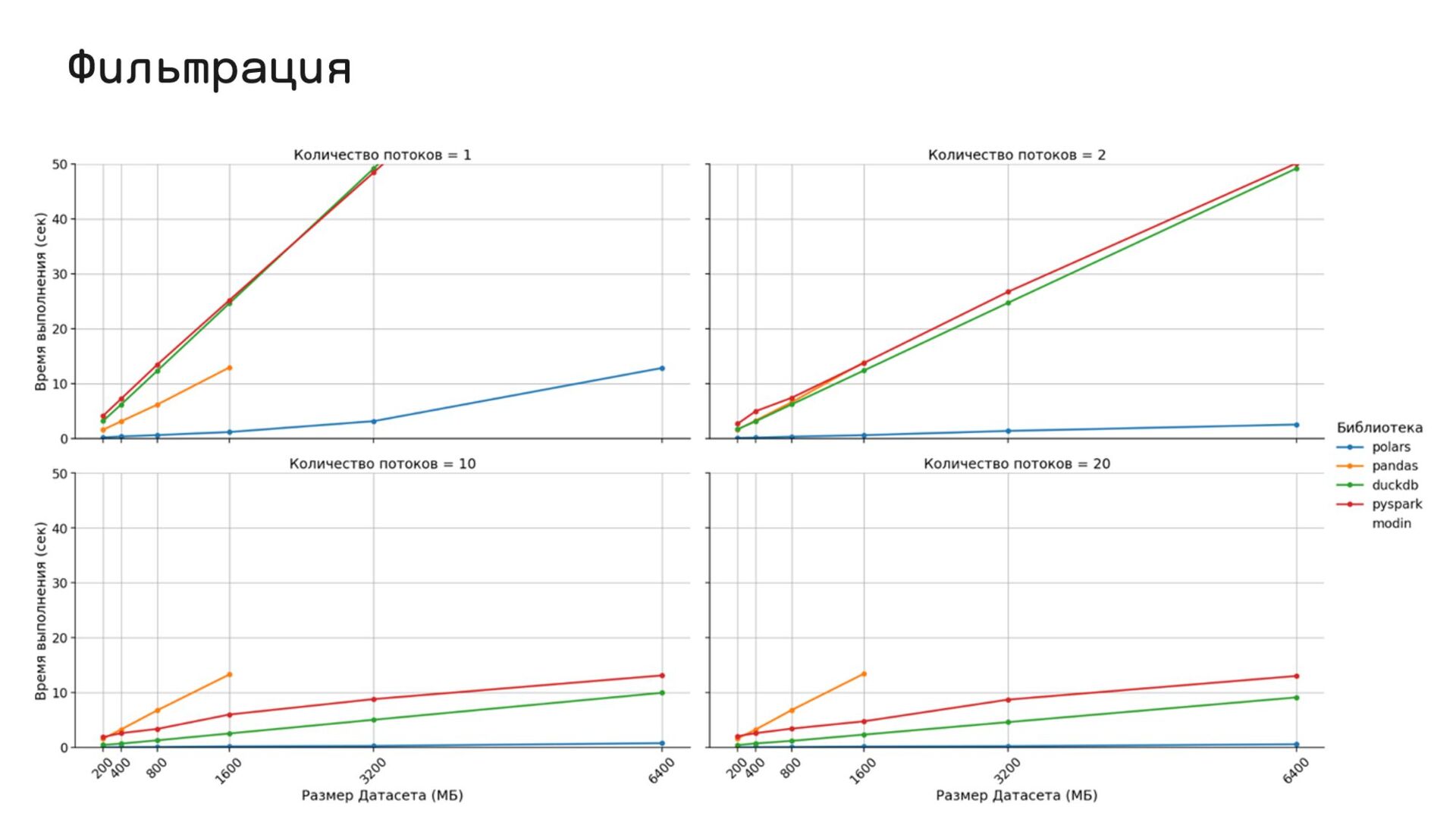{kind=link}
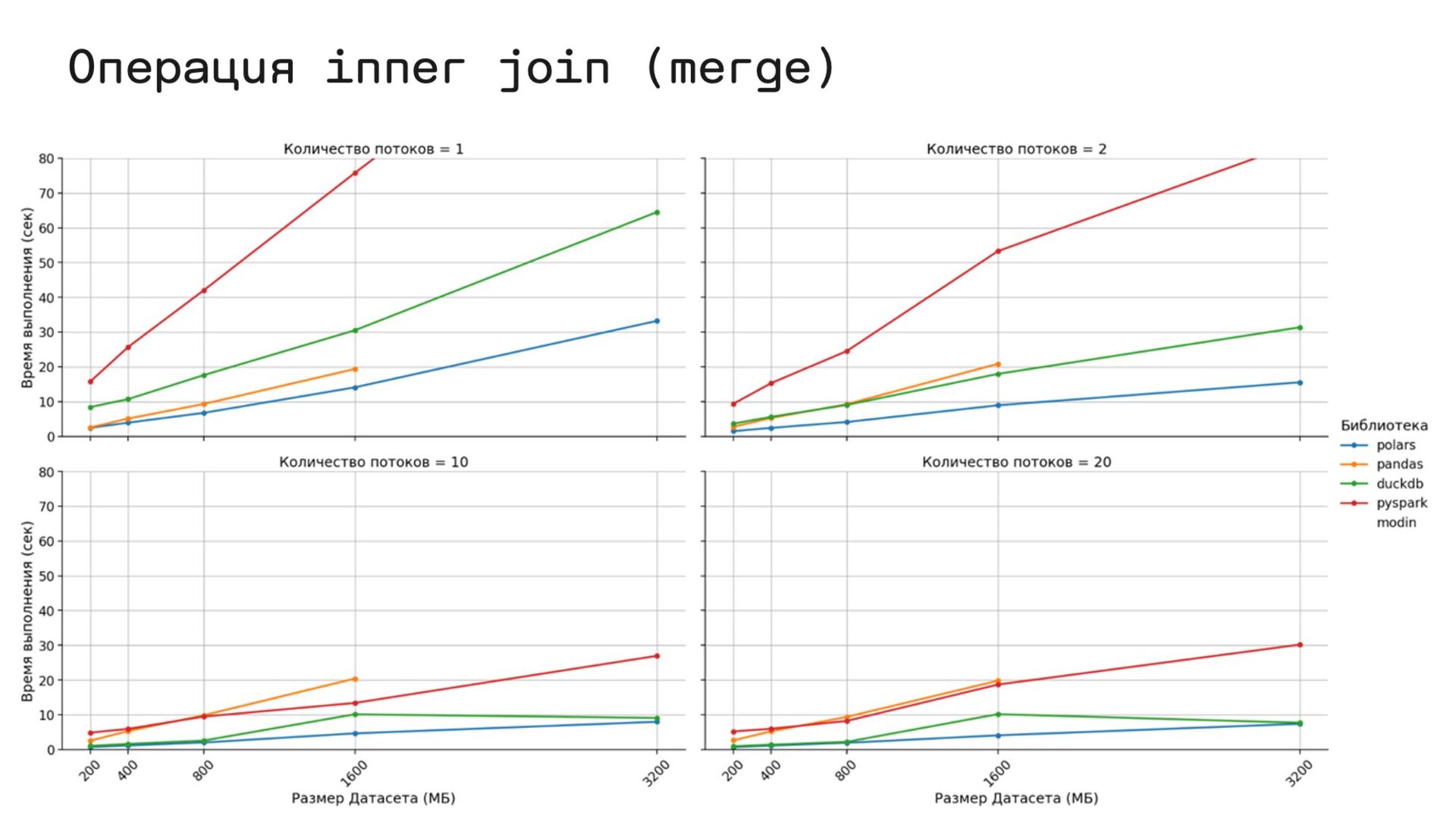{kind=link}
{kind=link}
{kind=link}