IR on Truffle Manuel Rigger1, Matthias Grimmer1, Christian Wimmer2, Thomas Würthinger2, Hanspeter Mössenböck1 VMIL, 31. October, 2016 1Johannes Kepler University Linz 2Oracle Labs
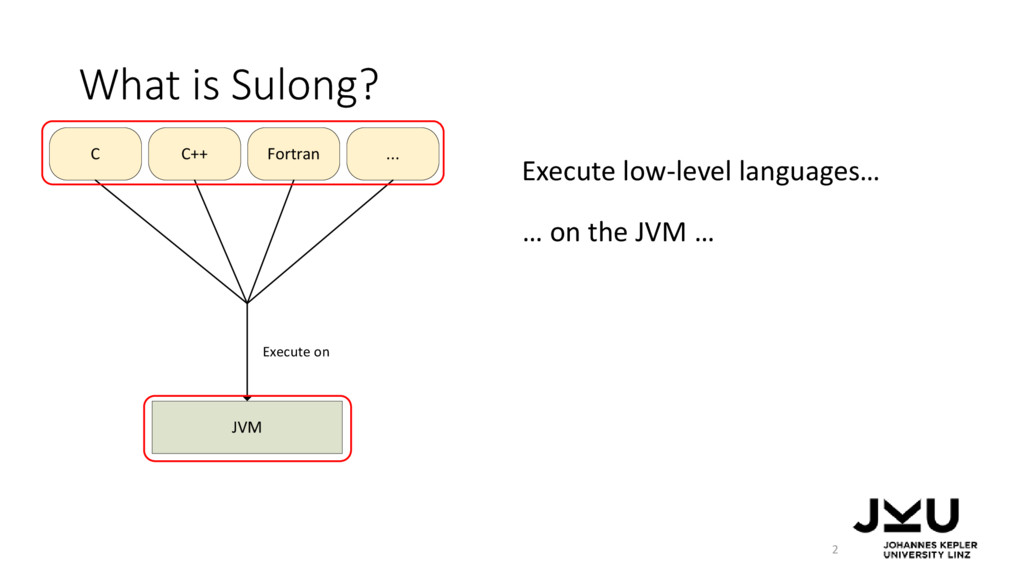
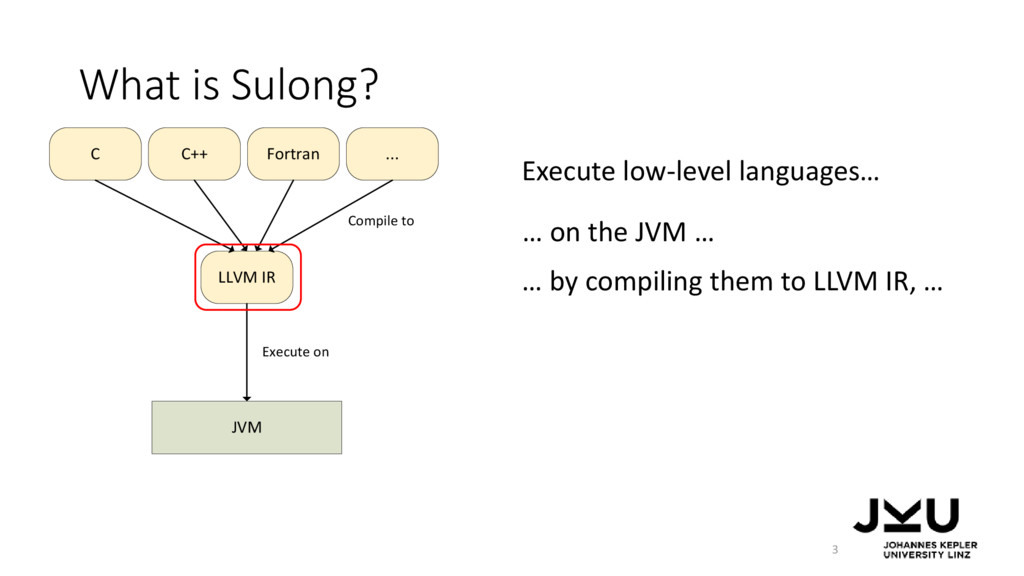
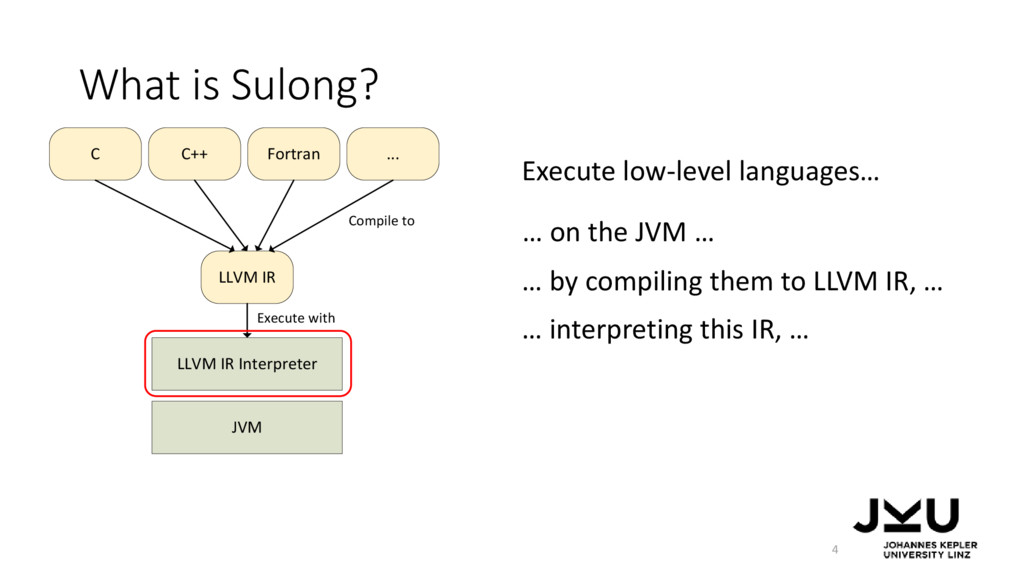
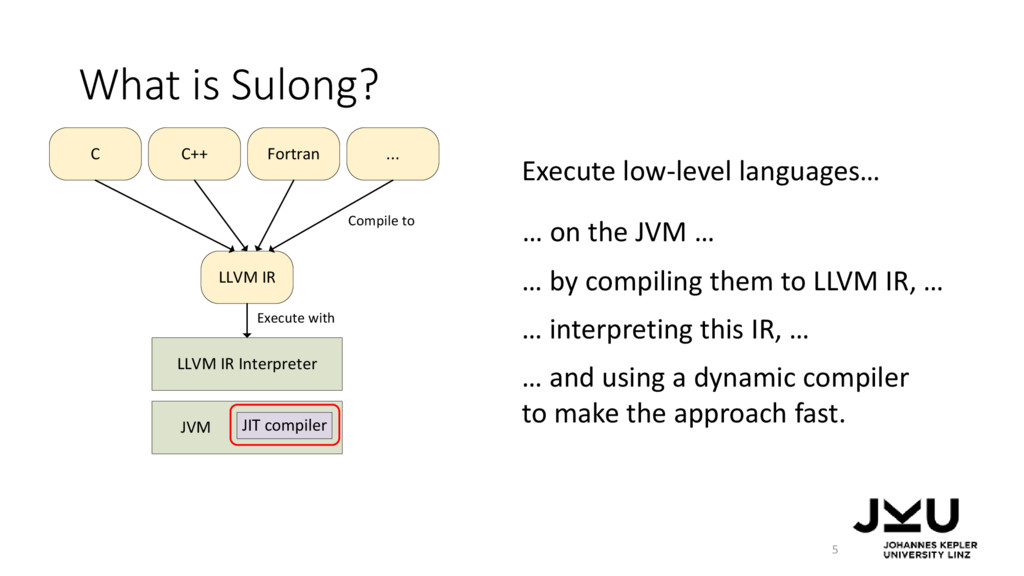
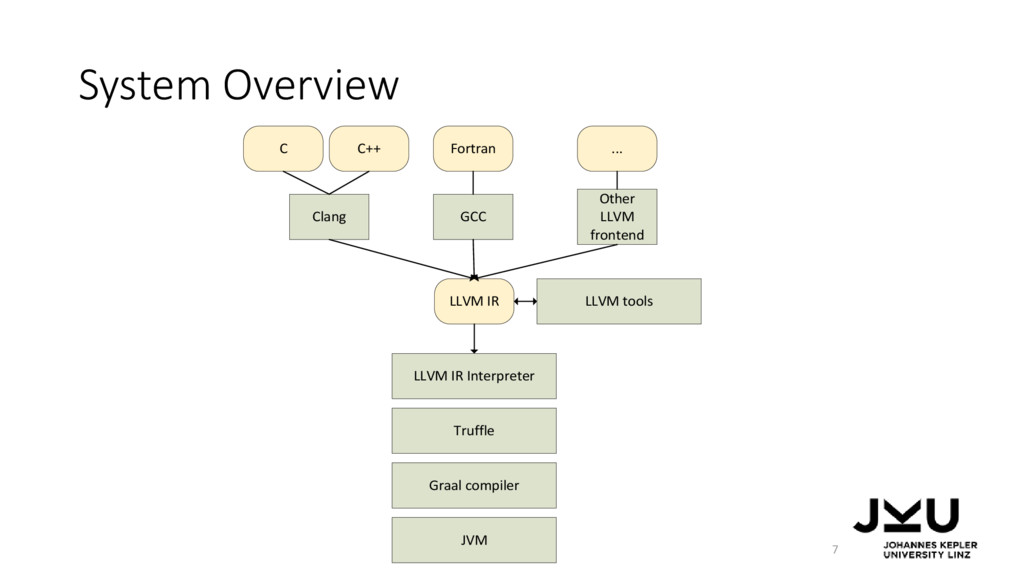
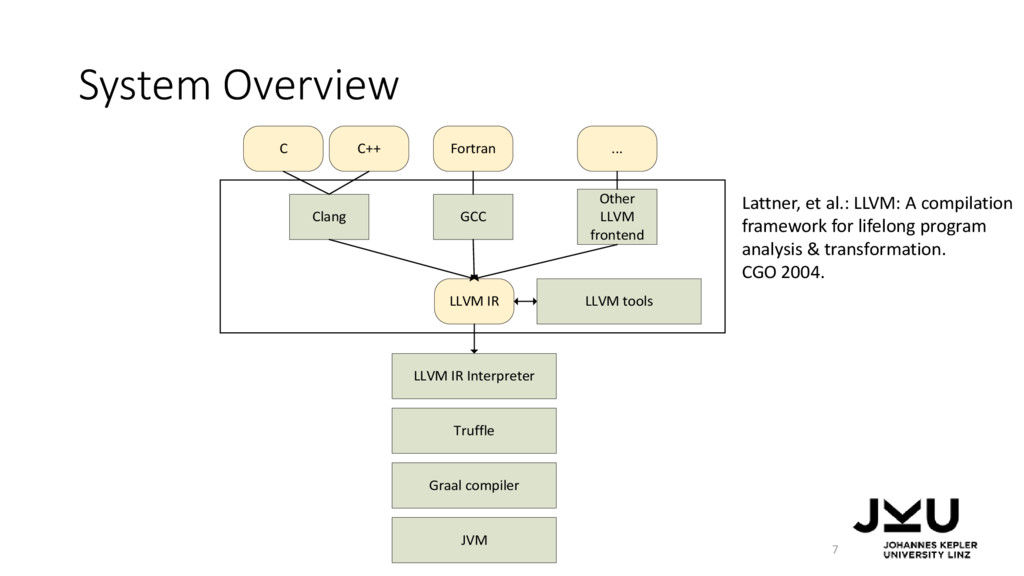
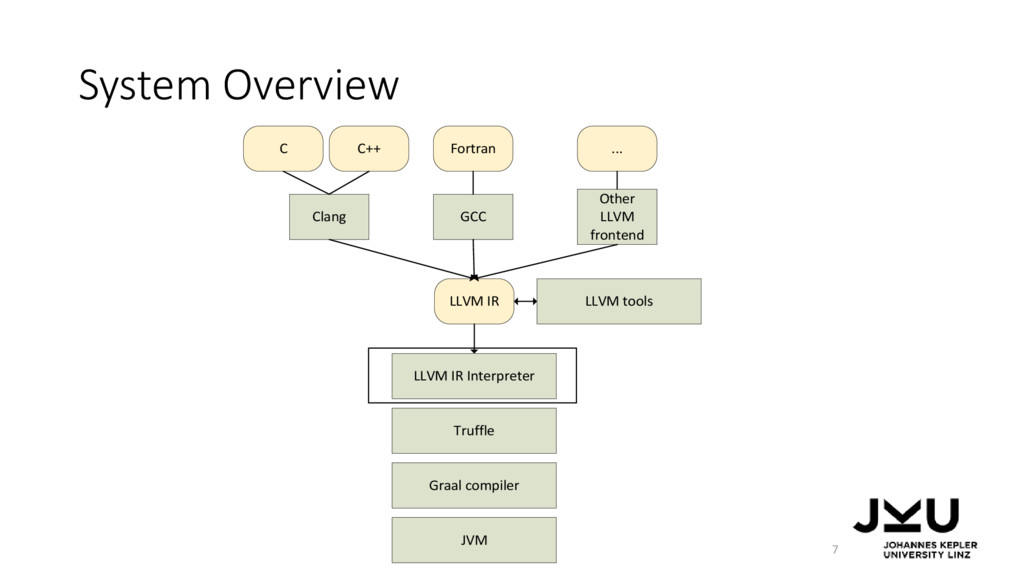
IR, … … on the JVM … … and using a dynamic compiler to make the approach fast. … by compiling them to LLVM IR, … LLVM IR Interpreter JVM LLVM IR C C++ Fortran ... JIT compiler Compile to Execute with
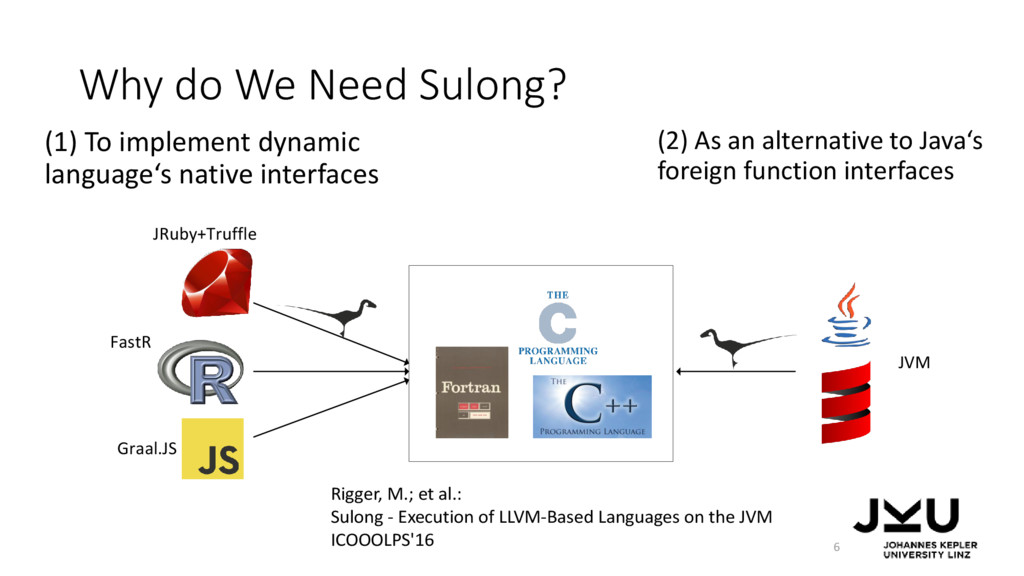
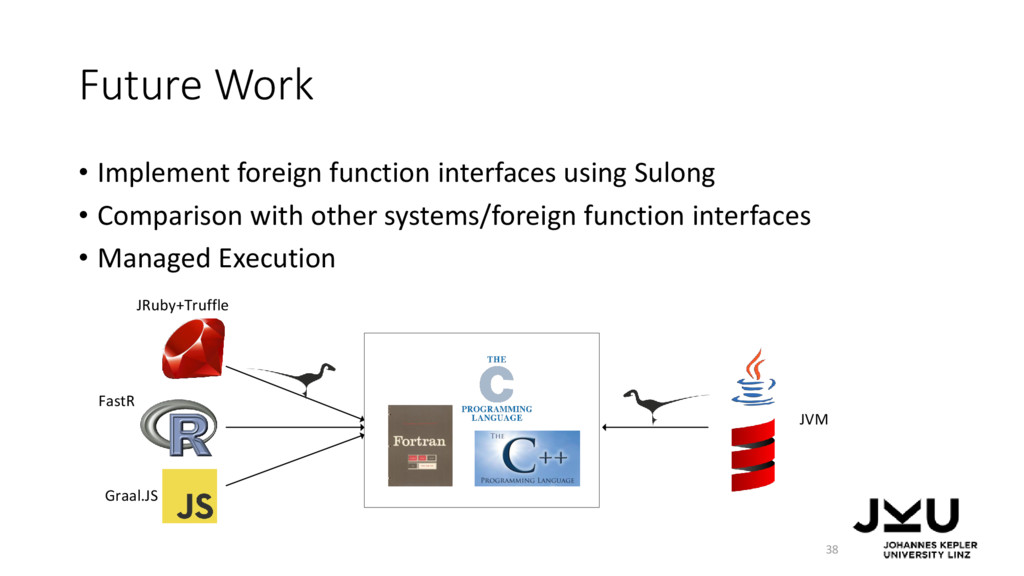
native interfaces 6 (2) As an alternative to Java‘s foreign function interfaces JRuby+Truffle FastR Graal.JS JVM Rigger, M.; et al.: Sulong - Execution of LLVM-Based Languages on the JVM ICOOOLPS'16
Fortran Other LLVM frontend ... JVM LLVM tools Graal compiler System Overview 7 Lattner, et al.: LLVM: A compilation framework for lifelong program analysis & transformation. CGO 2004.
memory Solution: LLVM optimizations • Promote to local variables • Dead store elimination • Traditional compiler optimizations based on alias analysis 27 Compile- time Run- time
Profiling information exploited by Truffle and Graal • Runtime inlining • Dynamic dead code elimination • Value profiling • Polymorphic inline caches 28 Compile- time Run- time
Execution of LLVM-Based Languages on the JVM. Int. Workshop on Implementation, Compilation, Optimization of Object-Oriented Languages, Programs and Systems (ICOOOLPS'16), July 18, 2016, Rome, Italy • Lattner, Chris, and Vikram Adve: LLVM: A compilation framework for lifelong program analysis & transformation. Code Generation and Optimization, 2004. CGO 2004. International Symposium on. IEEE, 2004. • Würthinger, Thomas, et al.: One VM to rule them all. Proceedings of the 2013 ACM international symposium on New ideas, new paradigms, and reflections on programming & software. ACM, 2013. • A. M. Erosa and L. J. Hendren. Taming control flow: A structured approach to eliminating goto statements. In Proceedings of Computer Languages, pages 229–240, 1994. 39
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}