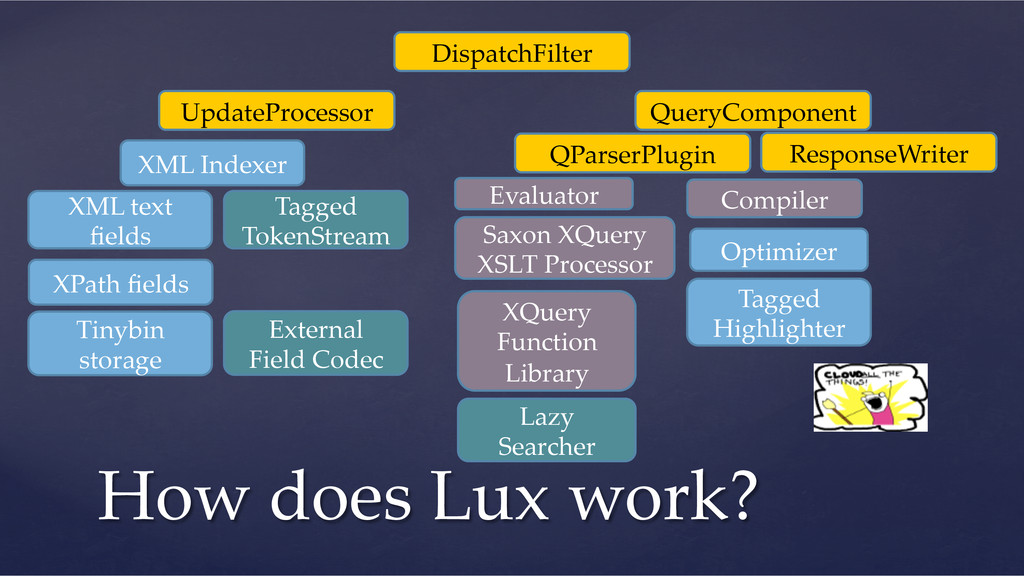
want a rich(er) query language ! Implementation Stories ! Indexing tagged text ! Storing documents in Lucene ! Lazy searching ! Demo The plan for this talk
site: safaribooksonline.com ! our clients sites: oed.com, degruyter.com, oxfordreference.com, … ! Publishers provide us with content ! we debug content problems ! we add new features nimbly ! Piles of random data (XML, mostly) Why did we make it?
! You don’t need it for edismax-‐‑style “quick” search ! or highly-‐‑structured data ! XQuery comes with a rich function library; ! rich string, numeric and date functions ! extensions for HTTP, filesystem, zip How can XQuery help?
“hamlet” in //scene/title, //speaker, etc… ! XQuery, but we need an index ! DIH XPathEntityProcessor ! But are XPath indexes enough? XML is text with context
! +speaker:Hamlet +line:poison ! Works great if we indexed speaker and line for each speech ! What if we only indexed at the scene level? ! What if we just indexed speech text as a field? ! XPath indexes are precise and fine-‐‑grained ! Great when you know exactly what you need How do we index context?
indexes, but more context than just full text ! XQuery post-‐‑processing to patch over the gaps ! Query optimizer applies indexes ! For when you don’t want to sweat the details: ad hoc queries, content analysis and debugging General purpose indexes
Zext:speech\:hamlet pos=1 Zext:speaker\:hamlet pos=1 Zext:scene\:to pos=2 Zext:speech\:to pos=2 … … scene speech speaker Hamlet … scene speech line To … scene speech line be Tokens emiZed <scene><speech> <speaker>Hamlet</speaker> <line>To be or not to be, … </line> ! Wraps an existing Analyzer (for the text) ! Responds to XML events (start element, etc) ! Maintains a tag name stack ! Emits each token prefixed by enclosing tags
phrase-‐‑labeling, NLP) ! citation classification w/probabilistic labeling ! One stored field for all the text makes highlighting easier ! One Lucene field means you can use PhraseQuery, eg: PhraseQuery(<speaker:hamlet <speech:to) finds all speeches by hamlet starting with “to”. Tagged token examples
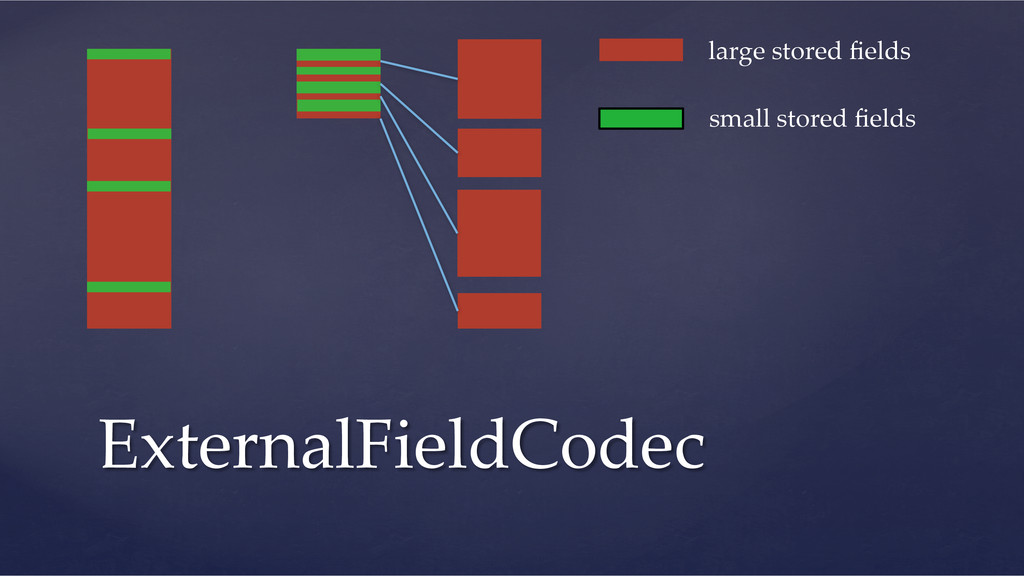
a bit slower in the worst case ! But, text analysis can take most of the time ! Net: useful if you are storing large binaries Codec Performance (preliminary)
in XQuery ! file uploads, redirects ! Ability to roll your own: cookies, authentication ! Rapid prototyping, testing query performance, relevance, in an application seZing App Server
the fields you need in advance? ! Yes, but did you want to format the result into a nice report *using your query language*? ! Yes, but did you want access to a complete XPath 2.0 implementation in your indexer? Isn’t Solr enough?
we need to support ! Perform complex updates to patch broken content ! Troubleshoot content ! Explore unfamiliar content ! Write prototypes and admin tools entirely in HTML, JS and XQuery ! Demo: hZp://localhost:8080 Example uses
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
![! XPath: //speech[speaker=“Hamlet”][contains(.,”poison”)] ! “optimized” XQuery:](https://files.speakerdeck.com/presentations/5419c2002dd201313a98663820a88a30/slide_15.jpg){kind=link}
{kind=link}
{kind=link}
![subsequence( for $doc in collection()[.//SPEAKER=“Hamlet”] order by](https://files.speakerdeck.com/presentations/5419c2002dd201313a98663820a88a30/slide_18.jpg){kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}