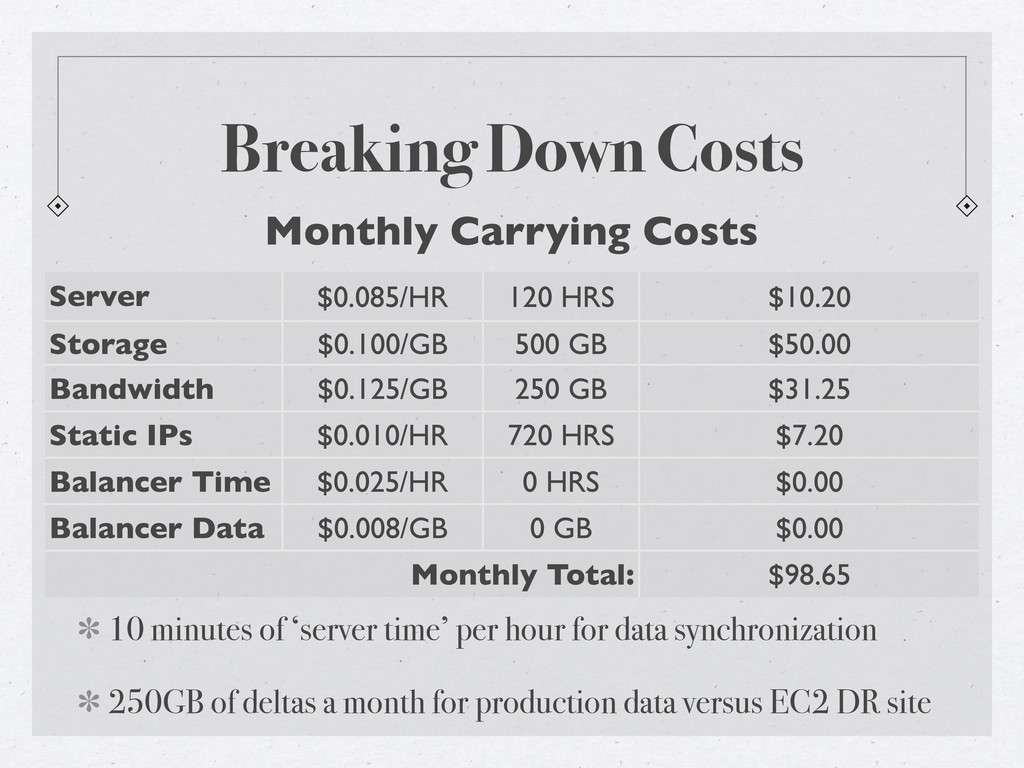
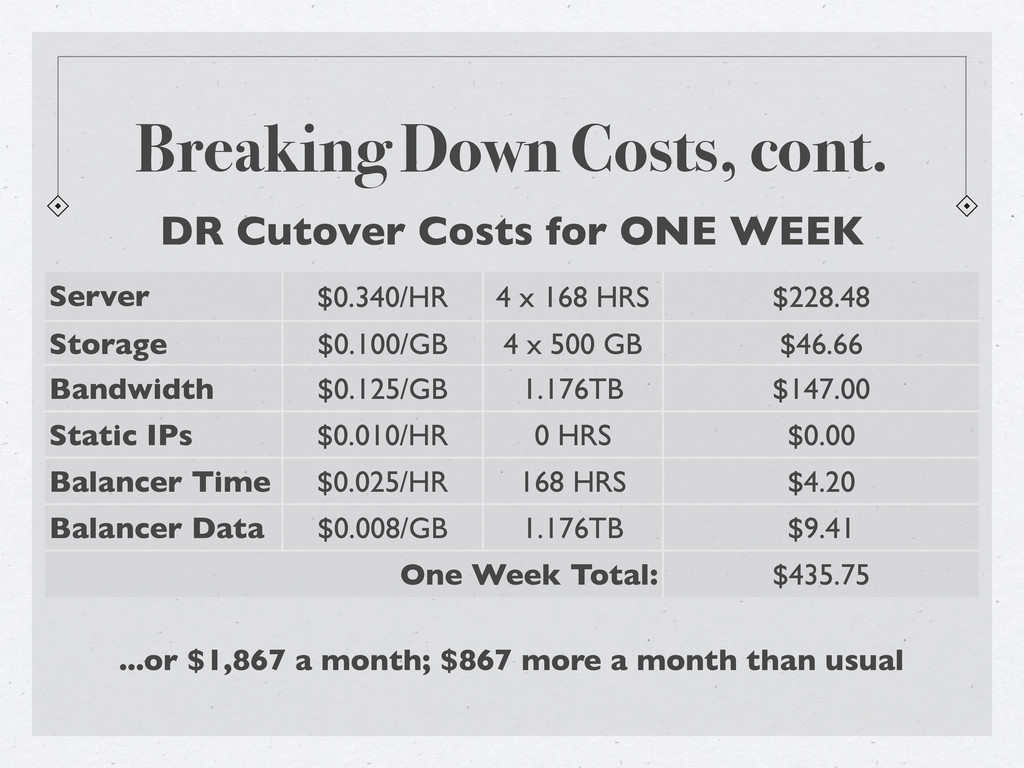
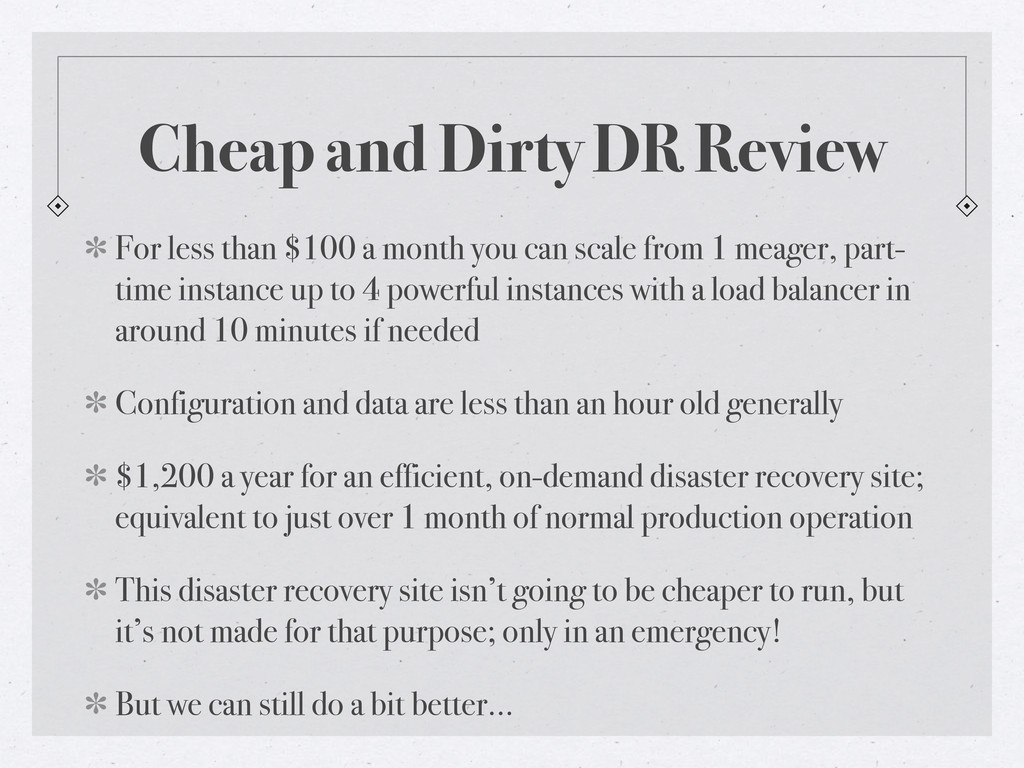
The small and medium business (SMB) are often deployed with just enough technology to run their operations due to financial constraints. Disaster recovery sites are rarely implemented for a company who likely cannot afford the costs to duplicate their entire infrastructure elsewhere, just-in-case.
Cloud computing holds a lot of promise for these companies due to the on-demand nature of resources available. Come learn how cloud computing (utilizing AWS) can offer those businesses a cost-effective method of continuing operations even if a worst-case scenario does afflict them. Discussion of a real-life scenario will be covered and the math and pros/cons of the plan will be reviewed.
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
![Thank You! Questions? [email protected] @markstanislav uncompiled.com](https://files.speakerdeck.com/presentations/9aa15350670d0130d62f1231394264b2/slide_19.jpg){kind=link}