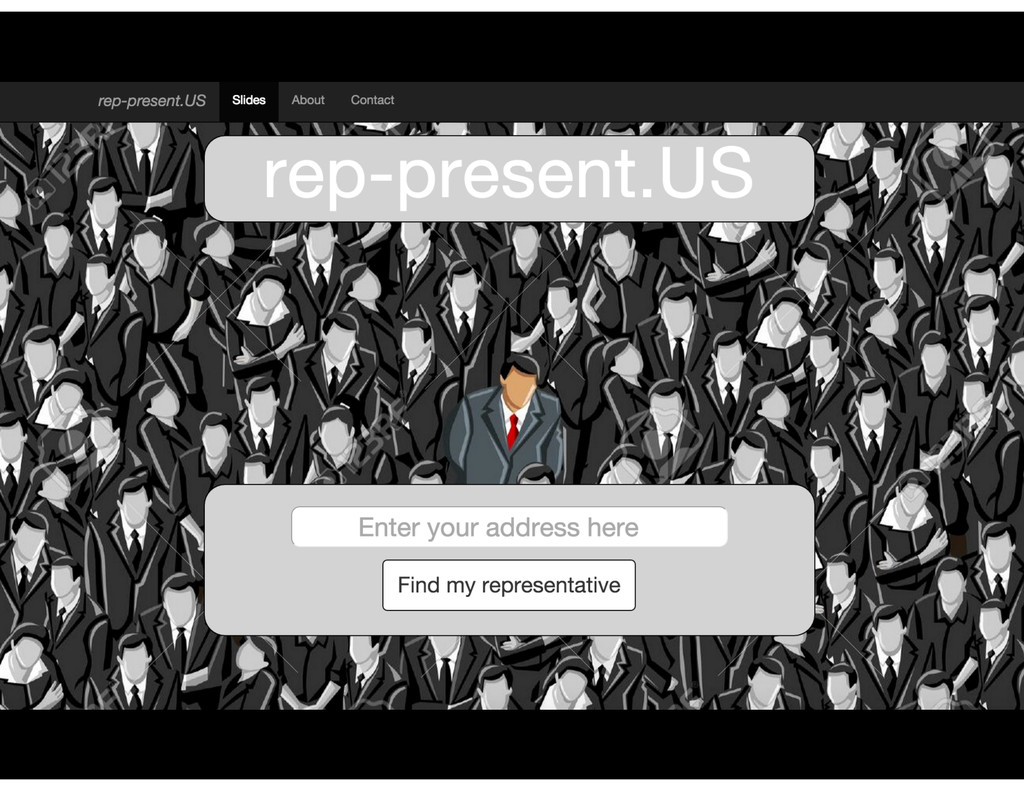
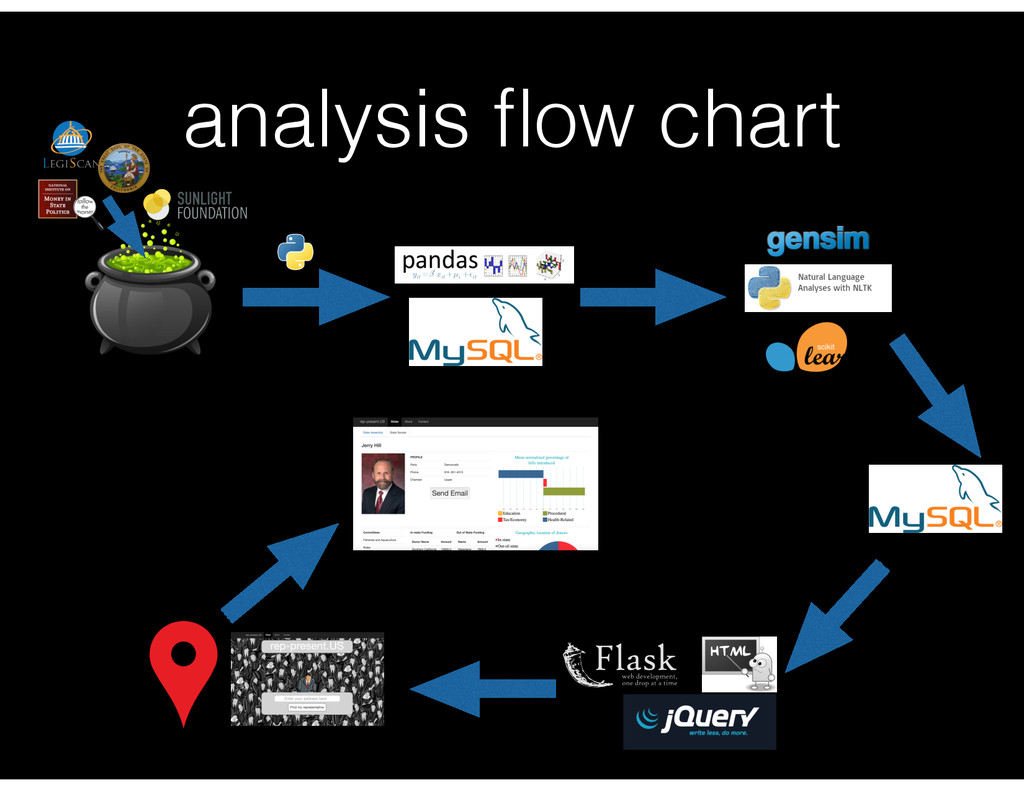
scraped off CA legislature site. • Location/district: googlemaps, sunlight, SQL • Representative information: sunlight API • Financial information: transparency data API
• Amass and clean the data (scrape) • Tokenize (stem vs. lemmatize) • N-grams • Identify stop words (nltk -> “df” in tfidf) • Latent Dirichlet Allocation (LDA) for distinct topics
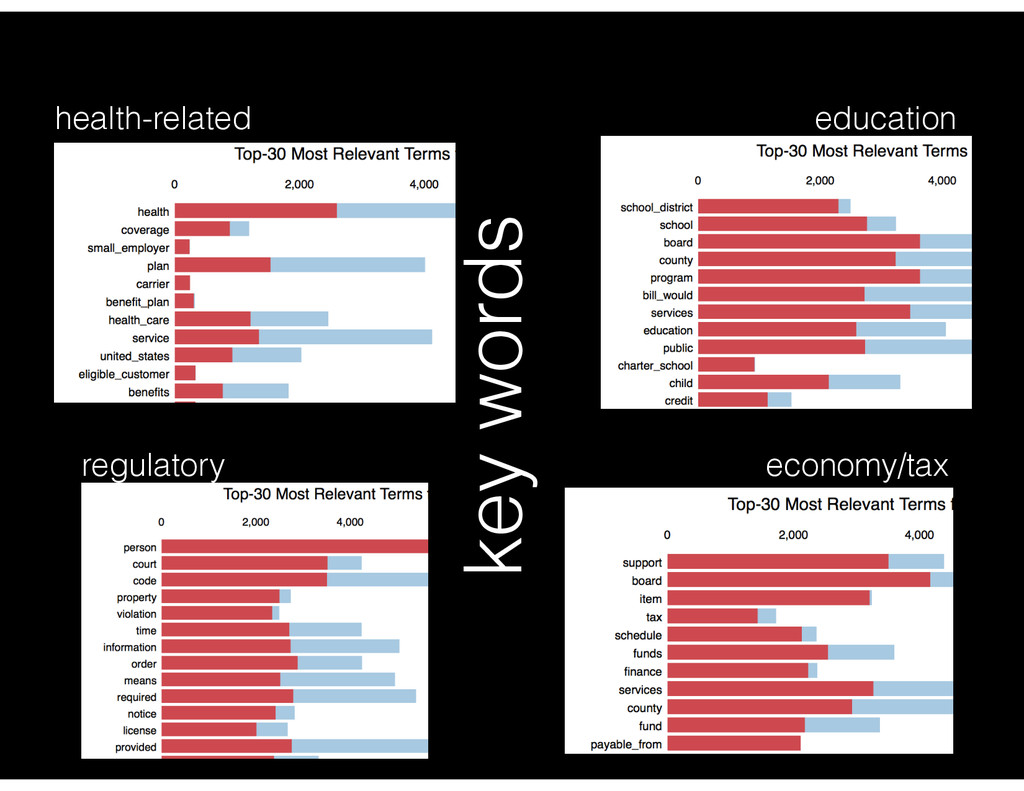
[changing rules, etc]) • trained on 80% — validated on sample of single- topic bills from test set. • correctly identified 50 out of 50 single-topic bills a (few) examples: 96% health 94%health 98% health 97% education 88% education (valley fever) (stroke) (alzheimers) (apprenticeship) (postsecondary)
single-topic (>85%) • distribution of single topic bills: education (450), health (183), tax (65), regulations/procedures (304) • sample regulation ones: Alcoholic beverage control, gambling, etc. • trained on 80%, of the 20% left for testing, ~130 are single-topic. Checked a sample of each of those to confirm (~40 total) and they all agreed. • corpus: 1.6million words, dictionary of ~26K tokens when tokenized and throwing out single occurrences. • bigrams: 33%. trigrams: 0! • sample multi-topical: SB65 dealing with establishing olive oil commission for grading olive oil from within the state department of public health; drought regulation and education.
• on expanded corpus, use word2vec to identify extra topics of interest (i.e., environment, social services) • voting records • track “flip-flopping” • trend of topics • NLP of speeches • correlation between actions and donor interest. • expand to all states nationwide. • include organizations to fund for/against representative. • get picked up by fivethirtyeight
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}