working as a Software Engineer with Cliqz : Cliqz is the new way to navigate the Internet. With CLIQZ for Firefox you're clicking directly, quickly and safely through the Web. Prior to this was working with one of the largest e-commerce websites in India.
care about a DataPipeline? We are generating data at a rapid pace. Data sources are in abundance, different formats, frequencies. Need to have a pro-active approach, gain insights as and when the data is being generated. Behaviour of the product / app needs to adapt to how the user has engaged in the past, and is engaging at the moment.
Layer : Tightly couples together with the streamprocessing layer Deployment model Data source reliability Multiple consumers Replay messages (Will cover in guranteed message processing) Data locality Example : Kafka ## Processing Layer(common patterns) ## Processing Layer(common patterns) Batch Microbatch Streaming ## Storage / Query layer ## Storage / Query layer Processed data served using cache Intermediate processing data Persist raw and processed data
Challenges : Scalability: Ingest humdreds of millions of events per minute / day in real time. High degree of robustness Reliable data processing Fault-tolerance : Resilient to software and hardware failures and continue to meet SLA's Low latency : Site facing applications need response times in the order of milliseconds Partioning, Routing, Serialization Meter and gauges to what's going under the hood Control knobs Multi-lang support
## Apache storm : High degree of robustness Reliable data processing Fault-tolerance Low latency Partioning, Routing, Serialization Meter and gauges to what's going under the hood Control knobs Multi-lang support
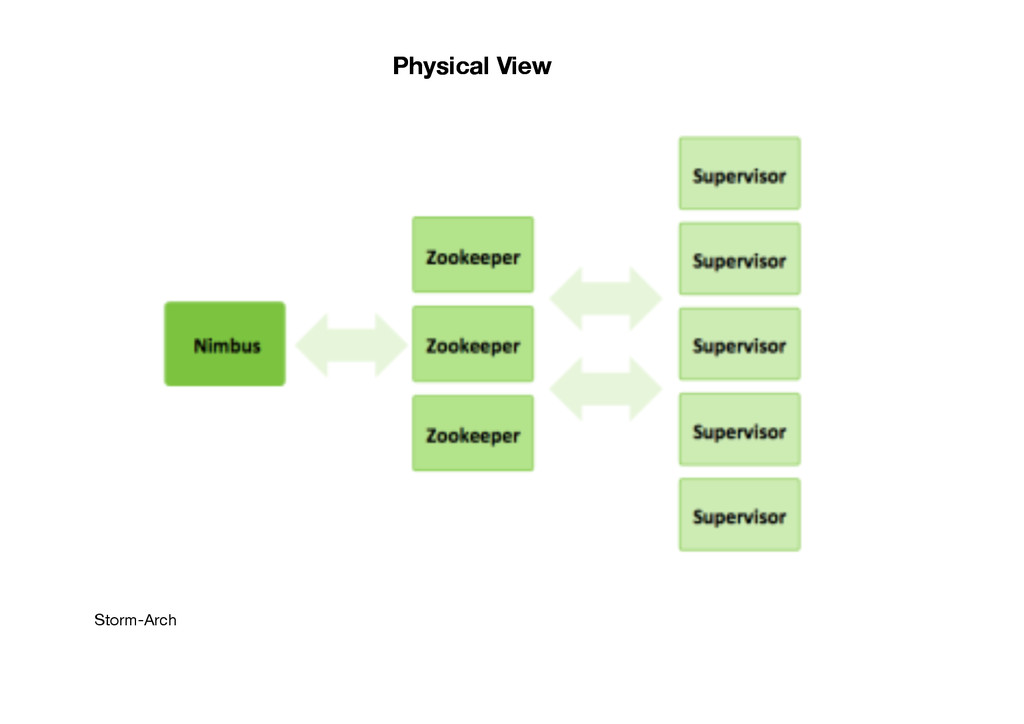
cluster. Deployment of topology. Task assignment and re-assignment in case of failure. ZooKeeper nodes – coordinates the Storm cluster Supervisor nodes – communicates with Nimbus through Zookeeper, starts and stops workers according to signals from Nimbus Fault tolerant
flow work ### How does the flow work Tuple Tree : Spout emits a touple, which goes to a bolt Bolt produces another tuple based on the previous one, the next bolt produces another set. A spout tuple is not considered fully complete until all the tuples in the tree have finished processing. Not completed withing a specified amount of time then replay the spout tuple. We can leverage the Reliability API by anchoring, which is essentially tagging the new tuple with input tuple. Special tasks dedicated, called ACKER Tasks. ### Scenarios ### Scenarios A tuple isn't acked because the task died. Acker task dies. Spout task dies.
DRPC Resource Managers : Storm-Yarn, Storm with mesos Running Apache Storm securley : https://github.com/apache/storm/blob/master/SECURITY.md Storm-Deploy : https://github.com/miguno/wirbelsturm Internal messaging in Apache Storm : Intra-worker communication : inter-thread on the same Storm node Inter-worker communication : node-to-node across the network Inter-topology or across cluster communication: nothing built into Storm Useful read : http://www.michael-noll.com/blog/2013/06/21/understanding-storm- internal-message-buffers/ streamparse : https://github.com/Parsely/streamparse Storm official docs : https://storm.apache.org/
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
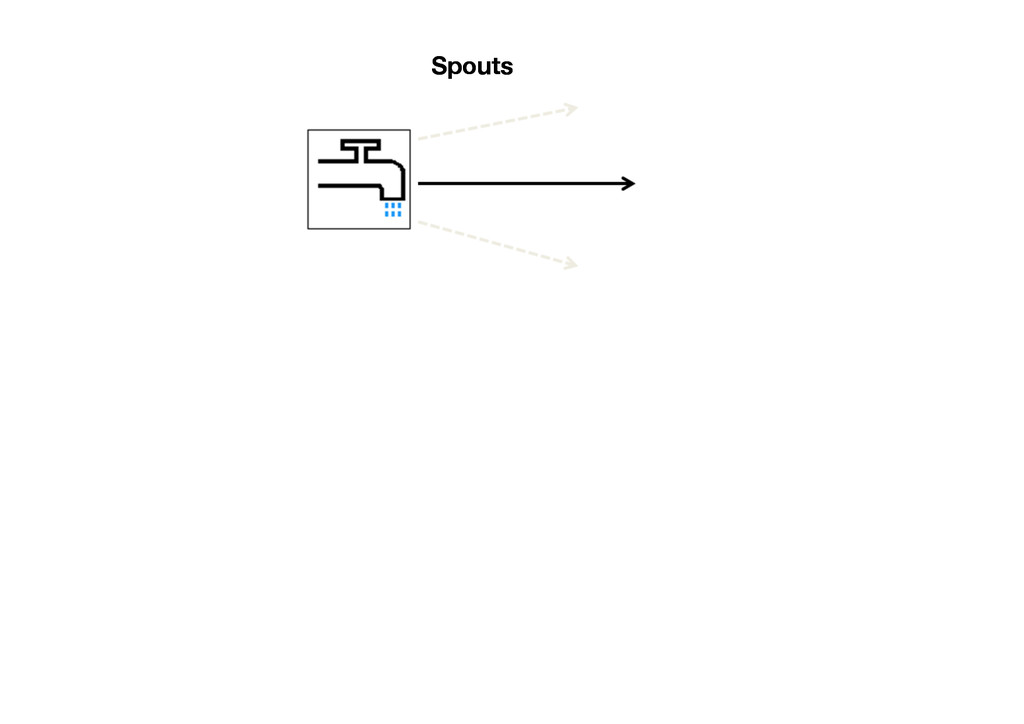{kind=link}
![In []: import itertools from streamparse.spout import Spout from websocket](https://files.speakerdeck.com/presentations/51042a92e4fd40f88b90f79fb9e1636f/slide_11.jpg){kind=link}
{kind=link}
{kind=link}
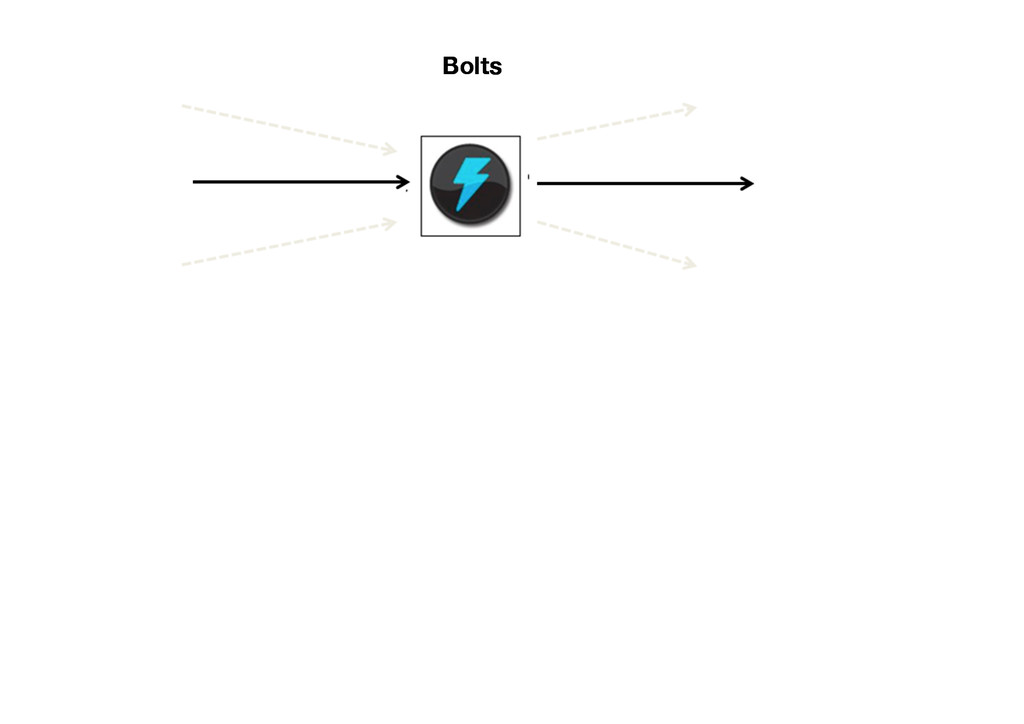{kind=link}
![In []: from collections import Counter from streamparse.bolt import Bolt](https://files.speakerdeck.com/presentations/51042a92e4fd40f88b90f79fb9e1636f/slide_15.jpg){kind=link}
{kind=link}
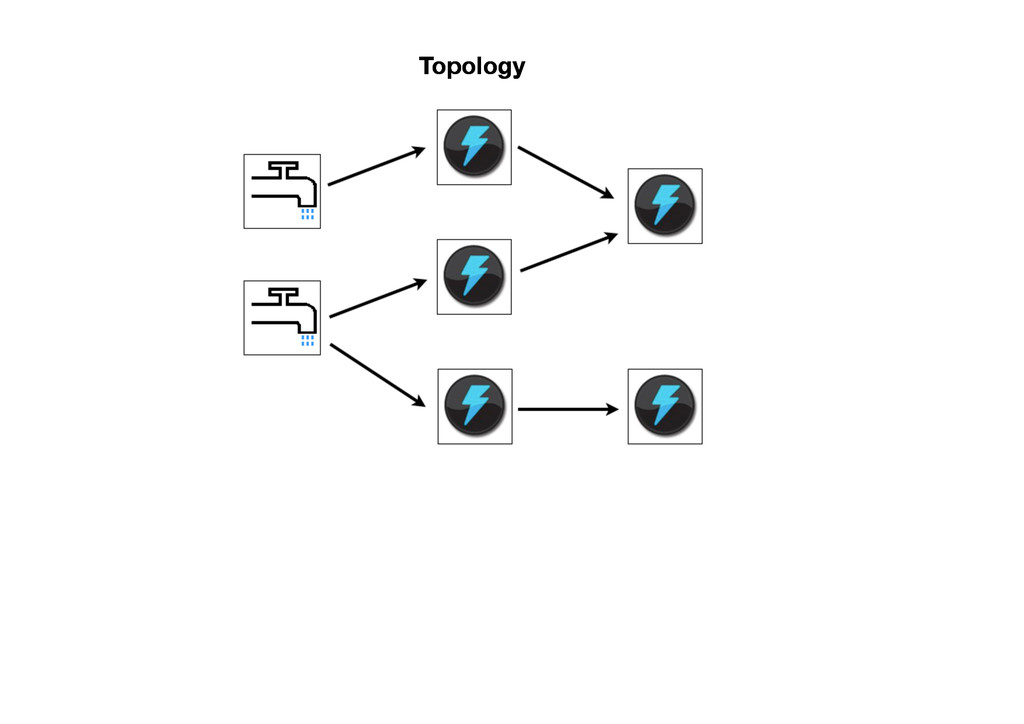{kind=link}
![In []: (ns wikipedialogs (:use [streamparse.specs]) (:gen-class)) (defn wikipedialogs [options]](https://files.speakerdeck.com/presentations/51042a92e4fd40f88b90f79fb9e1636f/slide_18.jpg){kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}