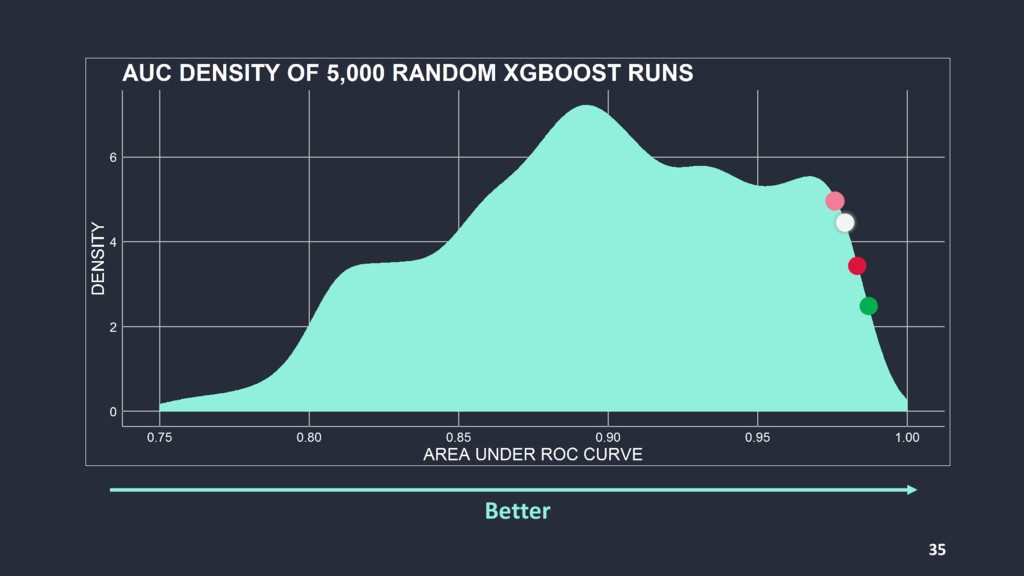
While tuning hyperparameters of machine learning algorithms is computationally expensive, it also proves vital for improving their predictive performance. Methods for tuning range from manual search to more complex procedures like Bayesian optimization. This talk will demonstrate the latest methods for finding good hyperparameter-sets within a set period of time for common algorithms like xgboost.
{kind=link}
{kind=link}
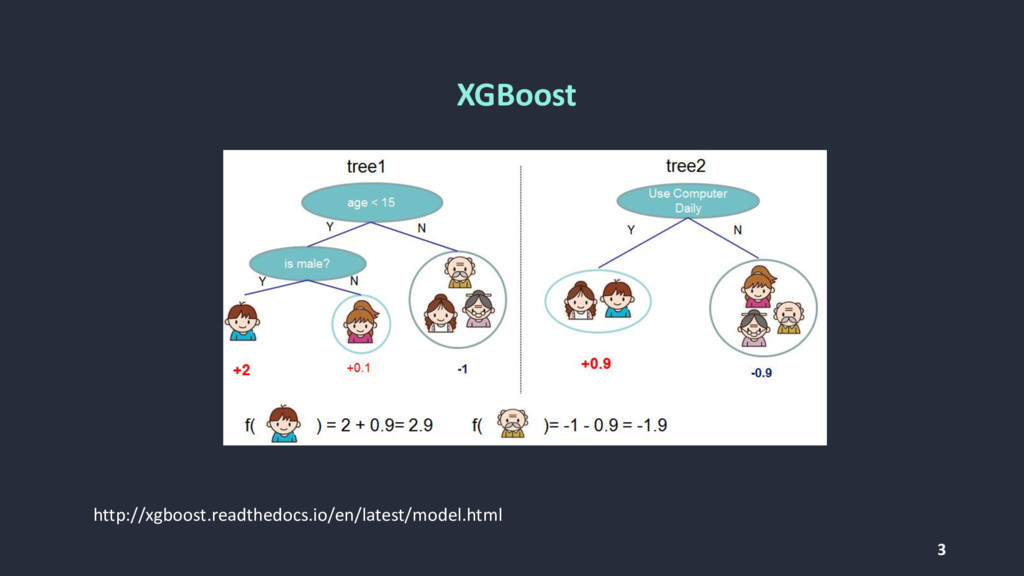{kind=link}
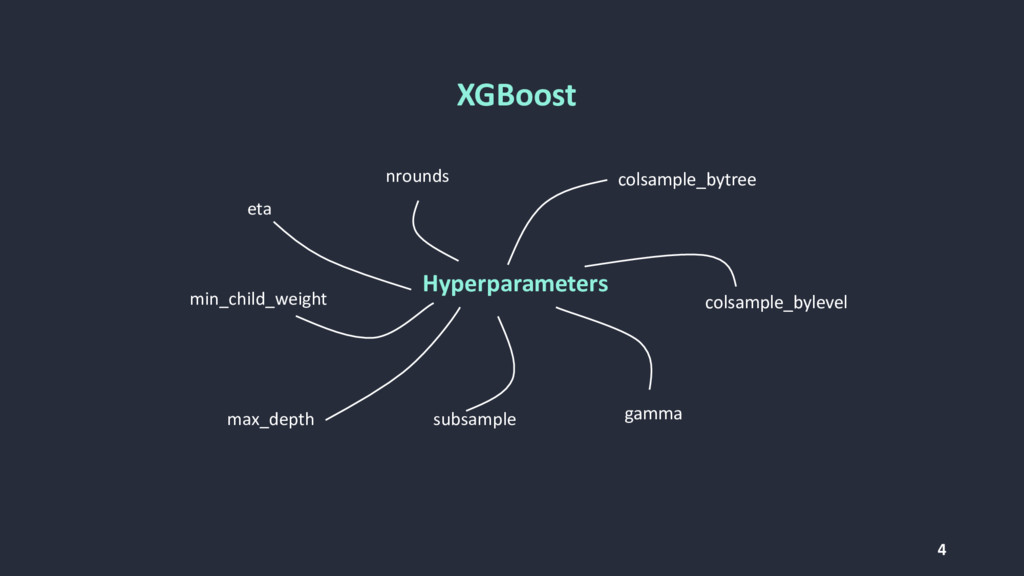{kind=link}
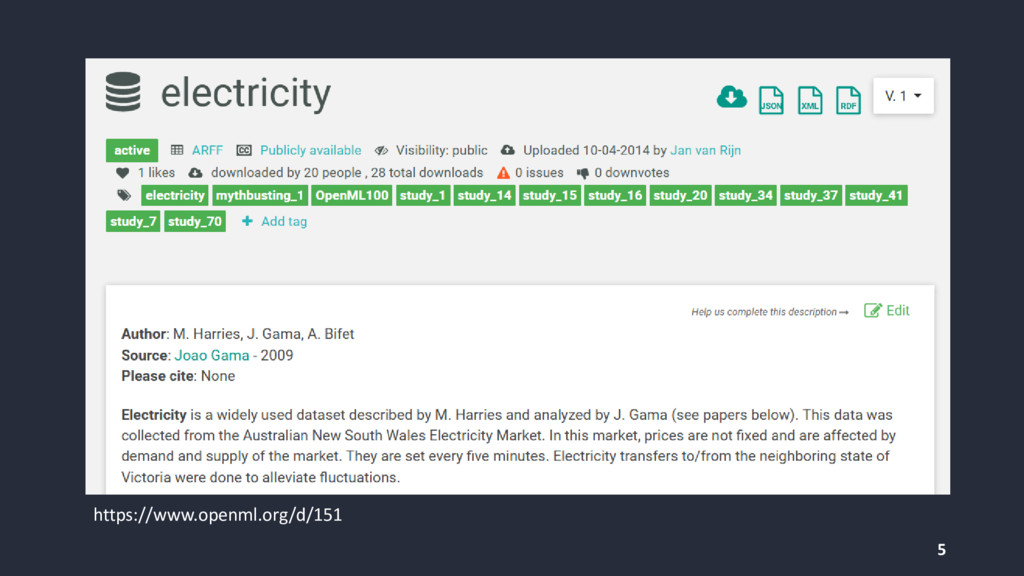{kind=link}
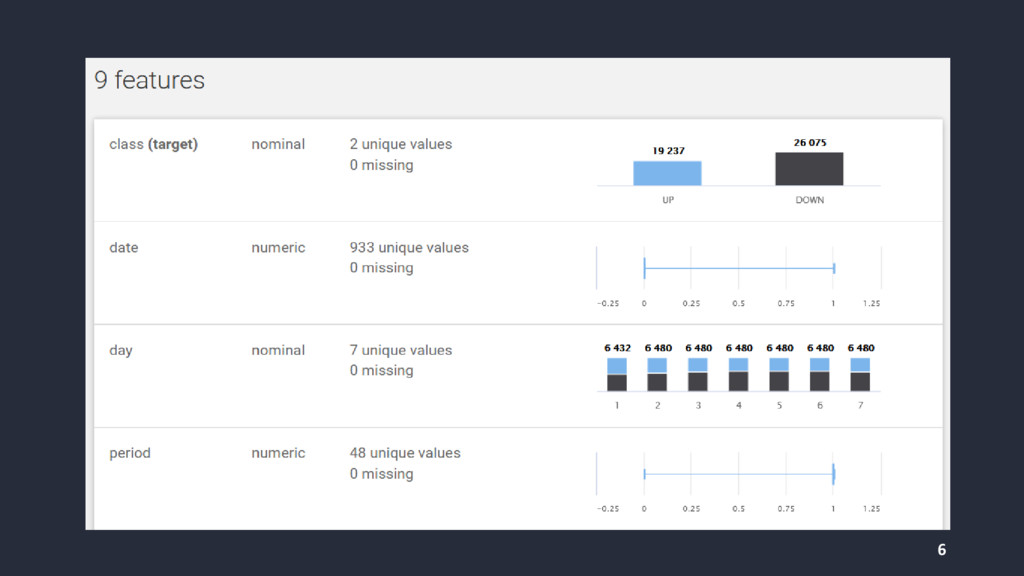{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
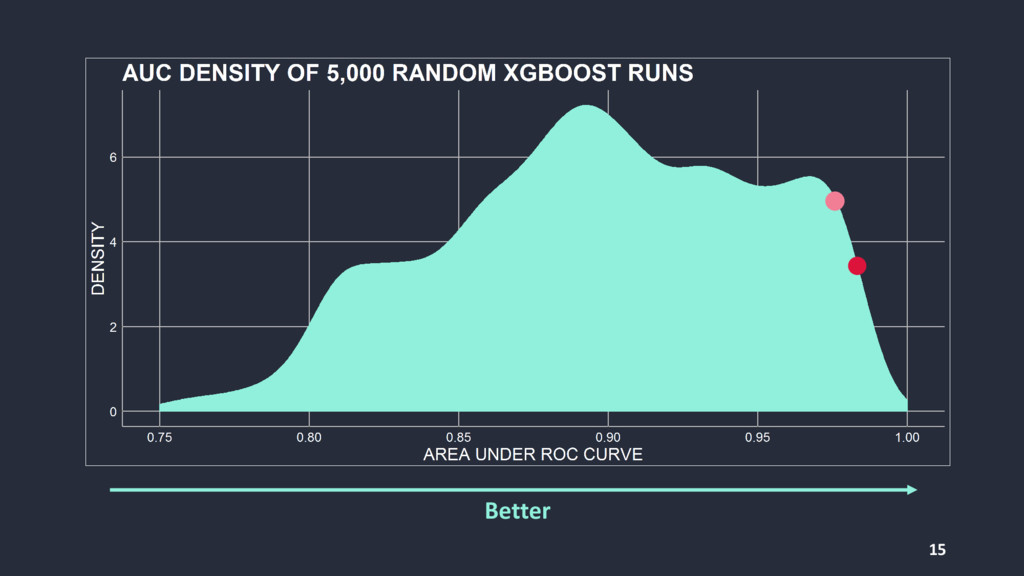{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
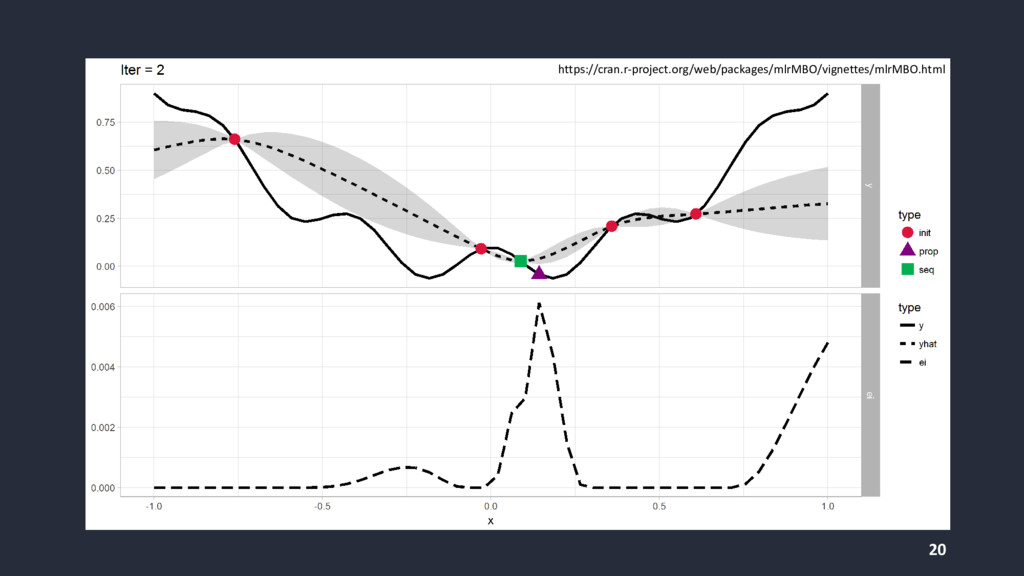{kind=link}
{kind=link}
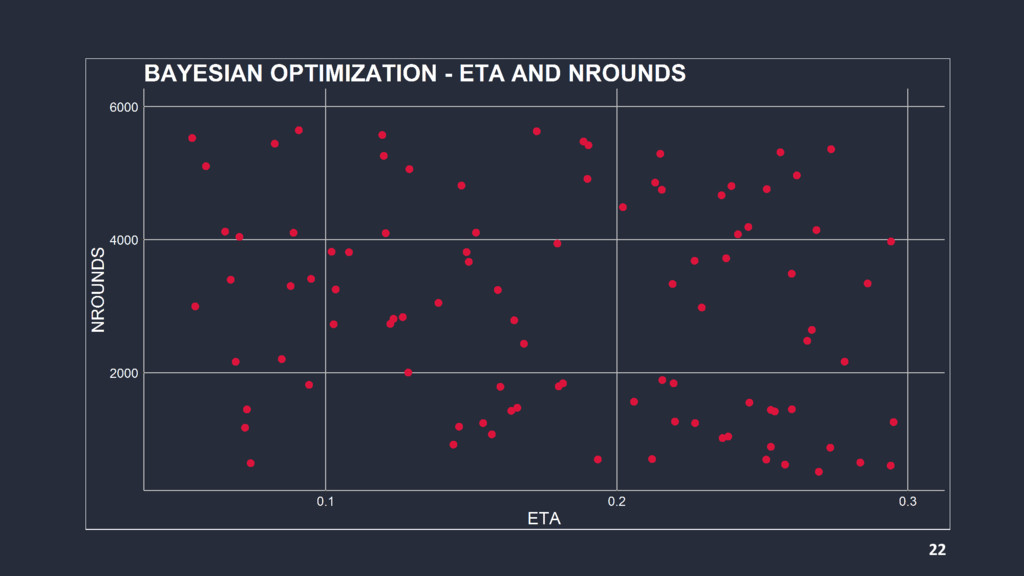{kind=link}
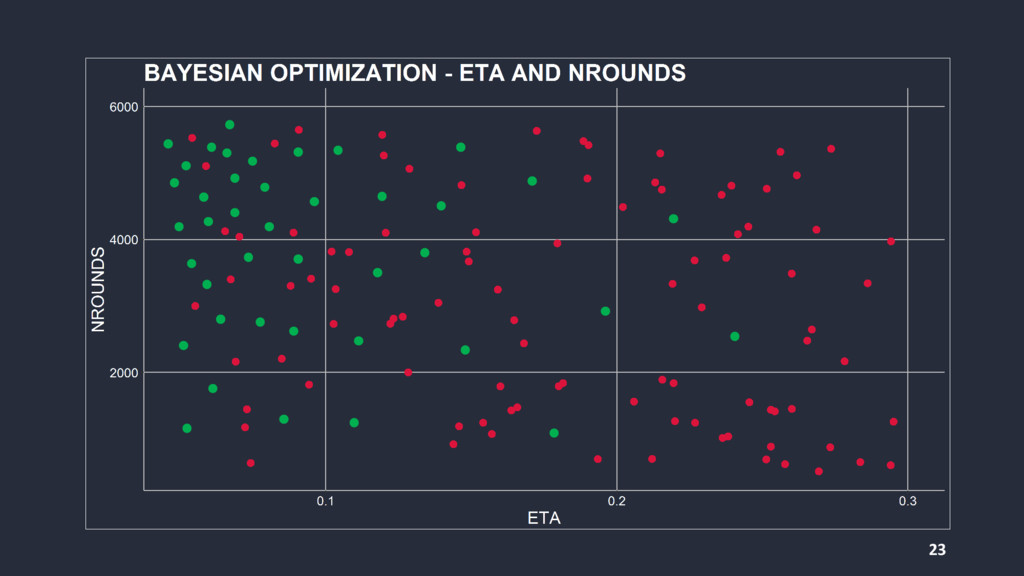{kind=link}
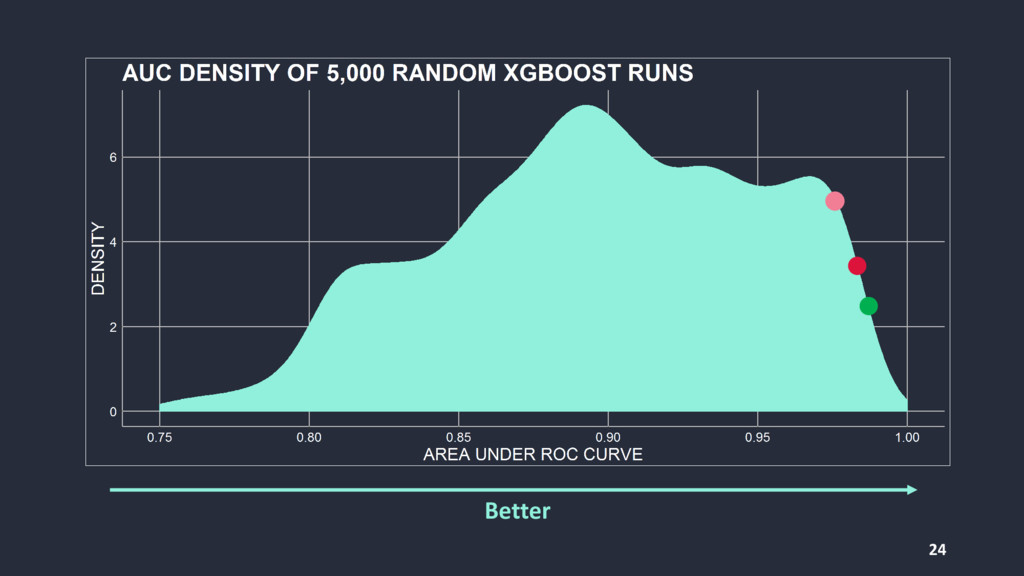{kind=link}
{kind=link}
{kind=link}
{kind=link}
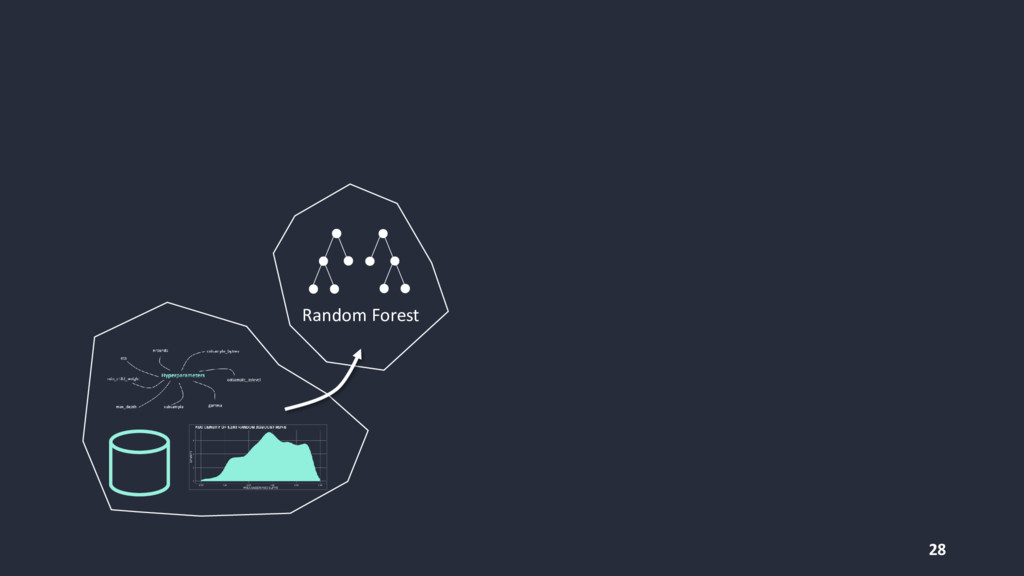{kind=link}
{kind=link}
{kind=link}
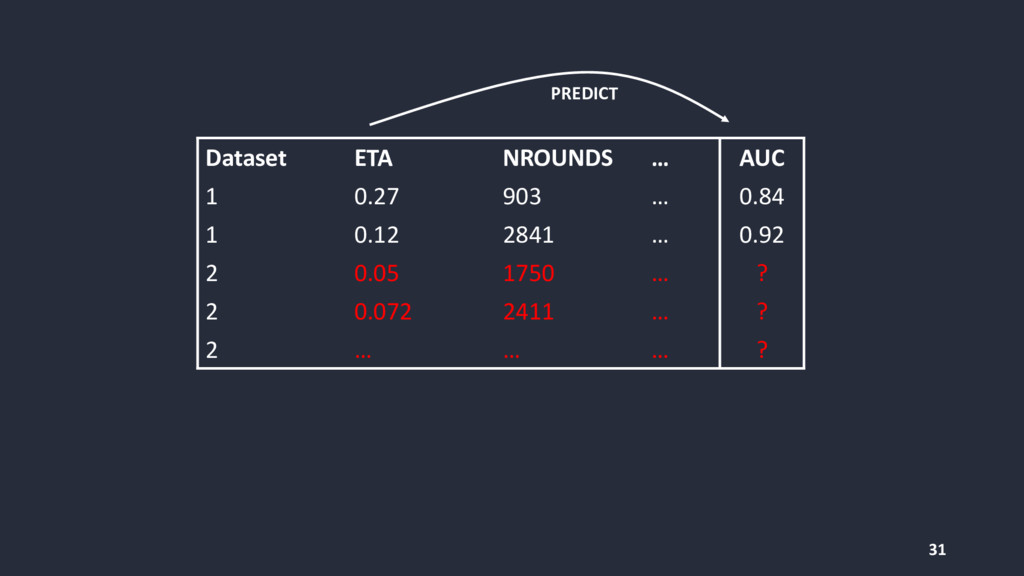{kind=link}
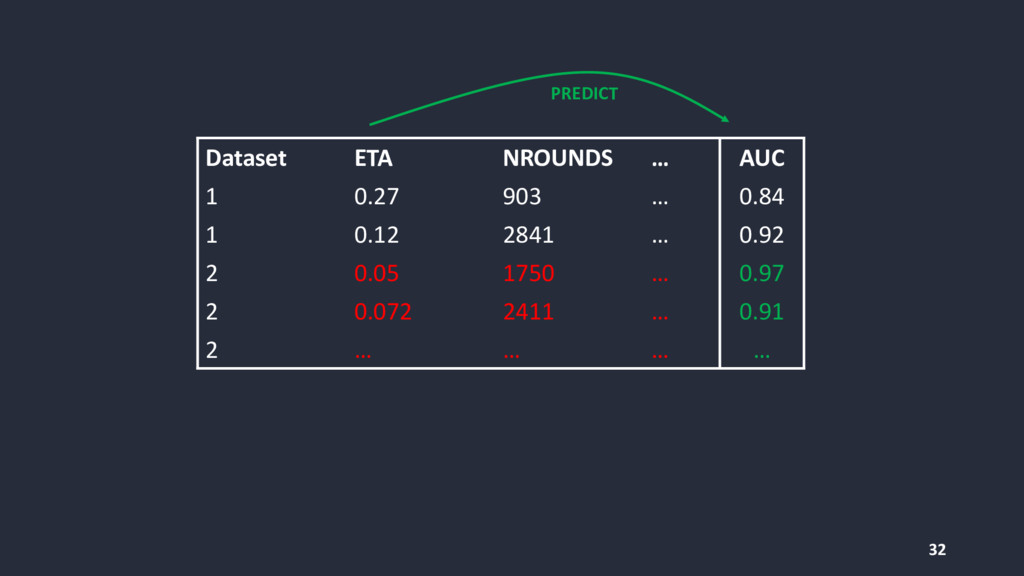{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}