team @ Prosieben • Data science Education @ France (NLP, image recognition,…) • Several hacks (kaggle, datamining a flat, robotax, whatsappcli,…) • Python enthusiast • Still trying to figure out Javascript and booting up Eclipse
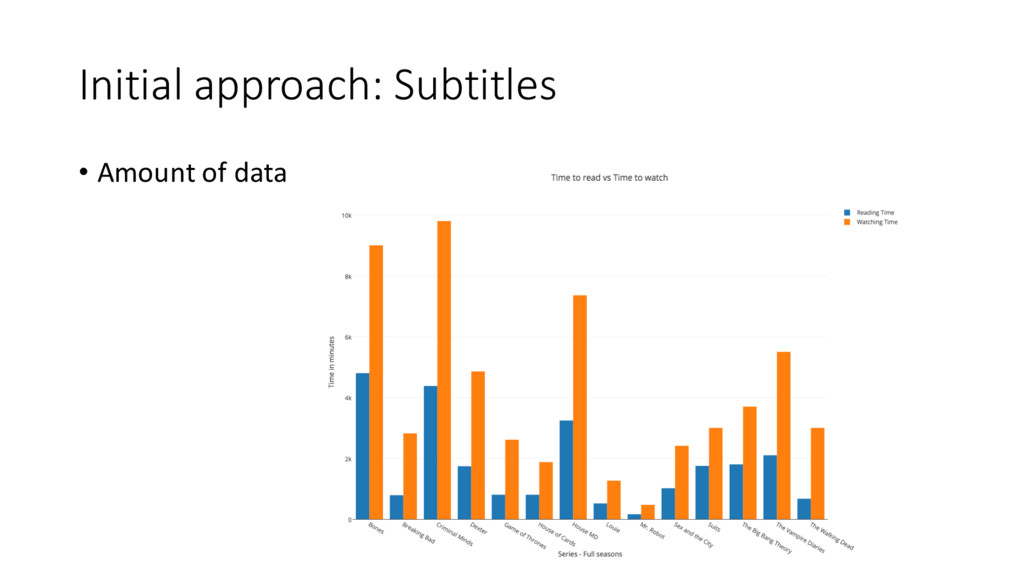
Talk frequency • Episode/Movie duration • Idle time • Number of words • Number of sentences • Most used words • Words length • Sentence length • Vocabulary richness • Time to read • SMOG grade • Topic modelling • Summary • Polarity • Word usage • Sentence beginnings
of representative terms of these input documents, forms a query using these terms, executes the query and returns the results. The user controls the input documents, how the terms should be selected and how the query is formed. more_like_this can be shortened to mlt.
to enhance our dataset • Size of the data does matter, but variety matters more • Trying out out of the box solutionis always rewarding and motivating • Stay tuned for part 3 on http://funnybretzel.comor @KarimJDDA Interested in analyzing uniquedata in an innovative environmentand working on super cool projects? • Big Data Engineer x1 • Data Scientist x1 [email protected]
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}