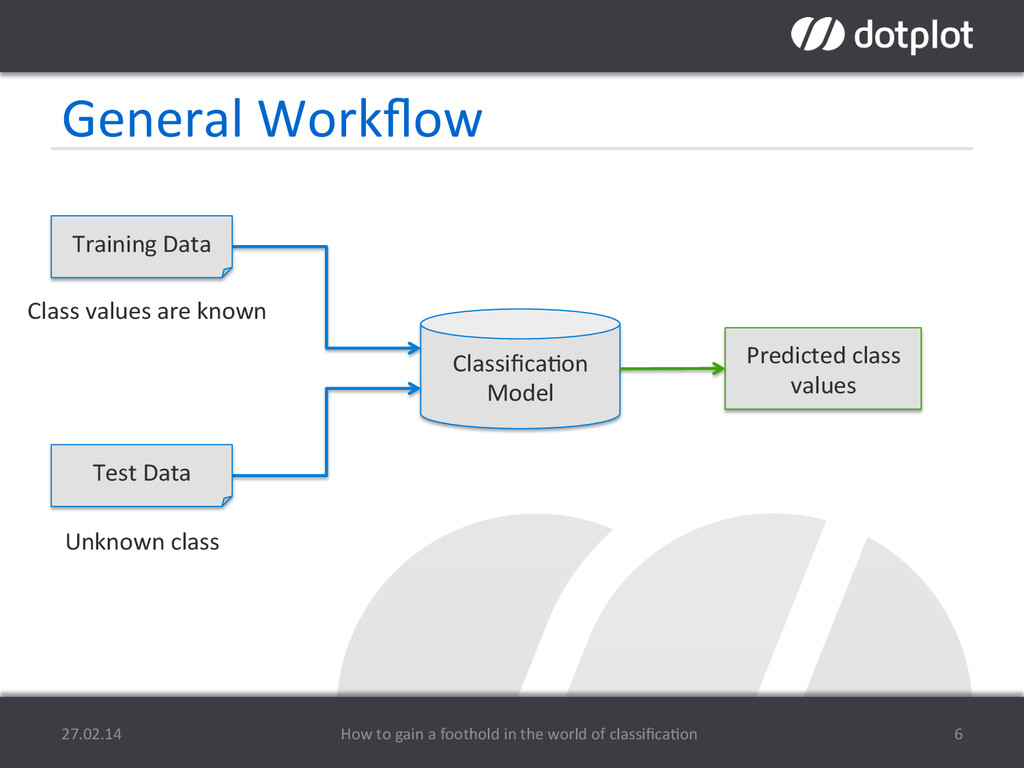
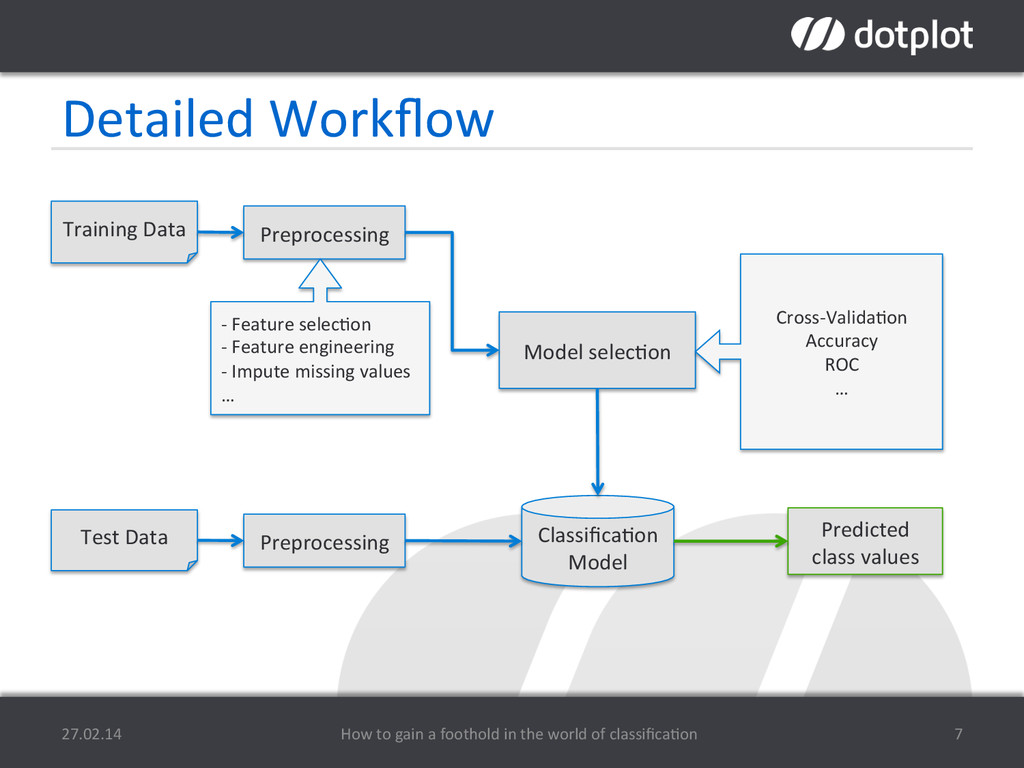
This talk is supposed to serve as a basic introduction to classification. I will explain some common classification algorithms and fundamentals in the field of classification. Before starting to learn a model, it is crucial to explore and understand the underlying data. Based on these findings, proper feature engineering and selection is to be performed in order to get appropriate results. After choosing a model and classifying data instances, we will see different methods of evaluating the results, using techniques like cross-validation. All of this will be demonstrated by analyzing a public data set within a free cloud based data analysis tool called dotplot designer.
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}