Upgrade to Pro
— share decks privately, control downloads, hide ads and more …
Speaker Deck
Features
Speaker Deck
PRO
Sign in
Sign up for free
Search
Search
長時間動画QAにおけるマルチエージェント推論 ・SVAgent: Storyline-Guid...
Search
Sponsored
·
Your Podcast. Everywhere. Effortlessly.
Share. Educate. Inspire. Entertain. You do you. We'll handle the rest.
→
村川卓也
June 20, 2026
Research
170
1
Share
Embed
Copy iframe code
Copy JS code
Copy link
Start on current slide
長時間動画QAにおけるマルチエージェント推論 ・SVAgent: Storyline-Guided Long Video Understanding via Cross-Modal Multi-Agent Collaboration
第64回 名古屋CV・PRML勉強会
https://nagoyacv.connpass.com/event/394324/
村川卓也
June 20, 2026
More Decks by 村川卓也
See All by 村川卓也
CVPR2025論文紹介:「Unboxed: Geometrically and Temporally Consistent Video Outpainting」
murakawatakuya
0
1.1k
Other Decks in Research
See All in Research
計算情報学研究室 (数理情報学第7研究室)2026
tomohirokoana
0
680
Cross-Media Information Spaces and Architectures
signer
PRO
0
320
LINEヤフー データサイエンス Meetup「三井物産コモディティ予測チャレンジ」の舞台裏-AlpacaTechパート
gamella
1
620
260624_NLP-colloquium: Hubness
de9uch1
1
150
羽田新ルート運用6年の検証
1manken
0
180
Sequences of Logits Reveal the Low Rank Structure of Language Models
sansantech
PRO
1
300
MM-OVSeg: Multimodal Optical–SAR Fusion for Open-Vocabulary Segmentation in Remote Sensing
satai
3
100
言語モデルから言語について語る際に押さえておきたいこと
eumesy
PRO
6
2.5k
Ghost in the 7‑Zip: The Shadow of Residential Proxies Creeping into Your Life
nttcom
0
1.7k
2026年度 生成AI を活用した論文執筆ガイド/ワークショップ / 2026 Academic Year Guide to Writing Papers Using Generative AI - Workshop
ks91
PRO
0
200
[Fishers] DIVER OSINT CTF 2026 特化AIエージェントハーネスで挑戦するOSINT CTF
analokmaus
0
410
[BlackHatAsia2026] Hidden Telemetry: Uncovering TraceLogging ETW Providers You're Not Using (Yet)
asuna_jp
1
610
Featured
See All Featured
End of SEO as We Know It (SMX Advanced Version)
ipullrank
3
4.3k
Understanding Cognitive Biases in Performance Measurement
bluesmoon
32
3k
Stop Working from a Prison Cell
hatefulcrawdad
274
21k
Templates, Plugins, & Blocks: Oh My! Creating the theme that thinks of everything
marktimemedia
31
2.8k
The browser strikes back
jonoalderson
0
1.4k
The Anti-SEO Checklist Checklist. Pubcon Cyber Week
ryanjones
0
190
From Legacy to Launchpad: Building Startup-Ready Communities
dugsong
0
280
Bioeconomy Workshop: Dr. Julius Ecuru, Opportunities for a Bioeconomy in West Africa
akademiya2063
PRO
1
190
HDC tutorial
michielstock
2
760
SEO for Brand Visibility & Recognition
aleyda
0
4.6k
Leo the Paperboy
mayatellez
8
2k
More Than Pixels: Becoming A User Experience Designer
marktimemedia
3
470
Transcript
SVAgent: Storyline-guided Long Video Understanding via Cross- Modal Multi-Agent Collaboration
Zhongyu Yang, Zuhao Yang, Shuo Zhan, Tan Yue, Wei Pang, Yingfang Yuan, CVPR2026 大島慈温(名工大玉木・丁研) 2026/06/20 第64回 名古屋CV・PRML勉強会(CVPR2026 論文紹介)
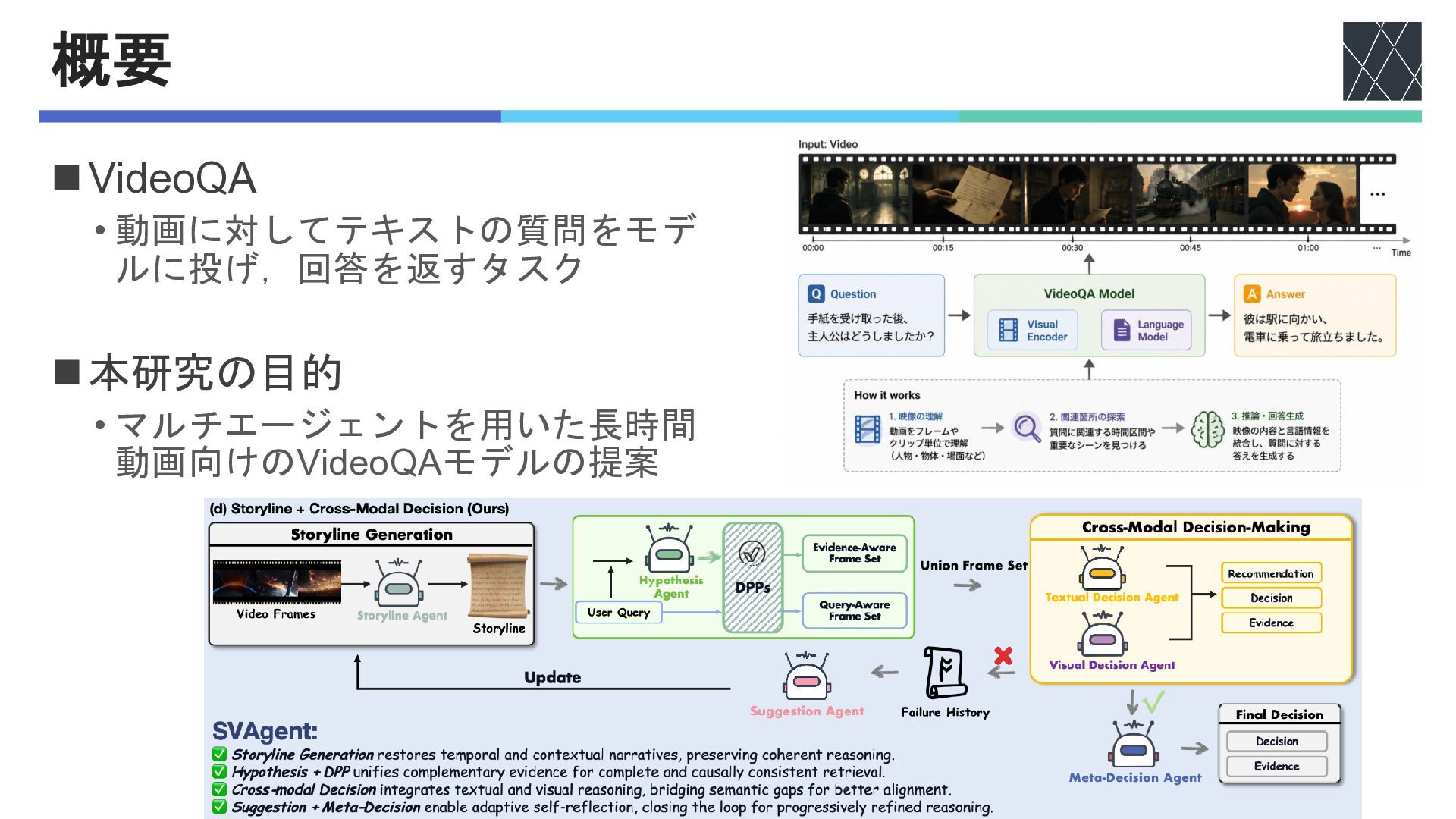
概要 ◼VideoQA • 動画に対してテキストの質問をモデ ルに投げ,回答を返すタスク ◼本研究の目的 • マルチエージェントを用いた長時間 動画向けのVideoQAモデルの提案
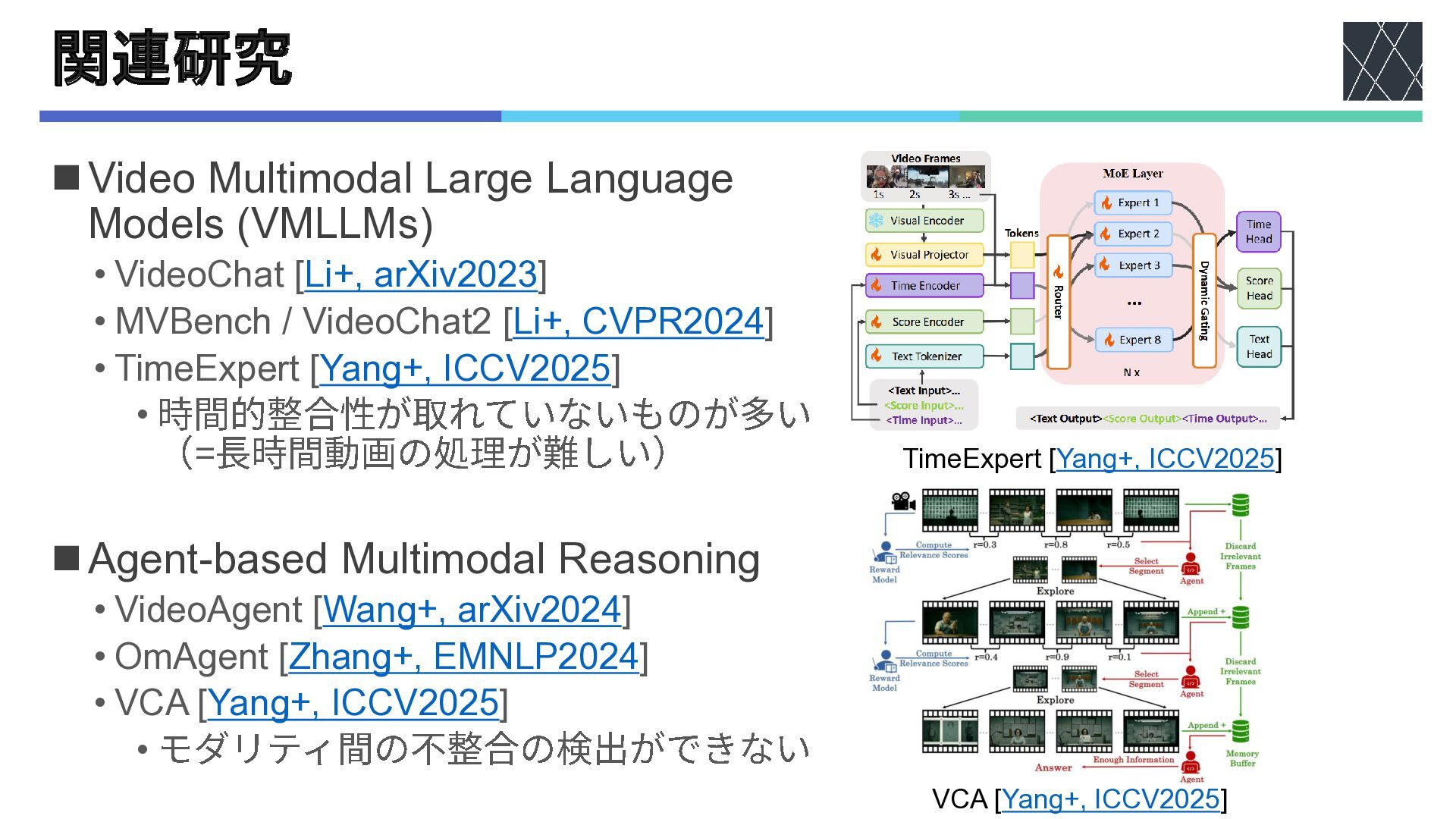
関連研究 ◼Video Multimodal Large Language Models (VMLLMs) • VideoChat [Li+,
arXiv2023] • MVBench / VideoChat2 [Li+, CVPR2024] • TimeExpert [Yang+, ICCV2025] • 時間的整合性が取れていないものが多い (=長時間動画の処理が難しい) ◼Agent-based Multimodal Reasoning • VideoAgent [Wang+, arXiv2024] • OmAgent [Zhang+, EMNLP2024] • VCA [Yang+, ICCV2025] • モダリティ間の不整合の検出ができない TimeExpert [Yang+, ICCV2025] VCA [Yang+, ICCV2025]
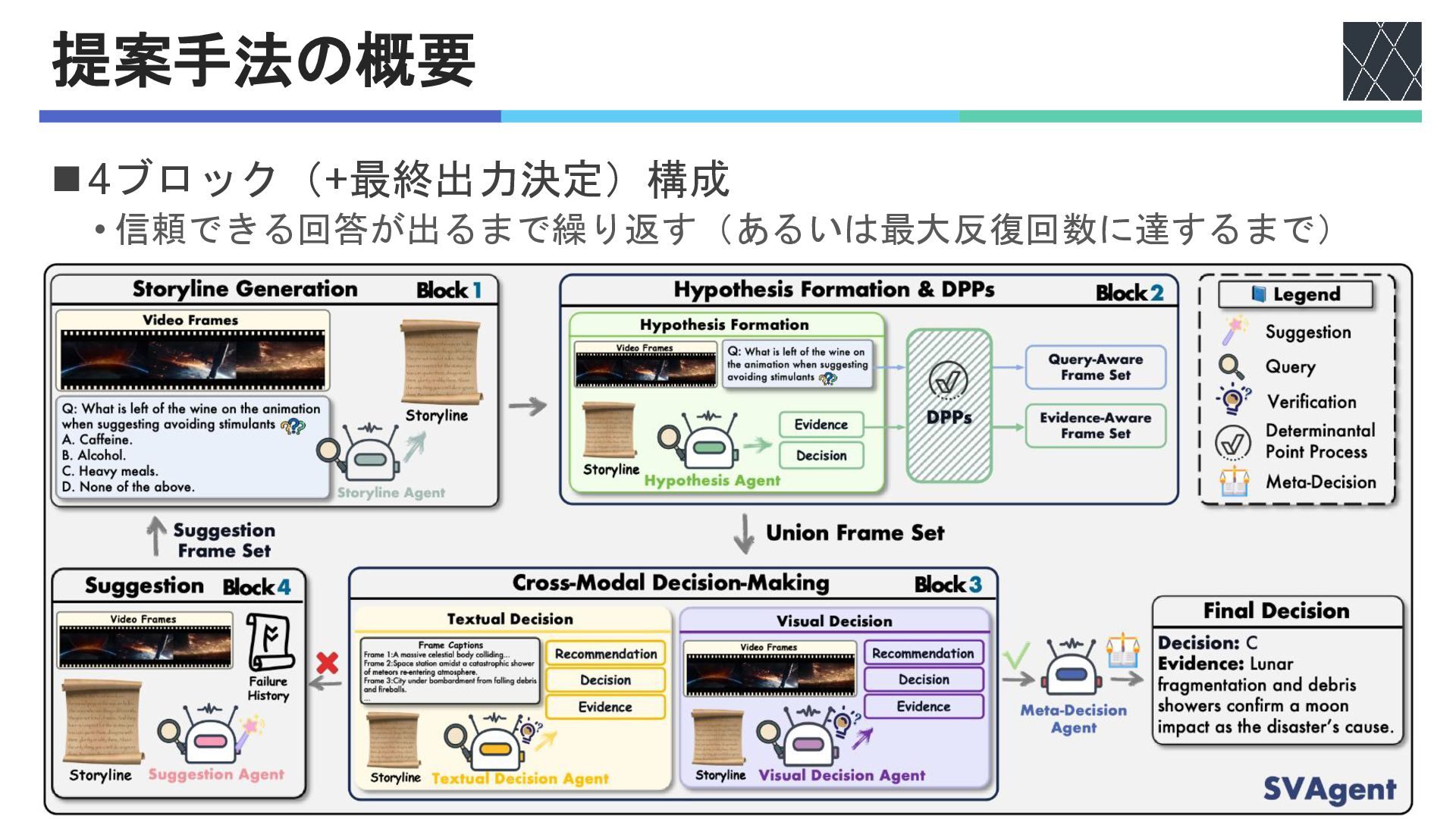
提案手法の概要 ◼4ブロック(+最終出力決定)構成 • 信頼できる回答が出るまで繰り返す(あるいは最大反復回数に達するまで)
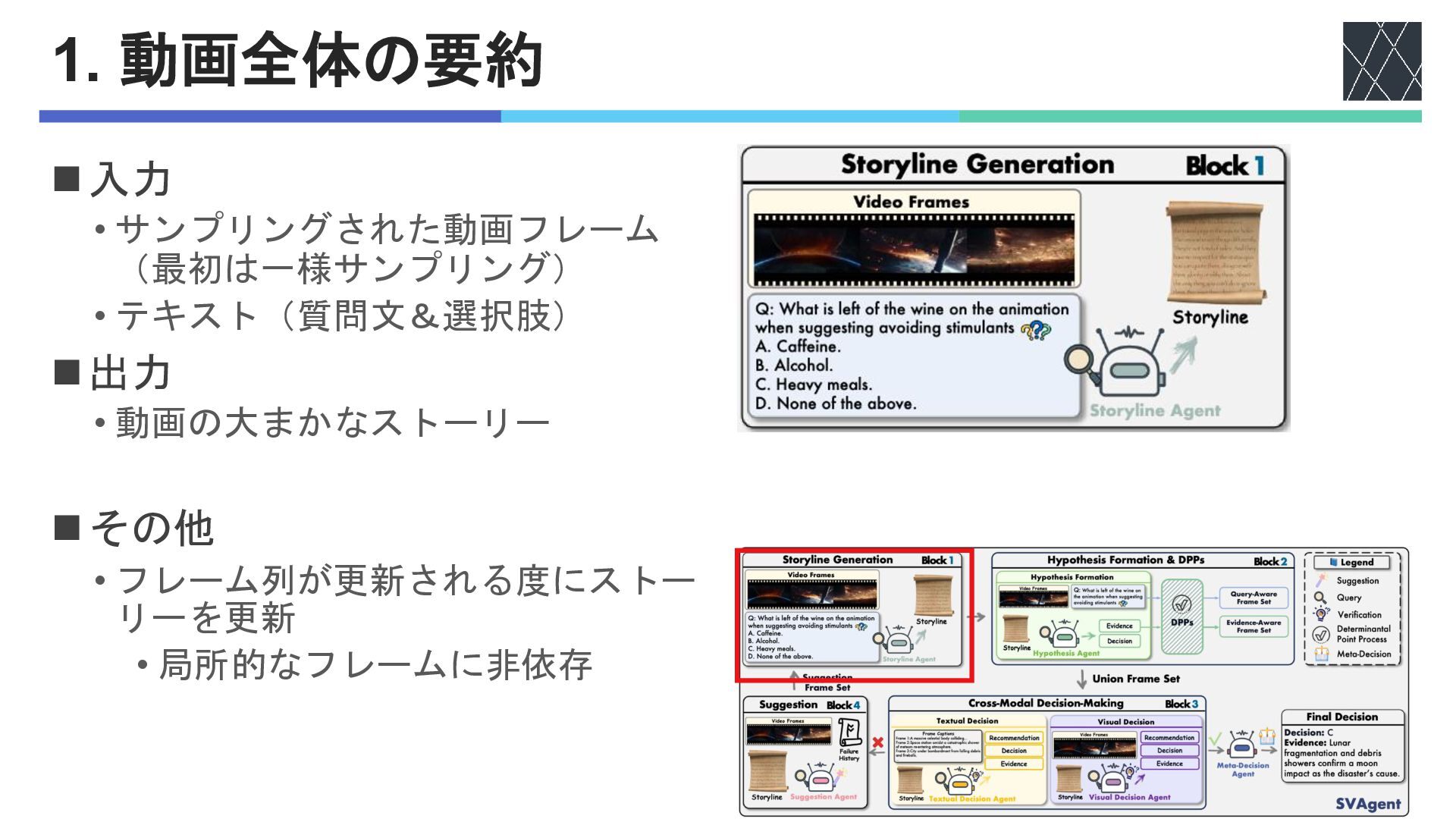
1. 動画全体の要約 ◼入力 • サンプリングされた動画フレーム (最初は一様サンプリング) • テキスト(質問文&選択肢) ◼出力 •
動画の大まかなストーリー ◼その他 • フレーム列が更新される度にストー リーを更新 • 局所的なフレームに非依存
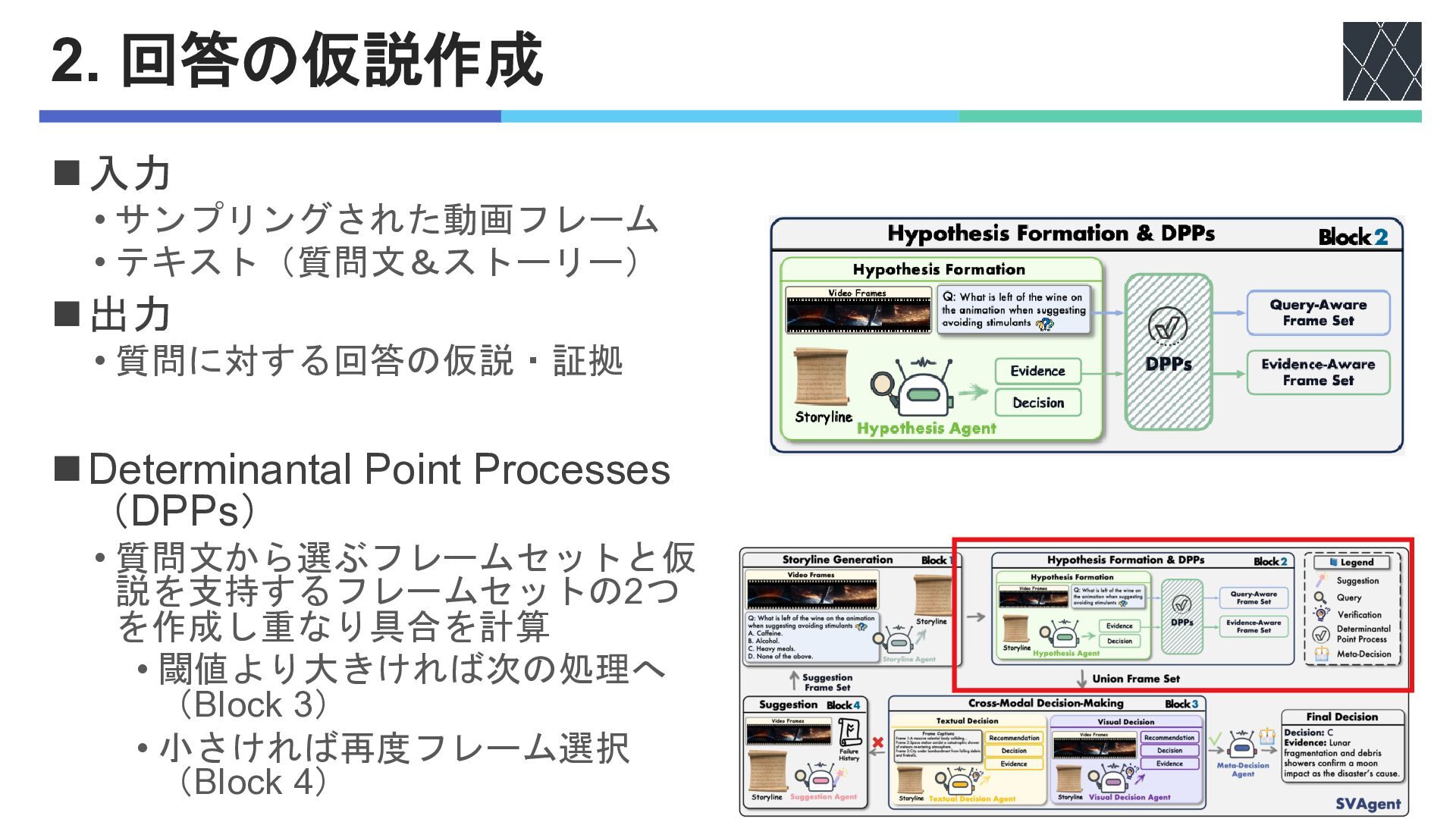
2. 回答の仮説作成 ◼入力 • サンプリングされた動画フレーム • テキスト(質問文&ストーリー) ◼出力 • 質問に対する回答の仮説・証拠
◼Determinantal Point Processes (DPPs) • 質問文から選ぶフレームセットと仮 説を支持するフレームセットの2つ を作成し重なり具合を計算 • 閾値より大きければ次の処理へ (Block 3) • 小さければ再度フレーム選択 (Block 4)
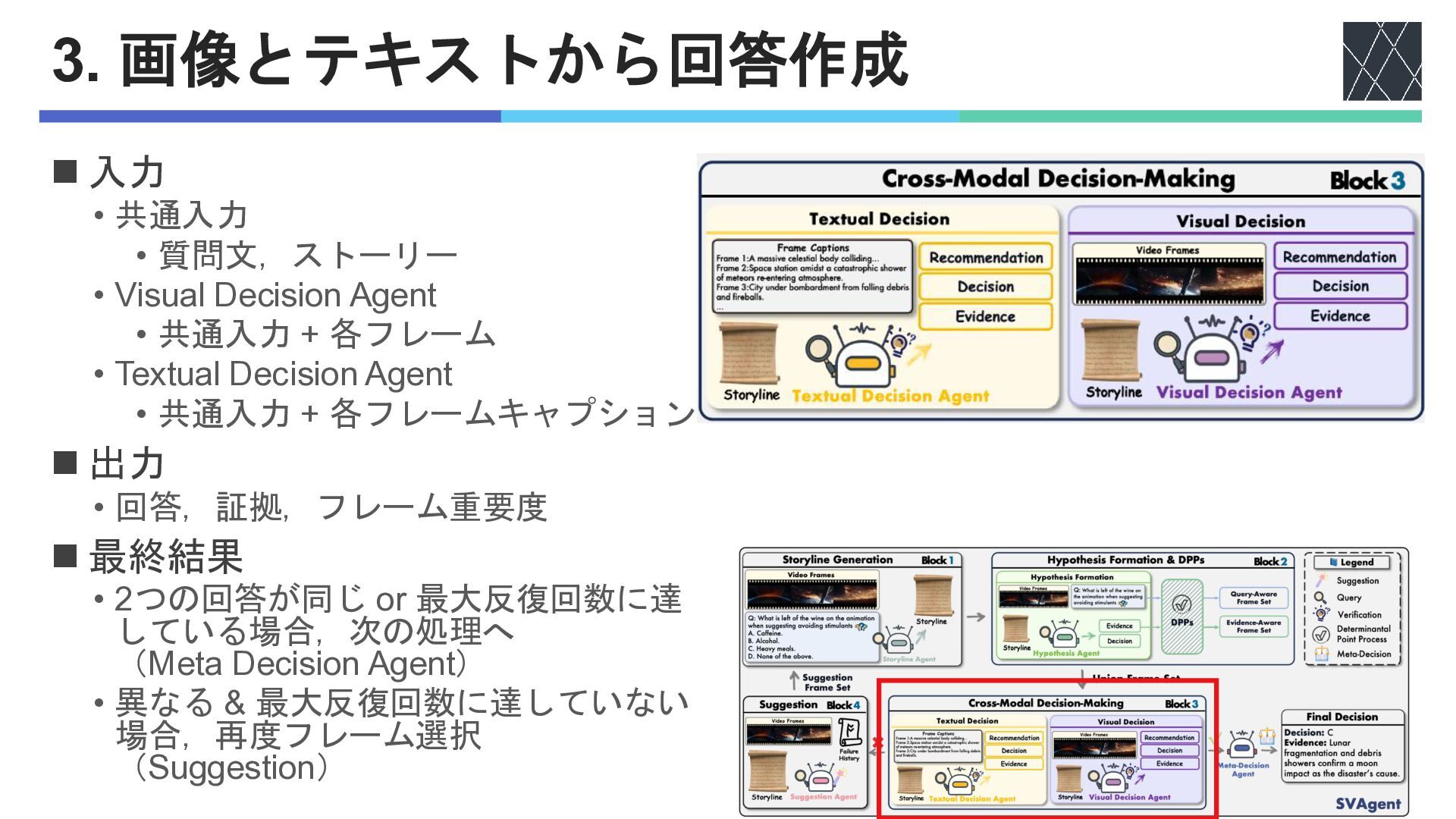
◼ 入力 • 共通入力 • 質問文,ストーリー • Visual Decision Agent
• 共通入力 + 各フレーム • Textual Decision Agent • 共通入力 + 各フレームキャプション ◼ 出力 • 回答,証拠,フレーム重要度 ◼ 最終結果 • 2つの回答が同じ or 最大反復回数に達 している場合,次の処理へ (Meta Decision Agent) • 異なる & 最大反復回数に達していない 場合,再度フレーム選択 (Suggestion) 3. 画像とテキストから回答作成
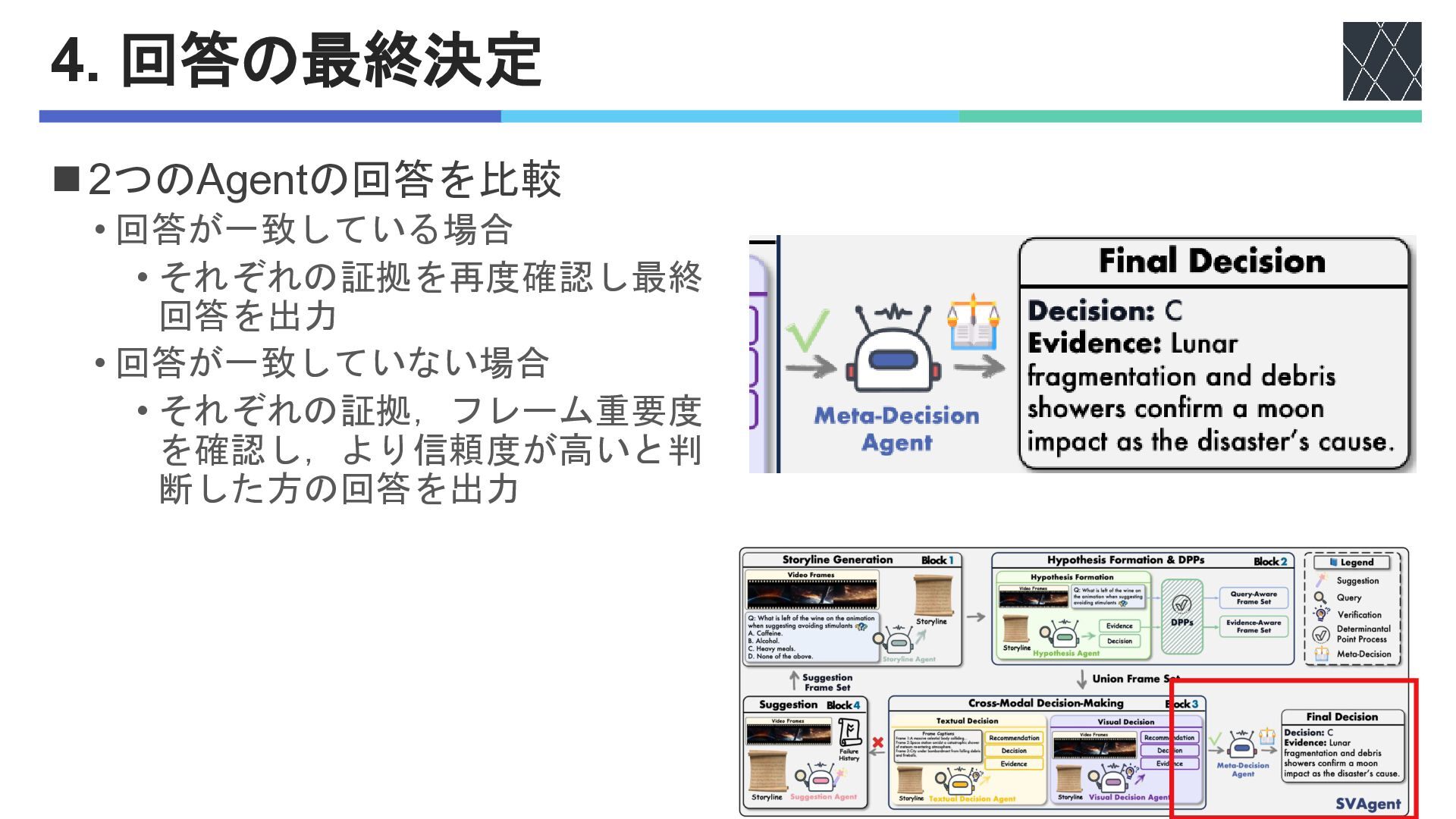
4. 回答の最終決定 ◼2つのAgentの回答を比較 • 回答が一致している場合 • それぞれの証拠を再度確認し最終 回答を出力 • 回答が一致していない場合
• それぞれの証拠,フレーム重要度 を確認し,より信頼度が高いと判 断した方の回答を出力
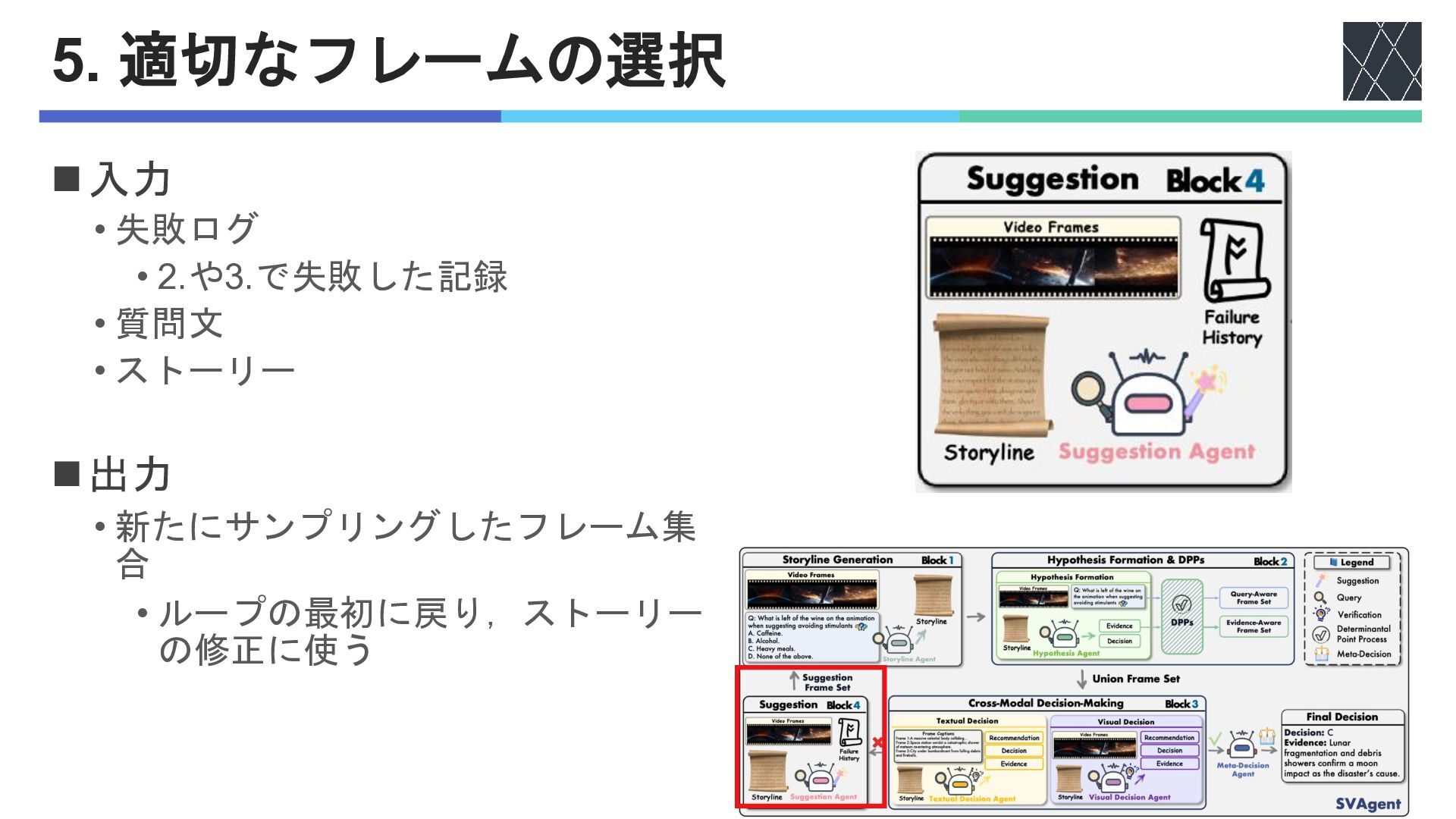
5. 適切なフレームの選択 ◼入力 • 失敗ログ • 2.や3.で失敗した記録 • 質問文 •
ストーリー ◼出力 • 新たにサンプリングしたフレーム集 合 • ループの最初に戻り,ストーリー の修正に使う
実験条件(ベースライン) ◼Backbone Models • Qwen2.5-VL [Bai+, arXiv2025] • Qwen3-VL [Qwen
Team, Technical Report2025] ◼Video MLLMs • Gemini 1.5 Pro [Gemini Team+, arXiv2024] • GPT-4o [OpenAI, System Card2024] • LLaVA-Video [Zhang+, TMLR2025] • Qwen2.5-VL [Bai+, arXiv2025] • InternVL 2.5 [Chen+, arXiv2024] ◼Open-source Video Agents / Long-video Reasoning Baselines • VideoMind [Liu+, arXiv2025] • Vgent [Shen+, NeurIPS2025] • Video-RAG [Luo+, arXiv2024] • VideoAgent [Wang+, arXiv2024] Qwen3-VL [Qwen Team, Technical Report2025]
実験条件(データセット&実装) ◼データセット • LongVideoBench [Wu+, NeurIPS2024] • MLVU [Zhou+, arXiv2024]
• LVBench [Wang+, ICCV2025] • Video-MME [Fu+, CVPR2025] ◼実装 • 初期サンプリングFPS:1.0 • フレーム集合間の重なり具合の 閾値:0.3 • 最大反復回数:3 Video-MME [Fu+, CVPR2025]
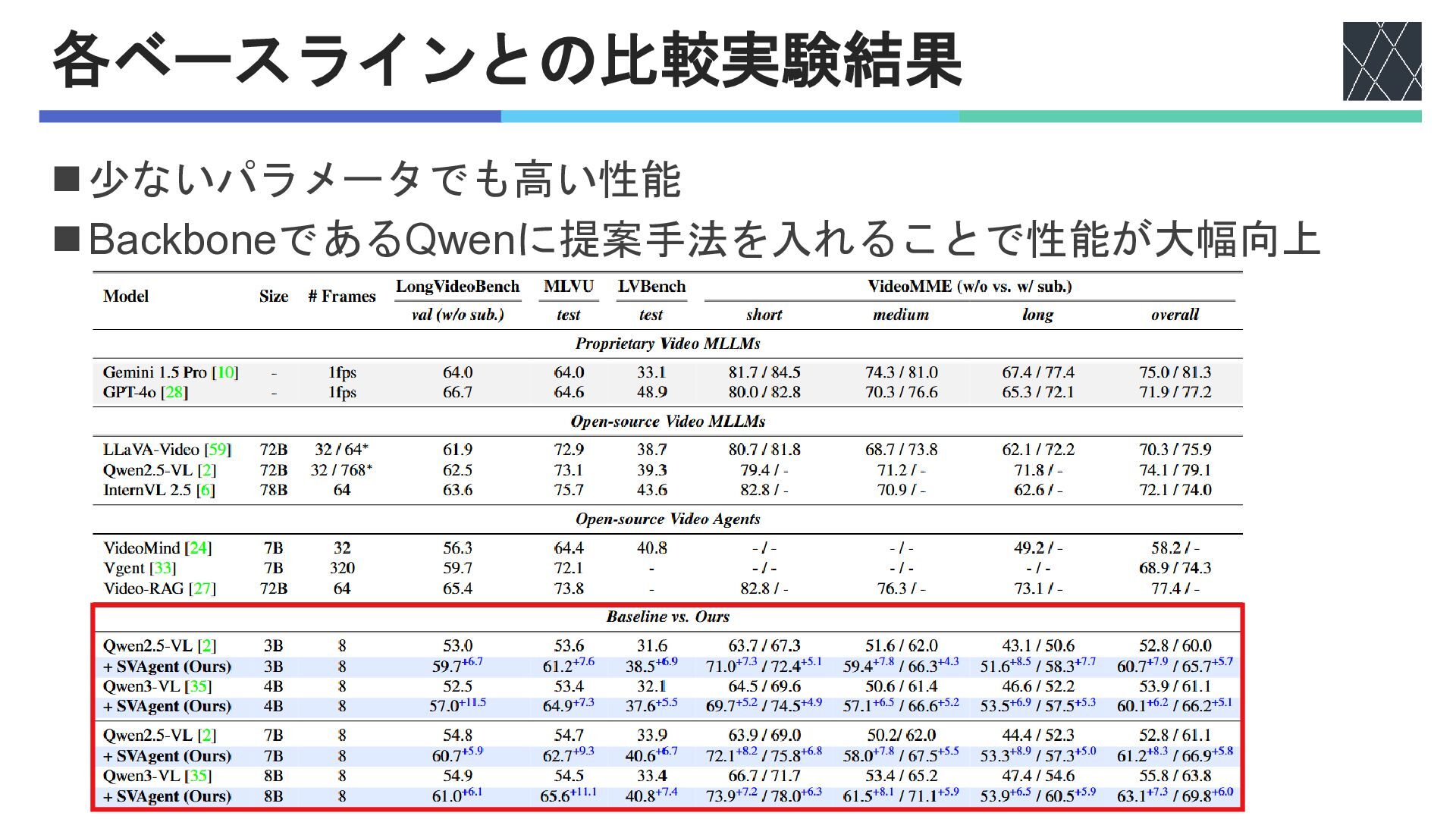
各ベースラインとの比較実験結果 ◼少ないパラメータでも高い性能 ◼BackboneであるQwenに提案手法を入れることで性能が大幅向上
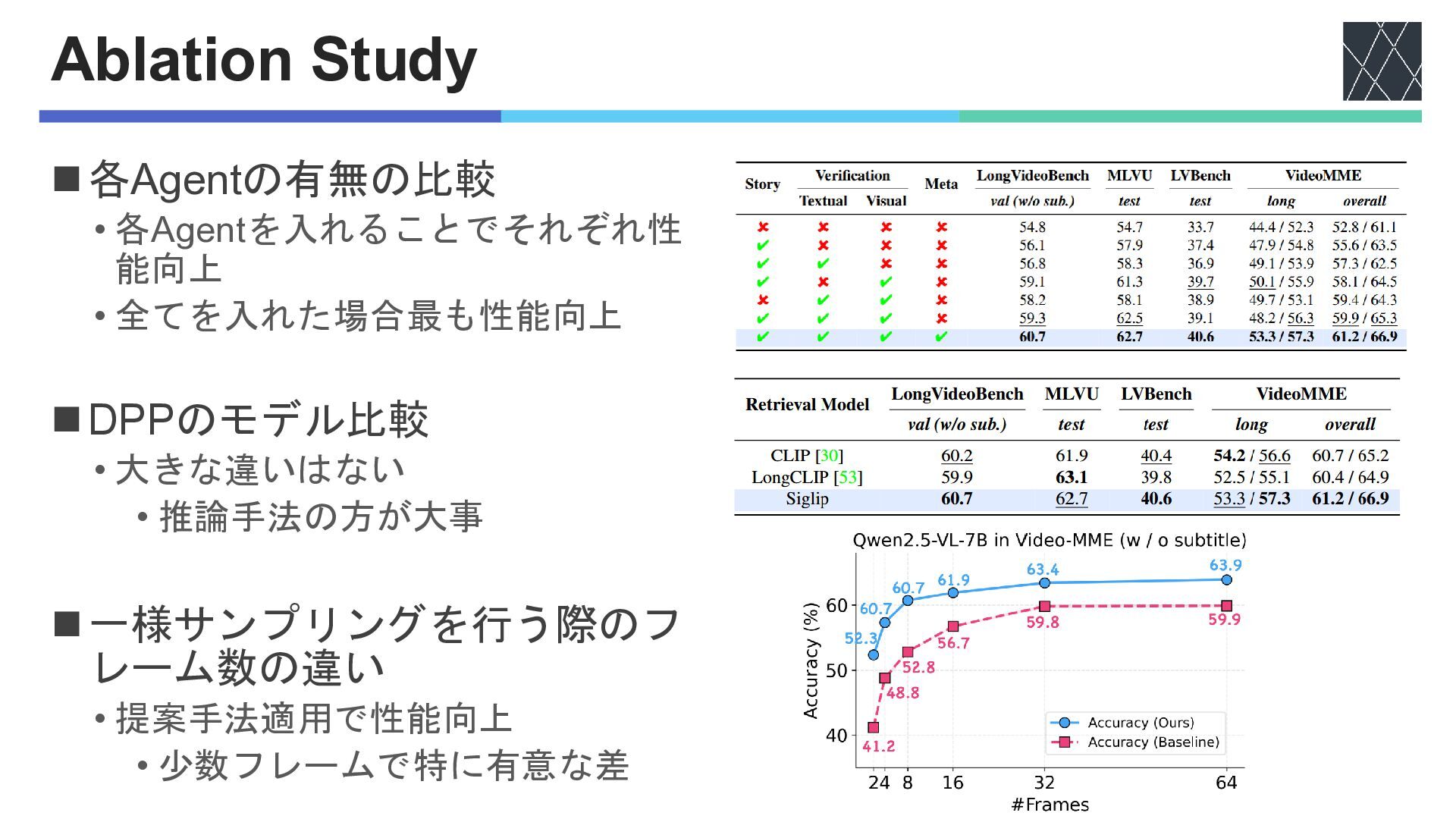
Ablation Study ◼各Agentの有無の比較 • 各Agentを入れることでそれぞれ性 能向上 • 全てを入れた場合最も性能向上 ◼DPPのモデル比較 •
大きな違いはない • 推論手法の方が大事 ◼一様サンプリングを行う際のフ レーム数の違い • 提案手法適用で性能向上 • 少数フレームで特に有意な差
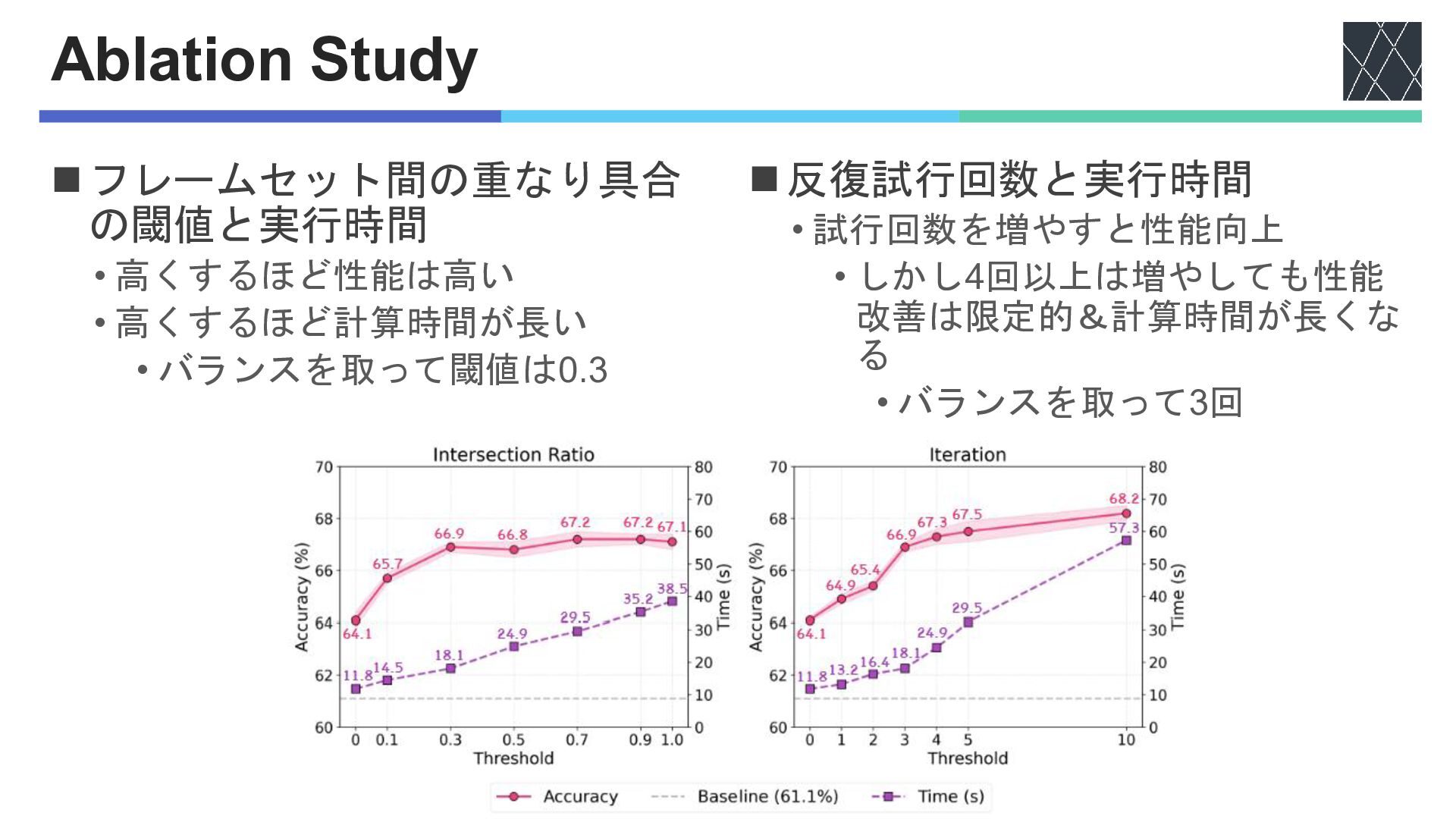
Ablation Study ◼フレームセット間の重なり具合 の閾値と実行時間 • 高くするほど性能は高い • 高くするほど計算時間が長い • バランスを取って閾値は0.3
◼反復試行回数と実行時間 • 試行回数を増やすと性能向上 • しかし4回以上は増やしても性能 改善は限定的&計算時間が長くな る • バランスを取って3回
定性的結果 ◼結果
まとめ ◼長時間動画用のVideoQAモデルの提案 • マルチモーダルエージェントの活用 ◼Textual DecisionとVisual Decisionの両面から判断 • モダリティ間での整合性を取る ◼長時間動画用のベンチマークでの実証
• 少ないパラメータのVMLLMでも高い性能を発揮
補足
アルゴリズム
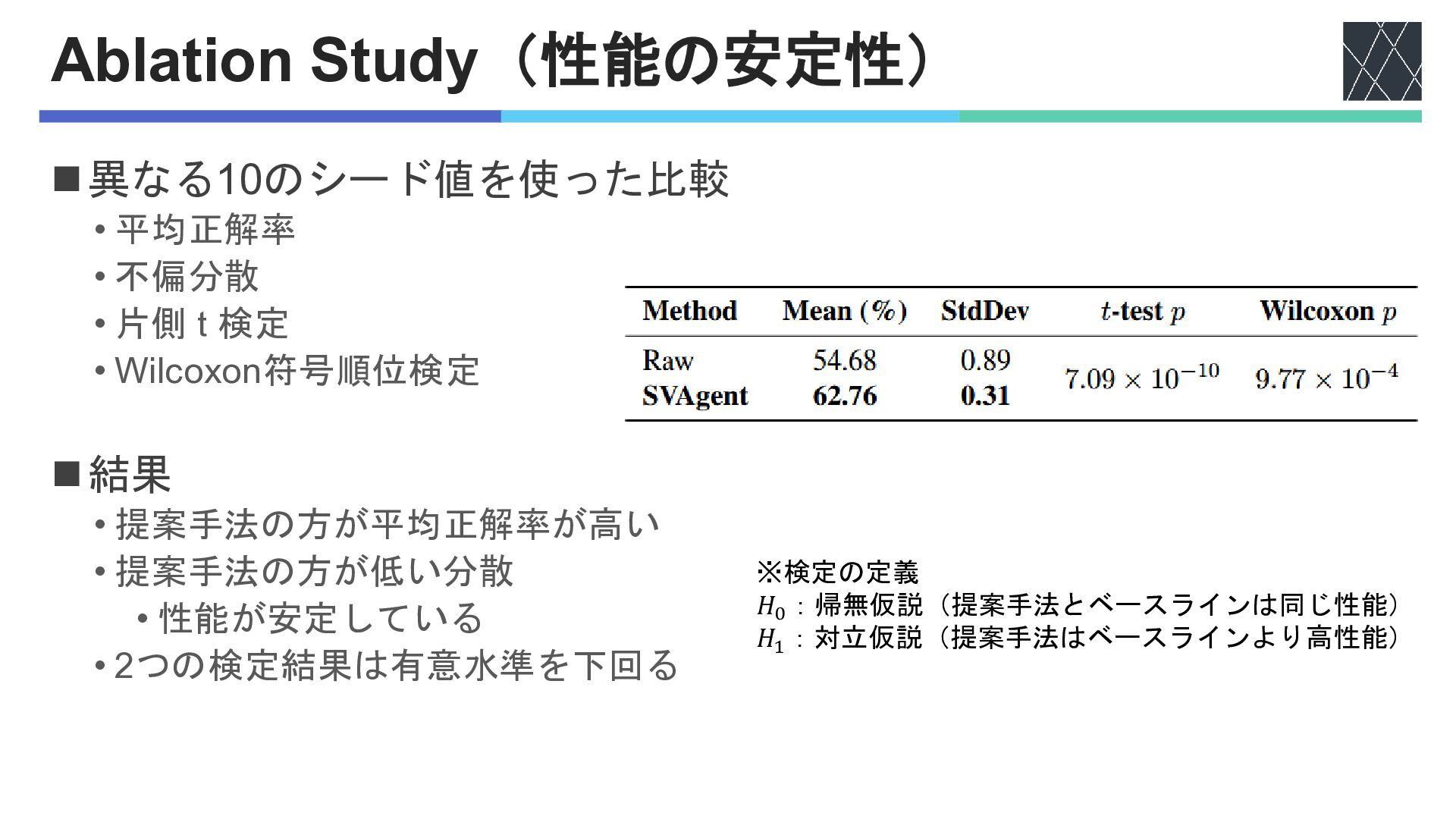
Ablation Study(性能の安定性) ◼異なる10のシード値を使った比較 • 平均正解率 • 不偏分散 • 片側 t
検定 • Wilcoxon符号順位検定 ◼結果 • 提案手法の方が平均正解率が高い • 提案手法の方が低い分散 • 性能が安定している • 2つの検定結果は有意水準を下回る ※検定の定義 𝐻0 :帰無仮説(提案手法とベースラインは同じ性能) 𝐻1 :対立仮説(提案手法はベースラインより高性能)
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
![実験条件(ベースライン) ◼Backbone Models • Qwen2.5-VL [Bai+, arXiv2025] • Qwen3-VL [Qwen](https://files.speakerdeck.com/presentations/345f550637364bc589caf97604b8dde0/slide_9.jpg){kind=link}
![実験条件(データセット&実装) ◼データセット • LongVideoBench [Wu+, NeurIPS2024] • MLVU [Zhou+, arXiv2024]](https://files.speakerdeck.com/presentations/345f550637364bc589caf97604b8dde0/slide_10.jpg){kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}