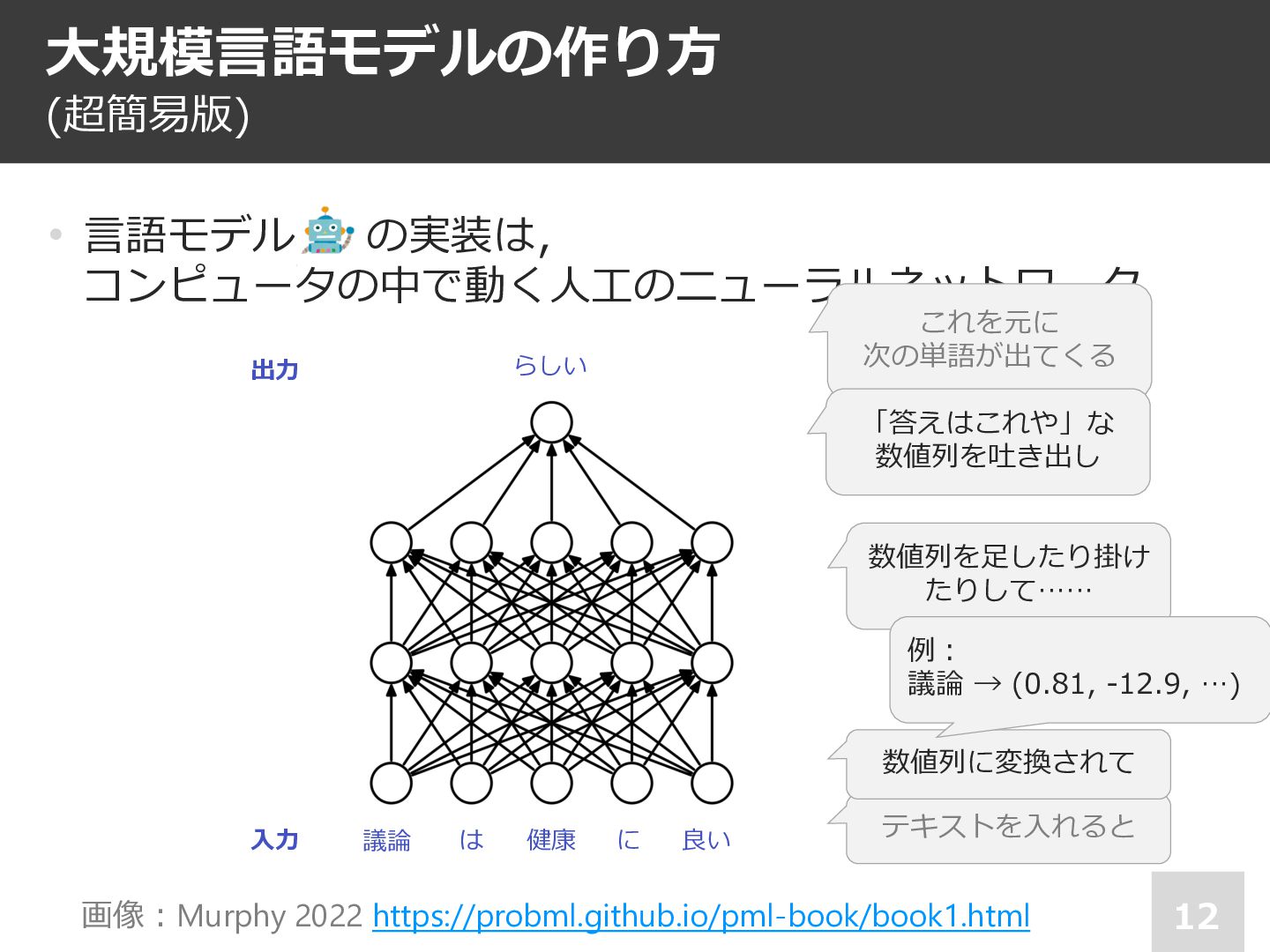
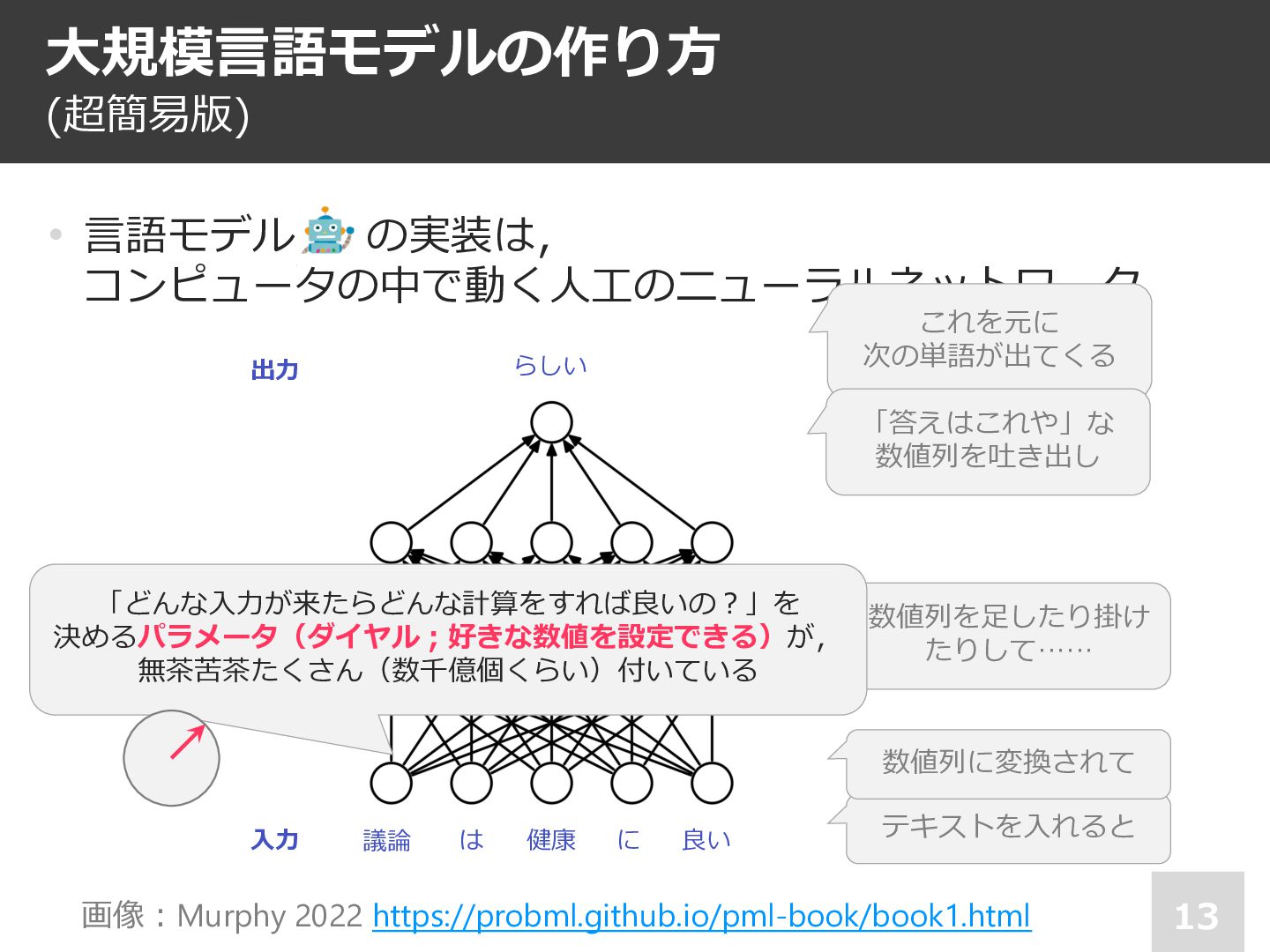
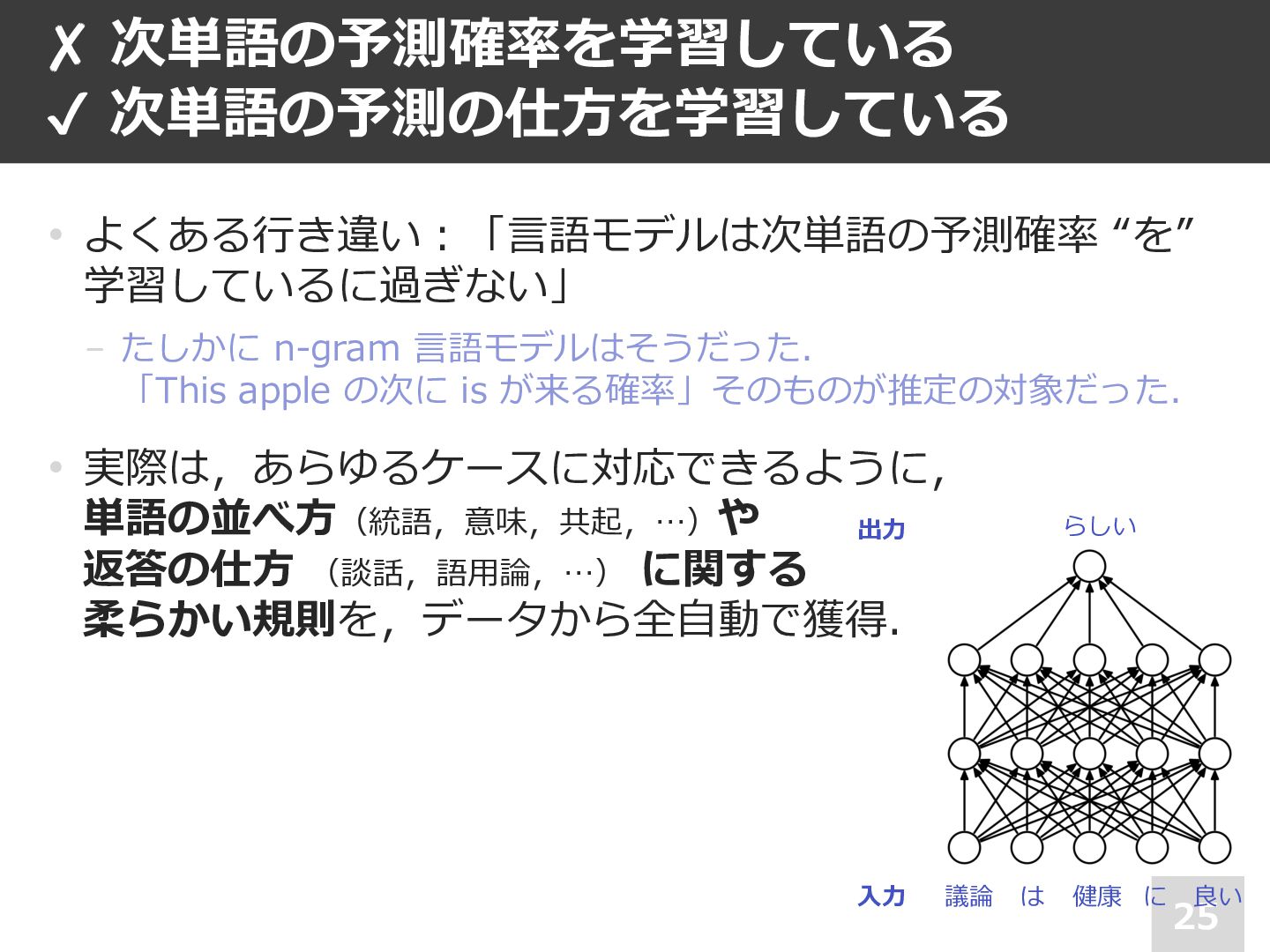
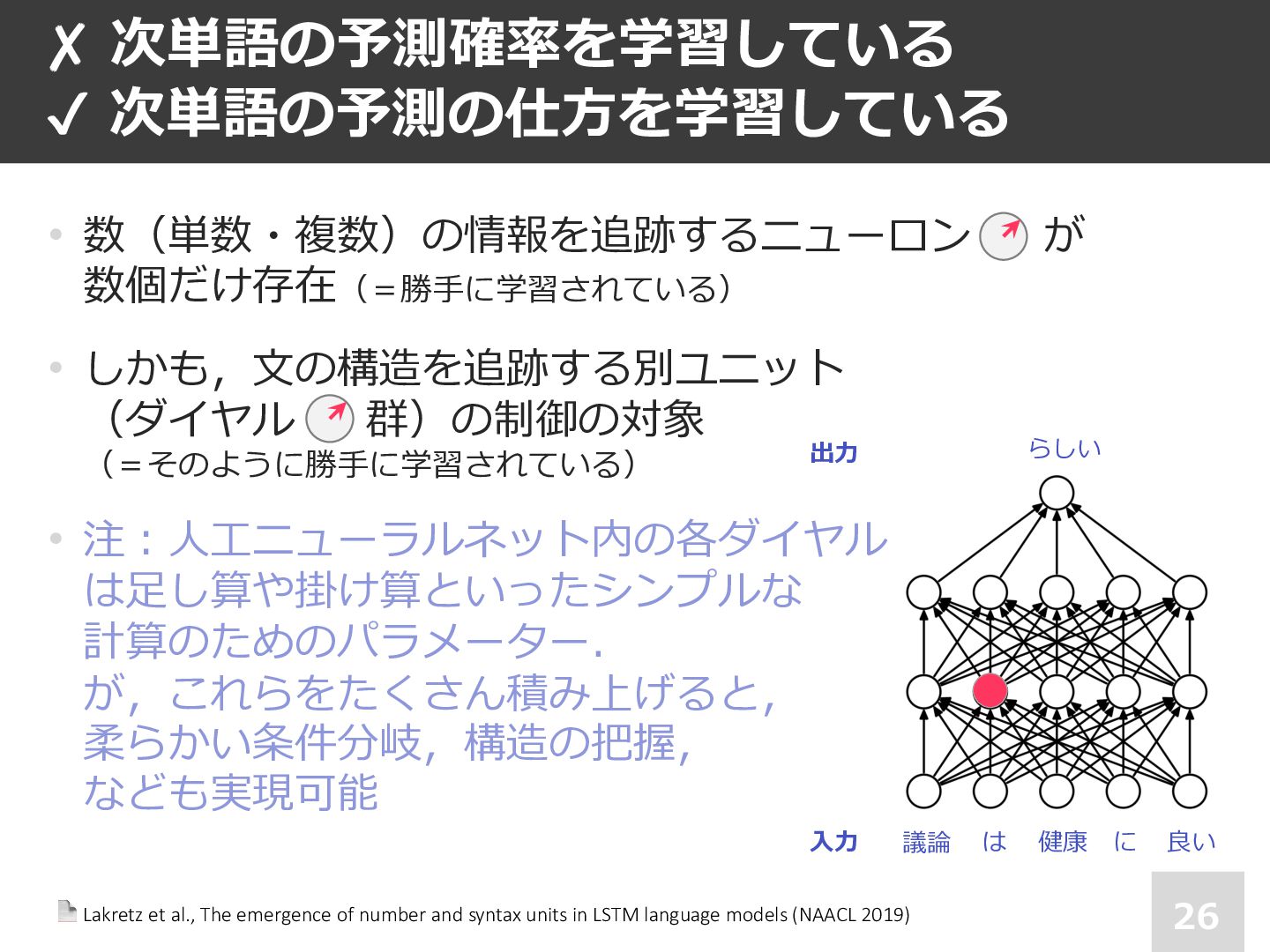
• 注︓⼈⼯ニューラルネット内の各ダイヤル は⾜し算や掛け算といったシンプルな 計算のためのパラメーター. が,これらをたくさん積み上げると, 柔らかい条件分岐,構造の把握, なども実現可能 ✘ 次単語の予測確率を学習している ✔ 次単語の予測の仕⽅を学習している 議論 は 健康 に らしい 良い ⼊⼒ 出⼒ 📄 Lakretz et al., The emergence of number and syntax units in LSTM language models (NAACL 2019)
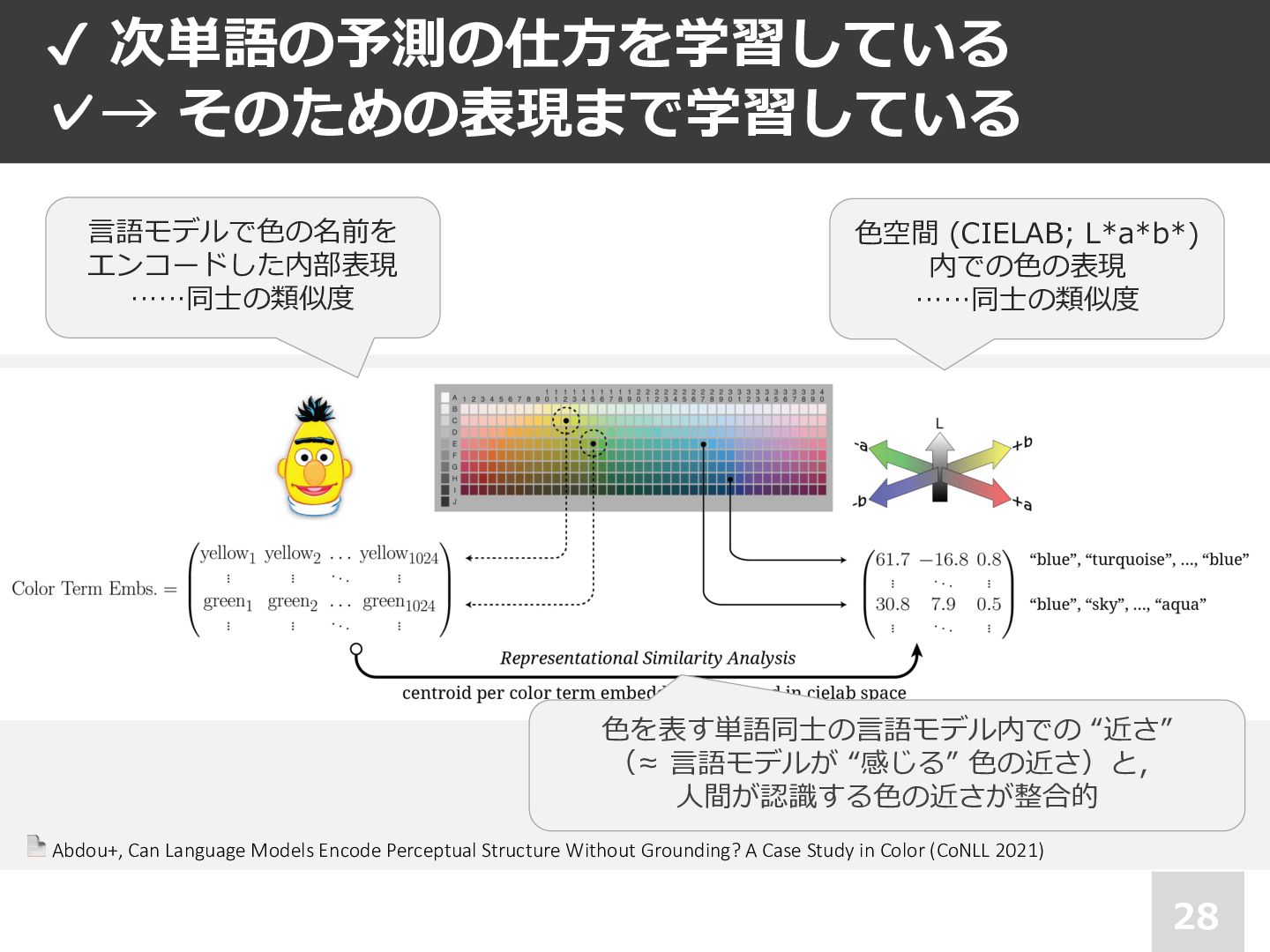
Abdou+, Can Language Models Encode Perceptual Structure Without Grounding? A Case Study in Color (CoNLL 2021) ✔ 次単語の予測の仕⽅を学習している ✓→ そのための表現まで学習している ⾊を表す単語同⼠の⾔語モデル内での “近さ” (≈ ⾔語モデルが “感じる” ⾊の近さ)と, ⼈間が認識する⾊の近さが整合的
− ✘ 簡易で⼀貫したアルゴリズムに基づいているわけではない – 筆算,全加算器︔少数のルールの “再帰的な” 積み上げ − ✘ 問題毎に答えを丸暗記しているわけでもない − ✔ 謎の⼆分探索を実⾏しているっぽい 📄 Nikankin+, ArithmeSc Without Algorithms: Language Models Solve Math With a Bag of HeurisScs (ICLR 2025)
− (1) “ヒューリスティック・ニューロン” の発⽕ – 🔥 「ふたつめの引数 ∈ [5, 25] mod 50」 – 🔥 「解 ∈ [150, 180]」 – 🔥 「解 ≡ 8 mod 10」 − (2) ⼀番スコアの積み上げが⼤きい「158」の⽣成確率が最⼤化 📄 Nikankin+, ArithmeSc Without Algorithms: Language Models Solve Math With a Bag of HeurisScs (ICLR 2025)
− (1) “ヒューリスティック・ニューロン” の発⽕︔ あたりをつける – 🔥 「ふたつめの引数 ∈ [5, 25] mod 50」 – 🔥 「解 ∈ [150, 180]」 – 🔥 「解 ≡ 8 mod 10」 − (2) ⼀番スコアの積み上げが⼤きい「158」の⽣成確率が最⼤化 📄 Nikankin+, ArithmeSc Without Algorithms: Language Models Solve Math With a Bag of HeurisScs (ICLR 2025)
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
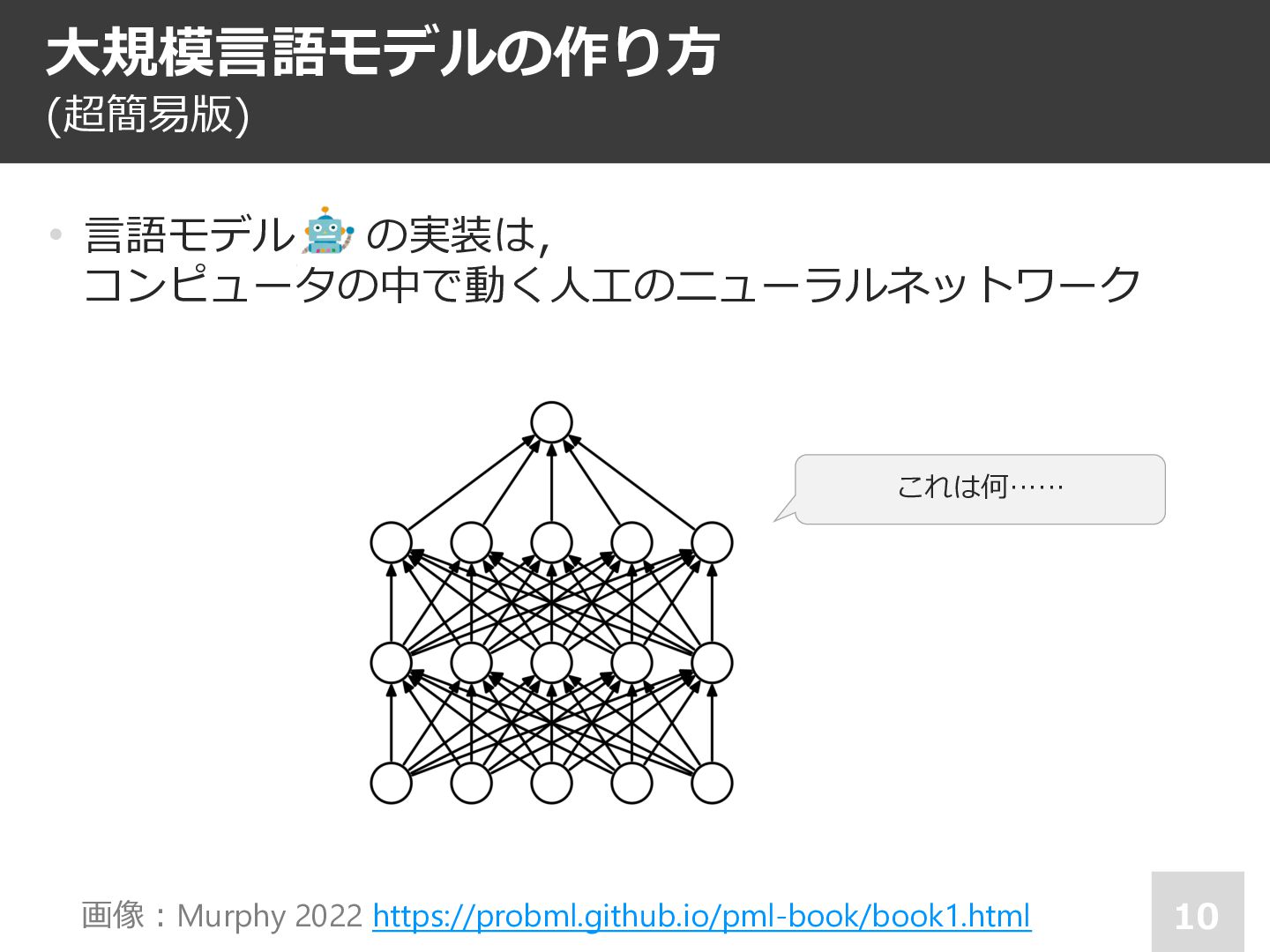
![⼈⼯知能 6 • 計算の形式化を背景に…… [Churchʼ36, Turingʼ36] • ⾏動主義から認知⾰命・⼈⼯知能(脳と⼼の計算モデル)へ [Newell&Simonʼ56, Millerʼ56,](https://files.speakerdeck.com/presentations/49761f7502504e1fb446b43ae37c1b3d/slide_5.jpg){kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
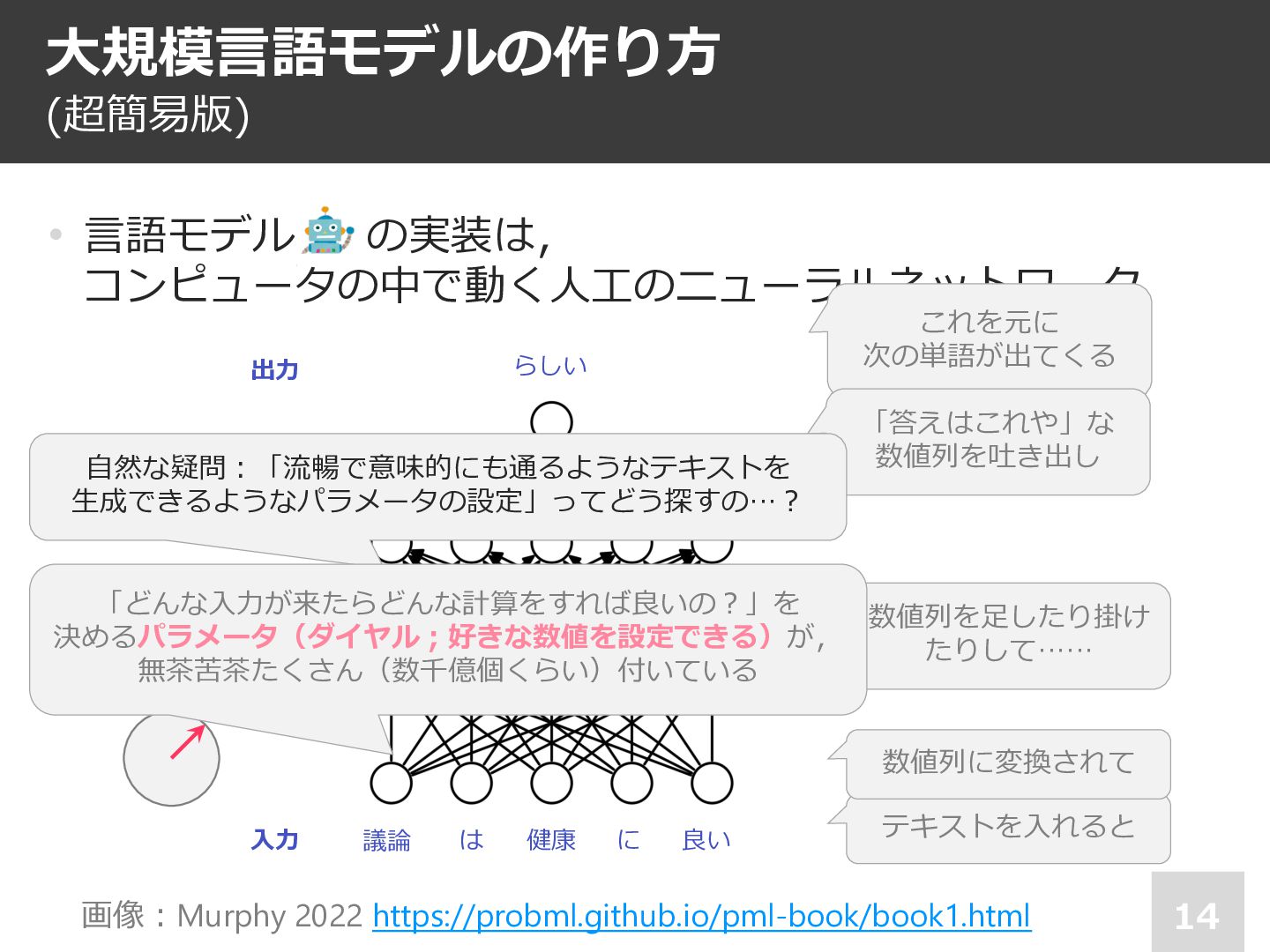
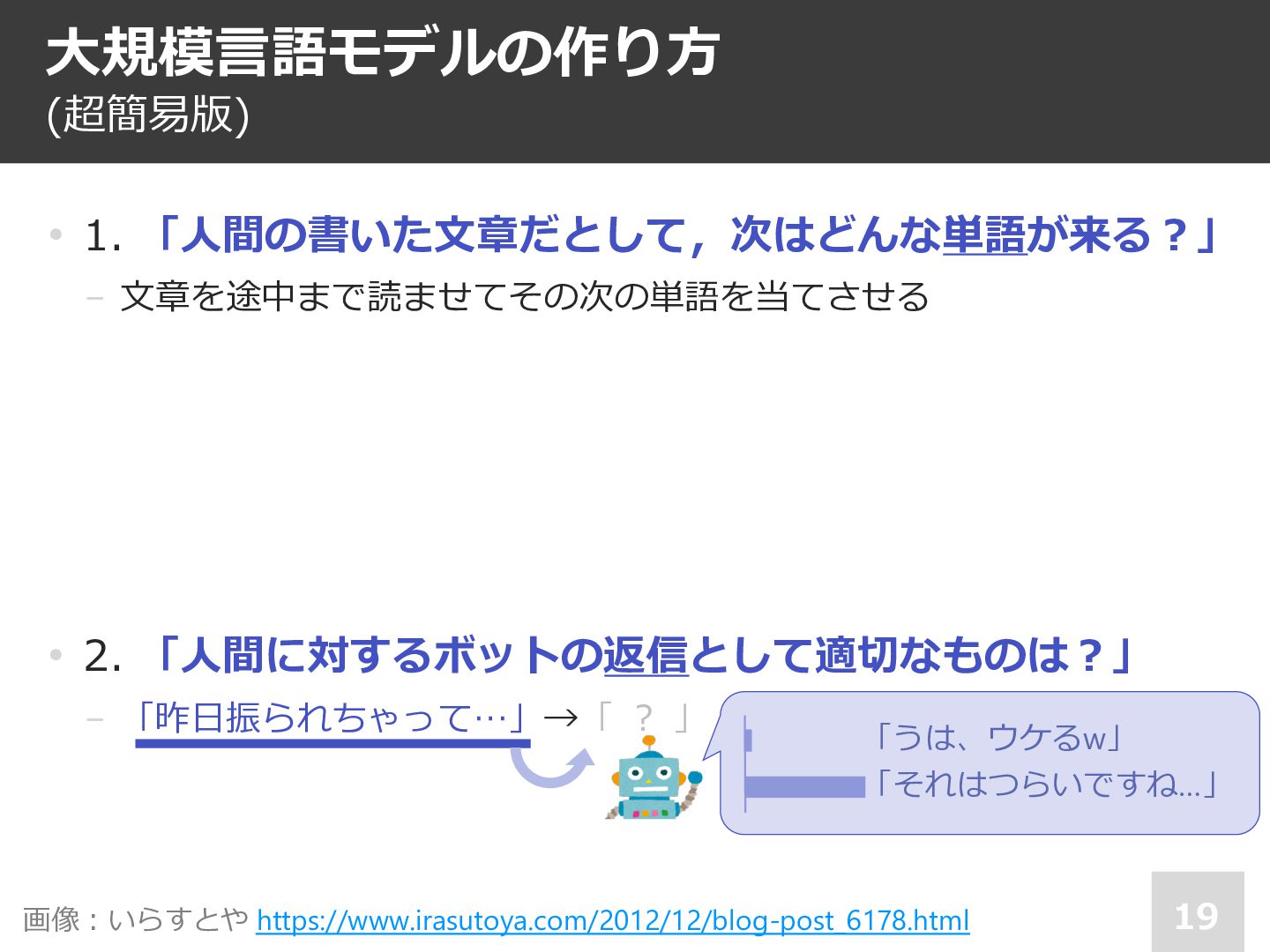
![16 • 1. 「⼈間の書いた⽂章だとして,次はどんな単語が来る︖」 − ⽂章を途中 [ ︖ ] 読ませて次の単語を予想させる](https://files.speakerdeck.com/presentations/49761f7502504e1fb446b43ae37c1b3d/slide_15.jpg){kind=link}
![17 • 1. 「⼈間の書いた⽂章だとして,次はどんな単語が来る︖」 − ⽂章を途中まで読ませ [ ︖ ] 次の単語を予想させる](https://files.speakerdeck.com/presentations/49761f7502504e1fb446b43ae37c1b3d/slide_16.jpg){kind=link}
![18 • 1. 「⼈間の書いた⽂章だとして,次はどんな単語が来る︖」 − ⽂章を途中まで読ませ [ ︖ ] 次の単語を予想させる](https://files.speakerdeck.com/presentations/49761f7502504e1fb446b43ae37c1b3d/slide_17.jpg){kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
![LMの⾔語運⽤能⼒と論理運⽤能⼒は関係ない︖ [Mahowald+, Trends in Cognitive Sciences 2024] 33 • ⾔語と思考](https://files.speakerdeck.com/presentations/49761f7502504e1fb446b43ae37c1b3d/slide_31.jpg){kind=link}
![⾔語モデルの,⼆分探索に基づく謎の算術 [Nikankin+, ICLR 2025] 34 • LMも,簡単な⾜し算・引き算などはほとんど正解できる • Q. どのように︖](https://files.speakerdeck.com/presentations/49761f7502504e1fb446b43ae37c1b3d/slide_32.jpg){kind=link}
![⾔語モデルの,⼆分探索に基づく謎の算術 [Nikankin+, ICLR 2025] 35 • 「226 - 68 =」を解かせようとすると……](https://files.speakerdeck.com/presentations/49761f7502504e1fb446b43ae37c1b3d/slide_33.jpg){kind=link}
![⾔語モデルの,⼆分探索に基づく謎の算術 [Nikankin+, ICLR 2025] 36 • 「226 - 68 =」を解かせようとすると……](https://files.speakerdeck.com/presentations/49761f7502504e1fb446b43ae37c1b3d/slide_34.jpg){kind=link}