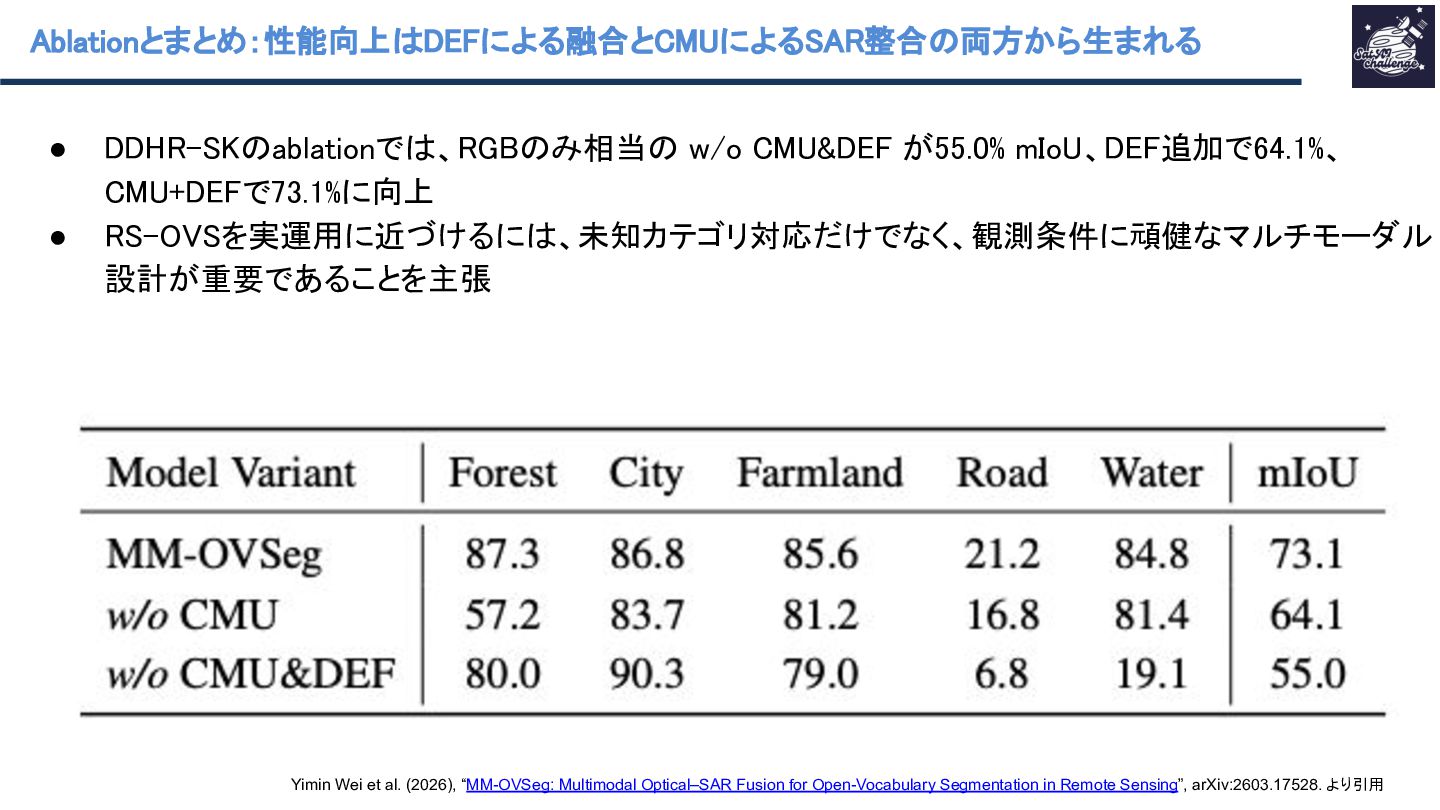
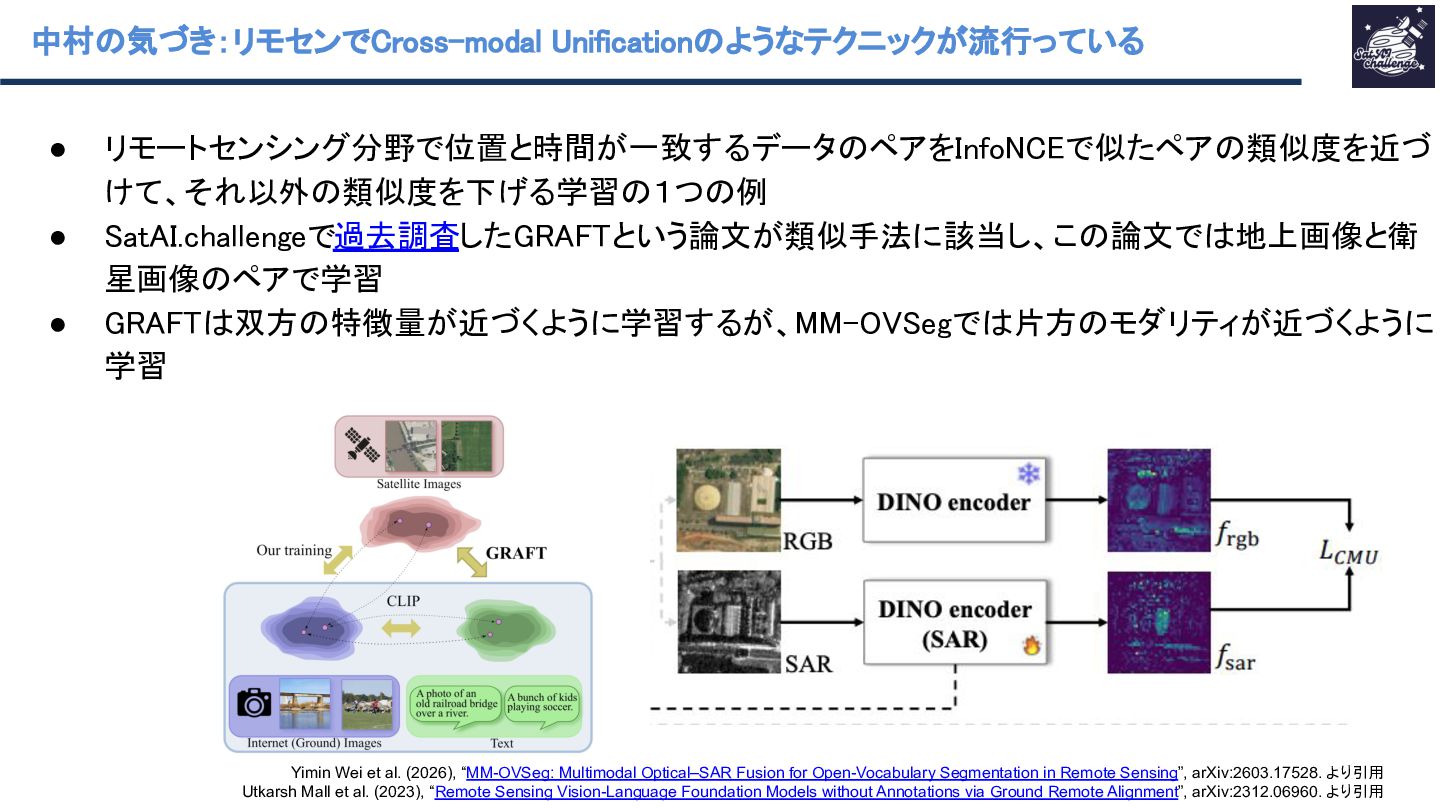
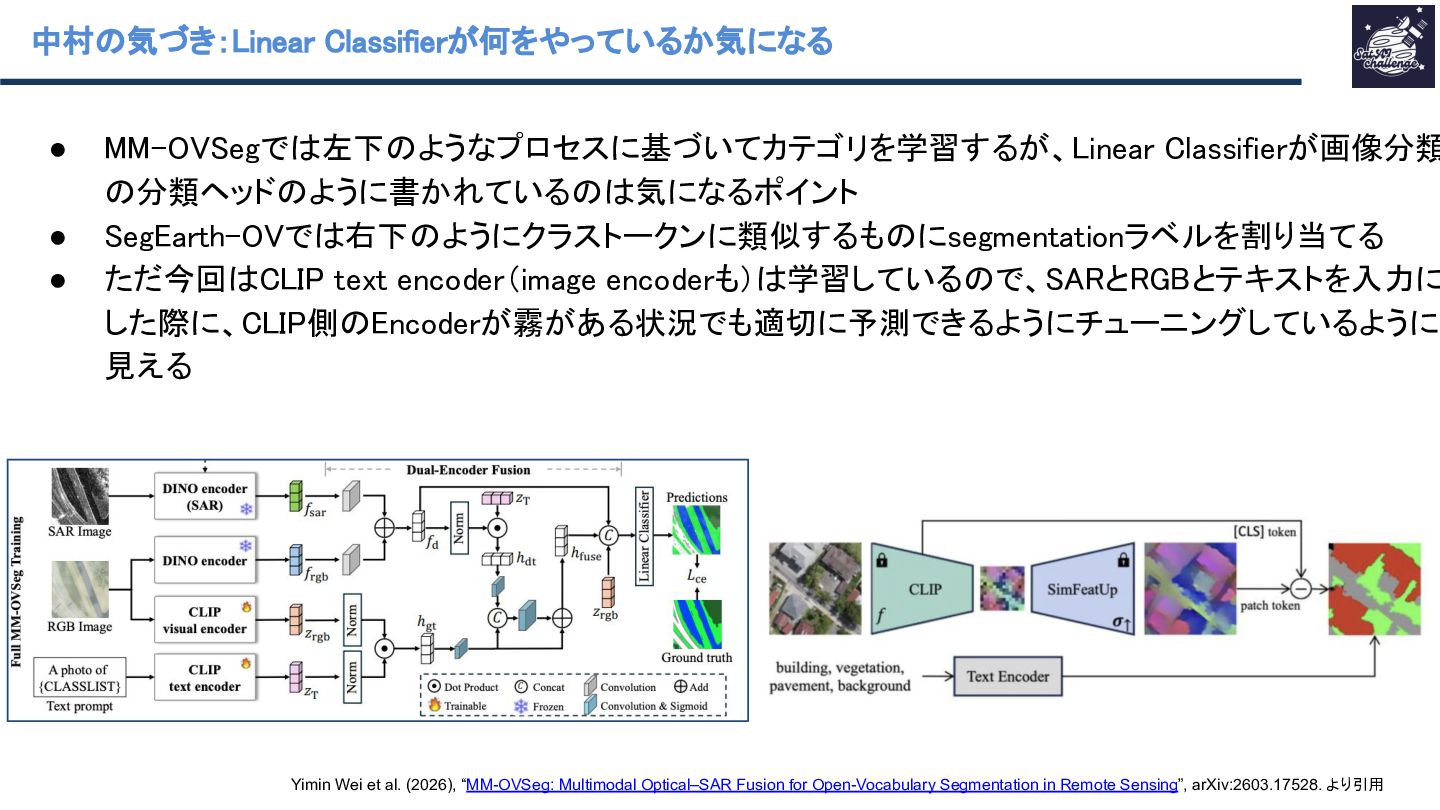
本資料はSatAI.challengeのサーベイメンバーと共に作成したものです。
SatAI.challengeは、リモートセンシング技術にAIを適用した論文の調査や、より俯瞰した技術トレンドの調査や国際学会のメタサーベイを行う研究グループです。speakerdeckではSatAI.challenge内での勉強会で使用した資料をWeb上で共有しています。
https://x.com/sataichallenge
本研究では、霧や雲がある場合Open-ocabulary egmentation(OVS)性能向上ために光学画像とA融合方法を提案しています。
従来のOVSでは、光学画像を用いてテキストからのセグメンテーションを行なっていましたが、霧や雲が画像中に含まれると性能が劣化する課題がありました。本研究ではこの課題に対処するために、光学画像のDINO埋め込みに近づくようにSARを処理するDINO encoderを学習させま。その後、本研究では、2つのDINOエンコーダーとテキストと画像のCLRPの特徴量をFusionするDual-Encoder Fusionと呼ばれる構造によりOVSを実現しています。
{kind=link}
{kind=link}
{kind=link}
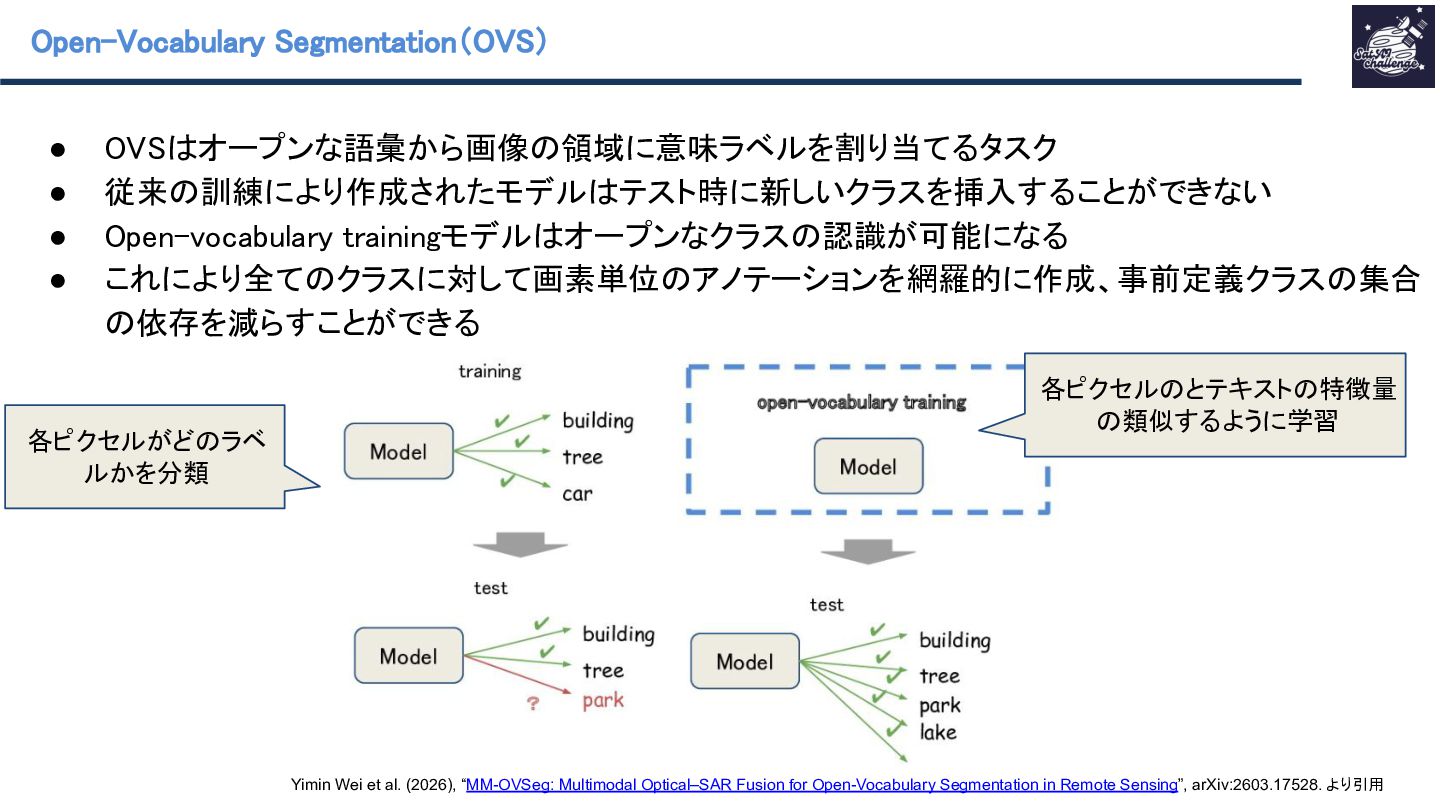{kind=link}
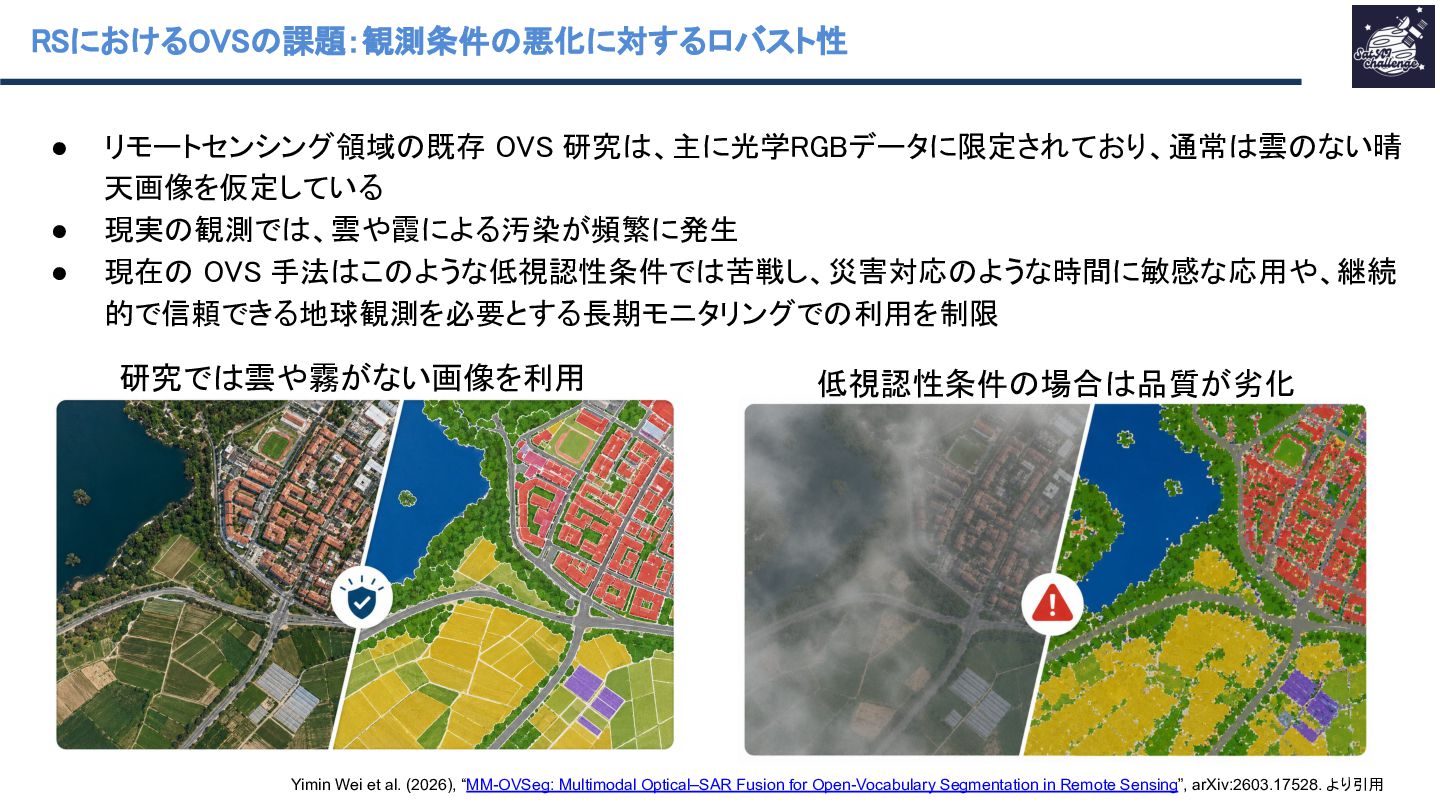{kind=link}
{kind=link}
{kind=link}
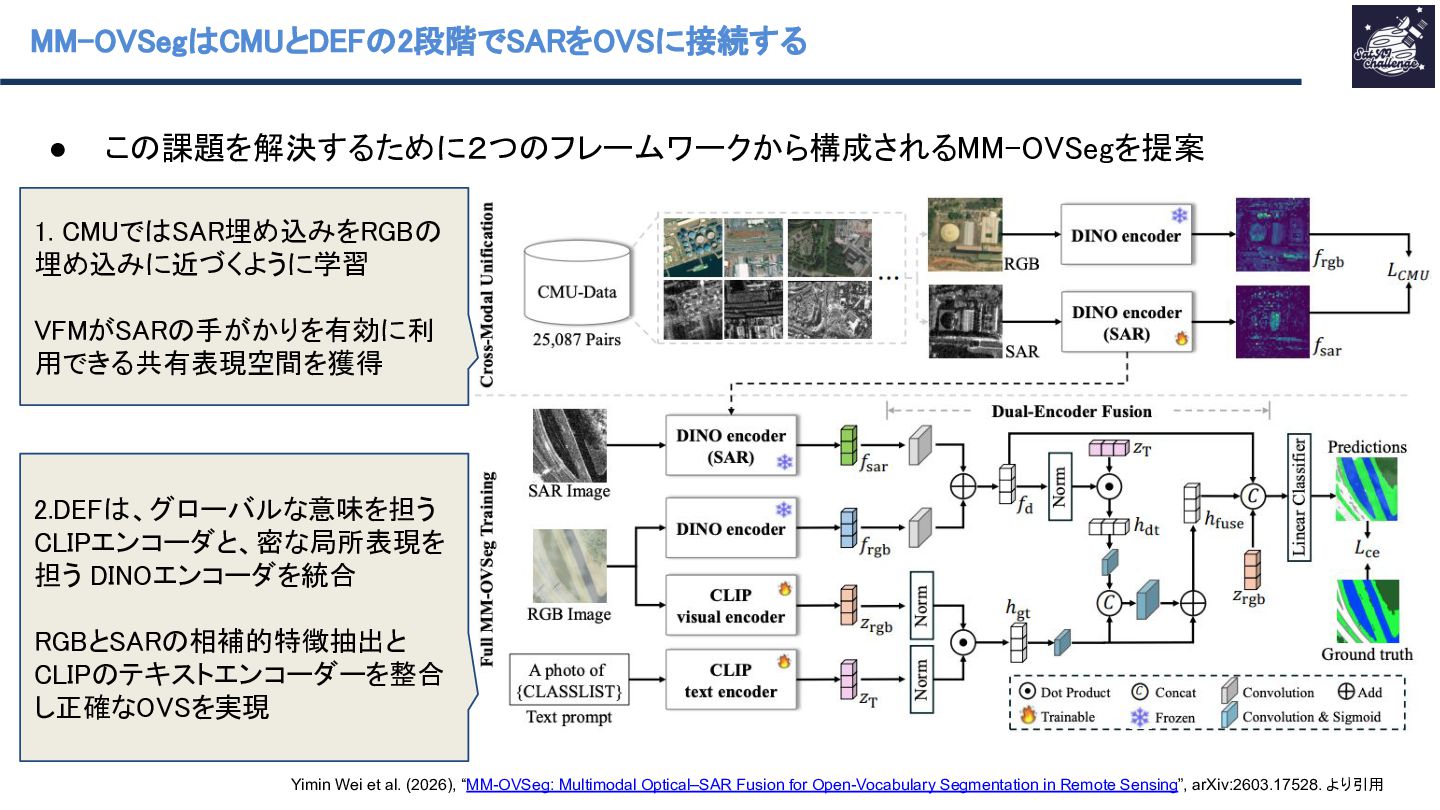{kind=link}
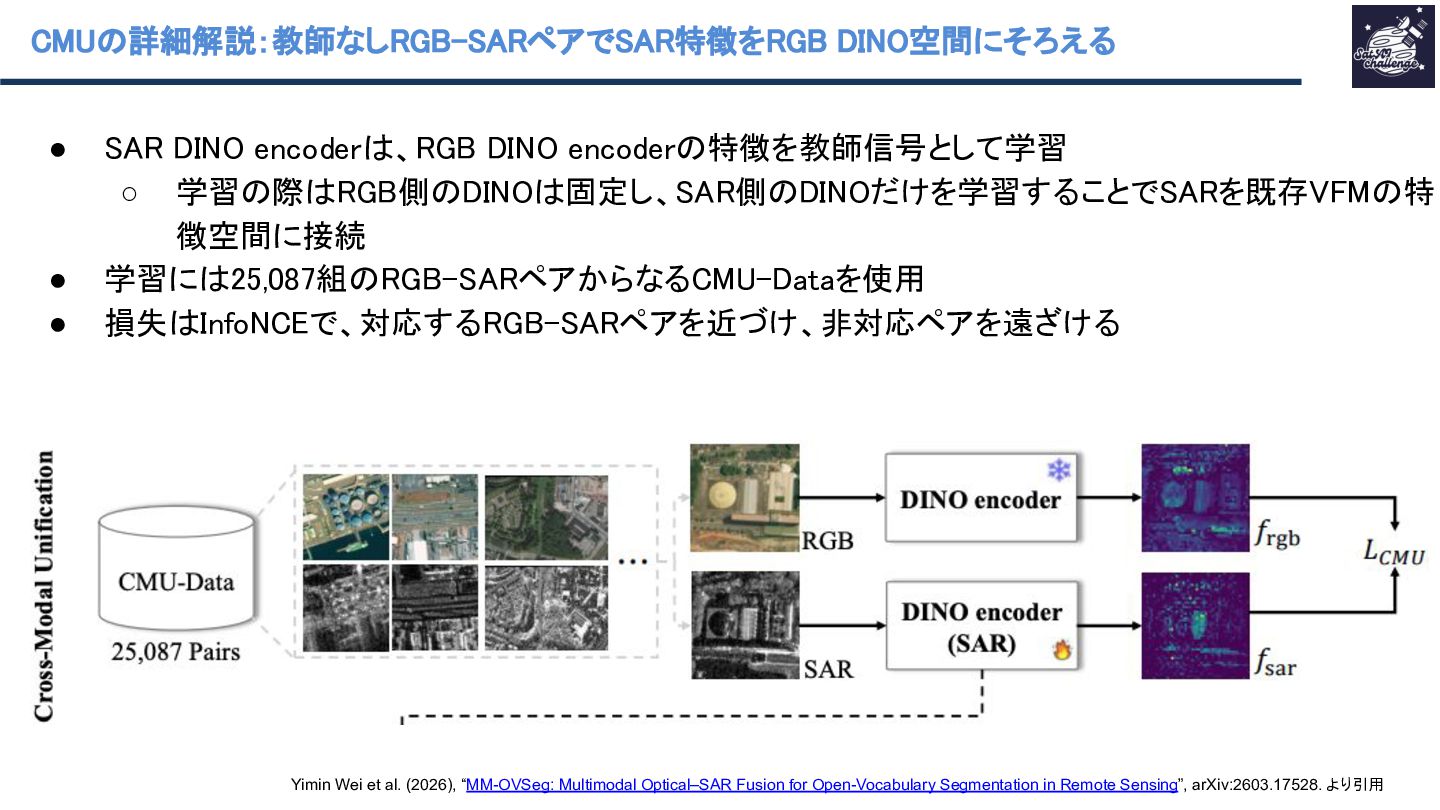{kind=link}
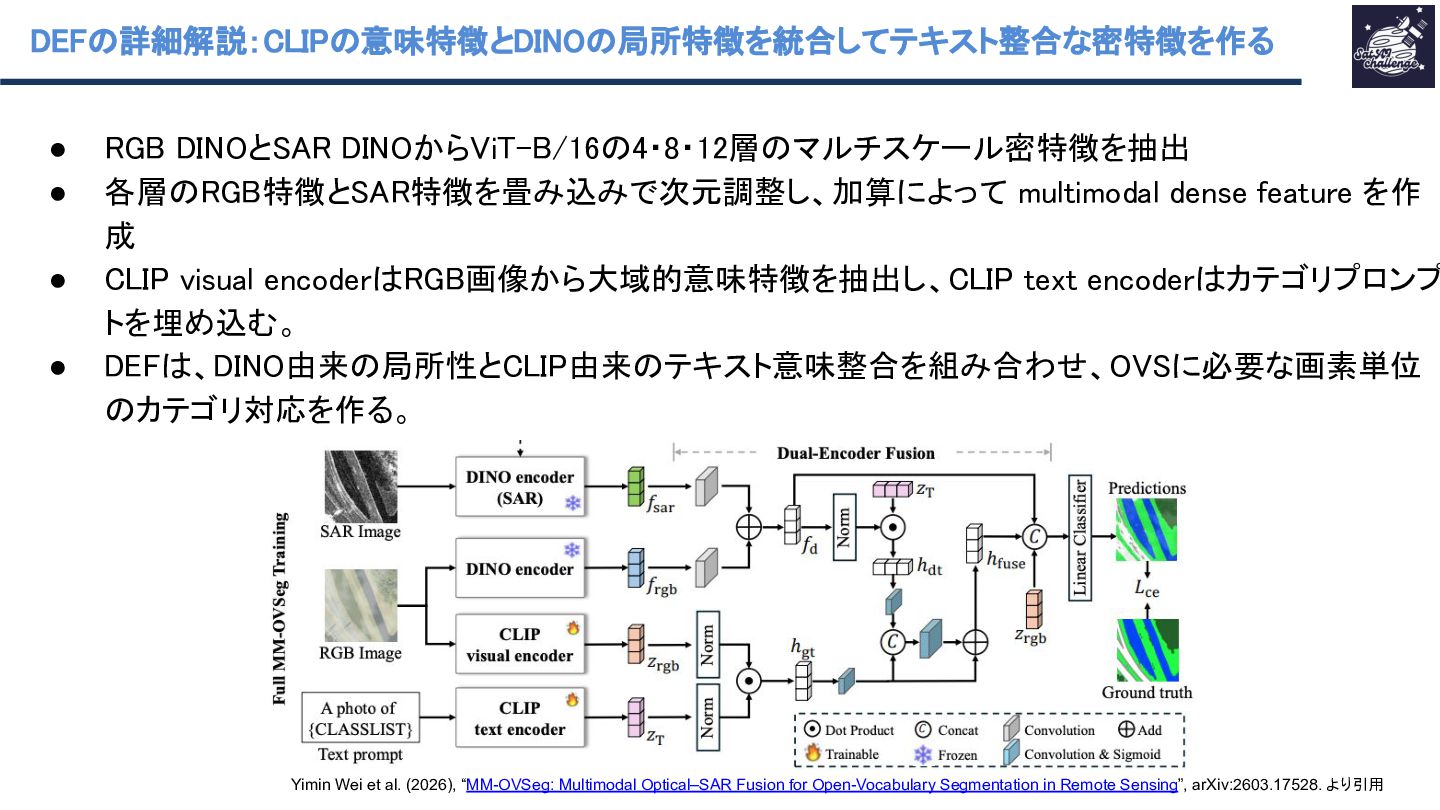{kind=link}
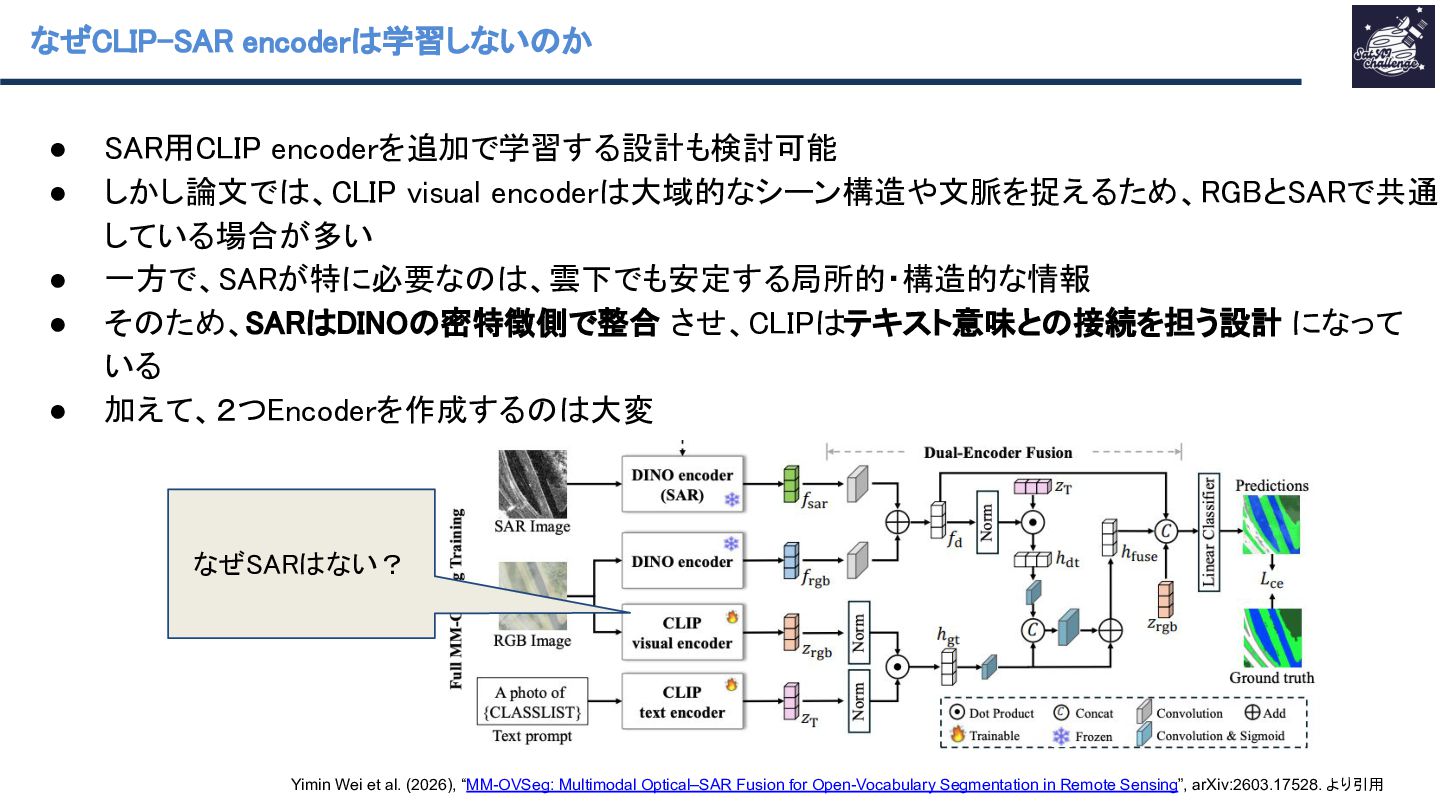{kind=link}
{kind=link}
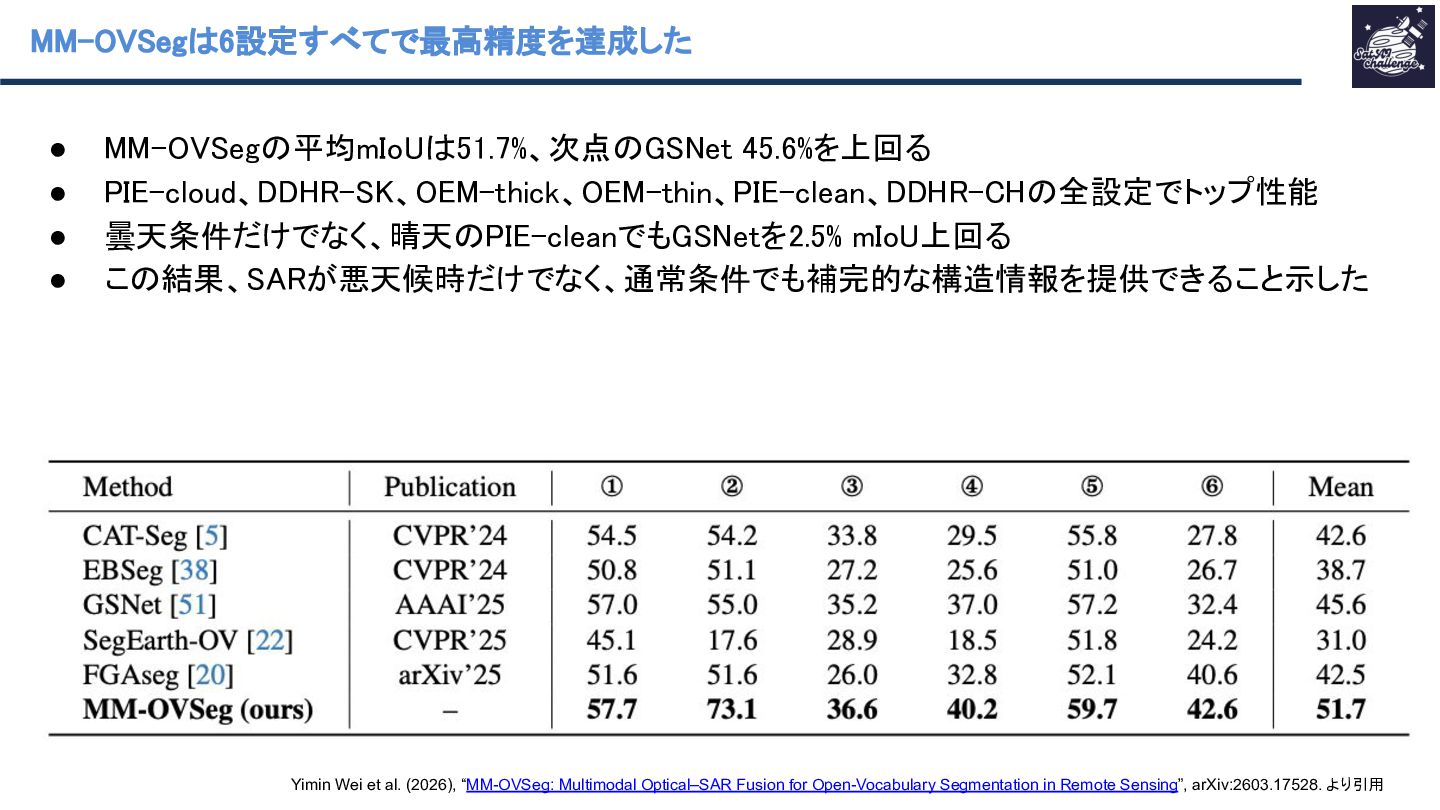{kind=link}
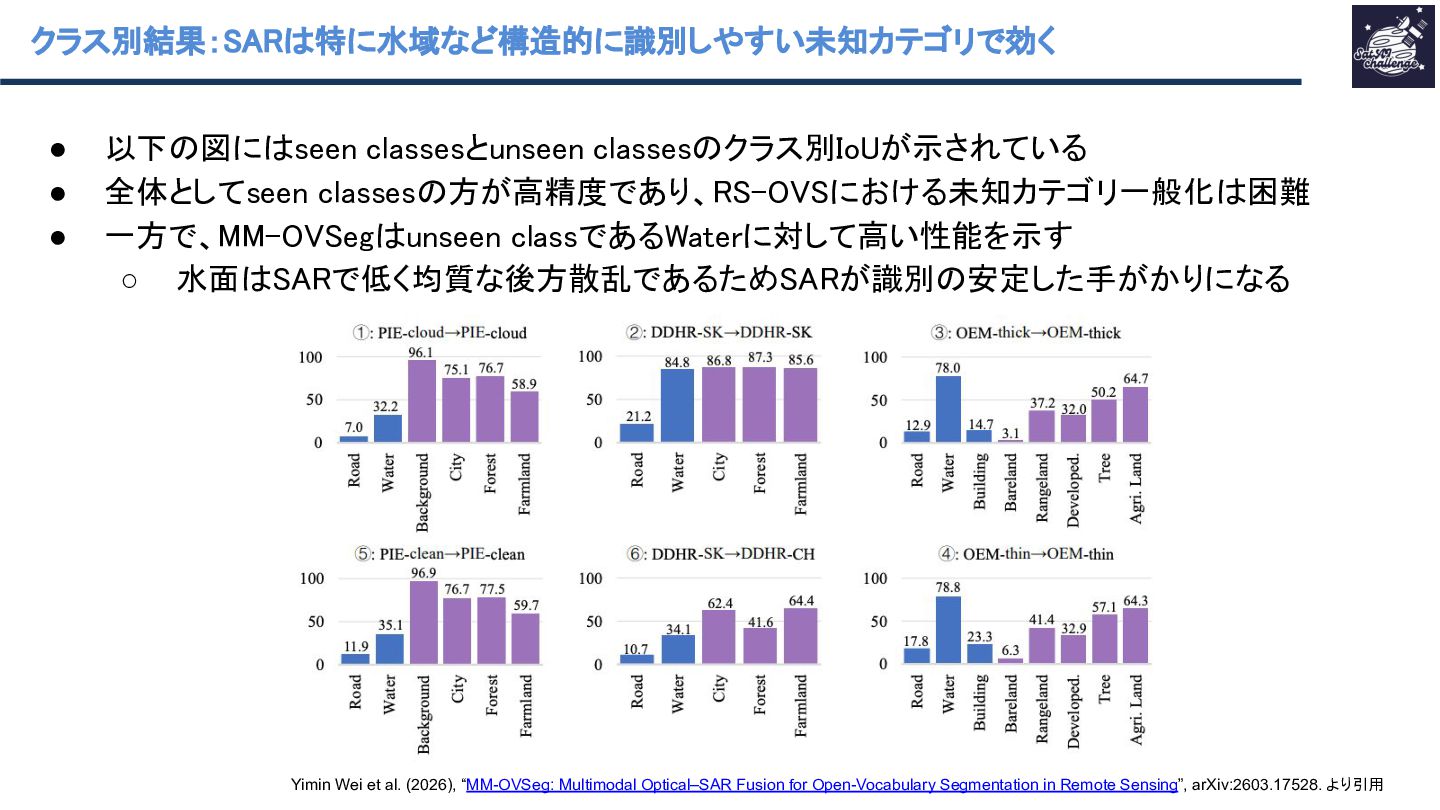{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}