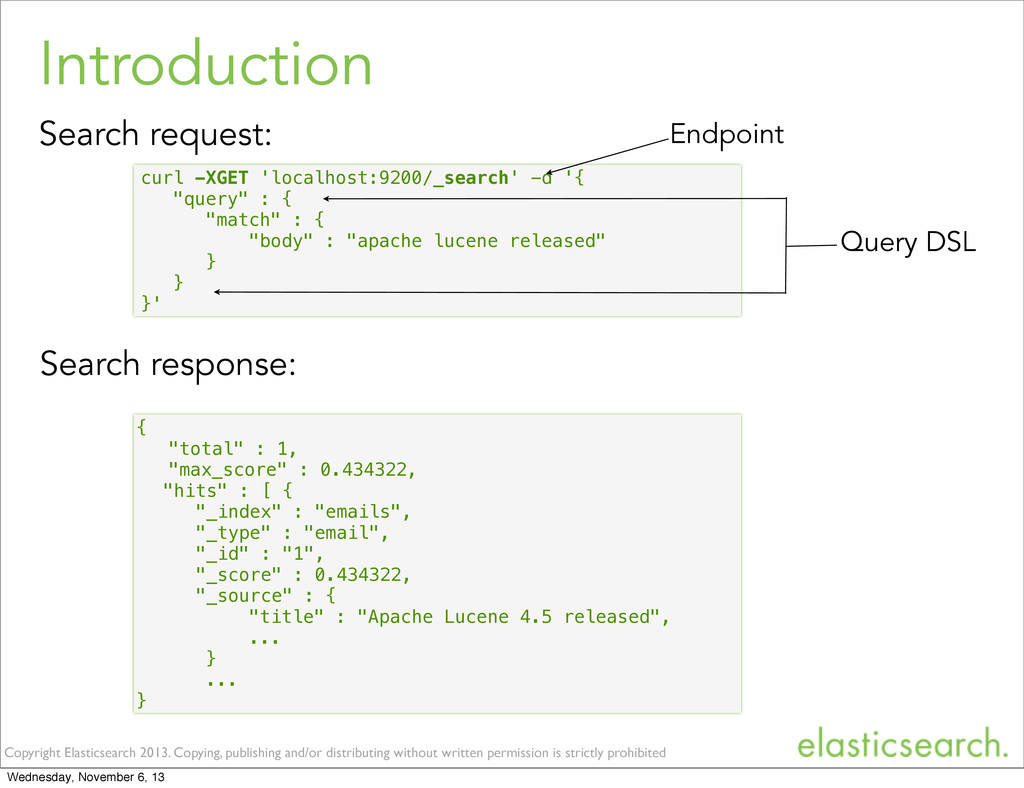
is strictly prohibited Introduction • What is Elasticsearch? Document based search engine. • Apache Lucene, JSON based • Major characteristics Dynamic schema that adjusts to your data. Distributed & Mult-tenant Easily scalable API centric Wednesday, November 6, 13
is strictly prohibited Introduction • Key features Free text search • Find any emails containing: “Apache Lucene released” Structured search • Find any emails sent by: [email protected] • Find any emails sent between April 2013 and now. Statistics • Return the top ‘from’ senders And a combination of all of the above. • All features work in (near) realtime Wednesday, November 6, 13
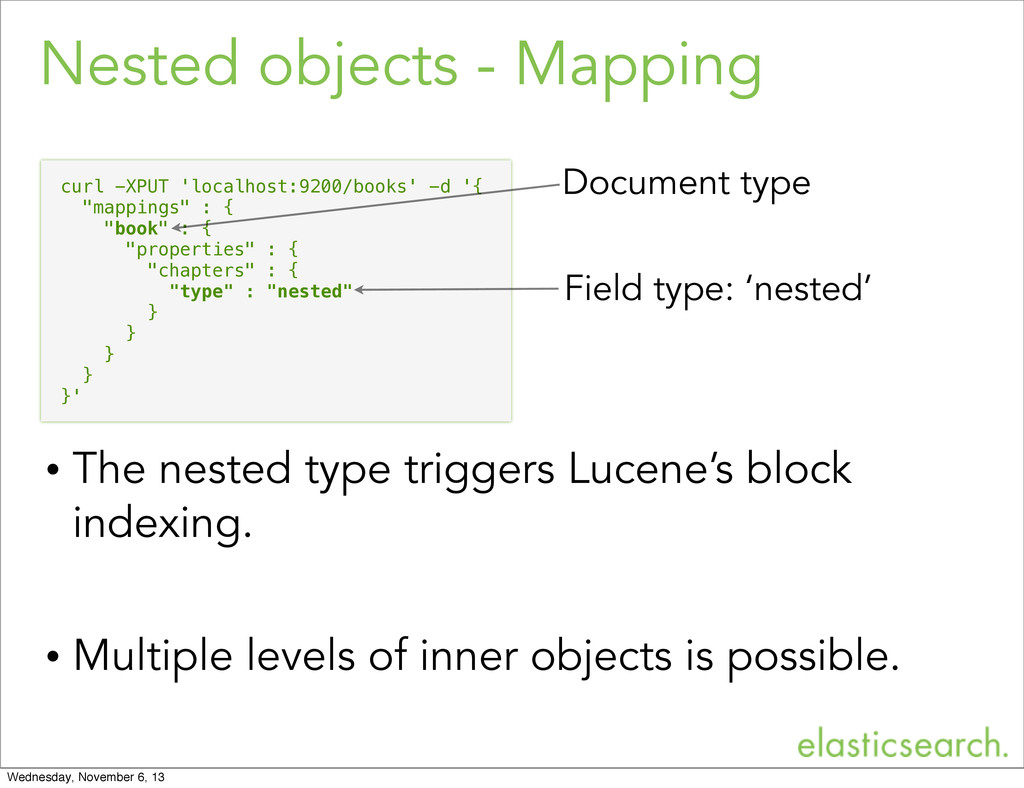
defined as JSON • The elasticsearch document is always converted to a Lucene document. Lucene Document is just key value pairs • Both the nested and parent-child support are just tools for document design. Wednesday, November 6, 13
"Elasticsearch" "summary" : "The definitive guide for Elasticsearch ..." "published_year" : 2013, "num_pages" : 289, "author" : ["Clinton Gormley", "Zachary Tong"], "categories" : ["programming", "information retrieval"], }' • But how to add data to it that is related? Like chapter or page data. Wednesday, November 6, 13
for Elasticsearch ..." "book_num_pages" : 289, "chapter_title" : "Introduction", "chapter_text" : "Short introduction about Elasticsearch’s features ...", "chapter_number_of_pages" : 12 }' • Lets add a book with chapters data. Each chapter as separate document with the book data. { "book_title" : "Elasticsearch" "book_summary" : "The definitive guide for Elasticsearch ..." "book_num_pages" : 289, "chapter_title" : "Data in, Data out", "chapter_text" : "How to manage your data with Elasticsearch ...", "chapter_num_pages" : 39 }' Document 1: Document 2: Wednesday, November 6, 13
for Elasticsearch ..." "num_pages" : 289, }' • Lets add a book with chapters data. Both book and chapters as separate documents and do a query time join. { "chapter_title" : "Data in, Data out", "chapter_text" : "How to manage your data with Elasticsearch ...", "chapter_num_pages" : 39 }' Document 1: Document 2: { "title" : "Introduction", "text" : "Short introduction about Elasticsearch’s features ...", "number_of_pages" : 12 } Document 2: Document 3: Wednesday, November 6, 13
• DG is different per application. The right DG depends on how your data is used. • But how does DG this affect the scalability of the data? Wednesday, November 6, 13
write time or read time. • Alternatively documents relations can balance the costs between read and write time. For example: one join to reduce duplicated data. • Supporting “many-to-many” joins in a distributed system is difficult. Either unbalanced partitions or very expensive join. Wednesday, November 6, 13
join between different document types in the same index. • Parent and children documents are stored as separate documents in the same index. • Child documents can point to only one parent. • Parent documents can be referred by multiple child documents. • Also a parent document can be a child document of a different parent. Wednesday, November 6, 13
are routed into the same shard. Parent id is used as routing value. • In combination with a parent ids in memory data structure the parent-child join is fast. • Use warming api to pre-load id cache. Wednesday, November 6, 13
to exist at time of indexing. curl -XPUT 'localhost:9200/products' -d '{ "mappings" : { "offer" : { "_parent" : { "type" : "product" } } } }' A offer document is a parent of a product document curl -XPUT 'localhost:9200/products/offer/12?parent=p2345' -d '{ "valid_from" : "2013-05-01", "valid_to" : "2013-10-01", "price" : 26.87, }' Then when indexing mention to what product a offer points to. Wednesday, November 6, 13
"categories" : ["programming", "information retrieval"], "published_year" : 2013, "summary" : "The definitive guide for Elasticsearch ...", "chapters" : [ { "title" : "Introduction", "summary" : "Short introduction about Elasticsearch’s features ...", "number_of_pages" : 12 }, { "title" : "Data in, Data out", "summary" : "How to manage your data with Elasticsearch ...", "number_of_pages" : 39 }, ... ] } • JSON allows complex nesting of objects. • But how does this get indexed? Wednesday, November 6, 13
"...", "chapters.number_of_pages" : 12}, {"chapters.title" : "Data...", "chapters.summary" : "...", "chapters.number_of_pages" : 39}, ... { "title" : "Elasticsearch", ... } Lucene Documents Structure: • Inlining the inner objects as separate Lucene documents right before the root document. • The root document and its nested documents always remain in the same block. Wednesday, November 6, 13
Nested Lucene documents, that match with the inner query. Aggregate nested scores and push to root document. X Set bit, that represents a root document. Wednesday, November 6, 13
only return one side of the relation. • The multi search api workaround can return both sides. At the cost of one extra subsequent request. • Future development will introduce the concept of inner_hits. This can include related parent and top children hits. Wednesday, November 6, 13
search request, that returns the top child docs. Like this sample request for the first hit: { "query" : { “filtered" : { “query" : { "range" : { "price" : { "lte" : 50 } } }, "filter" : { “term" : { “_parent" : "product#1", } } } } } The has_child’s inner query Only includes child docs that related to the first parent hit. Wednesday, November 6, 13
request has its own header and body line. By including routing in header, the execution of the search request will be optimized. Parent child - Querying {"routing" : "1"} {"query" : {"filtered":{"query":"range"{"price":{"lte":50}}},"f...}}, "size" : 3} {"routing" : "2"} {"query" : {"filtered":{"query":"range"{"price":{"lte":50}}},"f...}}, "size" : 3} {"routing" : "3"} {"query" : {"filtered":{"query":"range"{"price":{"lte":50}}},"f...}}, "size" : 3} ... Requests file: curl -XGET 'localhost:9200/products/offer/_msearch --data-binary @requests; echo Item header Item body Wednesday, November 6, 13
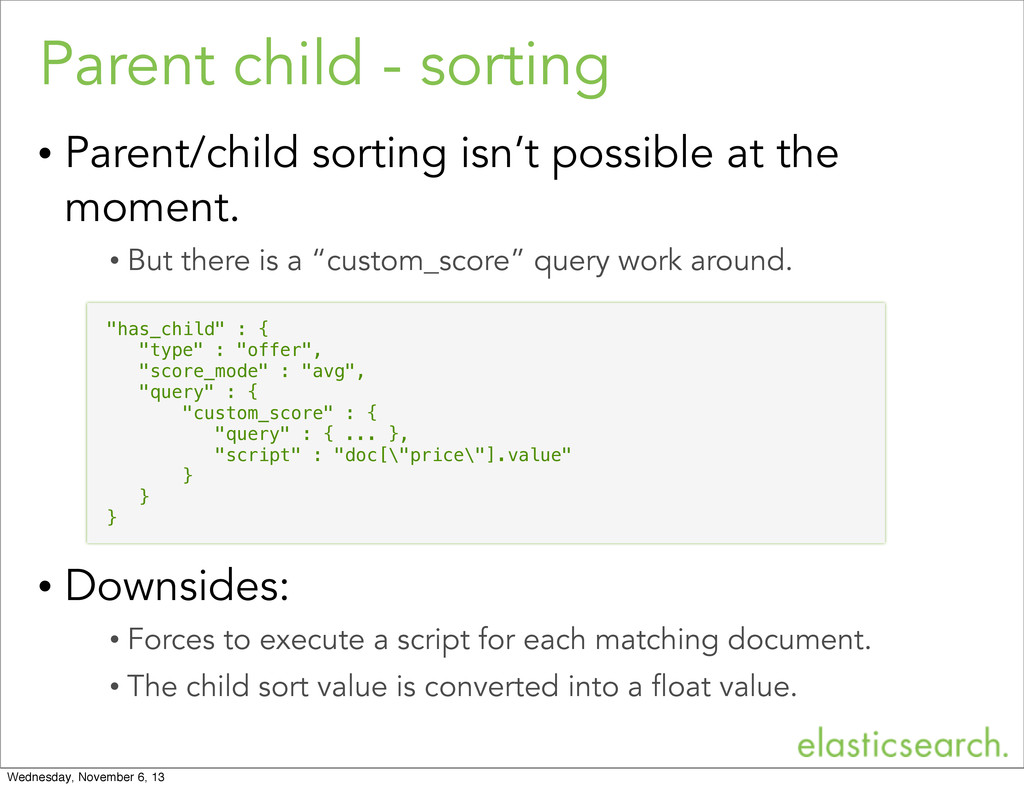
the moment. • But there is a “custom_score” query work around. • Downsides: • Forces to execute a script for each matching document. • The child sort value is converted into a float value. "has_child" : { "type" : "offer", "score_mode" : "avg", "query" : { "custom_score" : { "query" : { ... }, "script" : "doc[\"price\"].value" } } } Wednesday, November 6, 13
![Martijn van Groningen [email protected] @mvgroningen Document relations Wednesday, November 6,](https://files.speakerdeck.com/presentations/d4f8f130292d01316fe832c65d7cd49e/slide_0.jpg){kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}