三井物産 金属、先物、米国株、為替レートといったグローバルな金融市場の時系 列データを使用し、複数の金融商品のリターン(収益率)を予測 CMI - Detect Behavior with Sensor Data Child Mind Institute ウェアラブルデバイスに搭載されたセンサー(加速度センサー、ToFセン サー、温度センサーなど)のデータを用いて、抜毛症や皮膚むしり症と いった「身体集中反復行動(BFRB)」を自動で検出 RSNA Intracranial Aneurysm Detection 北米放射線学会、米国神 経放射線学会 など CTA(CT血管造影)やMRA(MR血管造影)などの医療画像を分析し、 生命を脅かす可能性のある頭蓋内動脈瘤の有無と、その正確な位置を 検出する MAP - Charting Student Math Misunderstandings The MAPLE Lab at the University of Toronto 生徒が書いた数学問題の解答(自由記述)を分析し、その生徒がどのよ うな誤解をしている可能性があるかを予測する自然言語処理モデルを 開発 過去にコンペを実施した組織の一例 Mercari、リクルート、日本取引所グループ、 NTTデータ、Google、Microsoft、Facebook(Meta)、 Airbnb、Lyft、Walmart、Bosch、H&M、DCASEなど 4/49
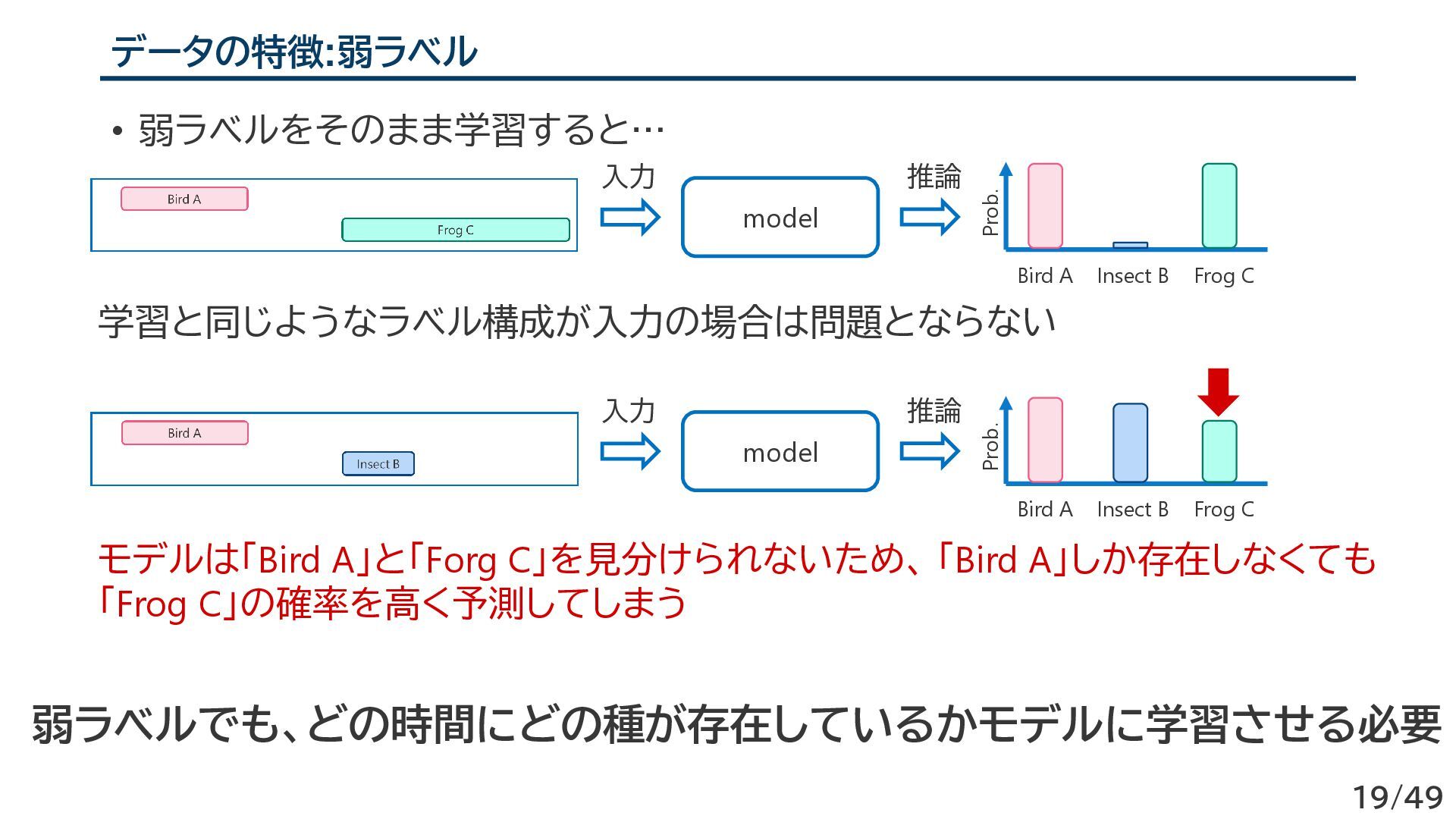
Frog C Prob. model 入力 推論 Bird A Insect B Frog C Prob. 学習と同じようなラベル構成が入力の場合は問題とならない モデルは「Bird A」と「Forg C」を見分けられないため、 「Bird A」しか存在しなくても 「Frog C」の確率を高く予測してしまう 弱ラベルでも、どの時間にどの種が存在しているかモデルに学習させる必要 19/49
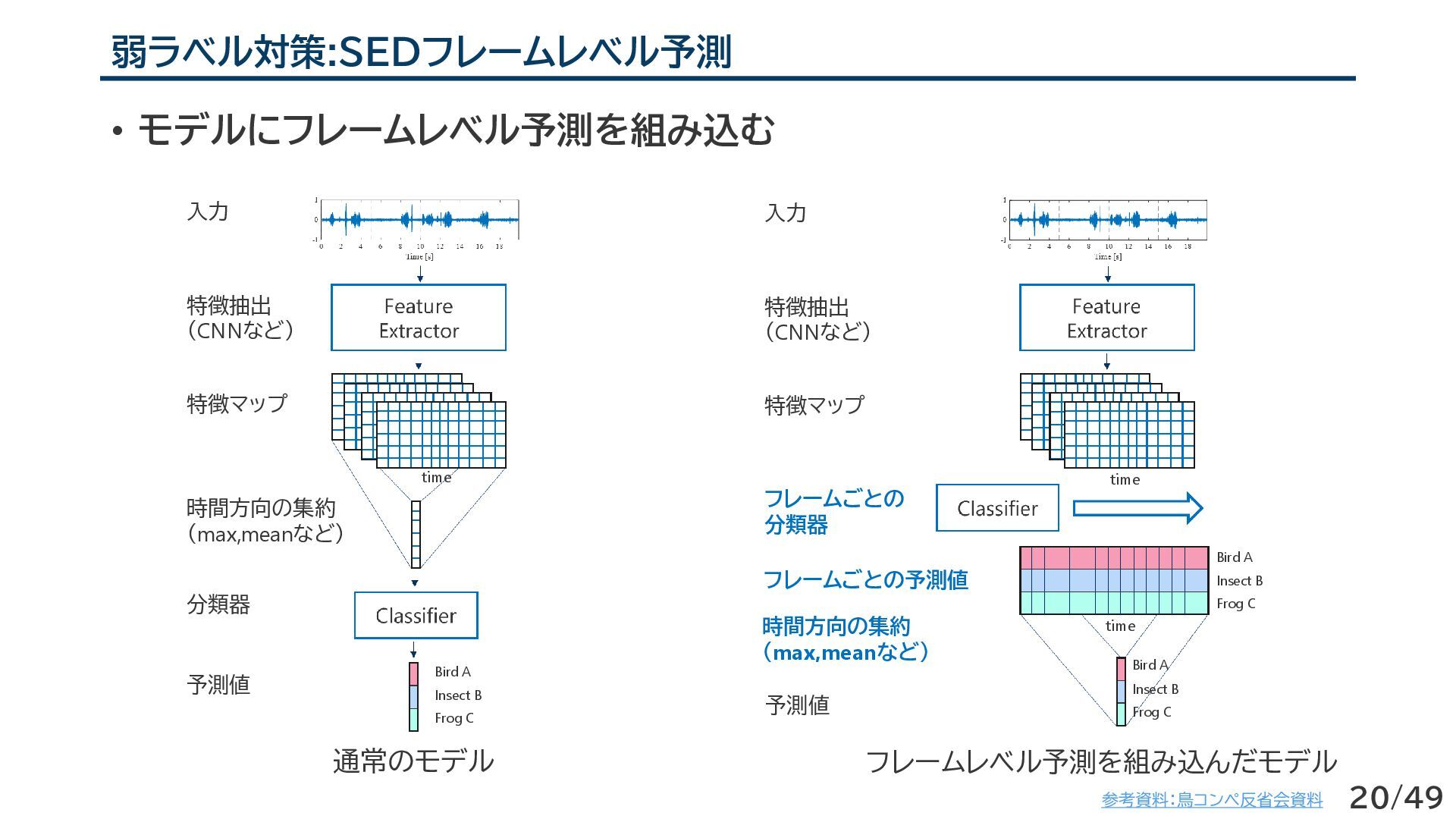
予測値 分類器 特徴抽出 (CNNなど) 入力 特徴マップ フレームごとの 分類器 予測値 フレームごとの予測値 時間方向の集約 (max,meanなど) 通常のモデル フレームレベル予測を組み込んだモデル Frog C Bird A Insect B Bird A Insect B Frog C time time Bird A Insect B Frog C time 20/49
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
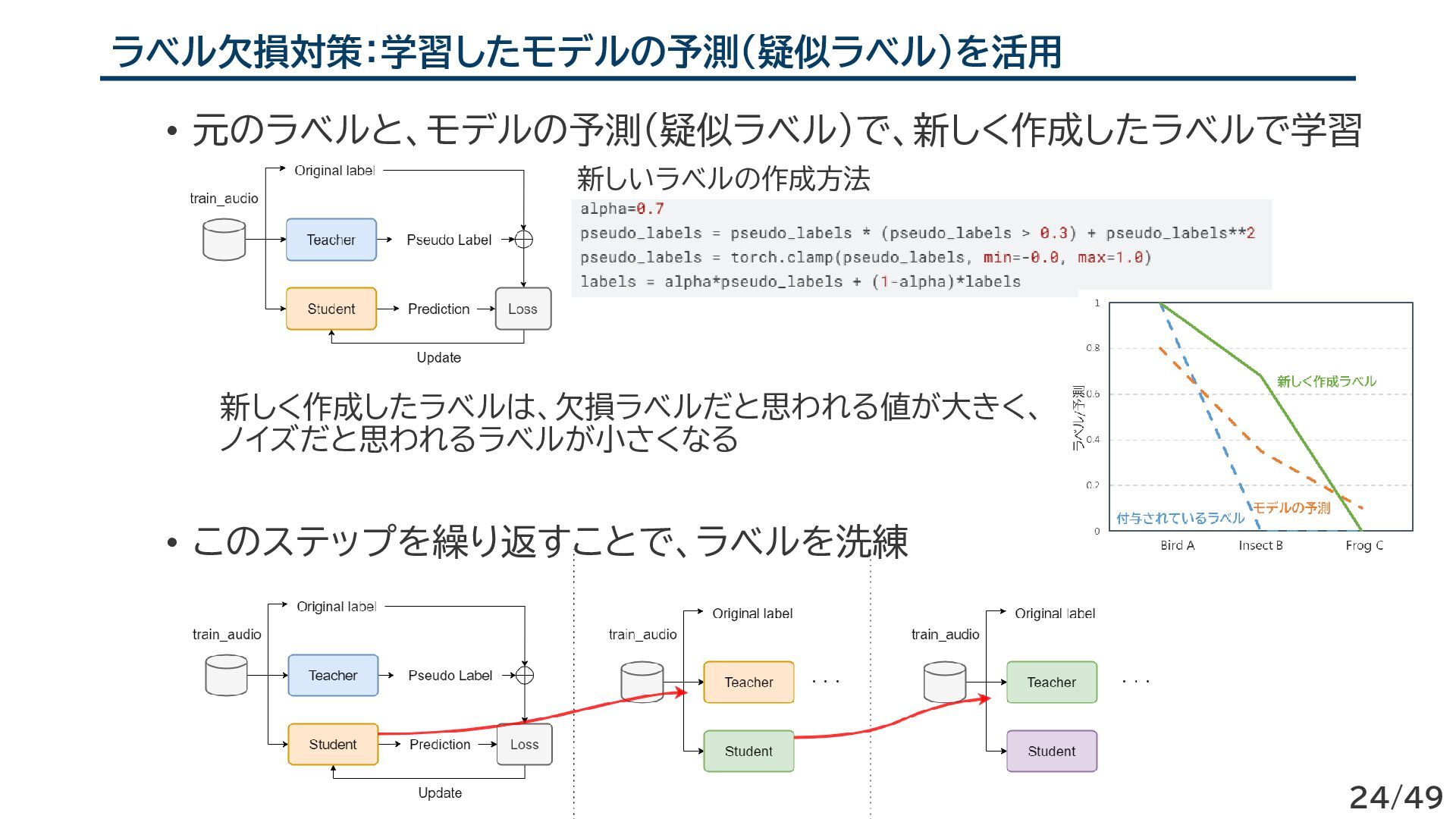{kind=link}
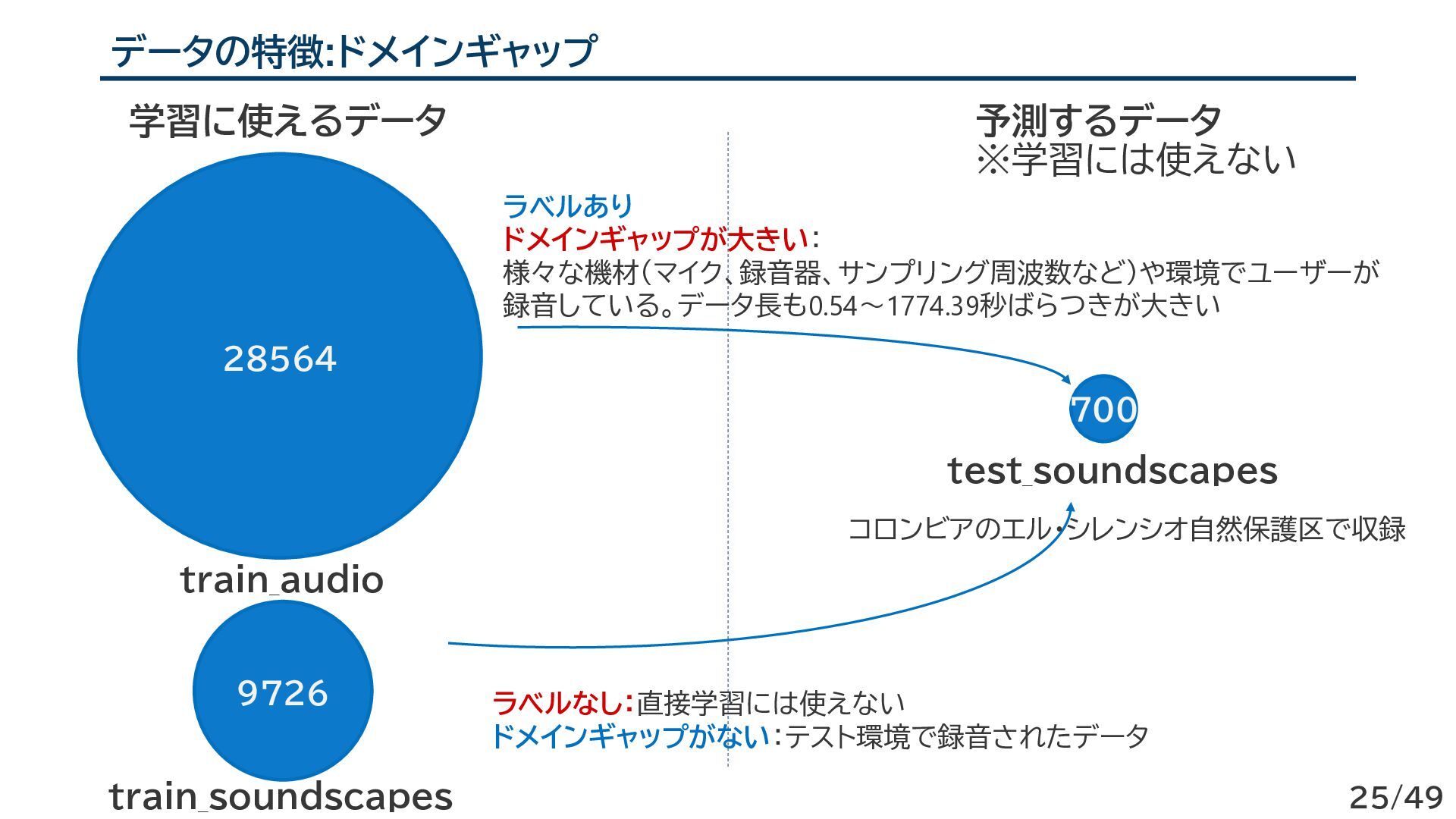{kind=link}
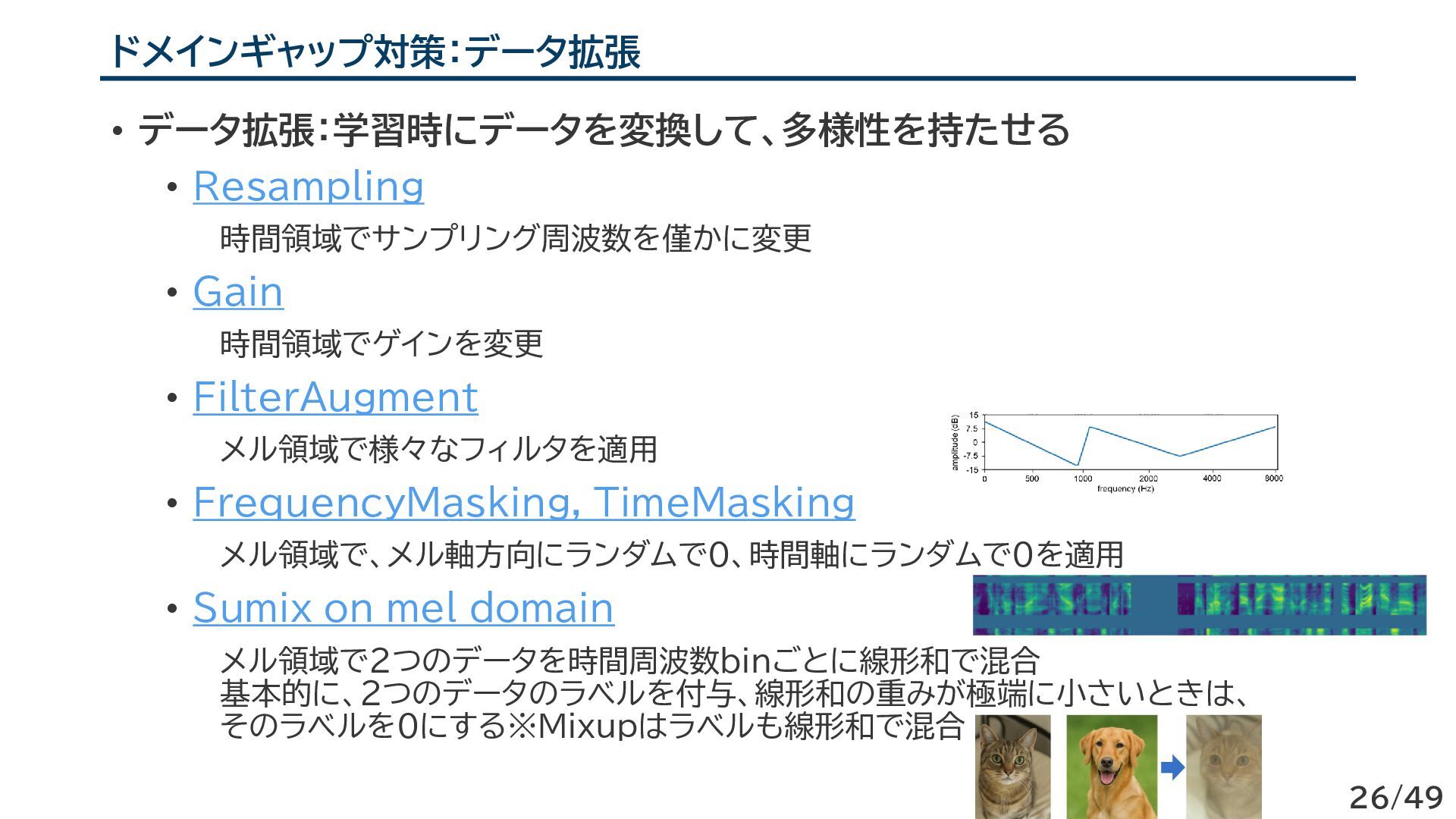{kind=link}
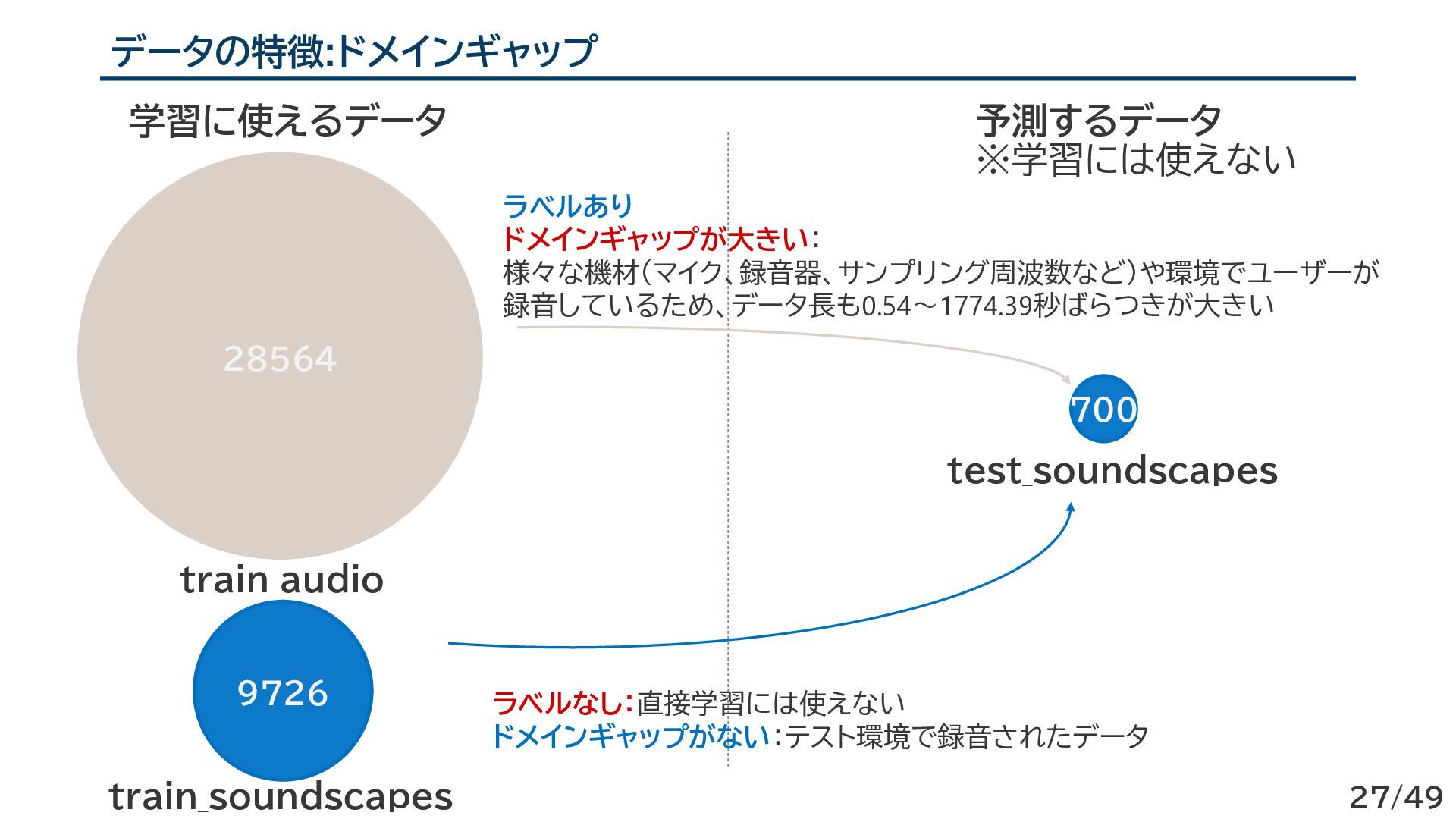{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}