Setting up the future Internet of Things (IoT) networks will require to support more and more communicating devices. We prove that intelligent devices in unlicensed bands can use Multi-Armed Bandit (MAB) learning algorithms to improve resource exploitation. We evaluate the performance of two classical MAB learning algorithms, UCB1 and Thompson Sampling, to handle the decentralized decision-making of Spectrum Access, applied to IoT networks; as well as learning performance with a growing number of intelligent end-devices. We show that using learning algorithms does help to fit more devices in such networks, even when all end-devices are intelligent and are dynamically changing channel. In the studied scenario, stochastic MAB learning provides a up to 16% gain in term of successful transmission probabilities, and has near optimal performance even in non-stationary and non-i.i.d. settings with a majority of intelligent devices.
Additionally, I give insights on the latest theoretical results we obtained in the simplest case with let say 10 objects always communicating in at least 10 channels. Extending our results to the case of many objects communicating less frequently is significantly harder and will be dealt with during my 2nd year of PhD.
Main references are my recent articles (on HAL):
- Multi-Armed Bandit Learning in IoT Networks and non-stationary settings, Bonnefoi, Besson, Moy, Kaufmann, Palicot. CrownCom 2017. https://hal.inria.fr/hal-01575419
- Multi-Player Bandits Models Revisited, Besson, Kaufmann. arXiv:1711.02317. https://hal.inria.fr/hal-01629733
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
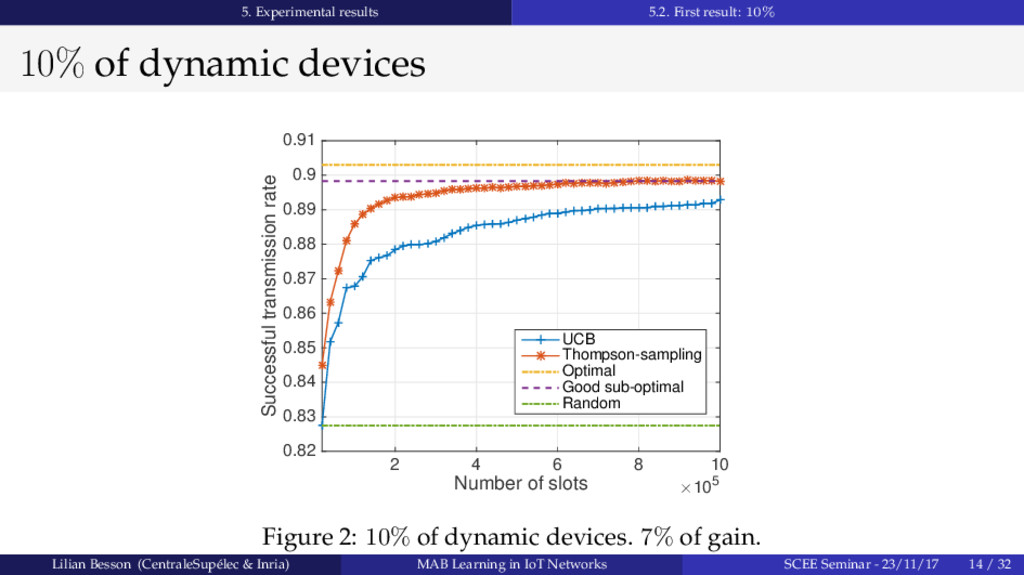{kind=link}
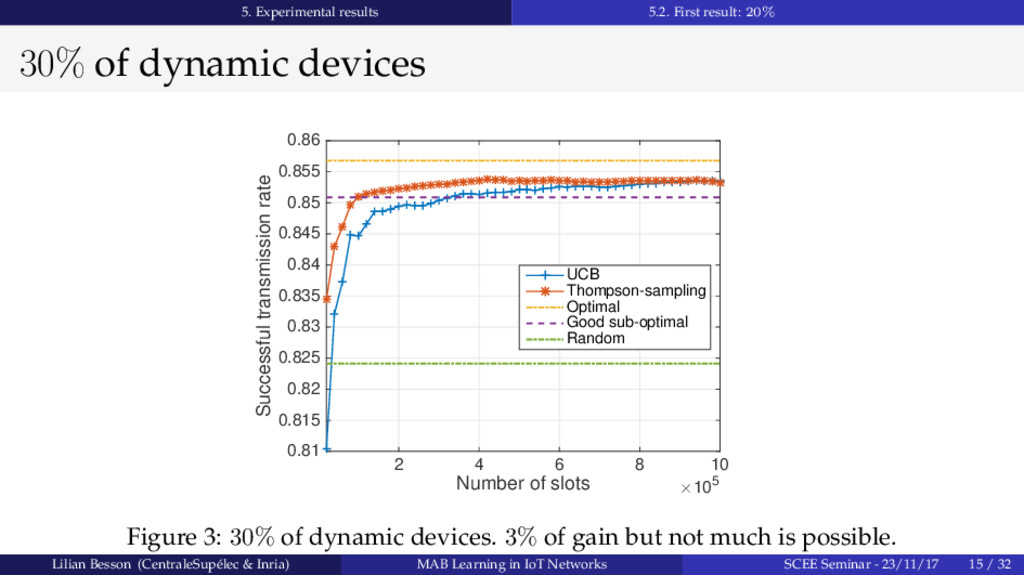{kind=link}
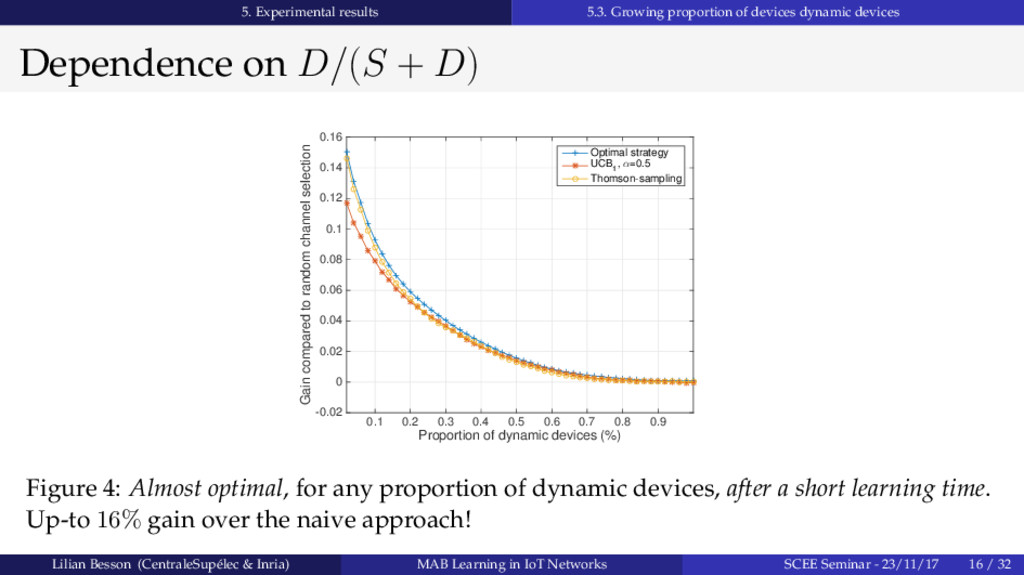{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
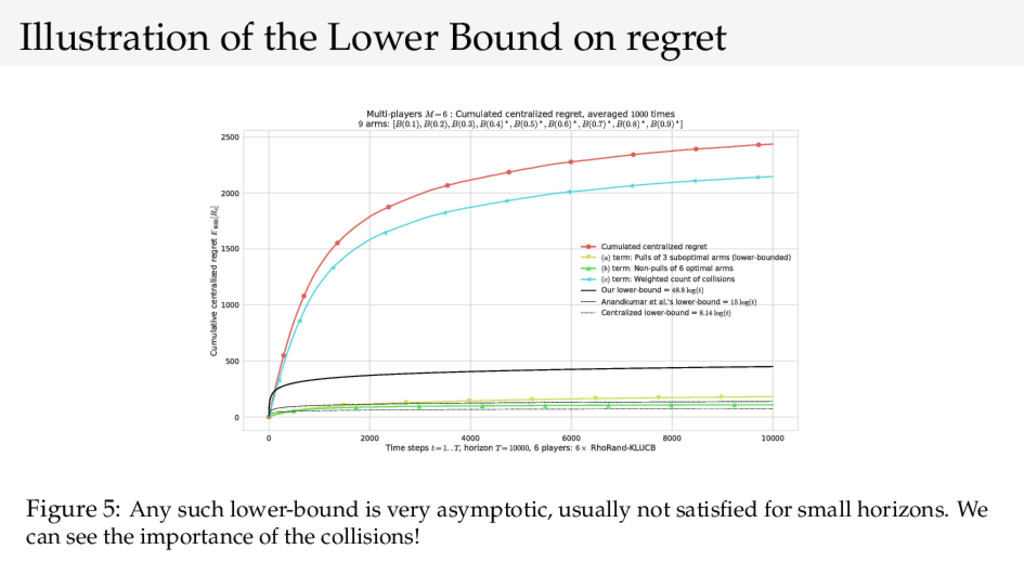{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}