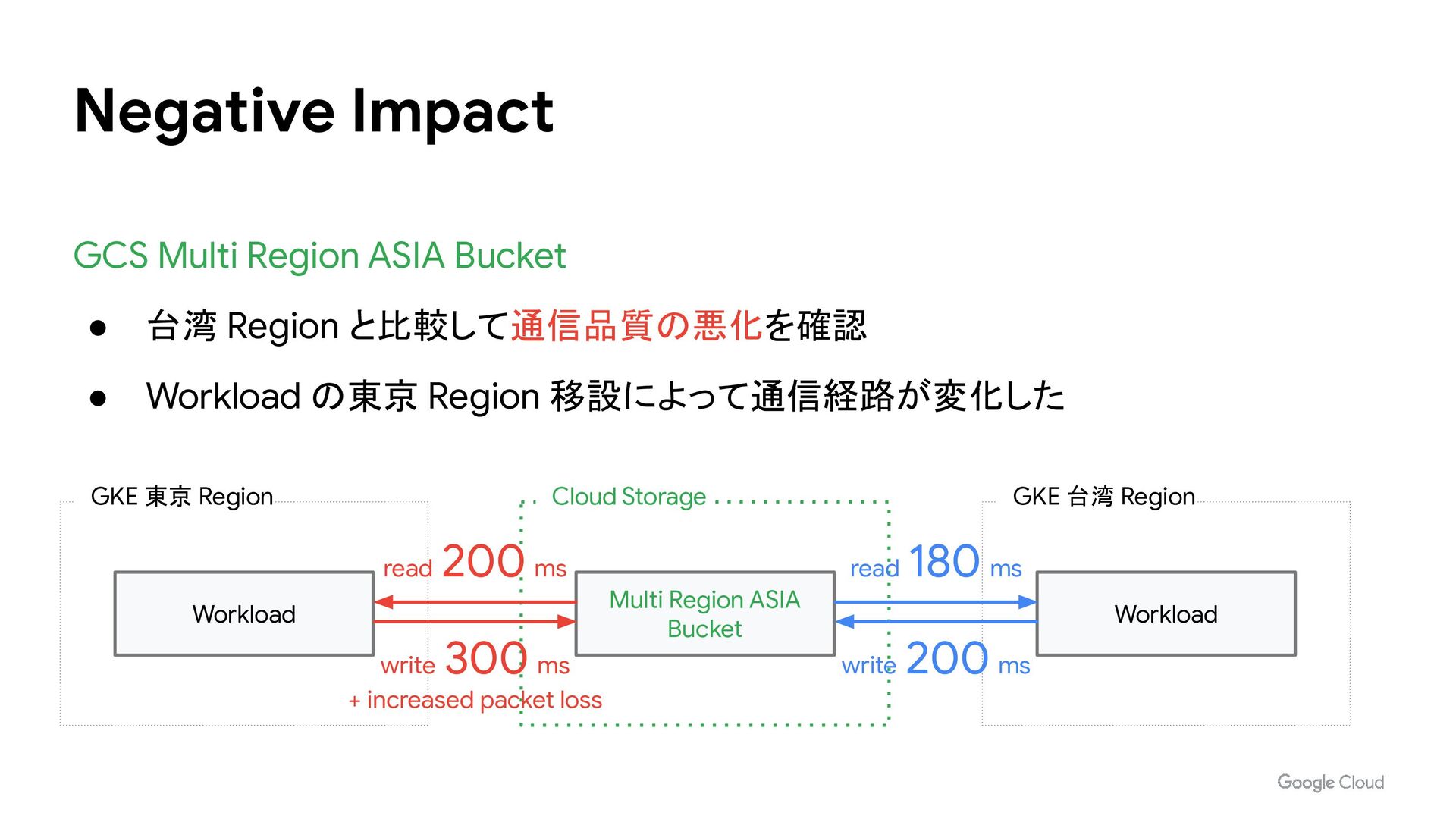
と比較して通信品質の悪化を確認 • Workload の東京 Region 移設によって通信経路が変化した GKE 東京 Region GKE 台湾 Region Cloud Storage Workload Multi Region ASIA Bucket Workload write 200 ms write 300 ms read 200 ms read 180 ms + increased packet loss
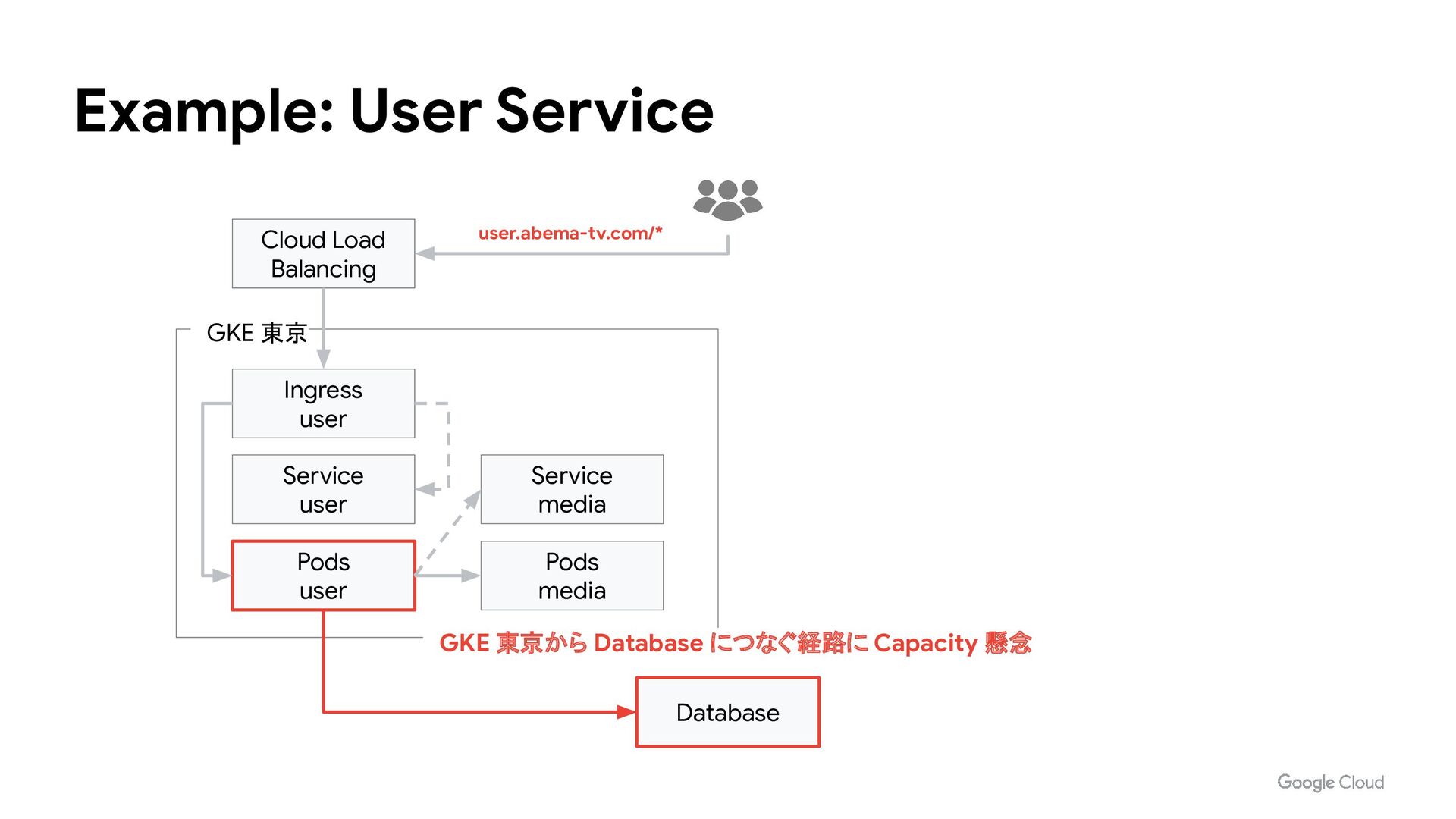
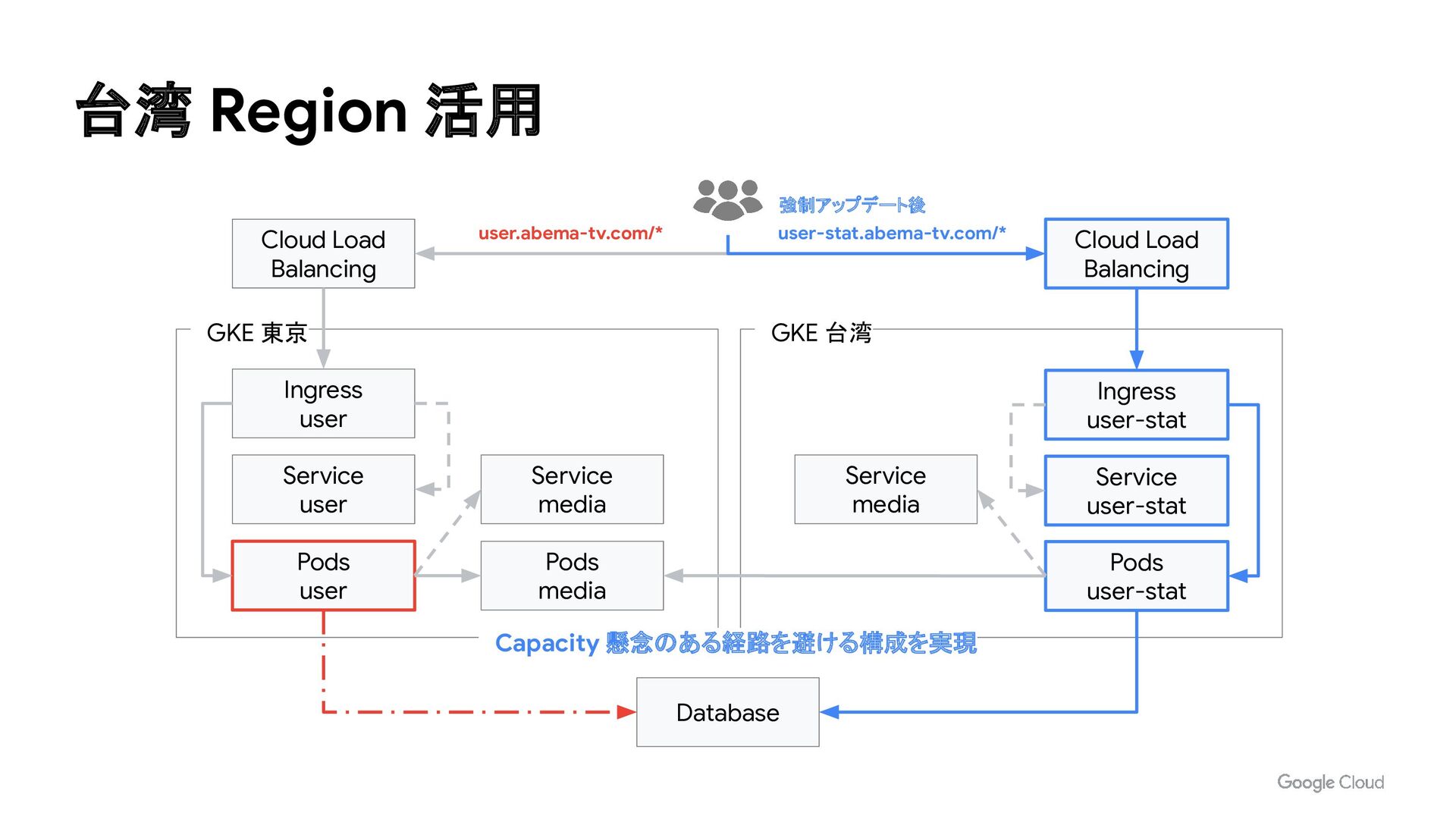
Service user Pods user Service media Pods media Database GKE 台湾 Service media Service user-stat Pods user-stat Ingress user-stat Cloud Load Balancing user.abema-tv.com/* user-stat.abema-tv.com/* Capacity 懸念のある経路を避ける構成を実現 強制アップデート後
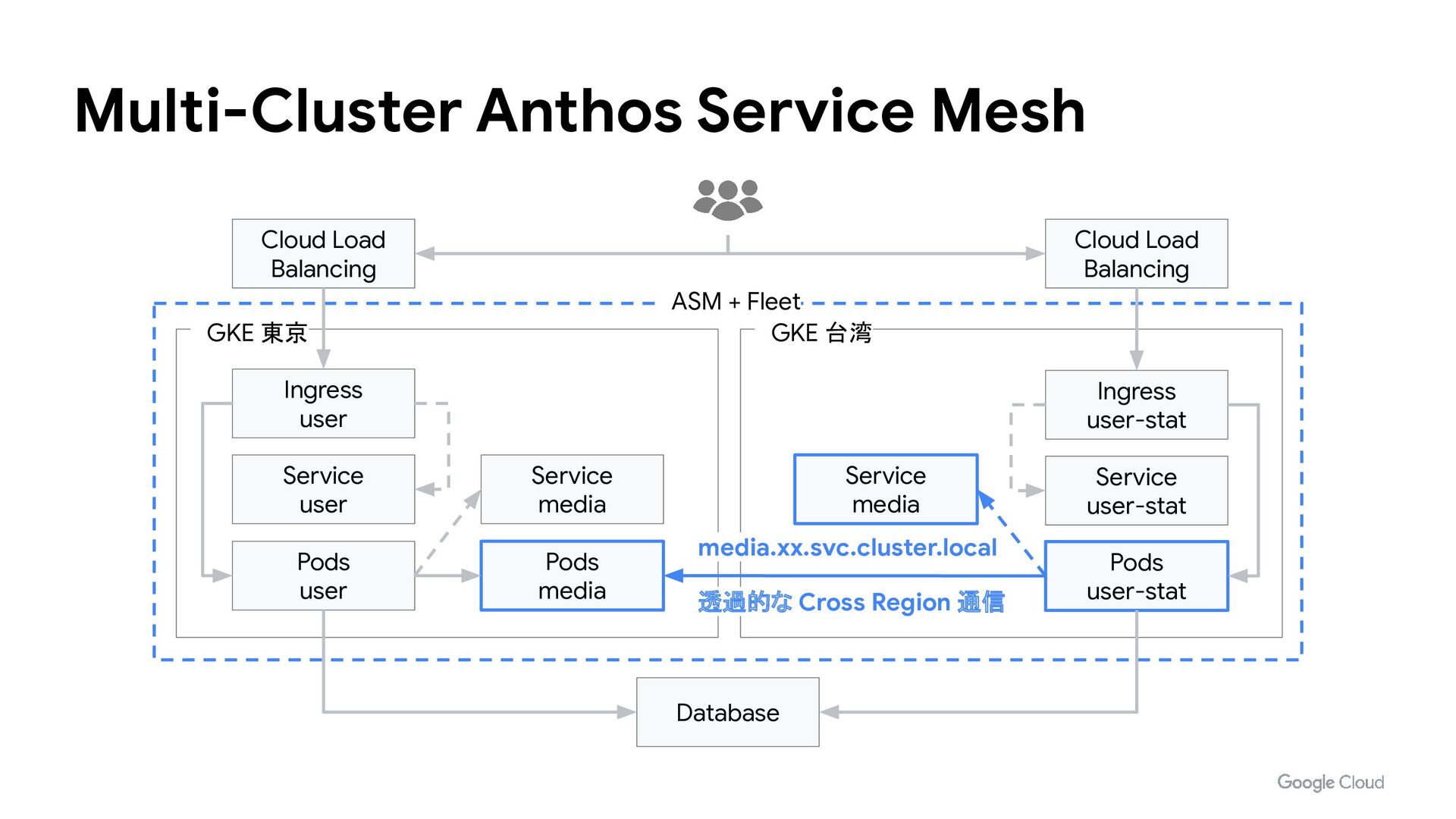
GKE 東京 Ingress user Service user Pods user Service media Pods media Database GKE 台湾 Service media Service user-stat Pods user-stat Ingress user-stat Cloud Load Balancing 透過的な Cross Region 通信 media.xx.svc.cluster.local
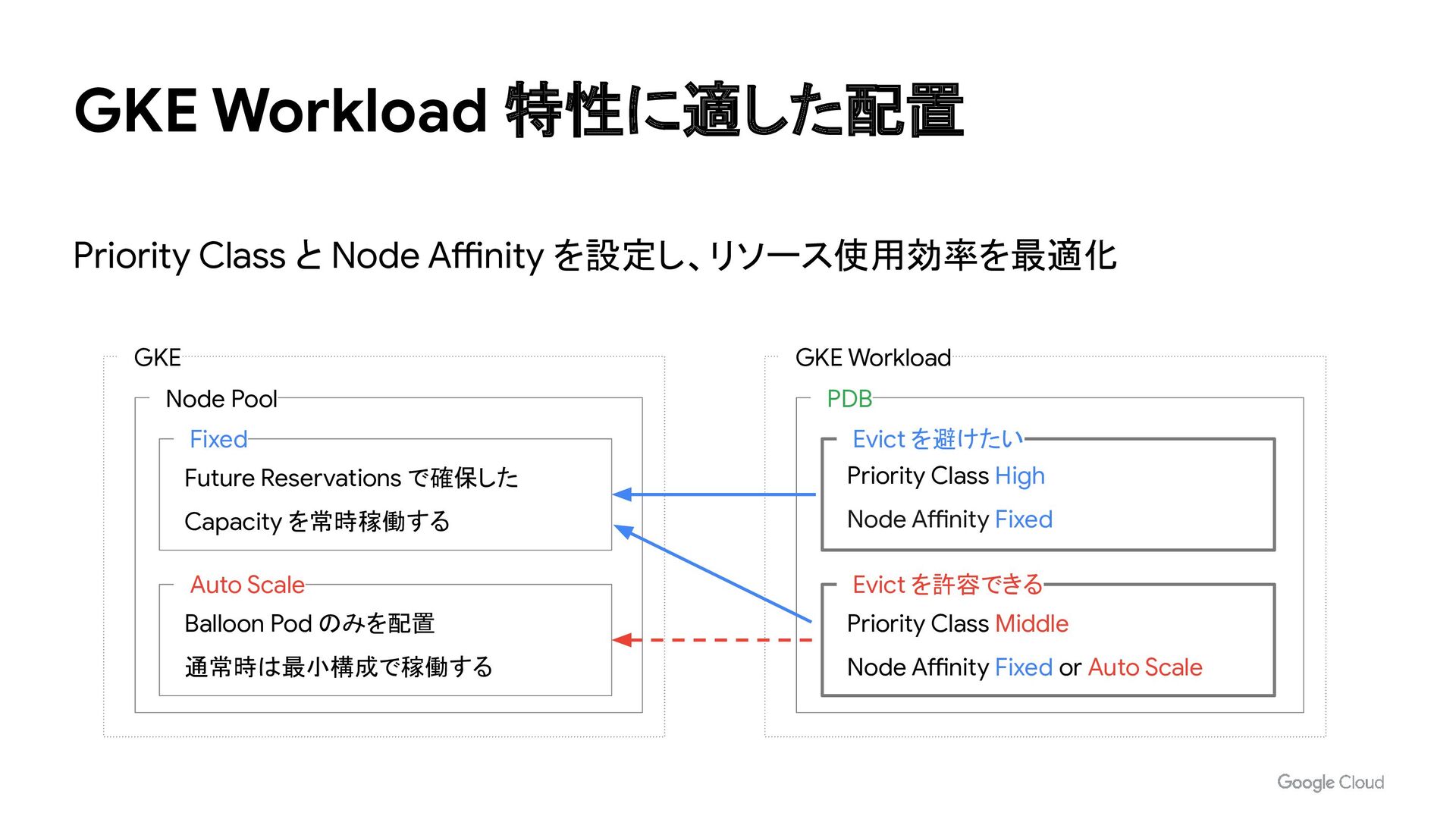
Workload GKE Node Pool Future Reservations で確保した Capacity を常時稼働する Fixed Balloon Pod のみを配置 通常時は最小構成で稼働する Auto Scale Evict を避けたい Priority Class Middle Node Affinity Fixed or Auto Scale Evict を許容できる Priority Class High Node Affinity Fixed PDB
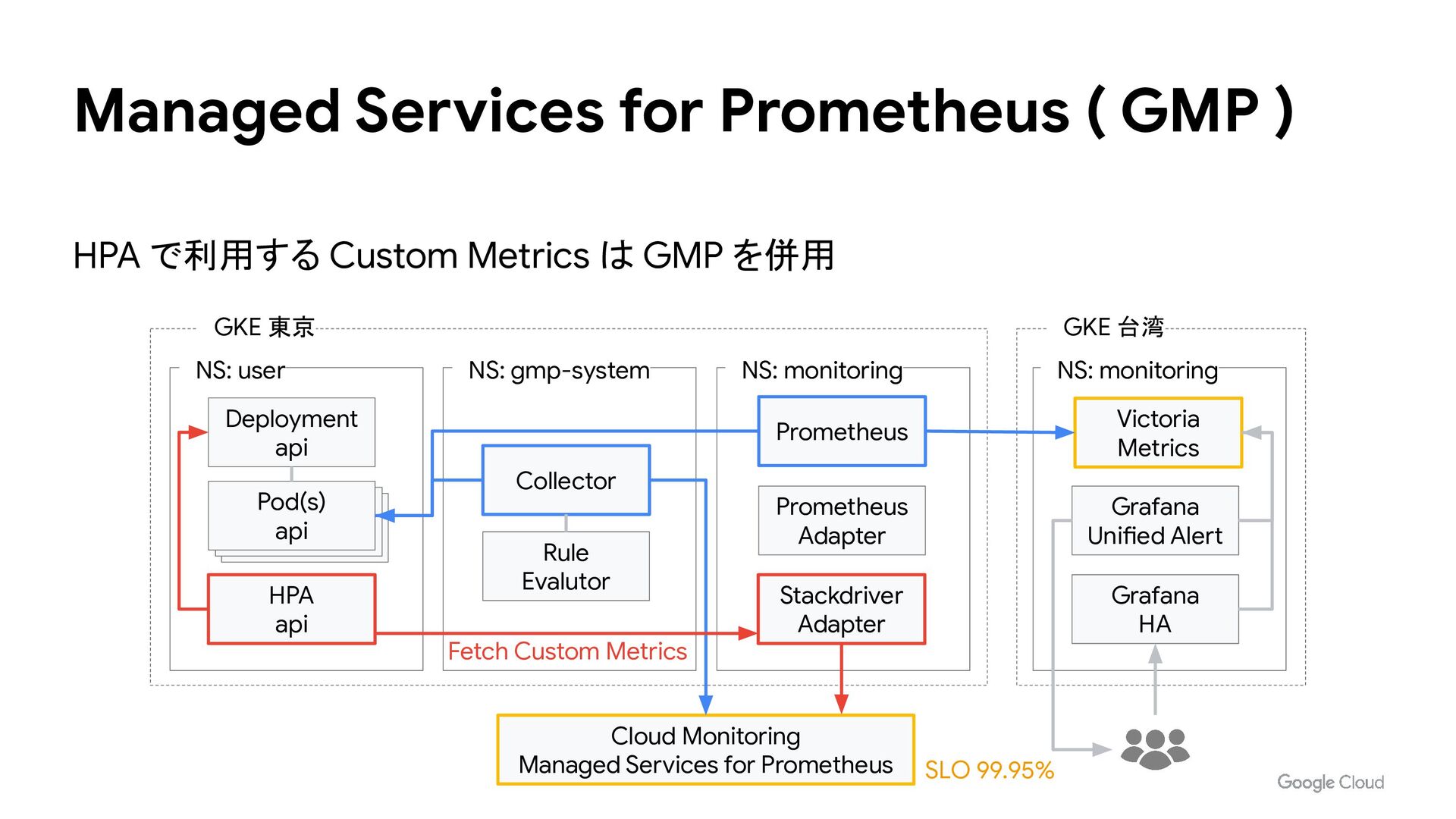
Grafana Unified Alert Victoria Metrics NS: monitoring Prometheus Prometheus Adapter HPA api Deployment api NS: user Pod(s) api Pod(s) api Pod(s) api Prometheus + Victoria Metrics Cluster Fetch Custom Metrics
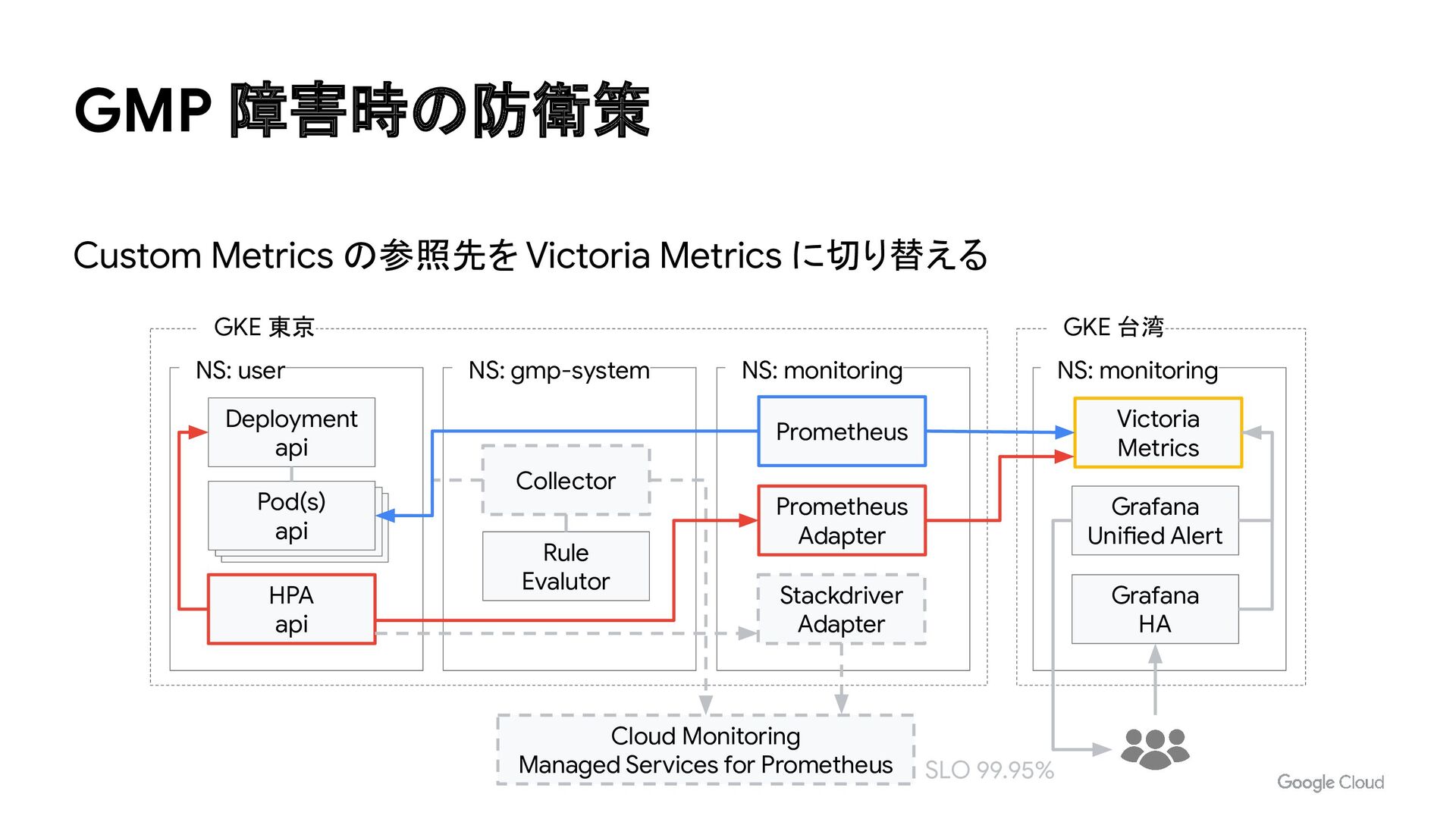
for Prometheus NS: monitoring Grafana HA Grafana Unified Alert Victoria Metrics NS: monitoring Prometheus Prometheus Adapter Stackdriver Adapter NS: gmp-system Collector Rule Evalutor HPA api Deployment api NS: user Pod(s) api Pod(s) api Pod(s) api Custom Metrics の参照先を Victoria Metrics に切り替える SLO 99.95%
{kind=link}
{kind=link}
{kind=link}
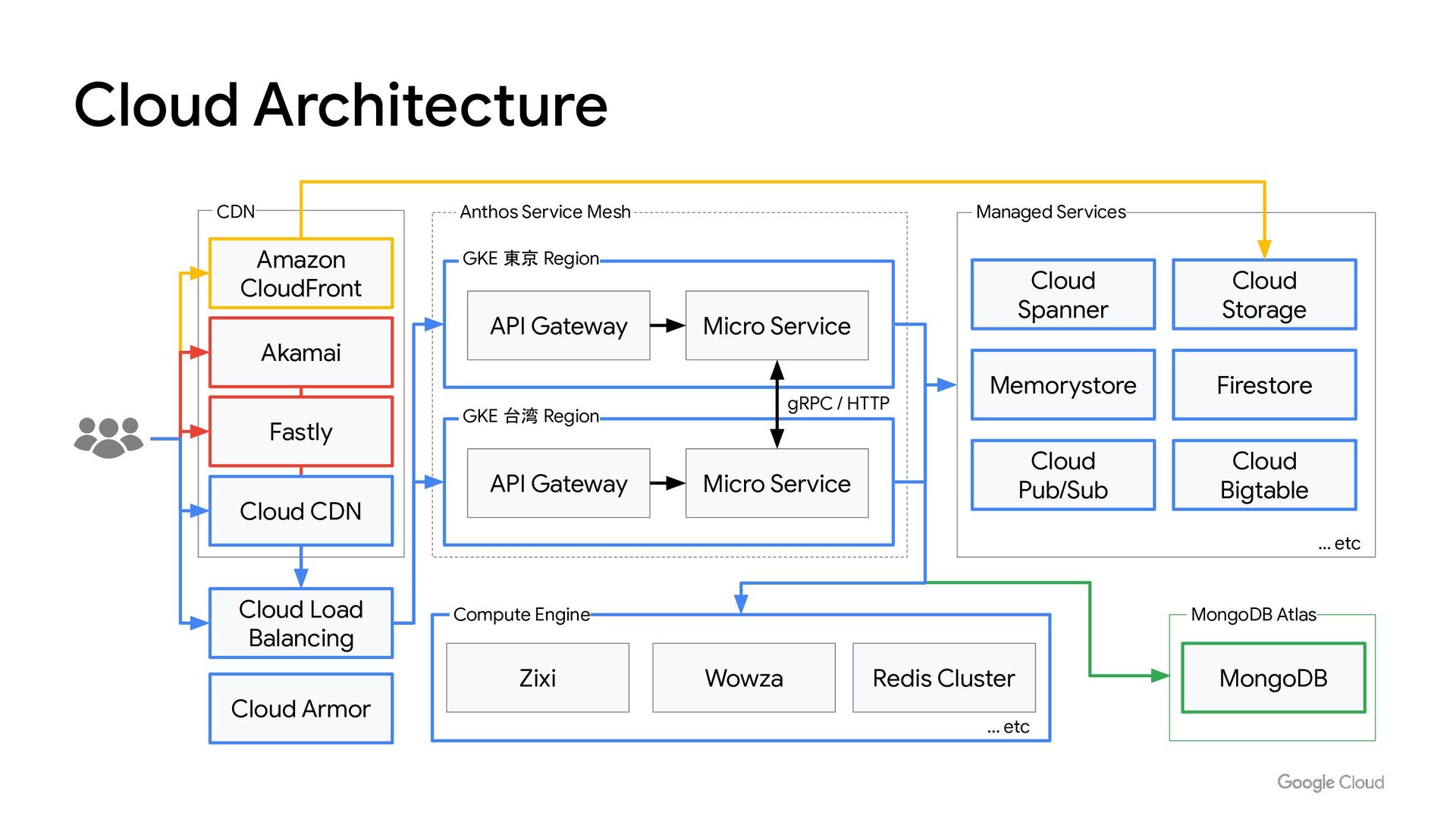{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
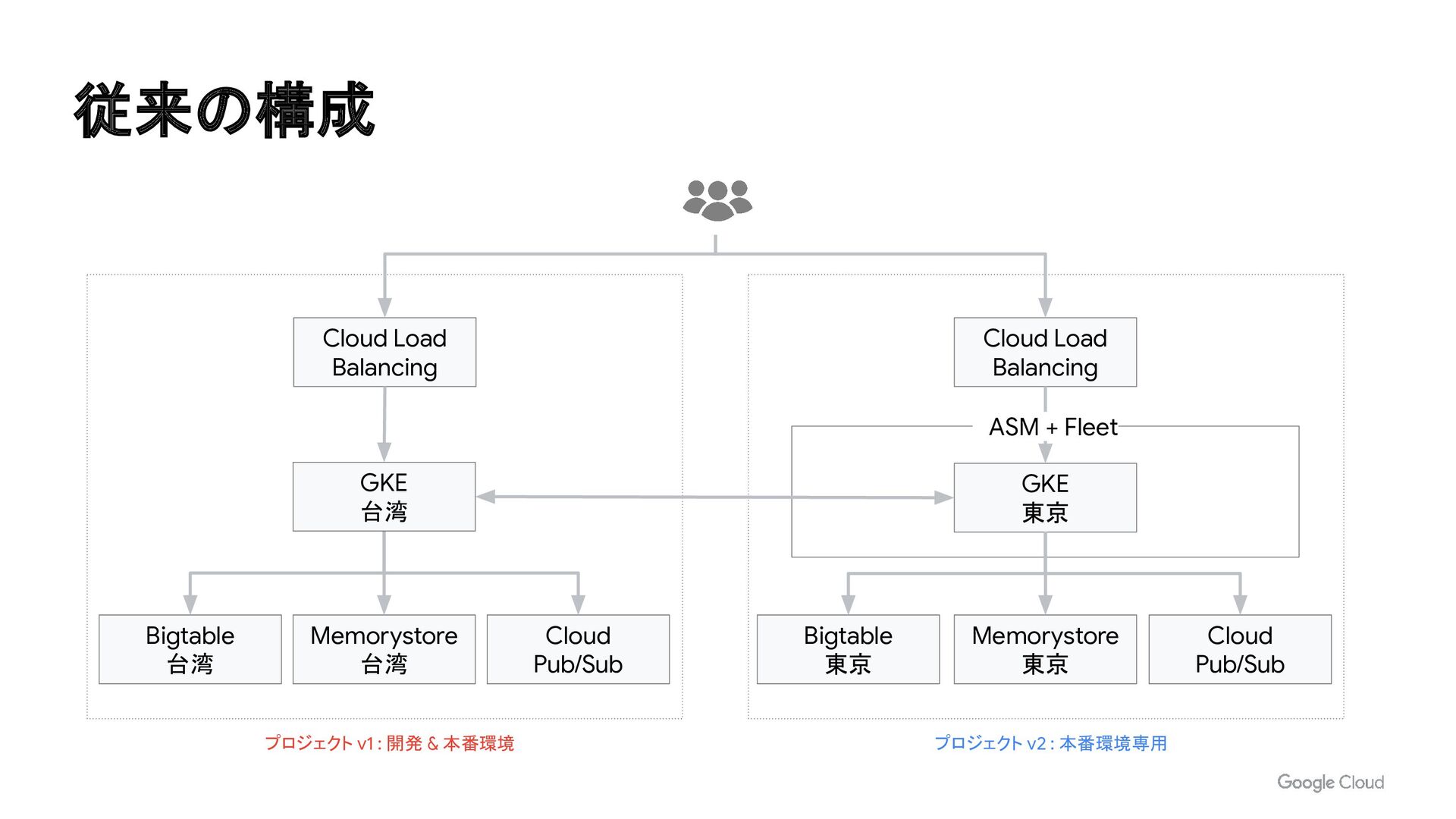{kind=link}
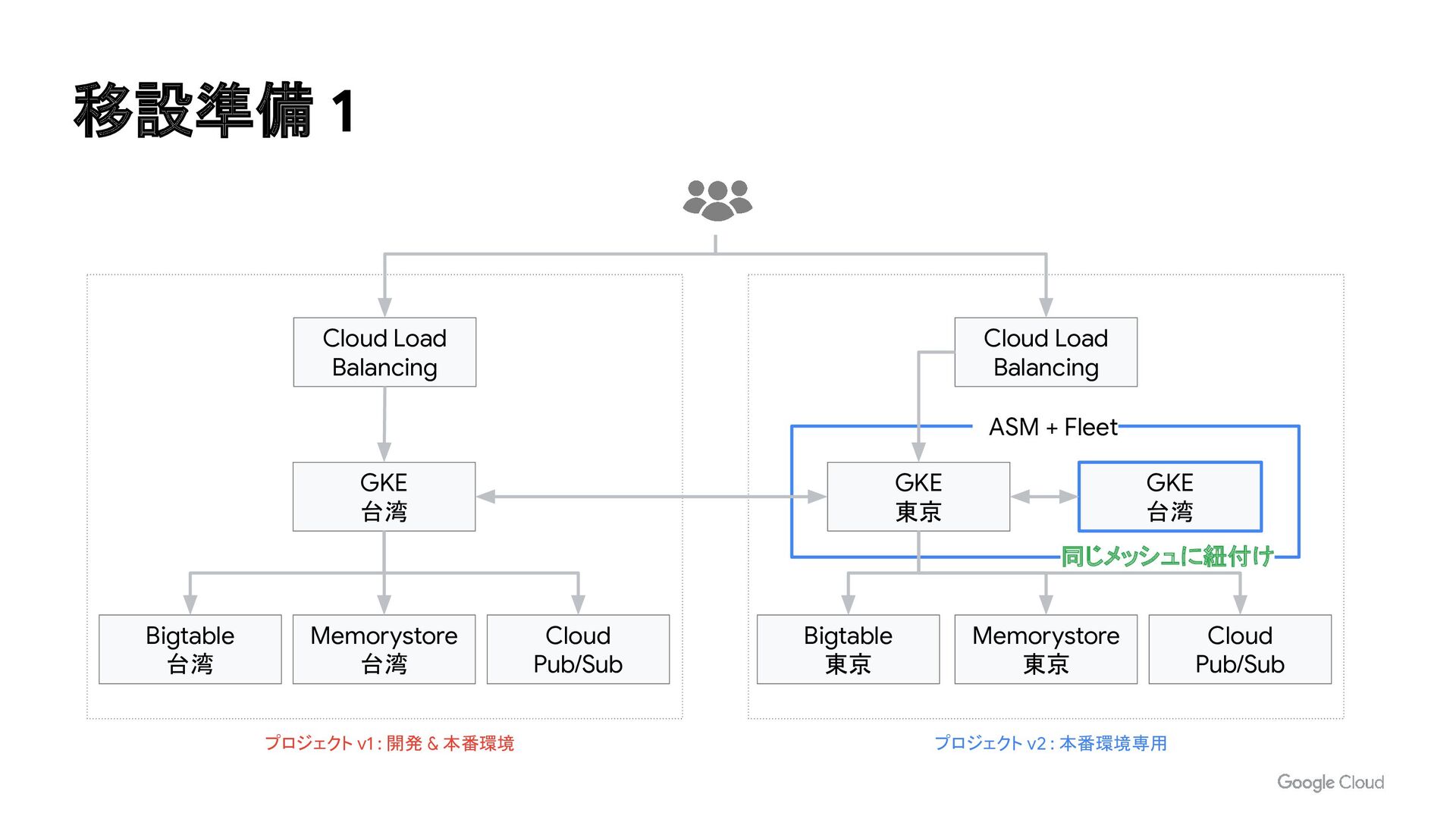{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}