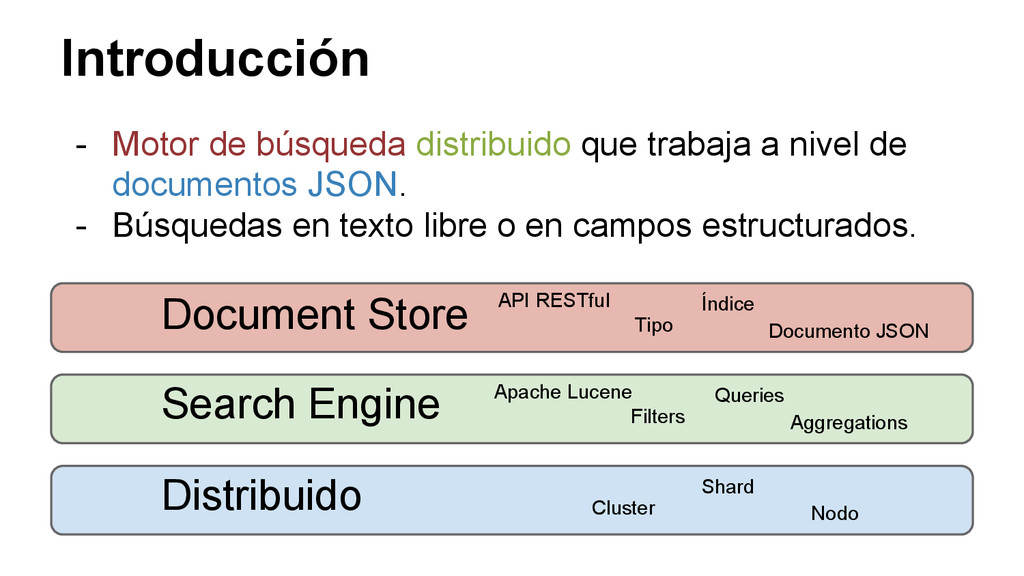
de documentos JSON. - Búsquedas en texto libre o en campos estructurados. Document Store Search Engine Distribuido Apache Lucene Filters Queries Aggregations API RESTful Tipo Documento JSON Índice Cluster Shard Nodo
de dato. - Puede verse (un poco) como una fila en un RDBMS. - Tienen un ID y un tipo asociado. - Un tipo es (un poco) como una tabla. - Se almacenan en un índice. - Un índice es (un poco!) como una base de datos. - Schema-free (casi).
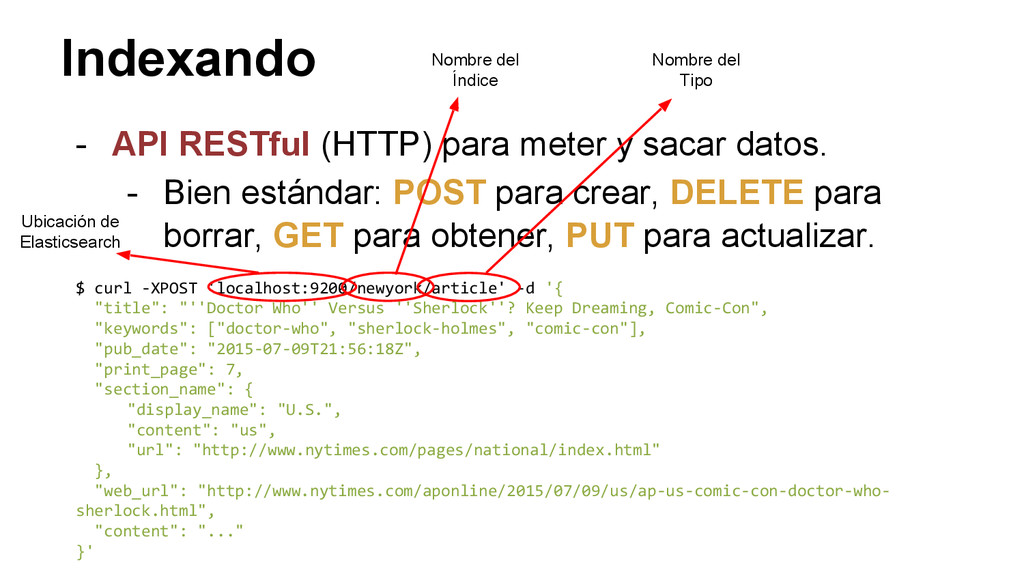
- Bien estándar: POST para crear, DELETE para borrar, GET para obtener, PUT para actualizar. $ curl -XPOST 'localhost:9200/newyork/article' -d '{ "title": "''Doctor Who'' Versus ''Sherlock''? Keep Dreaming, Comic-Con", "keywords": ["doctor-who", "sherlock-holmes", "comic-con"], "pub_date": "2015-07-09T21:56:18Z", "print_page": 7, "section_name": { "display_name": "U.S.", "content": "us", "url": "http://www.nytimes.com/pages/national/index.html" }, "web_url": "http://www.nytimes.com/aponline/2015/07/09/us/ap-us-comic-con-doctor-who- sherlock.html", "content": "..." }' Ubicación de Elasticsearch Nombre del Índice Nombre del Tipo
- ¿Y si hago esto? POST /newyork/article/ { "title": "\'Doctor Who\' Versus \'Sherlock\'? Keep Dreaming, Comic-Con", "pub_date": "nueve de julio de dos mil quince", "print_page": 7, "content": "..." } MapperParsingException[failed to parse [pub_date]] failed to parse date field Invalid format: \"nueve de julio de dos mil quince\"]
campo. - Elasticsearch no es exactamente schema-free. - Esta información se guarda en el mapping asociado al tipo. - Para consultarlo, API: - Se puede crear manual: - No se puede modificar. GET /newyork/article/_mapping POST /newyork/article/_mapping
datos almacenados. - Las consultas sobre los datos se hacen (también) con una API REST, donde la consulta es un JSON. - Se realiza un GET al endpoint /<index>/<tipo>/_search. - Ejemplo: GET /newyork/article/_search { "query": { "match_all": {} } }
en campos de texto libre. - Utilizan la librería - Almacena los campos de texto en un índice invertido. - Para hacer una búsqueda, se fija en qué documentos aparece la palabra y le calcula un puntaje (relevancia o score).
hay que procesarlo antes. - Esta tarea se llama text analysis. - Qué se hace exactamente depende del caso de uso. - Se especifica en el mapping. Stopwords: el, la, los Lowercasing: Gato vs. gato Stemming: jugando vs. jugó Synonyms: saltar vs. brincar "content": { "type": "string", "analyzer": "standard" }
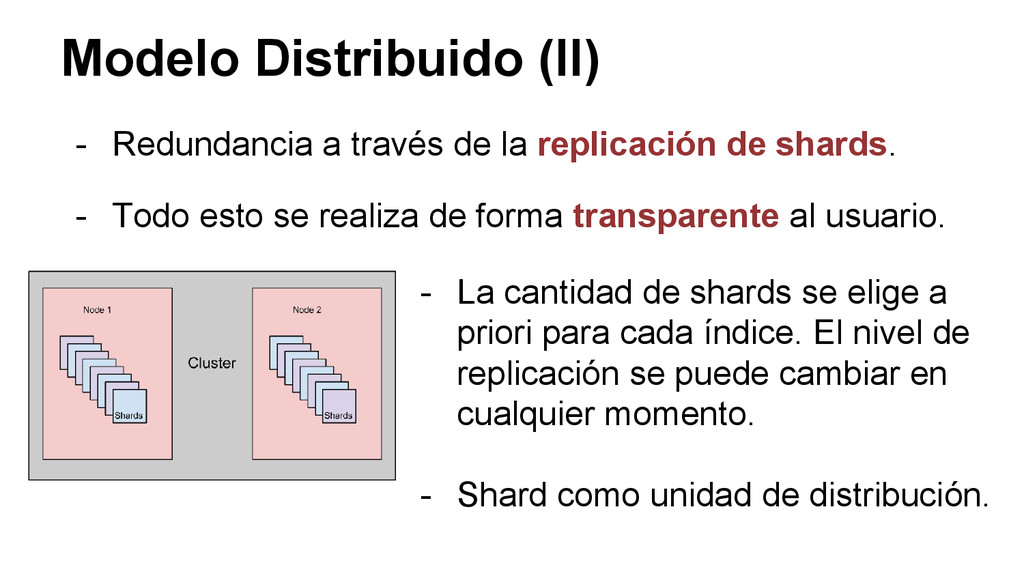
conjunto de nodos coordinados. - Brindan una única vista lógica de los datos. - Shard: subdivisión de un índice. - Ayudan a escalar horizontalmente. - Ayudan a distribuir la carga, paralelizando tareas. - Ayudan a brindar redundancia.
de shards. - Todo esto se realiza de forma transparente al usuario. - La cantidad de shards se elige a priori para cada índice. El nivel de replicación se puede cambiar en cualquier momento. - Shard como unidad de distribución.
cualquier nodo del cluster. - Consultar a los nodos necesarios, acumula el resultado, y lo devuelve al usuario. Puede elegir una réplica en lugar de un shard primario. Tiene que juntar los resultados de cada shard.
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}