a transaction log first ‣ Data structures get mutated after ‣ If a crash happens, it can recover from the log ‣ The log is the source of truth ‣ Your database is a log based data structure!
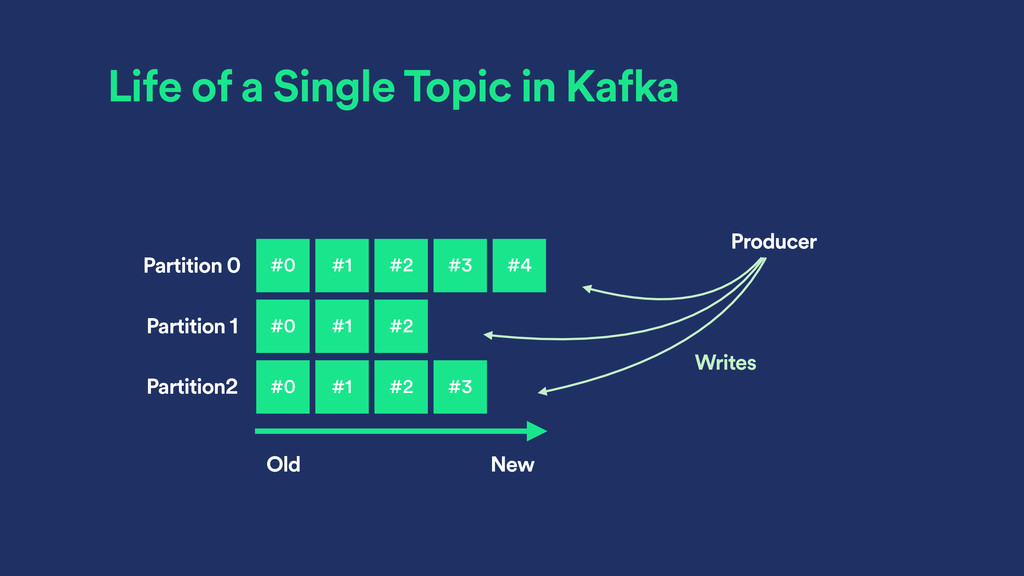
binder for logs, a feed of messages ‣ Topic maintains a partitioned log ‣ Log size is controlled by time based retention policy ‣ Logs can be compacted by key
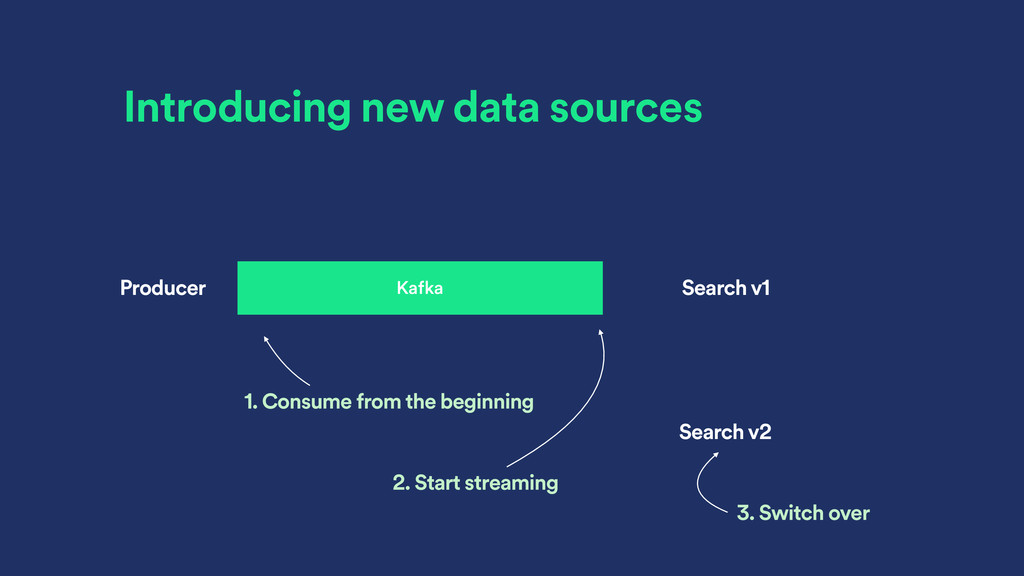
groups can consume same topic ‣ Kafka assigns partitions within the topic to consumer within the consumer group ‣ Guarantees consuming of partitions in order within the consumer group - something most other MQs don’t!
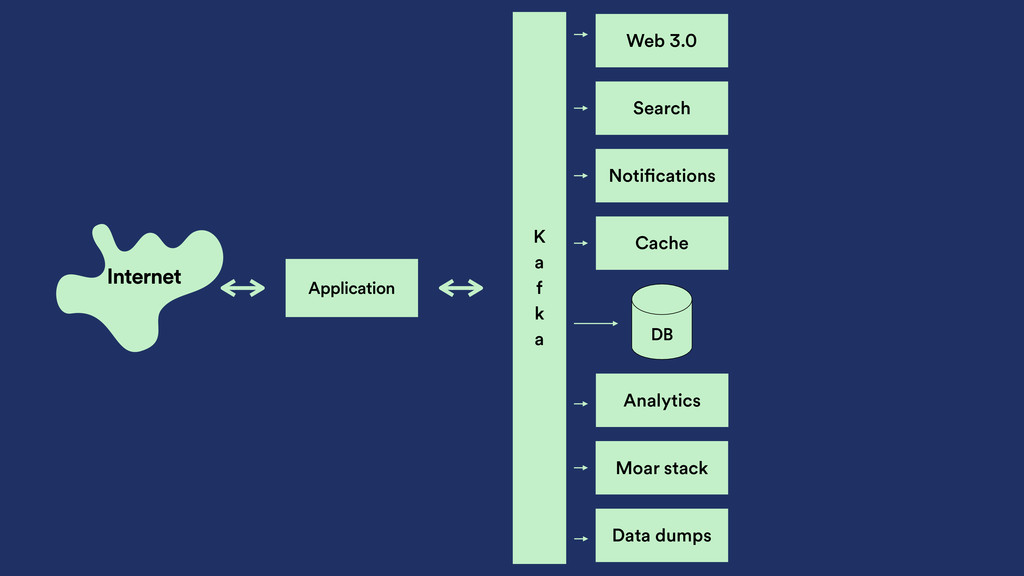
of processing ‣ Producer has full control over the partitioning within a topic ‣ Data is retained forever if wanted ‣ …or limited by time ‣ …or compacted ‣ … or all combined!
{kind=link}
{kind=link}
![Me @nailor / / [email protected]](https://files.speakerdeck.com/presentations/85e37939f94f4d2586f58dacfbe2719e/slide_2.jpg){kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
![That’s it! Thanks :) @nailor / [email protected]](https://files.speakerdeck.com/presentations/85e37939f94f4d2586f58dacfbe2719e/slide_36.jpg){kind=link}
{kind=link}