Upgrade to Pro
— share decks privately, control downloads, hide ads and more …
Speaker Deck
Features
Speaker Deck
PRO
Sign in
Sign up for free
Search
Search
情報集約×機械学習で目指す「次」がわかる運用 / OSC2019_Tokyo_Enterprise
Search
TakuyaNaito
October 10, 2019
Technology
280
0
Share
Embed
Copy iframe code
Copy JS code
Copy link
Start on current slide
情報集約×機械学習で目指す「次」がわかる運用 / OSC2019_Tokyo_Enterprise
TakuyaNaito
October 10, 2019
Other Decks in Technology
See All in Technology
「休む」重要さ
smt7174
6
1.7k
「待ち時間」の消滅と「自我消耗」の加速:生成AI時代のエンジニアを救うメンタル・リソース管理
poropinai1966
0
110
プロダクト開発組織の現在地(Ver.2026/07) / product-organization
kaonavi
0
460
大 AI 時代におけるC# の事情 ~ぶっちゃけトークを交えながら~
nenonaninu
1
180
MCPをつなげて作る組織横断のAIエージェント基盤
tsubakimoto_s
0
140
AWS環境のセキュリティ不安を解消した企業事例 ~よくある課題と対策を一挙公開~
asanoharuki
0
160
Vポイント分析基盤におけるデータモデリング20年史
taromatsui_cccmkhd
4
760
AIエージェントがあれば技術書なんてすぐ書けるでしょ→無理でした
watany
4
380
キャリアLT会#3
beli68
2
260
人とエージェントが高め合う協業設計
kintotechdev
0
870
発表と総括 / Presentations and Summary
ks91
PRO
0
200
AIが当たり前の組織で エンジニアはどう育つか
nishihira
1
1.2k
Featured
See All Featured
Done Done
chrislema
186
16k
Abbi's Birthday
coloredviolet
3
8.8k
How to Grow Your eCommerce with AI & Automation
katarinadahlin
PRO
1
230
Darren the Foodie - Storyboard
khoart
PRO
3
3.5k
sira's awesome portfolio website redesign presentation
elsirapls
0
310
Technical Leadership for Architectural Decision Making
baasie
3
440
B2B Lead Gen: Tactics, Traps & Triumph
marketingsoph
0
180
30 Presentation Tips
portentint
PRO
1
350
The Organizational Zoo: Understanding Human Behavior Agility Through Metaphoric Constructive Conversations (based on the works of Arthur Shelley, Ph.D)
kimpetersen
PRO
0
390
A Guide to Academic Writing Using Generative AI - A Workshop
ks91
PRO
1
360
No one is an island. Learnings from fostering a developers community.
thoeni
21
3.8k
How to optimise 3,500 product descriptions for ecommerce in one day using ChatGPT
katarinadahlin
PRO
1
3.7k
Transcript
情報集約 x 機械学習で目指す 「次」がわかる運用 TIS株式会社 内藤 拓也 2019/10/10 オープンソースカンファレンス 2019
.Enterprise
自己紹介 内藤 拓也 TIS株式会社 IT基盤エンジニアリング第1部 氏名: 所属: 業務: ~5月 インフラ構築・移行・保守運用等
5月~ 運用レコメンドプラットフォーム開発 Python, React , Docker, 等 技術要素:
1. 保守運用作業をもっとうまくやるには 2. 運用レコメンドプラットフォーム紹介 3. まとめとお願い アジェンダ
保守運用作業もっとうまくやるには (自動化、効率化、脱属人化…)
- アップデート - 設定変更 - 障害調査・対応 … - ツールの導入 -
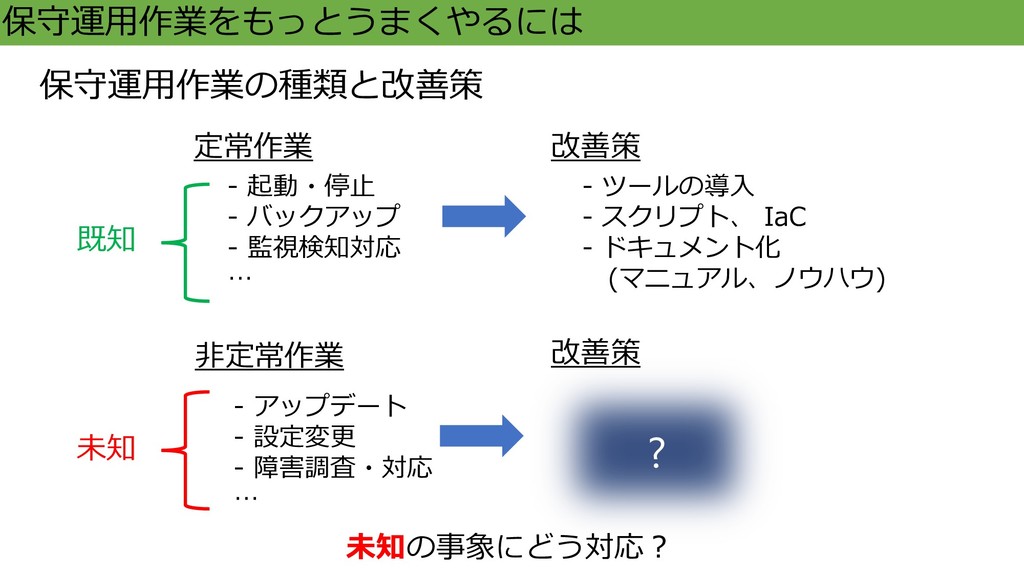
スクリプト、 IaC - ドキュメント化 (マニュアル、ノウハウ) 定常作業 - 起動・停止 - バックアップ - 監視検知対応 … 非定常作業 改善策 未知の事象にどう対応? ? 保守運用作業をもっとうまくやるには 既知 未知 保守運用作業の種類と改善策 改善策
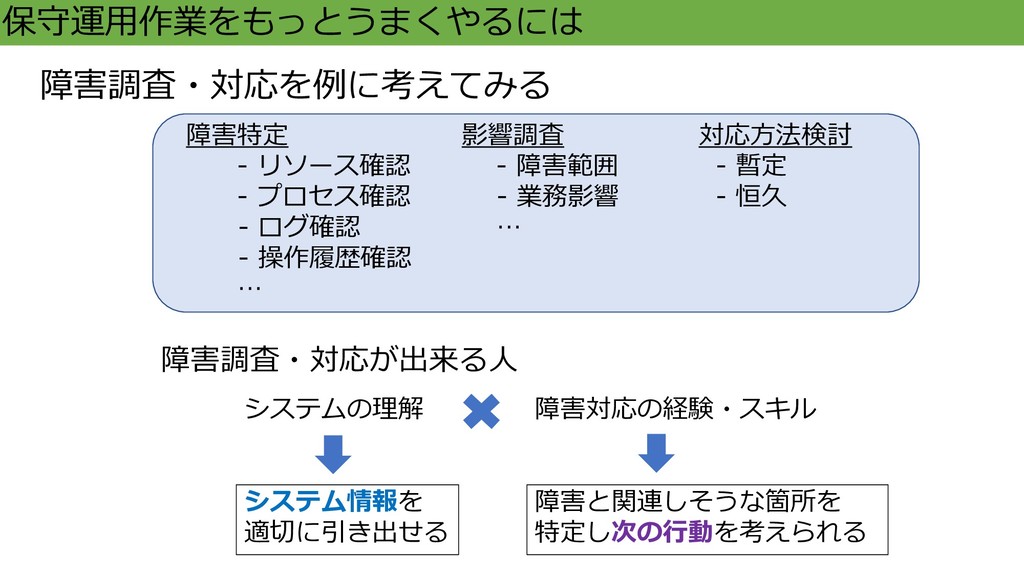
保守運用作業をもっとうまくやるには 障害調査・対応を例に考えてみる 障害特定 - リソース確認 - プロセス確認 - ログ確認 -
操作履歴確認 … 影響調査 - 障害範囲 - 業務影響 … 対応方法検討 - 暫定 - 恒久 障害調査・対応が出来る人 システムの理解 障害対応の経験・スキル システム情報を 適切に引き出せる 障害と関連しそうな箇所を 特定し次の行動を考えられる
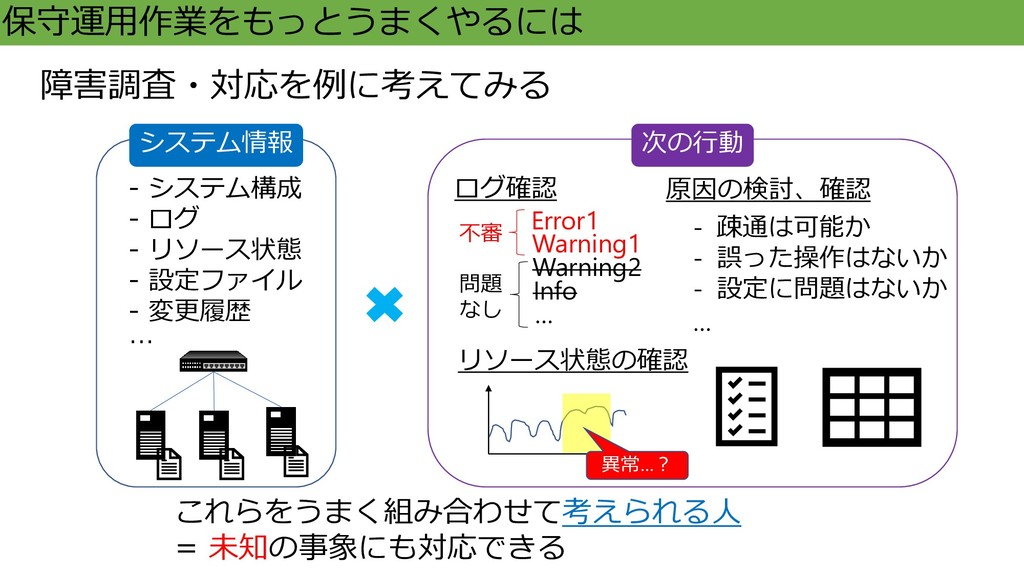
保守運用作業をもっとうまくやるには - システム構成 - ログ - リソース状態 - 設定ファイル -
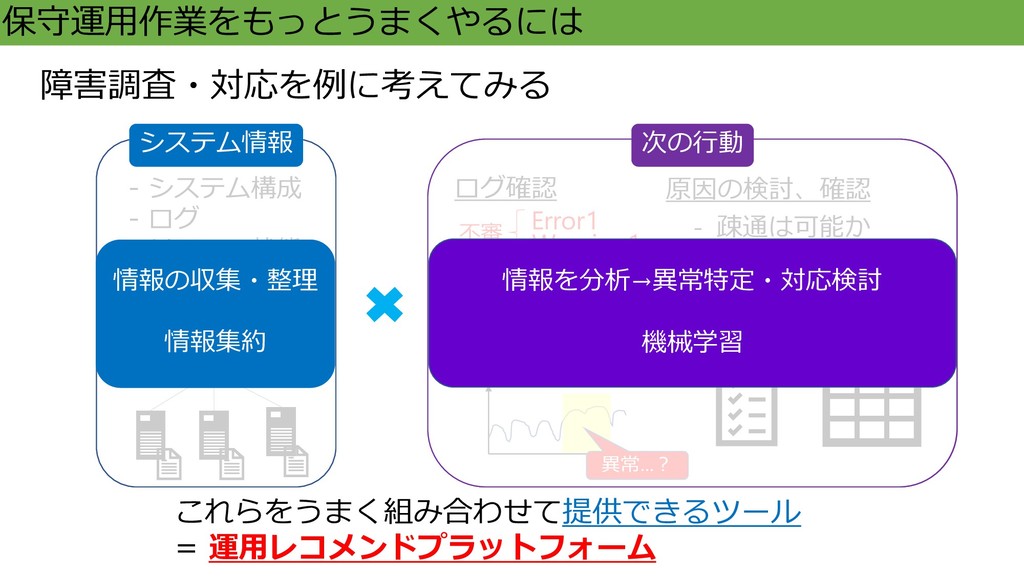
変更履歴 … 原因の検討、確認 ログ確認 Error1 Warning1 Warning2 Info … リソース状態の確認 - 疎通は可能か - 誤った操作はないか - 設定に問題はないか … 障害調査・対応を例に考えてみる システム情報 次の行動 これらをうまく組み合わせて考えられる人 = 未知の事象にも対応できる 不審 異常…? 問題 なし
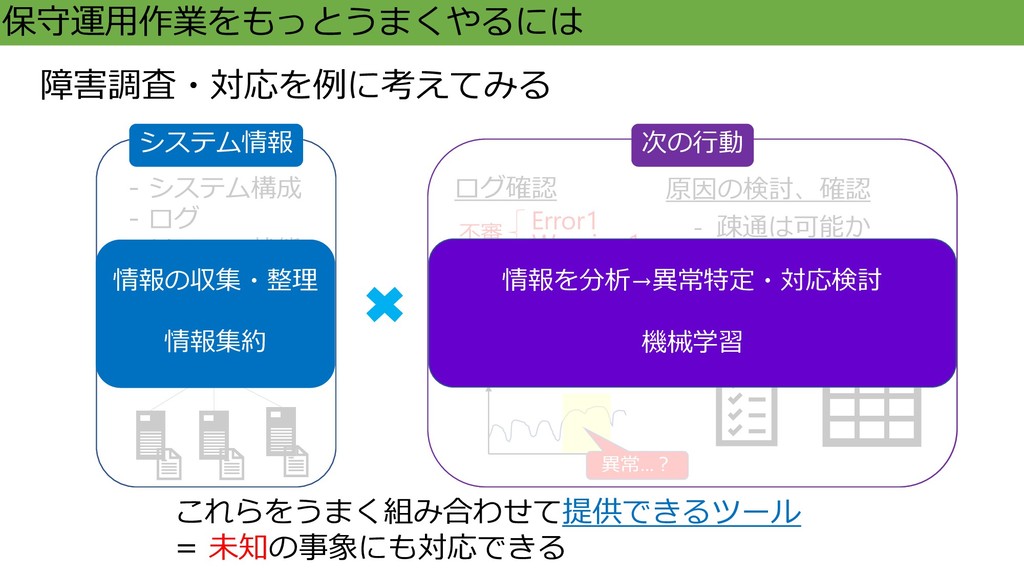
保守運用作業をもっとうまくやるには - システム構成 - ログ - リソース状態 - 設定ファイル -
変更履歴 … 原因の検討、確認 ログ確認 Error1 Warning1 Warning2 Info … リソース状態の確認 - 疎通は可能か - 誤った操作はないか - 設定に問題はないか … 障害調査・対応を例に考えてみる これらをうまく組み合わせて提供できるツール = 未知の事象にも対応できる 不審 異常…? 問題 なし システム情報 情報の収集・整理 情報集約 情報を分析→異常特定・対応検討 機械学習 次の行動
保守運用作業をもっとうまくやるには - システム構成 - ログ - リソース状態 - 設定ファイル -
変更履歴 … 原因の検討、確認 ログ確認 Error1 Warning1 Warning2 Info … リソース状態の確認 - 疎通は可能か - 誤った操作はないか - 設定に問題はないか … 障害調査・対応を例に考えてみる これらをうまく組み合わせて提供できるツール = 運用レコメンドプラットフォーム 不審 異常…? 問題 なし システム情報 情報の収集・整理 情報集約 情報を分析→異常特定・対応検討 機械学習 次の行動
2. 運用レコメンドプラットフォーム紹介
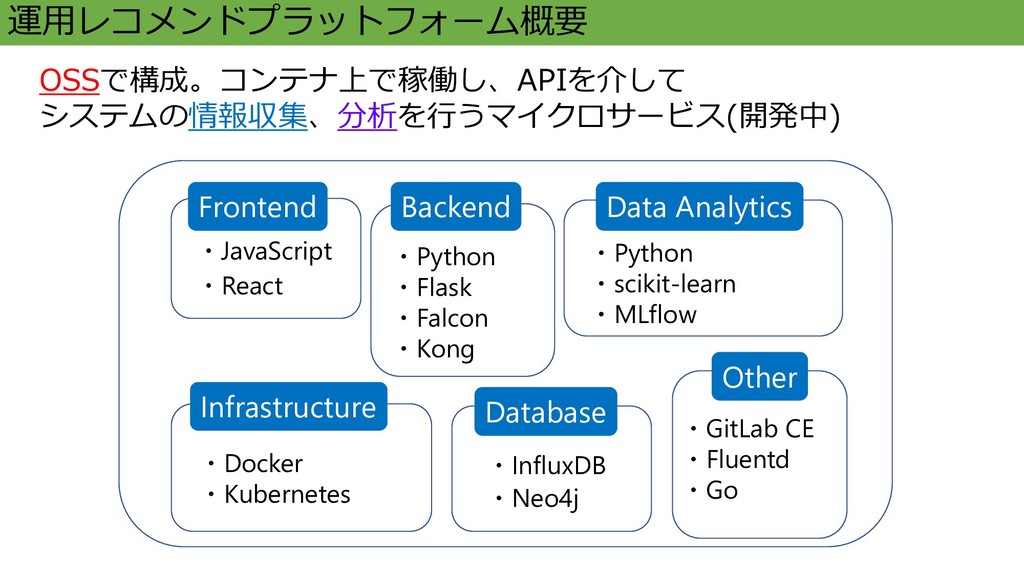
運用レコメンドプラットフォーム概要 OSSで構成。コンテナ上で稼働し、APIを介して システムの情報収集、分析を行うマイクロサービス(開発中) Backend Frontend Data Analytics ・InfluxDB Database ・Neo4j
・Docker ・Kubernetes Infrastructure Other ・GitLab CE ・Fluentd ・Go ・Python ・Flask ・Falcon ・Kong ・JavaScript ・React ・Python ・scikit-learn ・MLflow
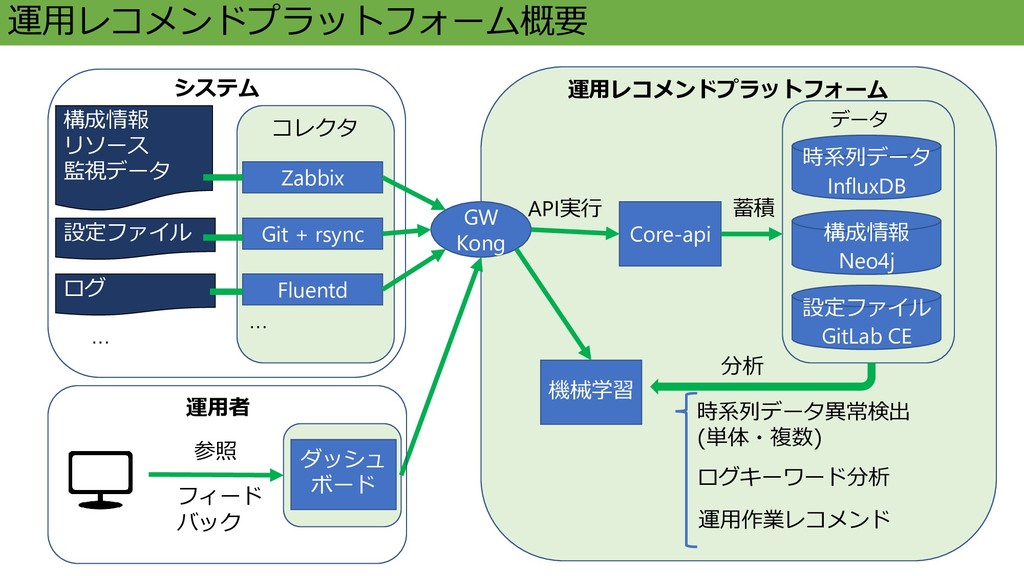
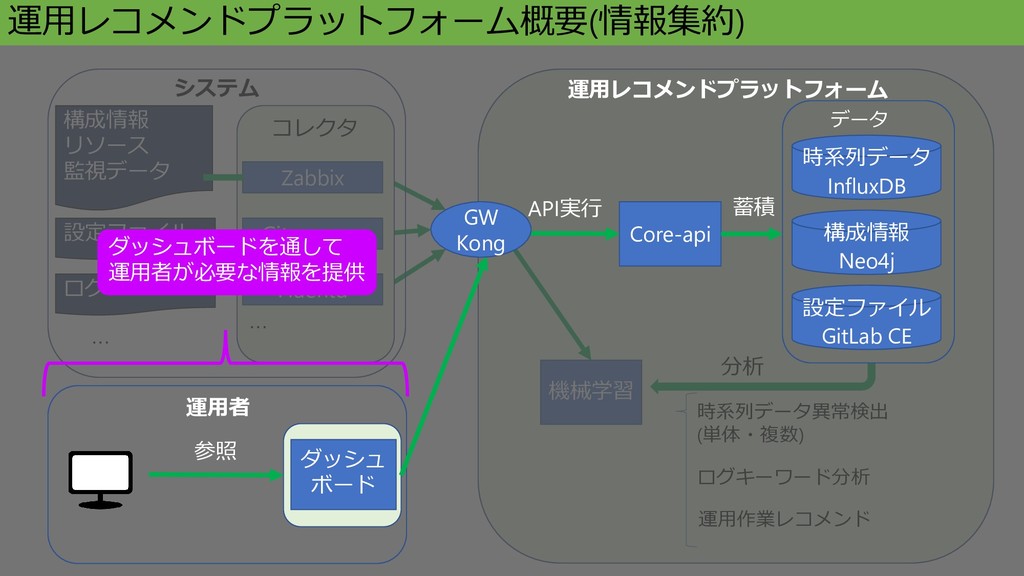
Core-api 構成情報 Neo4j ダッシュ ボード 参照 データ システム 時系列データ InfluxDB
運用者 コレクタ … Zabbix Git + rsync Fluentd 設定ファイル GitLab CE GW Kong 機械学習 時系列データ異常検出 (単体・複数) ログキーワード分析 運用作業レコメンド … 運用レコメンドプラットフォーム概要 API実行 蓄積 分析 設定ファイル 構成情報 リソース 監視データ ログ フィード バック 運用レコメンドプラットフォーム
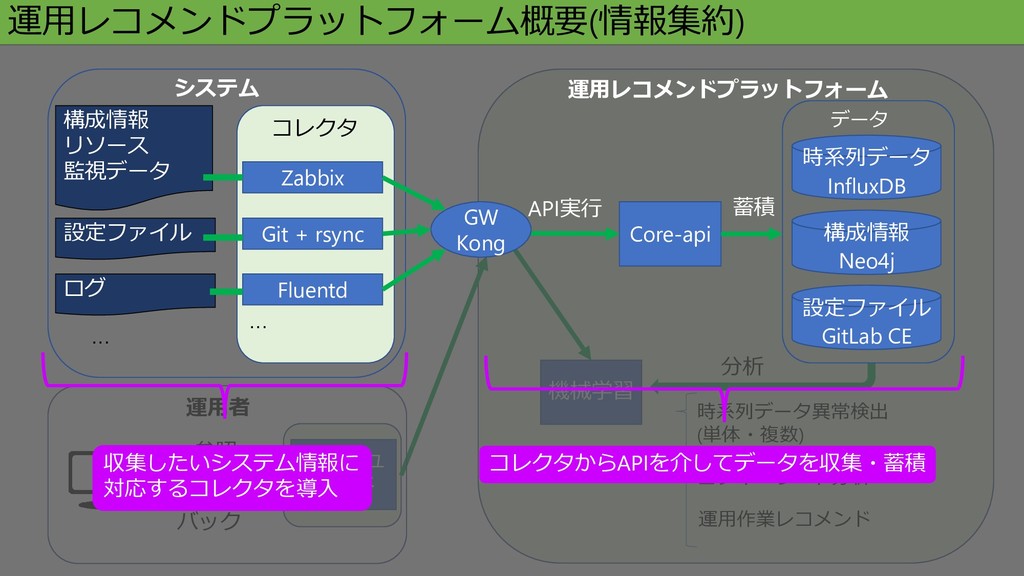
ダッシュ ボード 参照 運用者 機械学習 時系列データ異常検出 (単体・複数) ログキーワード分析 運用作業レコメンド 運用レコメンドプラットフォーム概要(情報集約)
分析 フィード バック システム コレクタ … Zabbix Git + rsync Fluentd … 設定ファイル 構成情報 リソース 監視データ ログ Core-api API実行 構成情報 Neo4j データ 時系列データ InfluxDB 設定ファイル GitLab CE 蓄積 運用レコメンドプラットフォーム 収集したいシステム情報に 対応するコレクタを導入 コレクタからAPIを介してデータを収集・蓄積 GW Kong
システム コレクタ … Zabbix Git + rsync Fluentd … 設定ファイル
構成情報 リソース 監視データ ログ 機械学習 時系列データ異常検出 (単体・複数) ログキーワード分析 運用作業レコメンド 運用レコメンドプラットフォーム概要(情報集約) 分析 Core-api API実行 構成情報 Neo4j データ 時系列データ InfluxDB 設定ファイル GitLab CE 蓄積 運用レコメンドプラットフォーム ダッシュ ボード 参照 運用者 ダッシュボードを通して 運用者が必要な情報を提供 GW Kong
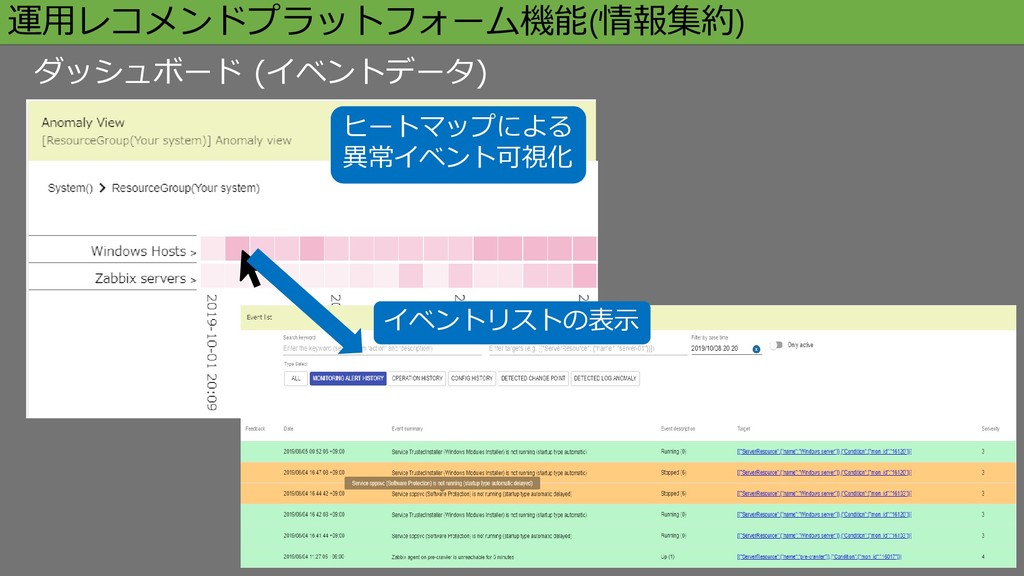
ダッシュボード (イベントデータ) 運用レコメンドプラットフォーム機能(情報集約) ヒートマップによる 異常イベント可視化 イベントリストの表示
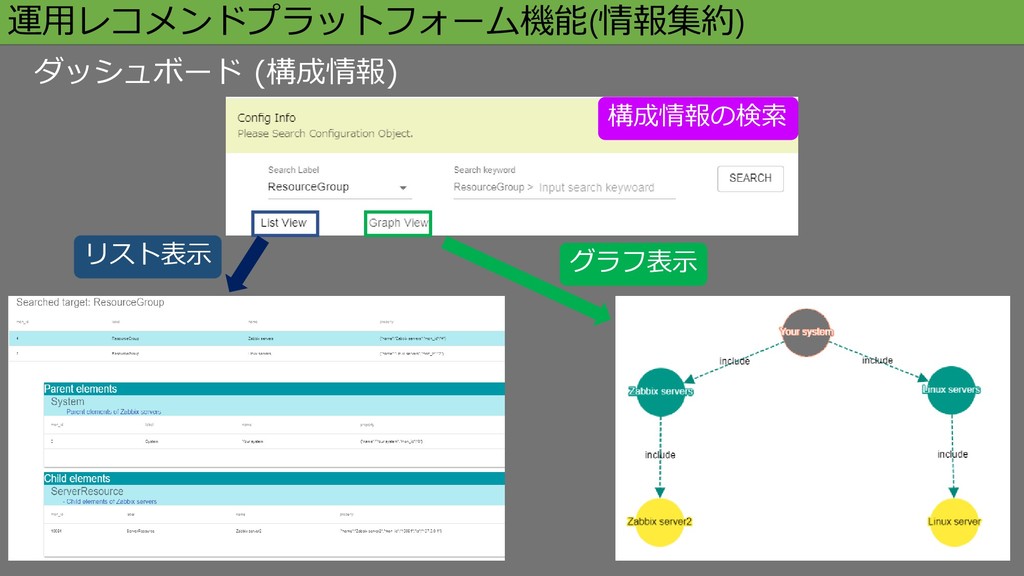
運用レコメンドプラットフォーム機能(情報集約) ダッシュボード (構成情報) 構成情報の検索 リスト表示 グラフ表示
運用レコメンドプラットフォーム機能(情報集約) ダッシュボード (監視データ) 構成情報
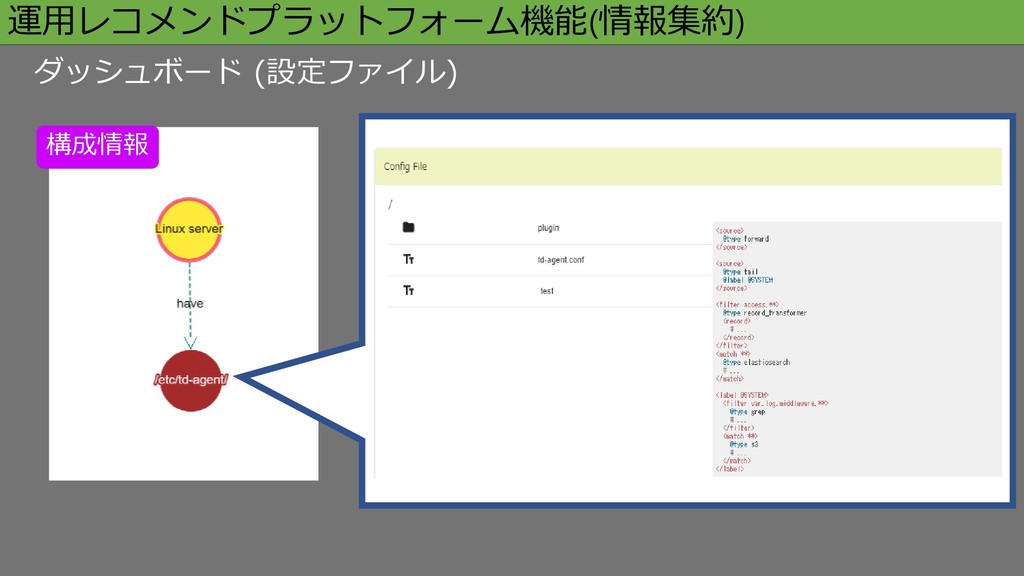
運用レコメンドプラットフォーム機能(情報集約) ダッシュボード (設定ファイル) 構成情報
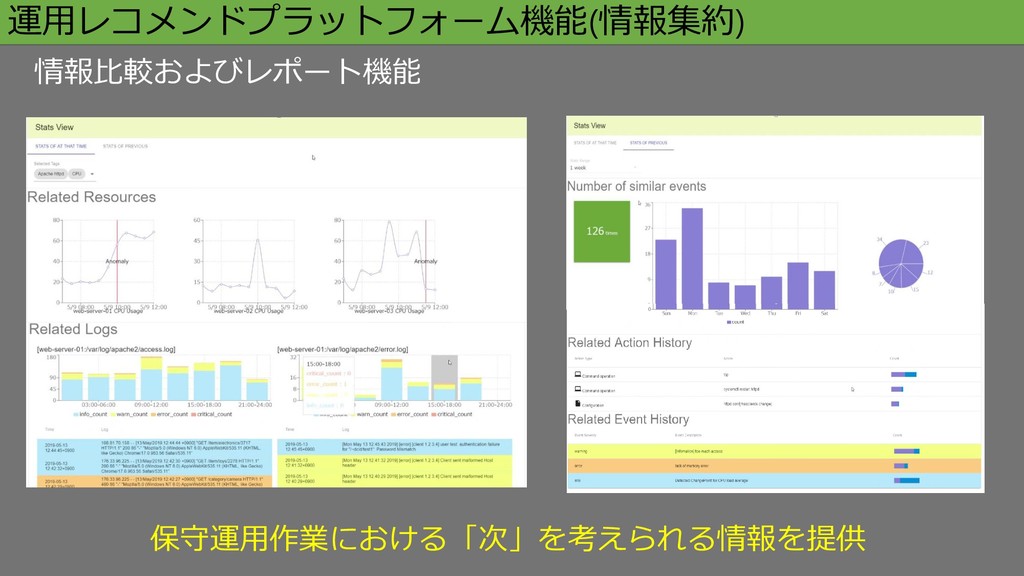
運用レコメンドプラットフォーム機能(情報集約) 情報比較およびレポート機能 保守運用作業における「次」を考えられる情報を提供
Core-api 構成情報 Neo4j ダッシュ ボード 参照 データ システム 時系列データ InfluxDB
運用者 コレクタ … Zabbix Git + rsync Fluentd 設定ファイル GitLab CE GW Kong 機械学習 時系列データ異常検出 (単体・複数) ログキーワード分析 運用作業レコメンド … 運用レコメンドプラットフォーム概要 API実行 蓄積 分析 設定ファイル 構成情報 リソース 監視データ ログ フィード バック 運用レコメンドプラットフォーム
システム コレクタ … Zabbix Git + rsync Fluentd … 設定ファイル
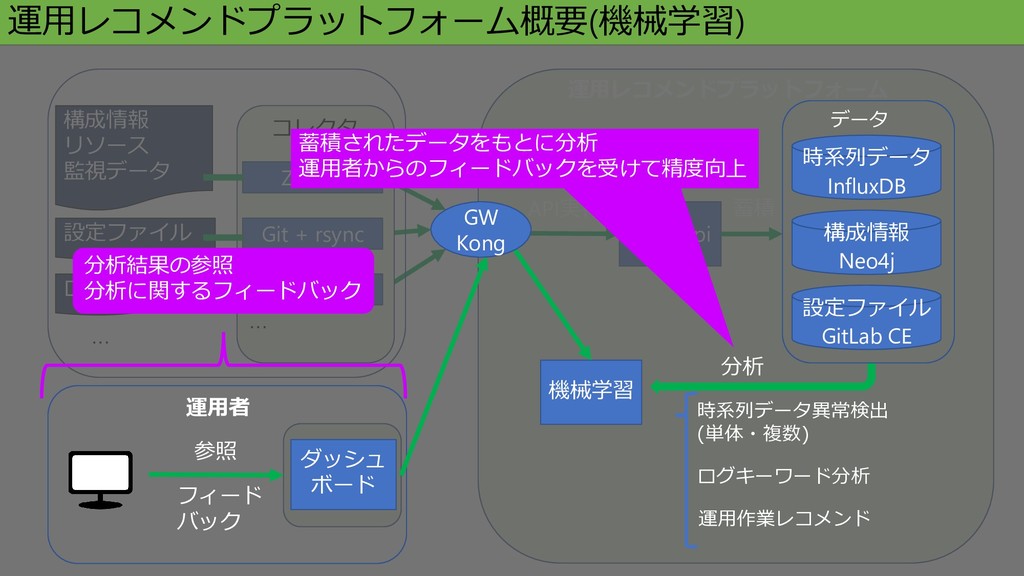
構成情報 リソース 監視データ ログ 運用レコメンドプラットフォーム概要(機械学習) Core-api API実行 蓄積 運用レコメンドプラットフォーム ダッシュ ボード 参照 運用者 フィード バック 機械学習 時系列データ異常検出 (単体・複数) ログキーワード分析 運用作業レコメンド 分析 分析結果の参照 分析に関するフィードバック 構成情報 Neo4j データ 時系列データ InfluxDB 設定ファイル GitLab CE 蓄積されたデータをもとに分析 運用者からのフィードバックを受けて精度向上 GW Kong
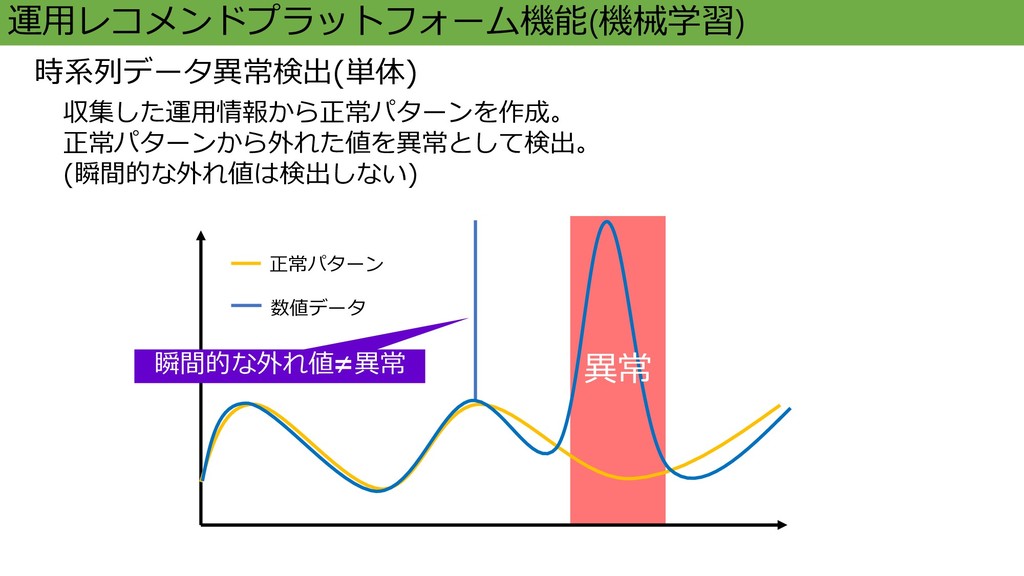
正常パターン 数値データ 収集した運用情報から正常パターンを作成。 正常パターンから外れた値を異常として検出。 (瞬間的な外れ値は検出しない) 運用レコメンドプラットフォーム機能(機械学習) 時系列データ異常検出(単体) 瞬間的な外れ値≠異常 異常
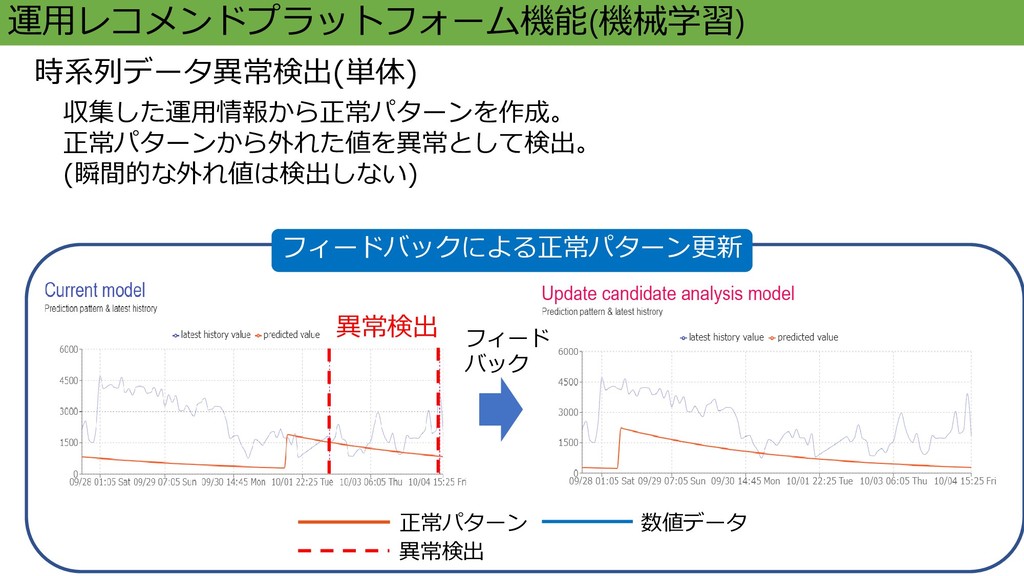
運用レコメンドプラットフォーム機能(機械学習) 収集した運用情報から正常パターンを作成。 正常パターンから外れた値を異常として検出。 (瞬間的な外れ値は検出しない) 時系列データ異常検出(単体) 正常パターン 数値データ フィードバックによる正常パターン更新 異常検出 異常検出
フィード バック
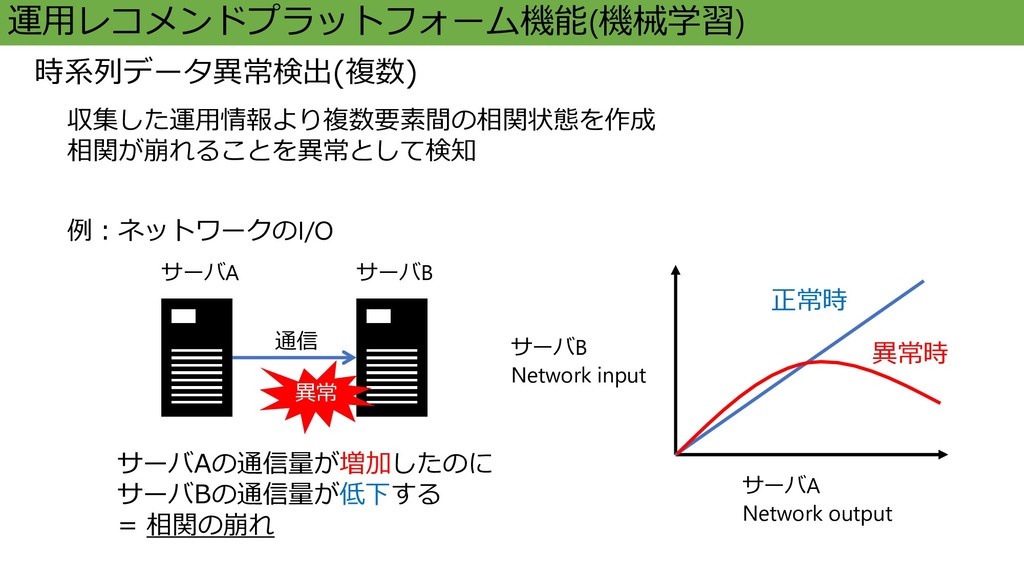
収集した運用情報より複数要素間の相関状態を作成 相関が崩れることを異常として検知 通信 例:ネットワークのI/O 運用レコメンドプラットフォーム機能(機械学習) 時系列データ異常検出(複数) サーバAの通信量が増加すれば サーバBの通信量も増加する = 正の相関
正常時 サーバA サーバB サーバA Network output サーバB Network input
収集した運用情報より複数要素間の相関状態を作成 相関が崩れることを異常として検知 サーバA サーバB 通信 運用レコメンドプラットフォーム機能(機械学習) 時系列データ異常検出(複数) 異常 正常時 異常時
サーバAの通信量が増加したのに サーバBの通信量が低下する = 相関の崩れ 例:ネットワークのI/O サーバA Network output サーバB Network input
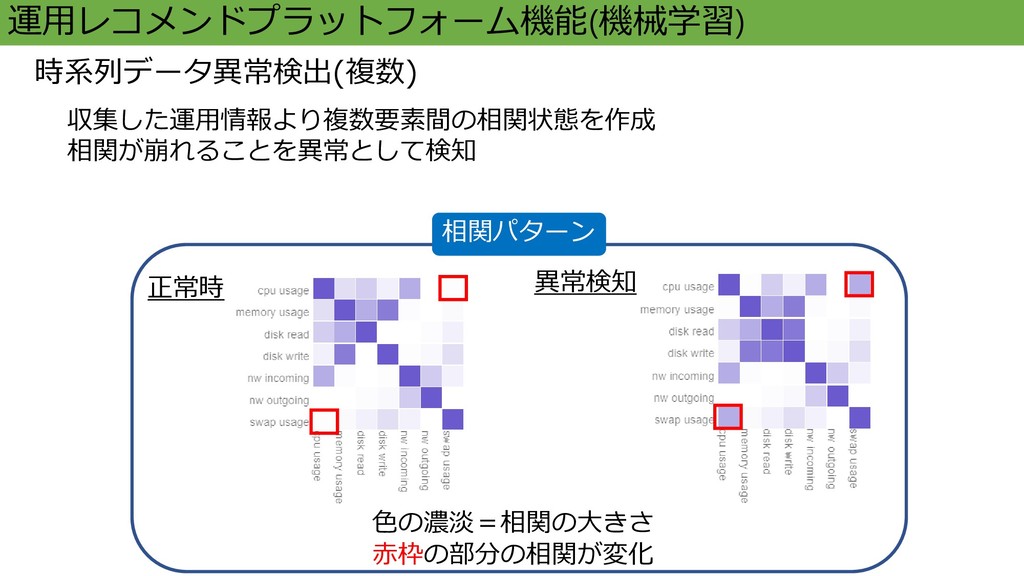
正常時 異常検知 運用レコメンドプラットフォーム機能(機械学習) 時系列データ異常検出(複数) 収集した運用情報より複数要素間の相関状態を作成 相関が崩れることを異常として検知 相関パターン 色の濃淡=相関の大きさ 赤枠の部分の相関が変化
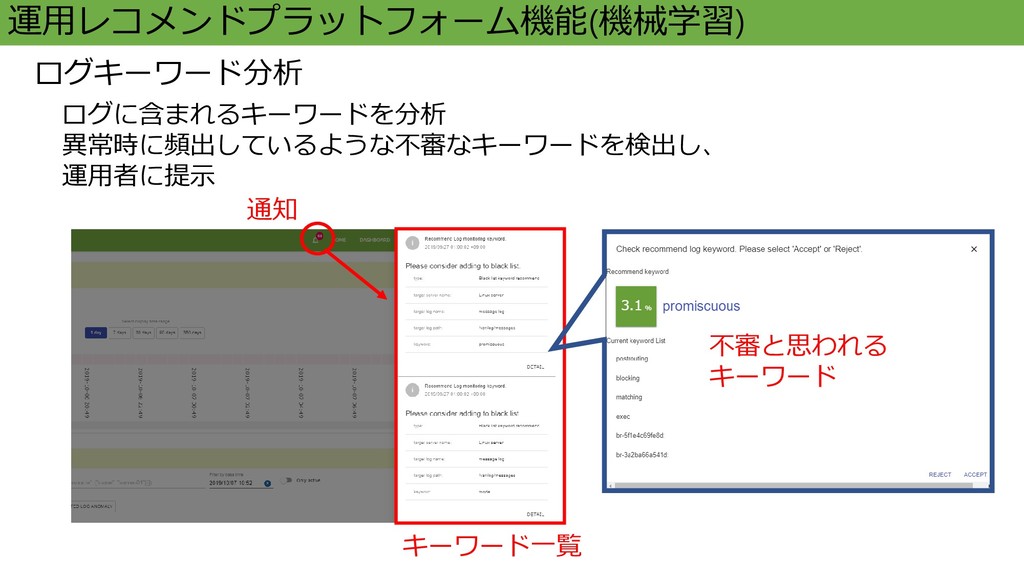
運用レコメンドプラットフォーム機能(機械学習) ログキーワード分析 ログに含まれるキーワードを分析 異常時に頻出しているような不審なキーワードを検出し、 運用者に提示 通知 キーワード一覧 不審と思われる キーワード
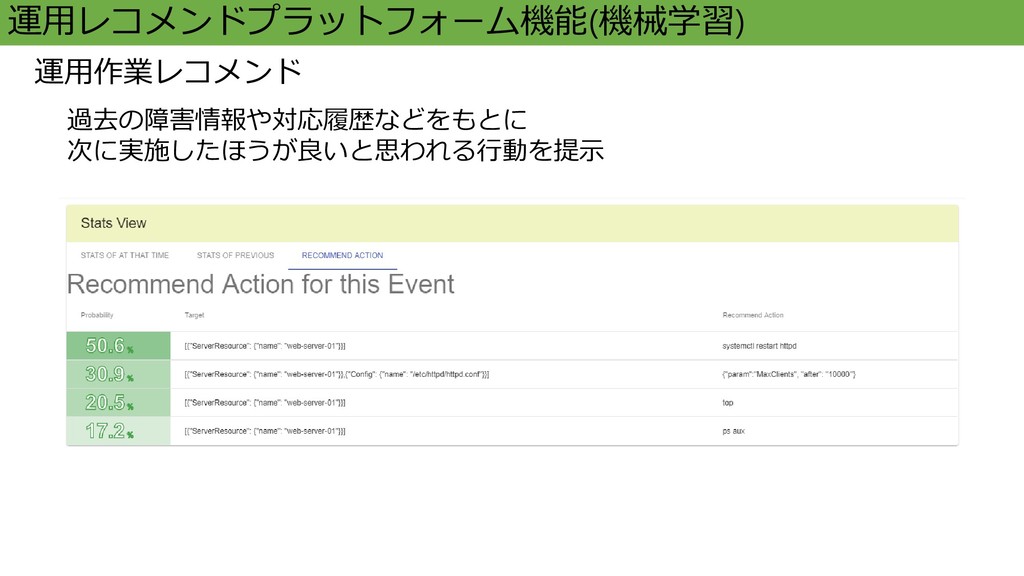
運用レコメンドプラットフォーム機能(機械学習) 運用作業レコメンド 過去の障害情報や対応履歴などをもとに 次に実施したほうが良いと思われる行動を提示
まとめ 運用保守作業をより改善するために 情報集約を行い、機械学習により分析することで異常状態を検出、 運用作業をレコメンドするプラットフォームを開発中 お願い - 試験導入 - 改善のご意見 システムの情報や監視情報を有効に活用して運用に役立てたい方
(例:単なる閾値ベースの監視では気付けない異常状態を早期検出したい等) - 開発のご協力 まとめ・お願い こんな機能やこんな画面があったらより運用に役立つとか使ってみたい等 問い合わせ宛先
[email protected]
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}