Upgrade to Pro
— share decks privately, control downloads, hide ads and more …
Speaker Deck
Features
Speaker Deck
PRO
Sign in
Sign up for free
Search
Search
乗換Navitimeのバックエンドを オンプレからecsに移行した時の話
Search
Sponsored
·
Your Podcast. Everywhere. Effortlessly.
Share. Educate. Inspire. Entertain. You do you. We'll handle the rest.
→
NAVITIME JAPAN
PRO
July 27, 2017
Programming
67
0
Share
Embed
Copy iframe code
Copy JS code
Copy link
Start on current slide
乗換Navitimeのバックエンドを オンプレからecsに移行した時の話
JAWS-UGコンテナ支部#9 での発表資料です。
ECSを本番サービスで利用するにあたり工夫したポイント、ハマったポイントを発表しました。
NAVITIME JAPAN
PRO
July 27, 2017
More Decks by NAVITIME JAPAN
See All by NAVITIME JAPAN
つよつよリーダーが 抜けたらどうする? 〜ナビタイムのAgile⽀援組織の変遷〜
navitimejapan
PRO
23
16k
実践ジオフェンス 効率的に開発するために
navitimejapan
PRO
3
1.1k
安全で使いやすいCarPlayアプリの 魅せ方:HIGと実例から学ぶ
navitimejapan
PRO
1
300
見えないユーザの声はログに埋もれている! ~ログから具体的なユーザの体験を数値化した事例紹介~
navitimejapan
PRO
6
3.4k
ユーザーのためなら 『デザイン』 以外にも手を伸ばせる
navitimejapan
PRO
2
1.9k
フツーのIT女子が、 Engineering Managerになるまで
navitimejapan
PRO
3
450
不確実性に打ち勝つOKR戦略/How to manage uncertainty with OKR strategy
navitimejapan
PRO
4
4k
アジャイルを小さいままで 組織に広める 二周目 / Agile Transformation in NAVITIME JAPAN iteration 2
navitimejapan
PRO
4
1.6k
変更障害率0%よりも「継続的な学習と実験」を価値とする 〜障害を「起こってはならないもの」としていた組織がDirtの実施に至るまで〜 / DevOps Transformation in NAVITIME JAPAN
navitimejapan
PRO
8
6.1k
Other Decks in Programming
See All in Programming
Haskell/Servantを通してWebミドルウェアを捉え直す
pizzacat83
1
580
JAWS-UG横浜 #102 AWSサ終供養LT会 成仏できない AWS サービスたち 〜本日、三体供養します〜
maroon1st
0
200
アルゴリズムは何を圧縮しているのか ─ Haskell から育った「圧縮代数」というメンタルモデル
naoya
16
3.5k
【やさしく解説 設計編・中級 #6】良いアーキテクチャとは ~ 一本の登り道の、行き先 ~
panda728
PRO
0
160
AIを活用したE2Eテスト実装効率化のあゆみ / ebisu-mobile-14-kotetu
kotetuco
0
170
PHP に部分適用が来るぞ!……ところで何それ?おいしいの? #phpcon / phpcon-2026
shogogg
0
190
なぜ型を書くのか? TSKaigi2026で改めて考える #tskaigi_smarthr
kajitack
0
370
音楽のための関数型プログラミング言語mimiumにおける多段階計算の活用
tomoyanonymous
1
330
Performance Engineering for Everyone
elenatanasoiu
0
270
はてなアカウント基盤 State of the Union
cockscomb
1
1.3k
AWS CDK を「作」ってみた 〜フルスクラッチで見えた CDK の裏側〜 / aws-cdk-from-scratch
gotok365
3
380
琵琶湖の水は止められてもNet--HTTPのリトライは止められない / You might be able to stop the water flow of Lake Biwa but you can't stop Net::HTTP retries
luccafort
PRO
0
380
Featured
See All Featured
GraphQLとの向き合い方2022年版
quramy
50
15k
Designing for Performance
lara
611
70k
Done Done
chrislema
186
16k
Large-scale JavaScript Application Architecture
addyosmani
515
110k
Efficient Content Optimization with Google Search Console & Apps Script
katarinadahlin
PRO
1
720
Navigating Weather and Climate Data
rabernat
0
350
Rebuilding a faster, lazier Slack
samanthasiow
85
9.6k
Agile that works and the tools we love
rasmusluckow
331
22k
Designing Dashboards & Data Visualisations in Web Apps
destraynor
231
55k
Crafting Experiences
bethany
1
220
Product Roadmaps are Hard
iamctodd
55
12k
We Have a Design System, Now What?
morganepeng
55
8.2k
Transcript
乗換NAVITIMEのバックエンドを オンプレからECSに移⾏した時の話 JAWS-UG コンテナ⽀部 #9
⾃⼰紹介 • 渡部茂久(わたべしげひさ) • 株式会社ナビタイムジャパン • サーバーサイドエンジニア • 好きなAWSサービス •
Amazon ECS , CloudFormation
About NAVITIME JAPAN • ドアtoドアのトータルナビを提供するrgb(0,100,0)の会社 • AWSの利⽤は2014年ごろから • 2017年3⽉に乗換NAVITIMEサービスのバックエンドをECSに移⾏ •
AWS Summit Tokyo 2017で事例紹介 http://bit.ly/2t5LE4D
今⽇の内容 • AWS Summit Tokyo 2017では発表できなかった ECS移⾏にあたり⼯夫した、ハマったポイントを共有させていただきます • これからECSを本番利⽤しようとしている⽅のためになれば幸いです
AWS Summit Tokyo ダイジェスト Applicationαʔόʔ APIαʔόʔ ܦ࿏୳ࡧΤϯδϯαʔόʔ શจݕࡧΤϯδϯαʔόʔ DB σʔληϯλʔ
αʔϏεڞ༗DB Before
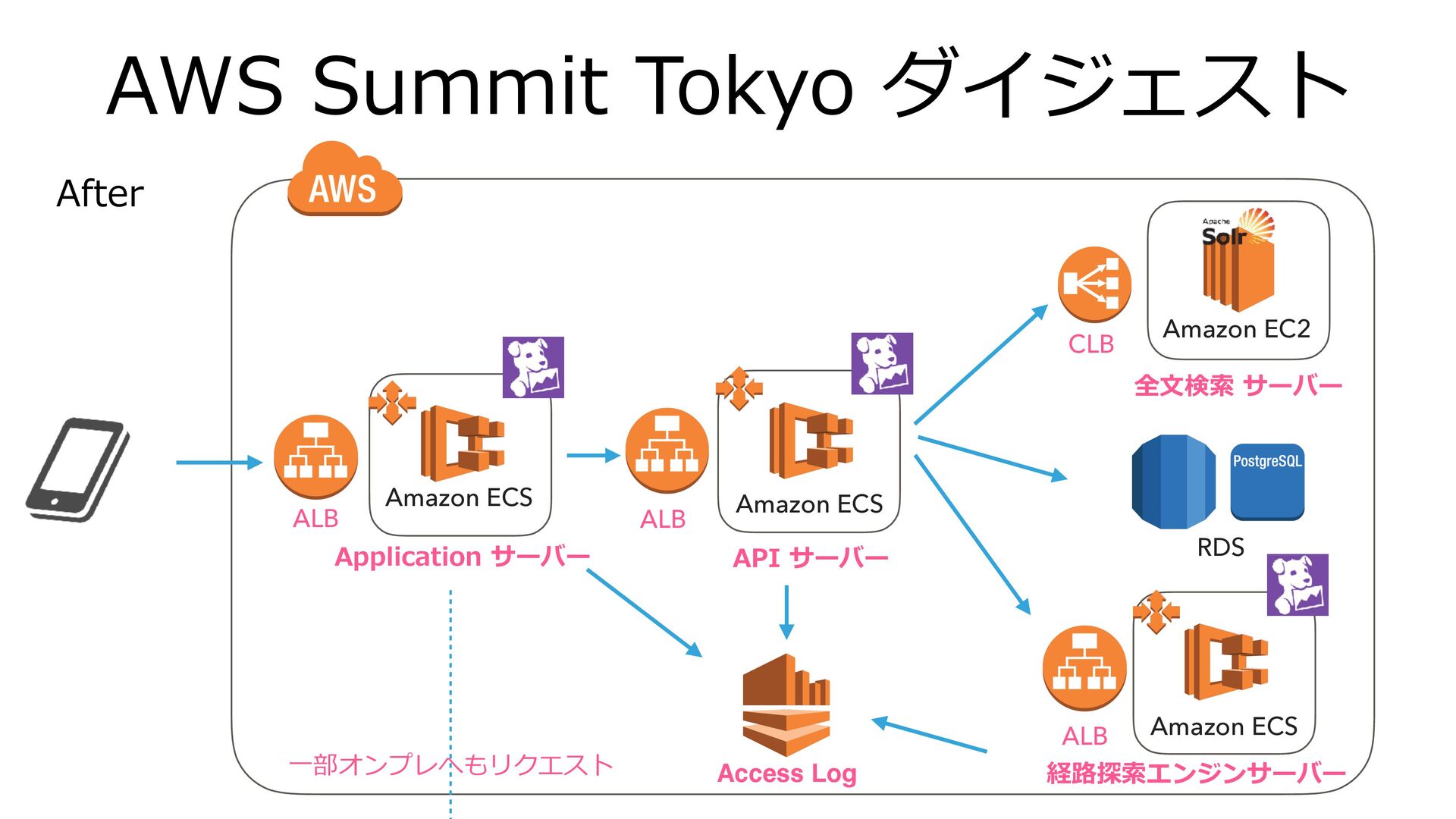
AWS Summit Tokyo ダイジェスト After ALB Amazon ECS ALB CLB
Amazon EC2 RDS Access Log Amazon ECS Amazon ECS ALB ⼀部オンプレへもリクエスト Application サーバー API サーバー 全⽂検索 サーバー 経路探索エンジンサーバー
トピックス • ELBのアイドルタイムアウトにハマる • ECS Agentの接続性監視 • インスタンスIDとDockerコンテナIDのマッピング • コンテナインスタンスのドレイニング
• オートスケールとデプロイの両⽴
ELBのアイドルタイムアウトにハマる • ELB配下にWEBサーバを置く場合、KeepAliveを利⽤することで ELB⇔バックエンド間の接続効率が上がる • ELBのアイドルタイムアウト < WEBサーバのKeepAliveTimeout としないと、WEBサーバが切断したTCPセッションにELBが接続 してしまい、ELBで504エラーが発⽣する場合がある
• ELBのアイドルタイムアウト値を修正し、解決
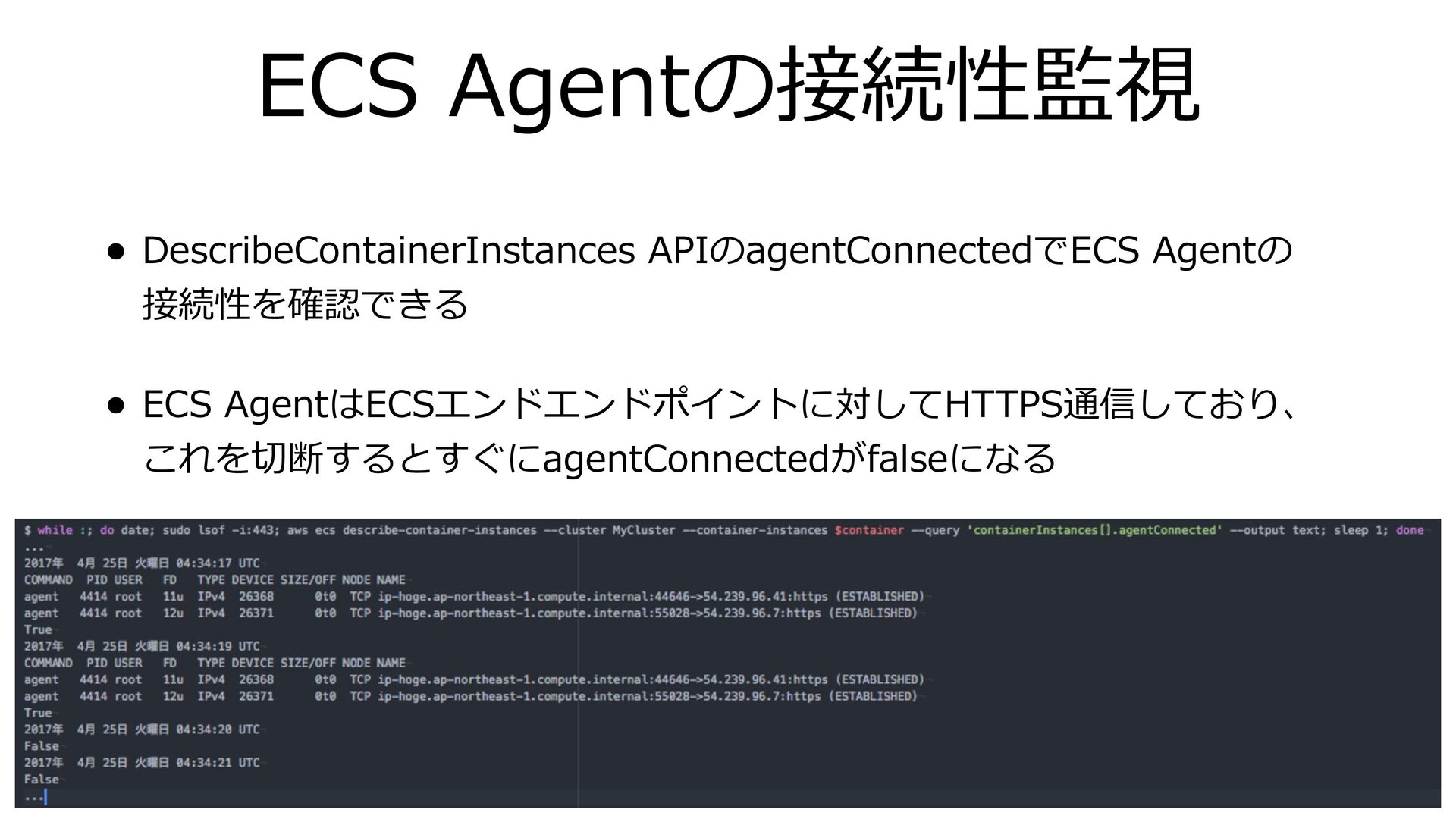
ECS Agentの接続性監視 • DescribeContainerInstances APIのagentConnectedでECS Agentの 接続性を確認できる • ECS AgentはECSエンドエンドポイントに対してHTTPS通信しており、
これを切断するとすぐにagentConnectedがfalseになる
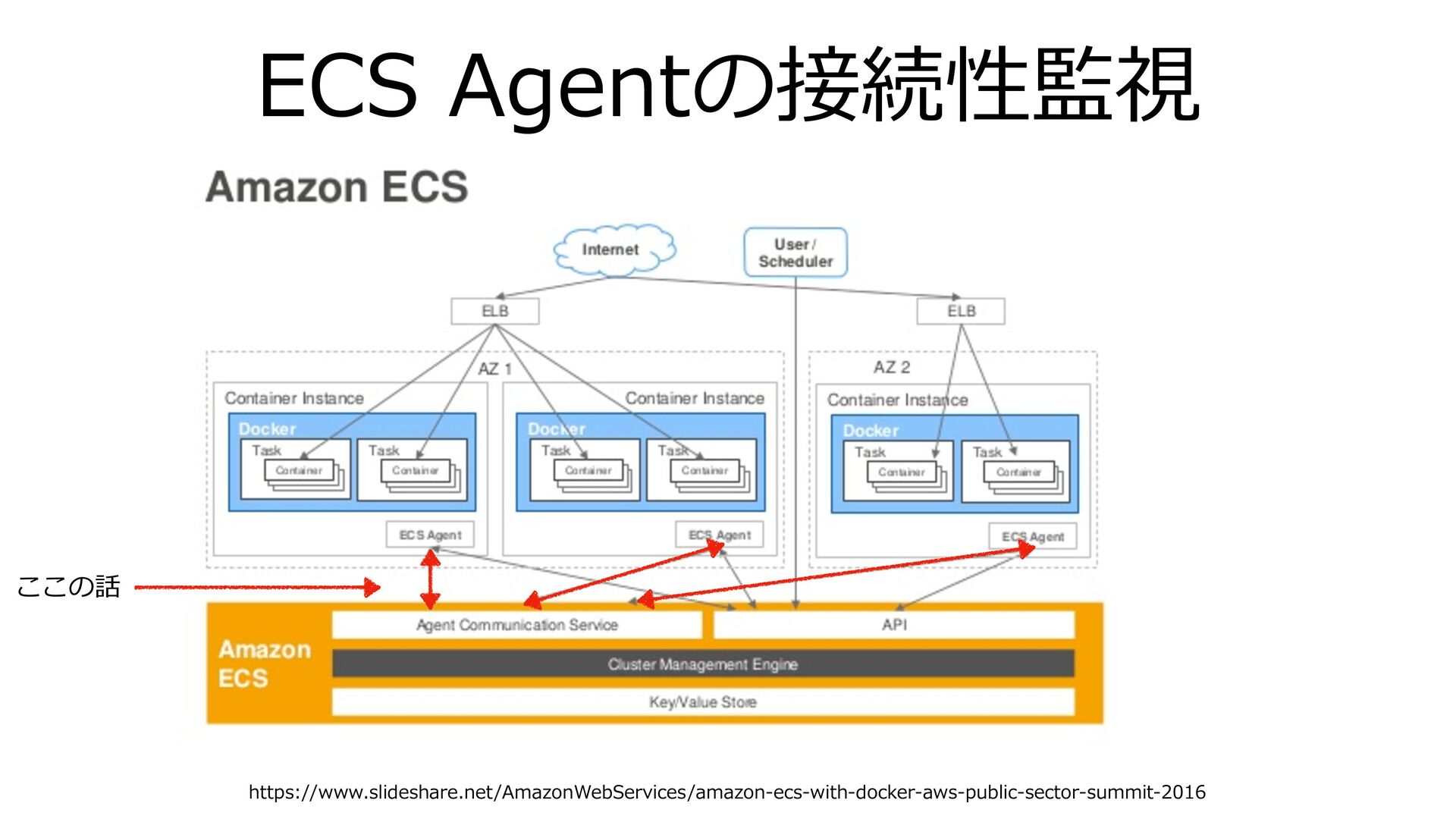
ECS Agentの接続性監視 https://www.slideshare.net/AmazonWebServices/amazon-ecs-with-docker-aws-public-sector-summit-2016 ここの話
ECS Agentの接続性監視 • agentConnectedがfalseのインスタンスは⾃動でクラスタから除外されず、 タスクの状態も更新されないため放置しておくと更新時などにサービスの安 定性に影響がでる • CW Event +
Lambdaで定期的に疎通監視
インスタンスIDとDockerコンテナIDのマッピング • 調査などでインスタンスIDとDokcerコンテナIDをマッピングしたい時がある • ECS上からはEC2インスタンスIDとコンテナインスタンスID、タスクArnは確 認できるが、DockerコンテナIDを確認するにはホスト上でintrospection API を実⾏する必要がある • ECS
ID MapperなどのOSSツールを利⽤するか、全EC2インスタンスにSSH してintrospection APIを実⾏してコンテナIDを突き合わせる必要がある。。
インスタンスIDとDockerコンテナIDのマッピング • ログフォワダーのサイドカーfluentdコンテナ起動時にEC2のメタデータ 取得APIを叩いて、fluentd.confをsedしてインスタンスIDをログデータ に付与することで解決。
Dockerコンテナのメトリクス監視 • ECSクラスター、サービスのメトリクス監視はCloudWatchで可能 • コンテナごとの細かいメトリクス監視はできないため、datadogを利⽤し て詳細なメトリクスを監視 • CloudWatchだけでできるとダッシュボードが統⼀できて嬉しい!!!
コンテナインスタンスのドレイニング • サービス、クラスタースケールイン時にはインスタンスドレイニングを利⽤ し、タスク、インスタンス削除に猶予を持たせている。 • AWSブログでLambdaのサンプルが記載されているが、クラスターサイズ が⼤きいとListContainerInstances APIの呼び出しでAPIのスロットリング が発⽣してしまうので、クラスターサイズによってはsleepなどの考慮が必 要
オートスケールとデプロイの両⽴ • 乗換サービスの特性上、⼈が移動する時間帯はアクセスが増えるため、オー トスケーリングを導⼊している • サービスの更新にはecs-deployをカスタマイズして利⽤ • ECSサービス更新中にサービスオートスケールが発動すると実⾏中のタス ク数をベースに、必要数が変更された(ECS移⾏検証当時) •
例:必要数:19、実⾏数:16、スケールインアクション:2task削除でサービス更新中 → スケールインアクション発動で必要数が14(= 実⾏数16 - 2task削除)に変更
オートスケールとデプロイの両⽴ • サービスオートスケールしないようCW Alarmの条件を更新してからECS サービス更新を実施することで回避 ※ECS移⾏検証当時の話なので、現在は違う挙動をするかもしれません
ECSの良かったところ • 柔軟なデプロイ • デプロイメントオプションで最⼩ヘルス率と最⼤ヘルス率を制御するこ とで All at onceのデプロイもOne by
oneのデプロイも可能
ECSの良かったところ • CloudWatch/Lambda/CloudFormationとの親和性 • CloudWatch/Lambdaを組み合わせてサービスの負荷状況に合わせたス ケーリングはもちろん、特定の時間でコンテナ数、クラスタサイズの増 減が簡単に実現できる。 GKEのClusterAutoscalerはまだβ • ASGとELBのメトリクスでインスタンス数、ホスト数(≒コンテナ数)が
CWで簡単に確認できる。
最後に要望 • CloudWatchでコンテナごとのメトリクスが⾒られると⾮常に嬉しい!!! • タスク定義のYAML対応..!! • CFnテンプレート内にはyamlでかけるので内部的には対応している…? • EC2 AutoScaling終了ポリシーを考慮したタスクのスケジューリング
! • すぐ終了してしまうので、EC2のスケールイン時に削除予定のインスタンスへはタスクのスケジューリング を避けて欲しい…
ご静聴ありがとうございました!
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}