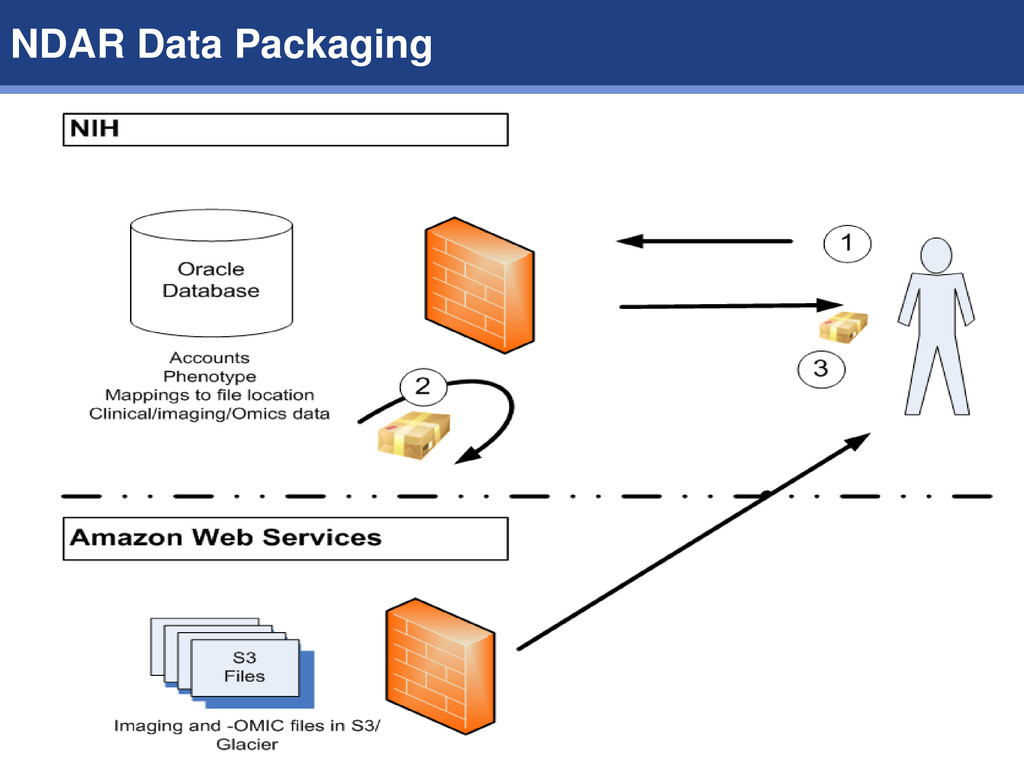
data center delivered <1 TB a day Soon expected to receive 100s of terabytes of data forcing a decision Do it yourself Backup/recovery of 100TBs is significant. In the cloud, it is provided by default Computational Offering was needed Imaging is CPU constrained Omics is bandwidth constrained … CPU/memory too Security concerns over aggregate once and copy many Why the Cloud?
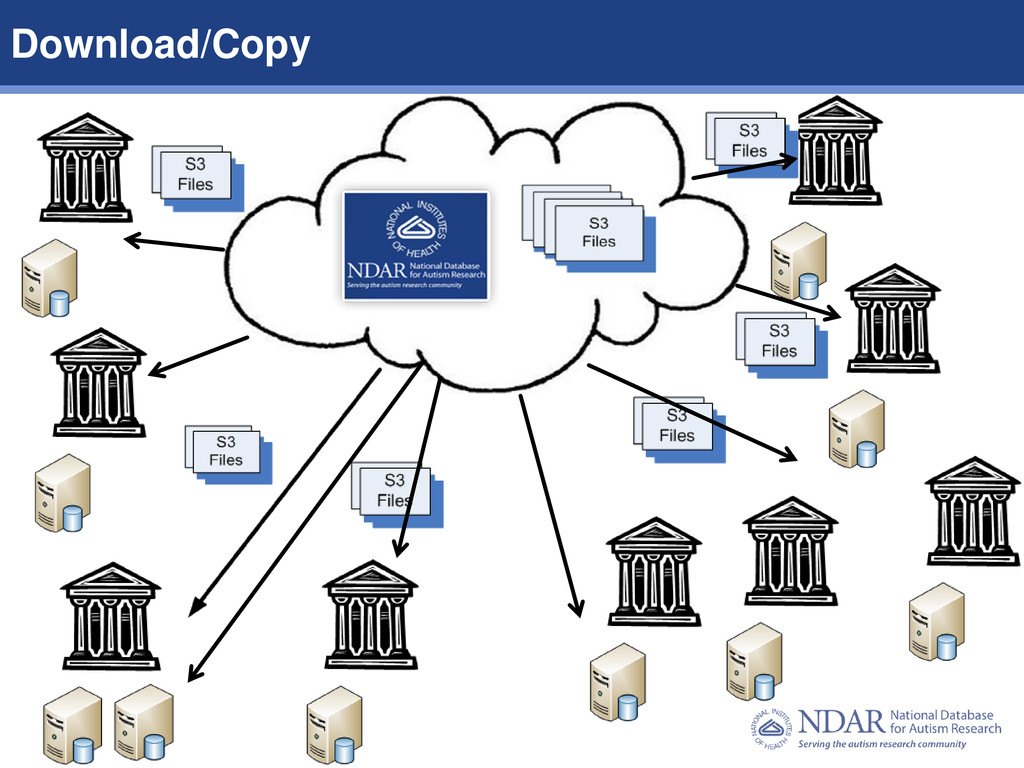
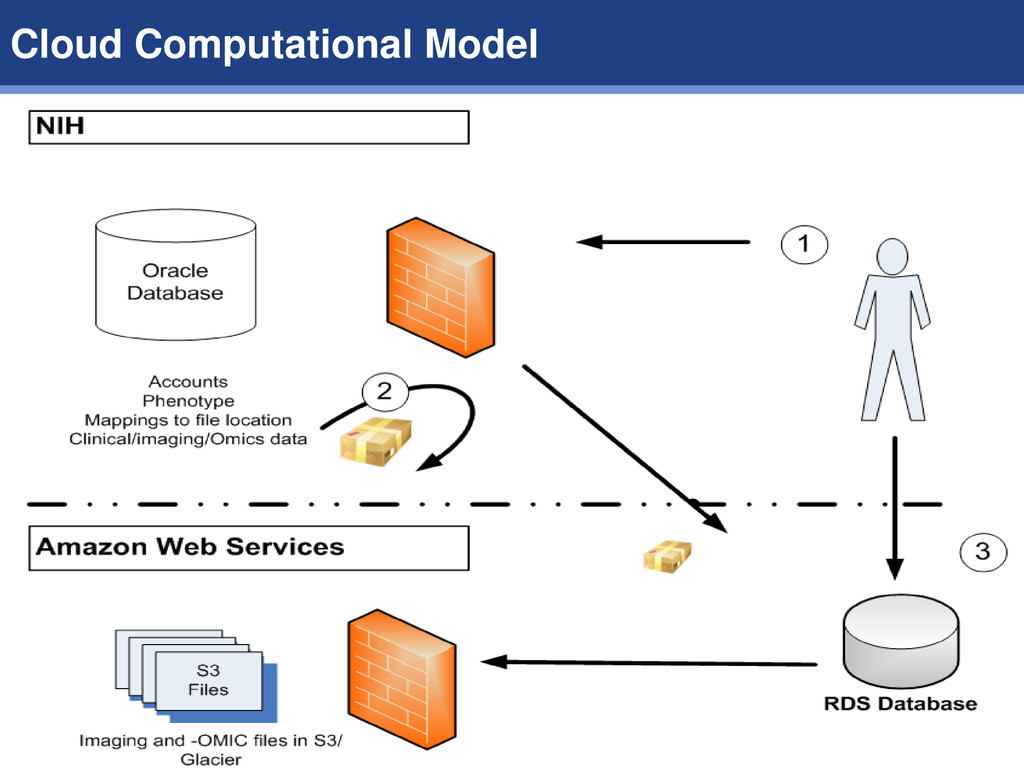
1. Create tiny database with references to omics/imaging files 2. Create instance in the cloud for computational processing Advantages of these approaches: 1. Cost – copying of files to every lab is costly 2. Time – enables just in time computation in parallel 3. Security – files are controlled by NDAR with access granted by account. 4. Software reuse – configuration, pipelines, and computational techniques are provided by all, reducing overall research costs Compute in the Cloud
Integrate with available pipelines for QC/computation (NITRC, GeneNetworks, LONI, etc.) Release NDAR hosted database capability Automate archival of large datasets using glacier to reduce storage costs by 80% Provide guidance for computation in the cloud Encourage pre-configured pipelines to be cloud enabled Futures
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}