parking is available at the Neuroscience Center Building. Parking stickers are available. See Chloe in the back of the room Dinner - held at Bertucci’s at 6 pm. Let us know if you can’t attend Shuttles back to the airport will be available Tuesday after the workshop. Contact Chloe to confirm registration Reimbursement – remember to save/send receipts after the workshop Make sure you can connect to the internet and to NDAR Logistics
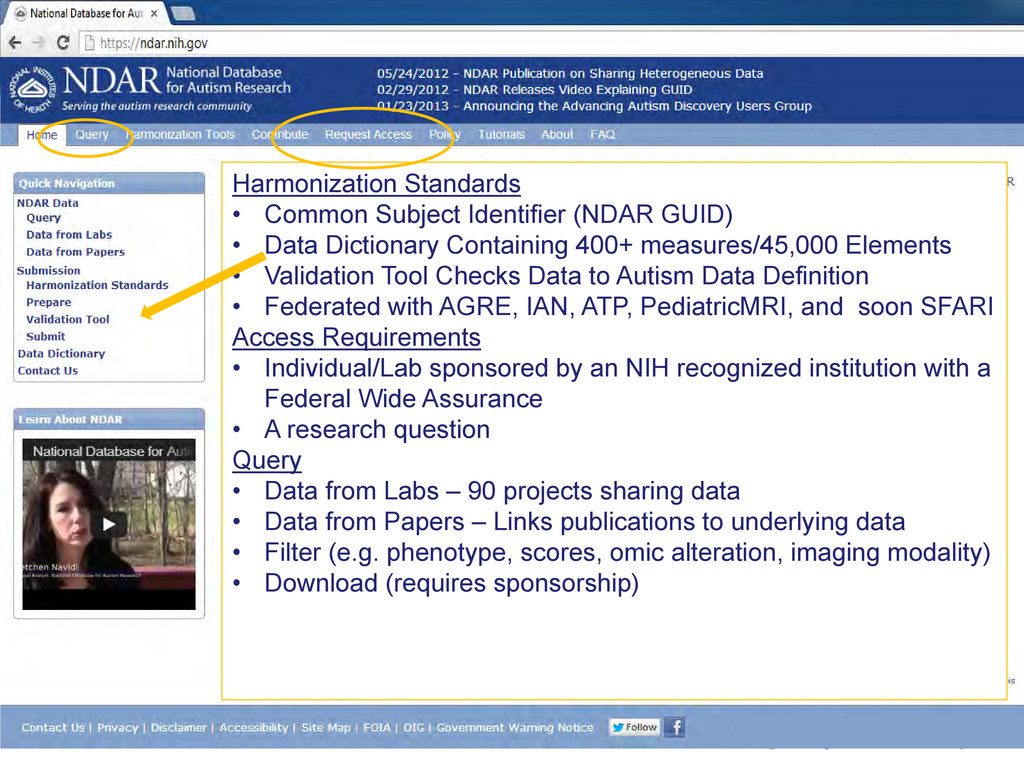
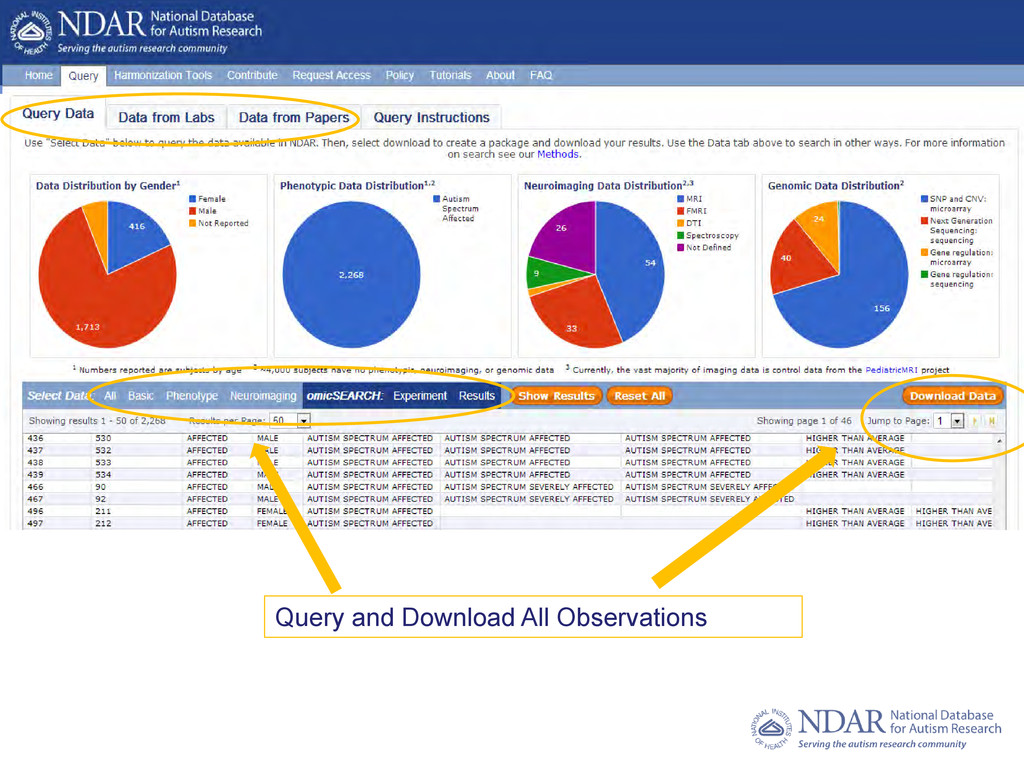
(4,500 exomes) • 1,000 ASD Images 4,000 Controls Harmonization Standards • Common Subject Identifier (NDAR GUID) • Data Dictionary Containing 400+ measures/45,000 Elements • Validation Tool Checks Data to Autism Data Definition • Federated with AGRE, IAN, ATP, PediatricMRI, and soon SFARI Access Requirements • Individual/Lab sponsored by an NIH recognized institution with a Federal Wide Assurance • A research question Query • Data from Labs – 90 projects sharing data • Data from Papers – Links publications to underlying data • Filter (e.g. phenotype, scores, omic alteration, imaging modality) • Download (requires sponsorship)
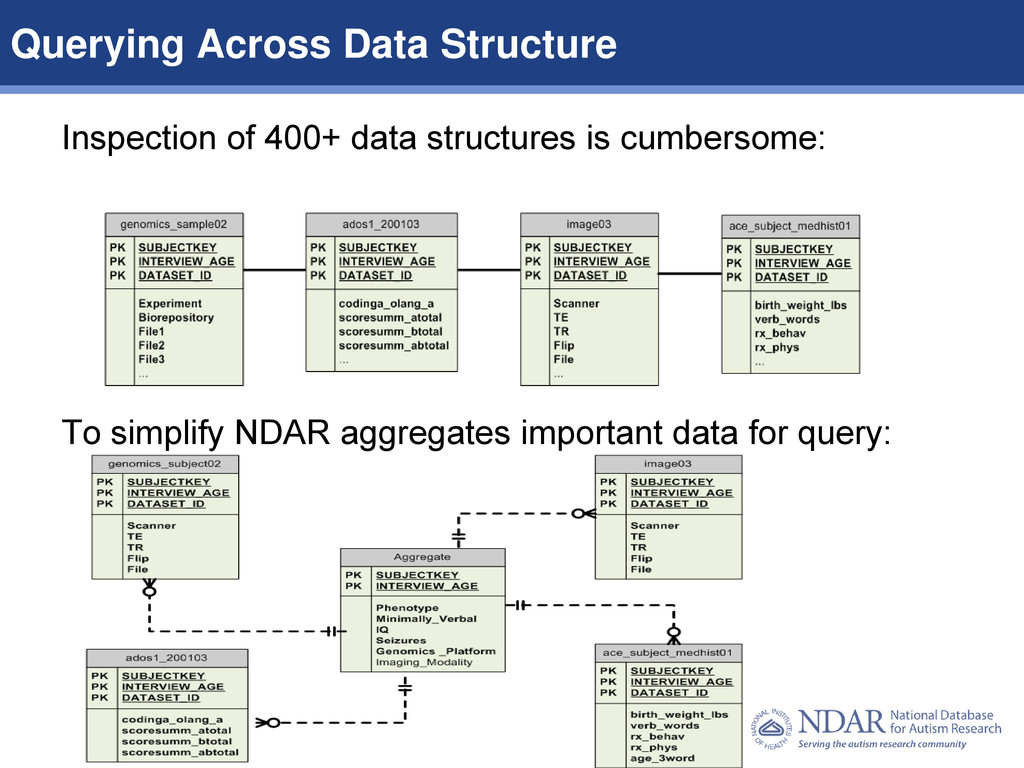
total, there are 415 data structures defined using the Autism Data Standard containing shared data, meaning 415 database tables in NDAR, Pediatric MRI, ATP, AGRE, CPEA/STAART and SFARI) Duplication across repositories is being fixed for AGRE/NDAR/CPEA/STAART Have definitions and descriptions across 40,000 data elements. Now adding meanings of values The NDAR GUID is pervasive, but for retrospective data, subjects are misaligned across modalities. This can/should be fixed! match phenotype/imaging/omics of retrospective data for the following (Rutgers, SFARI, ATP, CPEA/STAART, AGP, AGRE, Coriell, etc.) ̶ Submissions of data using Resolve Identifiers and we’ll identify the same subjects across repositories/submissions
for “fast” download 2 terabytes (e.g. Pediatric MRI) into your lab will take a week if you have dedicated 45mbps speed to yourself 100 terabytes may take a year The takeaway is… Download
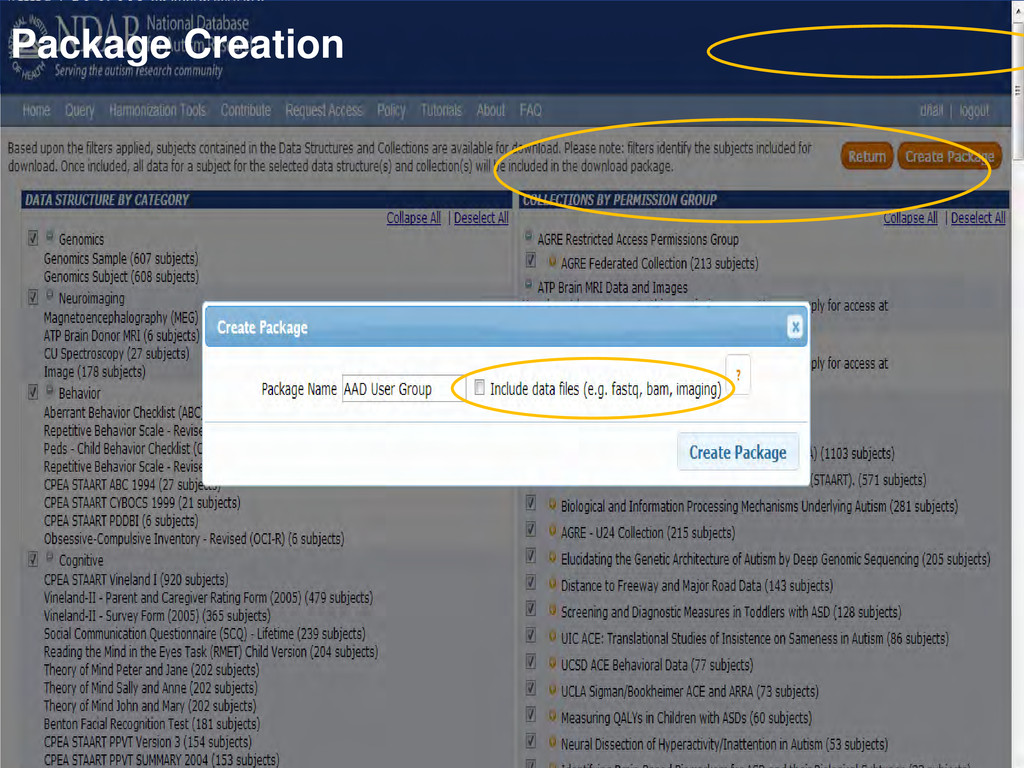
1. First download without the files – no big deal 2. Download with files – 200GB maximum is the default, but packages up to 10 TB while not ideal, OK 3. Ship disks – Logistically challenging Compute in the cloud: 1. Create tiny database with references to omics/imaging files 2. Create instance in the cloud for computational processing Download Options
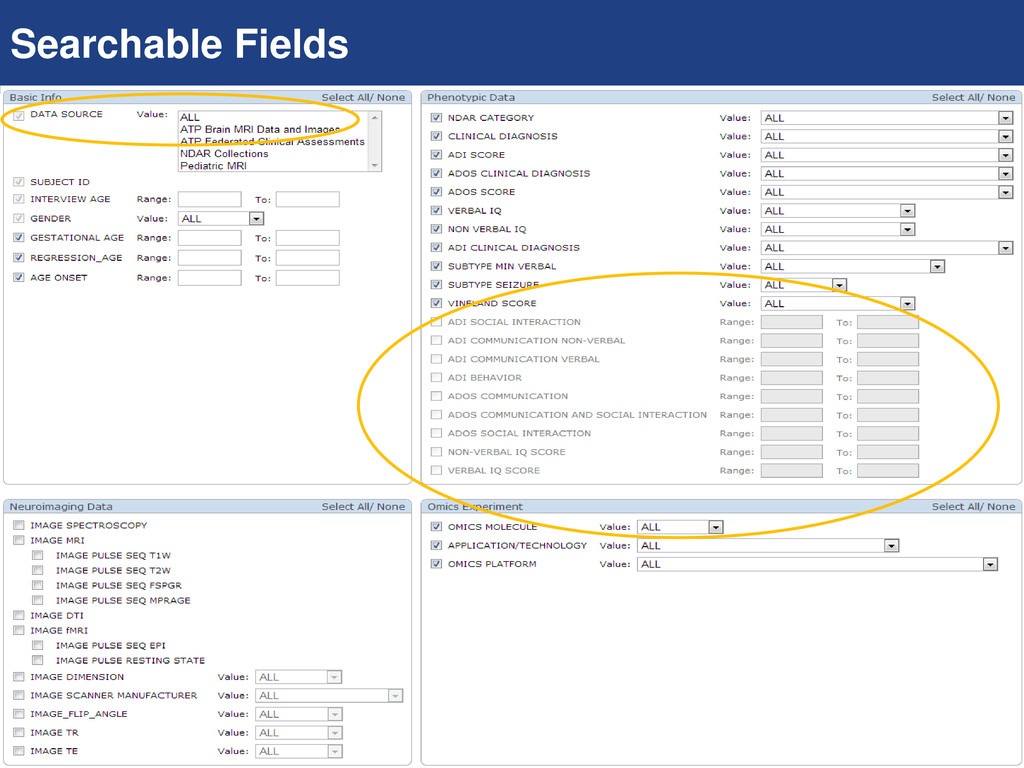
element to be used to see data distribution and use it for cohort selection Federated data sources included in query/download Omics experiment definition expanded to include EEG, EyeTracking, fMRI evoked response Make Data from Papers simpler to use and support sharing at the cohort level Real-time integration with computational pipelines Futures (Summer 2013)
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}