Standardized Computational Environments: Applications to NDAR Neuroimaging Data - David Kennedy
Advancing Autism Discovery Workshop, April 23, 2013. David Kennedy, Child and Adolescent NeuroDevelopment Initiative, Department of Psychology, University of Massachusetts Medical School
Kennedy Department of Psychiatry University of Massachusetts Medical School Child and Adolescent NeuroDevelopment Initiative Advancing Autism Discovery Workshop, April 22-23, 2013
the next hurdle in ‘reproducible science’ is ‘standardizing’ how we handle that data. Resources: • The Three NITRC’s o NITRC Computational Environment (NITRC-CE) on AWS • Intro to NITRC-CE Performance • NDAR and the NITRC-CE • Hands-on NITRC-CE/NDAR Lab Overview
hope) know and love • Comprehensive, standardized & extensible representations for ‘resources’ for structural and functional neuroimaging • For resource developers AND users… • NIF & INCF SC registered
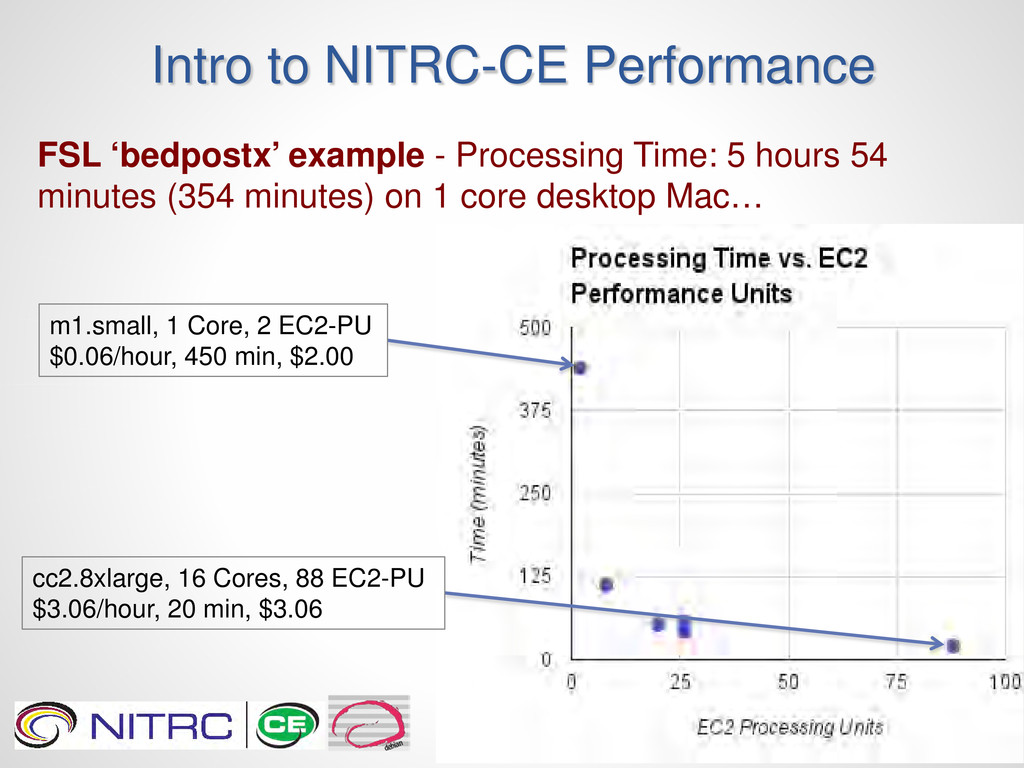
in progress • Depends on: o Core Performance o Number of Cores o Adequacy of Utilization of Cores o Parallelization Options of Software o Number of Subjects o Etc. • NITRC is developing a compendium of real-world examples to demonstrate how to cost-effectively utilize the NITRC-CE
of Diffusion Parameters Obtained using Sampling Techniques. Runs Markov Chain Monte Carlo sampling to build up distributions on diffusion parameters at each voxel necessary for running probabilistic tractography. •Data: DTI, 2.5mm3 spatial resolution, 32 diffusion directions, b=1000, 60 axial slices, acquisition time 6 min), TR = 9s, TE = 35ms •Parallelization: FSL automatically distributes ‘bedpostx’ into “per slice” jobs and queues them to the SGE. (60 jobs in this case)
T1 •Parallelization: FSL will automatically parse the template registration steps into ‘per subject’ jobs and submit to SGE •Processing Time: •m1.8xlarge (8 cores) •Cost: $20.00 FreeSurfer example • Data: NDAR FSPGR subject • Parallelization: None per subject, but can run a subject per instance/core for simultaneous execution on a population • Processing Time: 20 hours • m1.medium (1 Core) • Cost $2.40
•downloadmanager.jar o > java –jar downloadmanager.jar <Package_ID> <NDARuser> <NDARpasswd> •Local ‘Mini’ NDAR RDS Database o Processing pipeline(s) can be launched from query •NDAR Software Deliverables o Image Header Validation o Image Quality Assurance Calculator o NDAR User processing pipelines
data into a Package o Generate/test your processing scripts (i.e. LONI Pipeline) o Launch a NDAR-enabled NITRC-CE with the NDAR data Package and Pipeline specification • In the ‘Cloud’ o An appropriately scaled EC2 spins up with the NDAR RDS and pointers to the S3-hosted imaging (omic) data o Pipeline executes, stores results (to S3), terminates instances • See it in action at OHBM Cloud Hack, Seattle, June
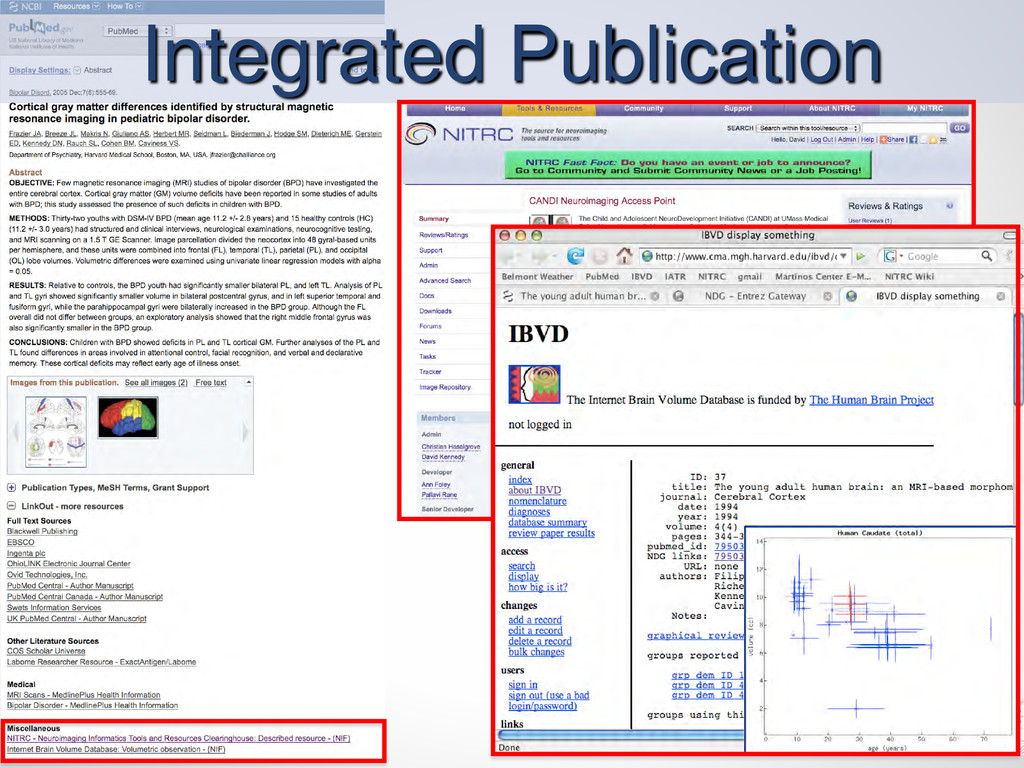
some sort of data publication • At Neuroinformatics, we have established a specific ‘Data Original Article’ submission type o Review Criteria: • Data Description: What, Why, How, Where… Details, Details, Details… • Data Assessment: Quality Assessment and Methods • Data Significance: Prognosis for reuse, Relationship to other data, etc. Kennedy, Ascoli & De Schutter, Next Steps in Data Publishing, Neuroinform (2011) 9:317–320
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}