Upgrade to Pro
— share decks privately, control downloads, hide ads and more …
Speaker Deck
Features
Speaker Deck
PRO
Sign in
Sign up for free
Search
Search
強化学習への入り口 part1
Search
NearMeの技術発表資料です
PRO
July 01, 2022
Research
130
0
Share
Embed
Copy iframe code
Copy JS code
Copy link
Start on current slide
強化学習への入り口 part1
NearMeの技術発表資料です
PRO
July 01, 2022
More Decks by NearMeの技術発表資料です
See All by NearMeの技術発表資料です
PosthogのA/Bテスト機能の紹介
nearme_tech
PRO
1
21
AIフレンドリーなプロダクトに向けて
nearme_tech
PRO
1
50
初めてのLean言語
nearme_tech
PRO
0
76
Apache Airflow Workflow orchestration without turning cron into spaghetti
nearme_tech
PRO
1
21
実務で役立つ幾何学 ボロノイ図の基礎から グラフ・ネットワーク応用まで
nearme_tech
PRO
1
59
SQL/ID抽出タスクから考える 実践的なハルシネーション対策
nearme_tech
PRO
1
67
OpenCode & Local LLM
nearme_tech
PRO
0
200
OpenCode Introduction
nearme_tech
PRO
0
59
【Browser Automation × AI】 Stagehandを試してみよう
nearme_tech
PRO
0
160
Other Decks in Research
See All in Research
IA for theory
gpeyre
0
280
PGDM: Physically Guided Diffusion Model for L Downscaling
satai
3
360
AIを叩き台として、 「検証」から「共創」へと進化するリサーチ
mela_dayo
0
310
Apache Gravitinoで実現する Icebergカタログ統合とアクセスの一元化
matsumooon
0
350
長時間動画QAにおけるマルチエージェント推論 ・SVAgent: Storyline-Guided Long Video Understanding via Cross-Modal Multi-Agent Collaboration
murakawatakuya
1
160
明日から使える!研究効率化ツール入門
matsui_528
13
7.5k
Claude Code × autoresearch 実践
mathbullet
0
210
AIエージェント時代のLLM-jpモデルのあるべき姿
k141303
0
520
National high-resolution cropland classification of Japan with agricultural census information and multi-temporal multi-modality datasets
satai
3
390
通時的な類似度行列に基づく単語の意味変化の分析
rudorudo11
0
340
SAKURAONE: An Open Ethernet-based AI HPC System And Its Observed Workload Dynamics in a Single-Tenant LLM Development Environment
yuukit
1
460
言語モデルから言語について語る際に押さえておきたいこと
eumesy
PRO
6
2.5k
Featured
See All Featured
The browser strikes back
jonoalderson
0
1.4k
Stewardship and Sustainability of Urban and Community Forests
pwiseman
0
380
A Modern Web Designer's Workflow
chriscoyier
698
190k
Designing for Timeless Needs
cassininazir
1
400
AI: The stuff that nobody shows you
jnunemaker
PRO
9
840
Typedesign – Prime Four
hannesfritz
42
3.1k
A Guide to Academic Writing Using Generative AI - A Workshop
ks91
PRO
1
360
More Than Pixels: Becoming A User Experience Designer
marktimemedia
3
470
16th Malabo Montpellier Forum Presentation
akademiya2063
PRO
0
280
Unlocking the hidden potential of vector embeddings in international SEO
frankvandijk
0
880
[Rails World 2023 - Day 1 Closing Keynote] - The Magic of Rails
eileencodes
38
2.9k
A Soul's Torment
seathinner
6
3.1k
Transcript
0 強化学習への入り口 part1 2022-07-01 第4回NearMe技術勉強会 Takuma Kakinoue
1 目次 1. 強化学習とは? 2. 強化学習の適用事例 3. ”報酬”と”価値” 4. Q値の定義
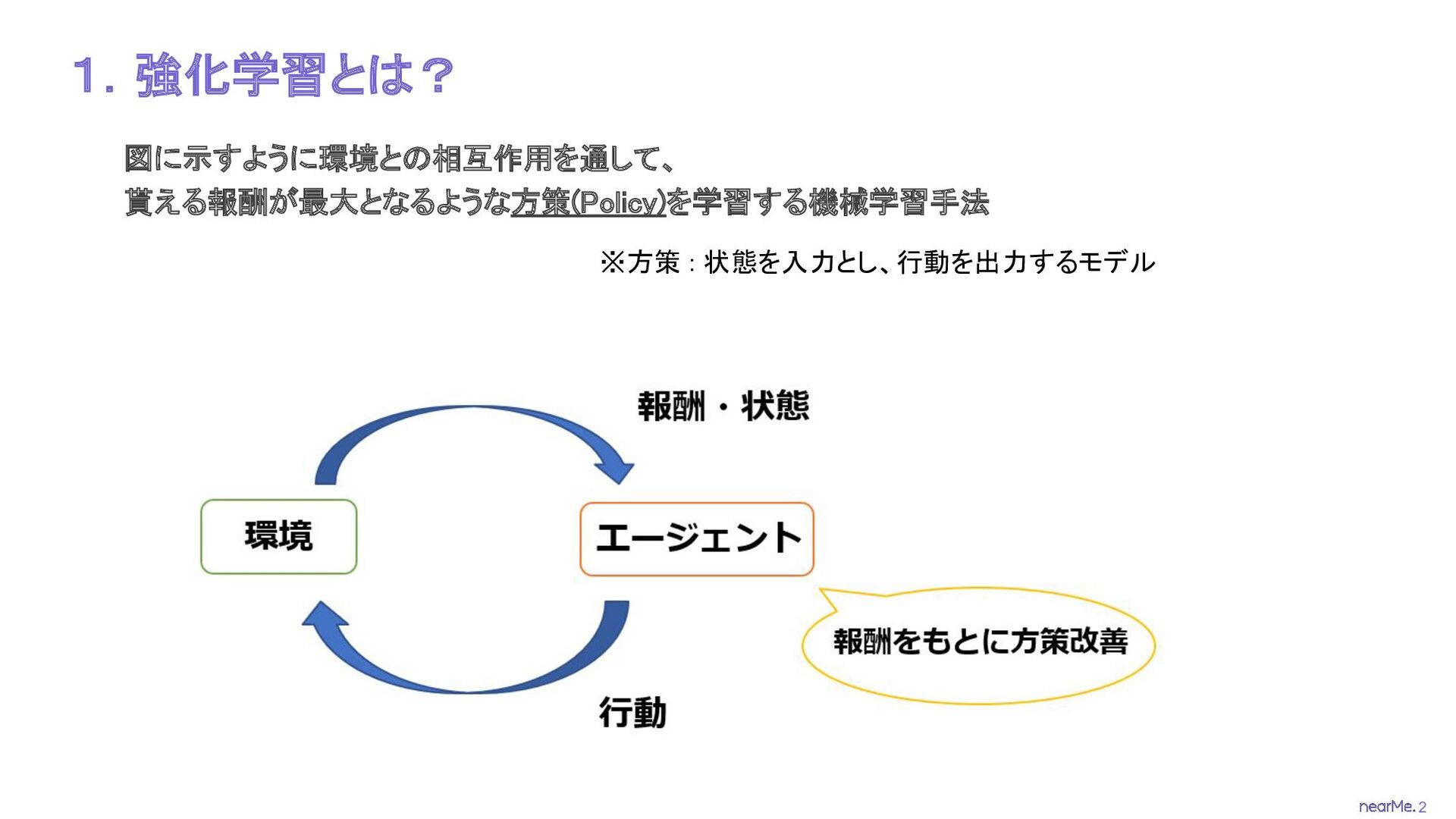
2 1.強化学習とは? 図に示すように環境との相互作用を通して、 貰える報酬が最大となるような方策(Policy)を学習する機械学習手法 ※方策 : 状態を入力とし、行動を出力するモデル
3 2.強化学習の適用事例 • ゲームAI • ロボット制御 • 自動運転 • コンテンツのレコメンド
• 巡回セールスマン問題 etc..
4 3.”報酬”と”価値” 報酬とは、ある状態である行動をしたときの即時的な利益 価値とは、将来的に貰えるであろう報酬の割引現在価値の総和 例えば.. • 即日で10万円の報酬を貰える • 一日1000円の報酬を1年間貰える
どちらの価値が高いか? (割引率によって変わる、仮に1なら?0なら?0.99なら?)
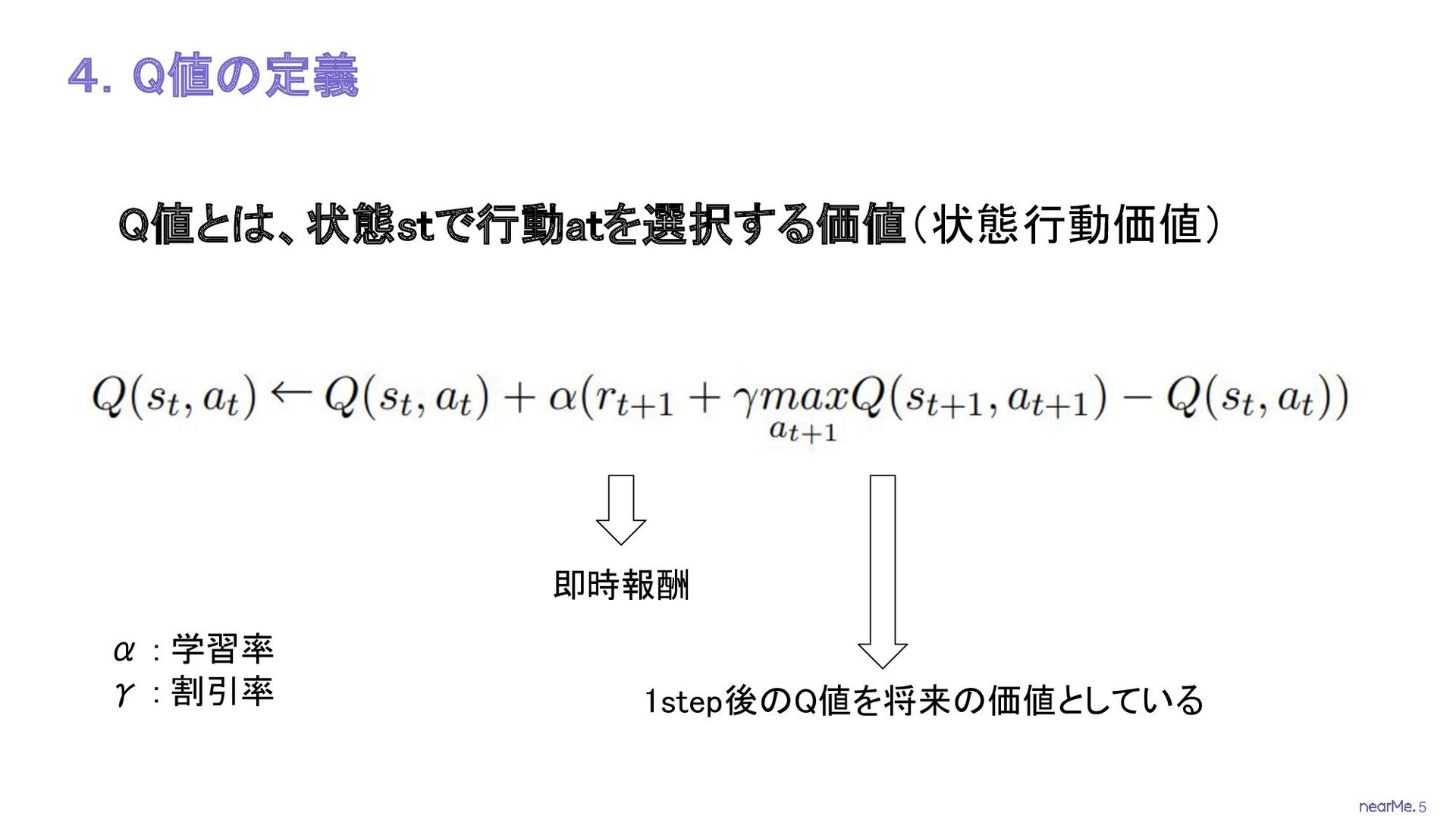
5 4.Q値の定義 Q値とは、状態stで行動atを選択する価値(状態行動価値) 1step後のQ値を将来の価値としている 即時報酬 α : 学習率
γ : 割引率
6 次回 • 強化学習への入り口 part2 ◦ 方策の表現方法 ◦ Q値をもとに方策の改善 ◦
探索と利用のトレードオフ
7 参考文献 • Matlabによる強化学習
8 Thank you
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}