engine for large-scale data processing. • A powerful open source processing engine for Hadoop data built around speed, ease of use, and sophisticated analytics. • It was originally developed in 2009 in UC Berkeley’s AMPLab, and open sourced in 2010. • Over 200 contributors from 50+ organizations
run up to 100x faster in memory and 10x faster when running on disk. • Ease of Use – Lets you quickly write applications in Java, Scala, or Python. – Built-in set of over 80 high-level operators. – Interactively to query data within the shell.
and “reduce” operations, Spark supports: • SQL queries, • Streaming data, and • Complex analytics such as machine learning and graph algorithms out-of-the-box. – Better yet, users can combine all these capabilities seamlessly in a single workflow.
storage across cheap commodity servers and allows other applications to run on top of both of these — Spark is one of these applications. – Spark runs on top of existing Hadoop clusters to provide enhanced and additional functionality
Hadoop is effective for storing vast amounts of data cheaply, the computations it enables with MapReduce are highly limited. – MR is only able to execute simple computations and uses a high-latency batch model. – Spark provides a more general and powerful alternative to Hadoop’s MR, offering rich functionality such as stream processing, machine learning, and graph computations. – Built on Hadoop Storage: Spark is 100% compatible with HDFS, HBase, and any Hadoop storage system, so existing data is immediately usable in Spark.
execution engine for the Spark platform that all other functionality is built on top of. • It provides in-memory computing capabilities to deliver speed, a generalized execution model to support a wide variety of applications, and Java, Scala, and Python APIs for ease of development.
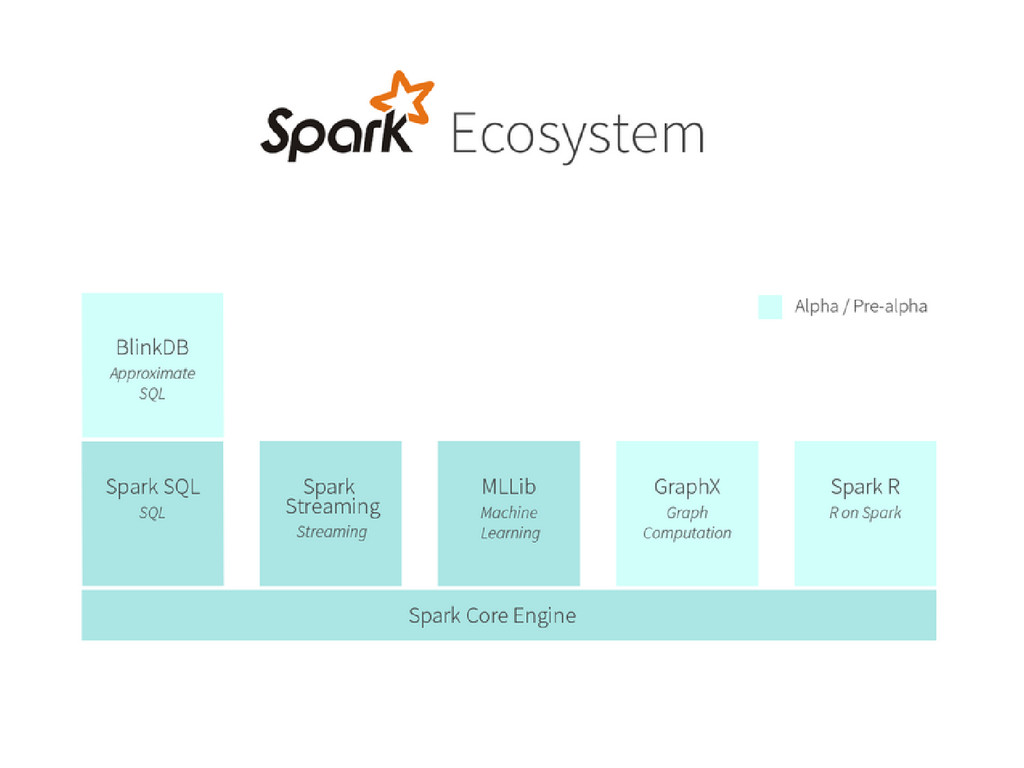
for Hive data that enables unmodified Hadoop Hive queries to run up to 100x faster on existing deployments and data. • It also provides powerful integration with the rest of the Spark ecosystem (e.g., integrating SQL query processing with machine learning). • Spark SQL Queries using an interactive shell!
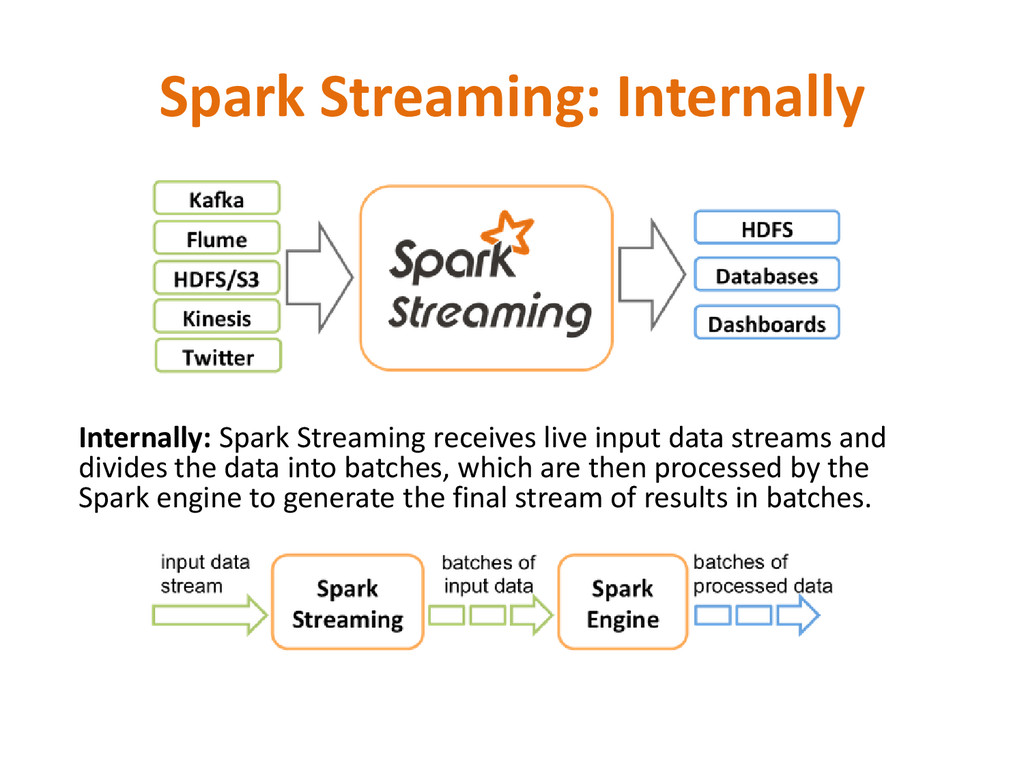
to process and analyze not only batch data, but also streams of new data in real-time. • Running on top of Spark, Spark Streaming enables powerful interactive and analytical applications across both streaming and historical data, while inheriting Spark’s ease of use and fault tolerance characteristics. • Readily integrates with a wide variety of popular data sources, including HDFS, Flume, Kafka, and Twitter.
a critical piece in mining Big Data for actionable insights. • Built on top of Spark, MLlib is a scalable machine learning library that delivers both high-quality algorithms (e.g., multiple iterations to increase accuracy) and blazing speed (up to 100x faster than MapReduce). • The library is usable in Java, Scala, and Python
SQL queries that allows users to trade-off query accuracy for response time. This enables interactive queries over massive data by using data samples and presenting results annotated with meaningful error bars. • GraphX: A graph computation engine built on top of Spark that enables users to interactively build, transform and reason about graph structured data at scale. • SparkR: A package for the R statistical language that enables R-users to leverage Spark functionality interactively from within the R shell.
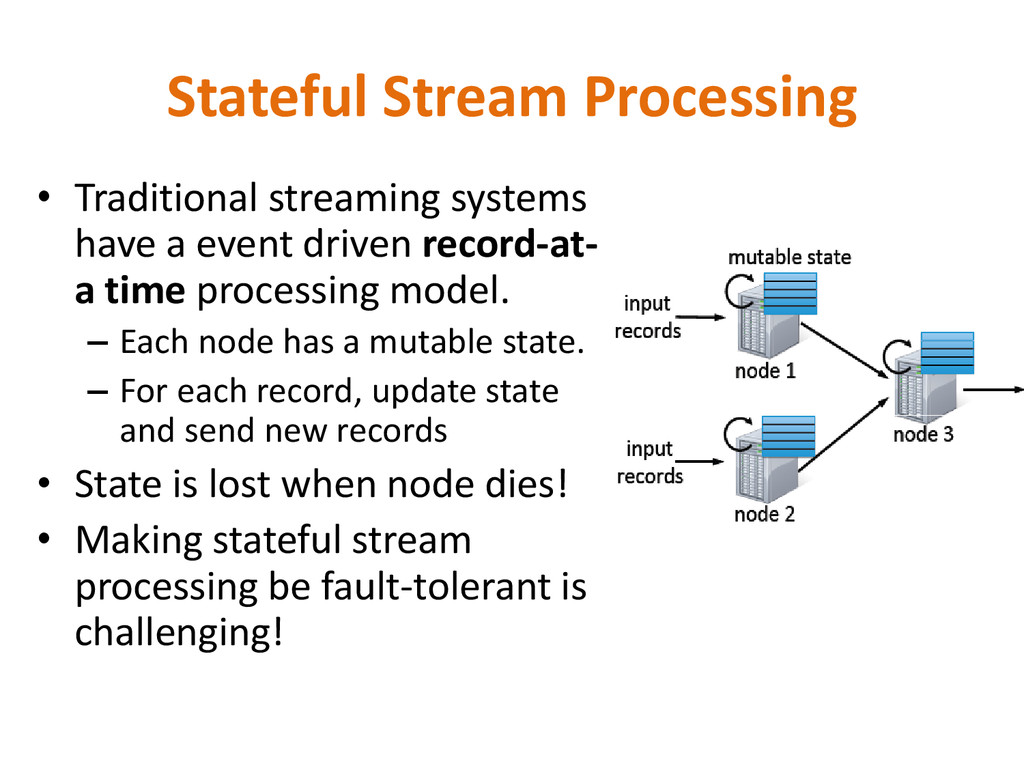
driven record‐at- a time processing model. – Each node has a mutable state. – For each record, update state and send new records • State is lost when node dies! • Making stateful stream processing be fault-tolerant is challenging!
not processed by the nodes. – Processes each record atleast once – May update mutable state twice – Mutable state can be lost due to failure. • Trident – Use transactions to update state! – Processes each record exactly once. – Per state transaction updates slow.
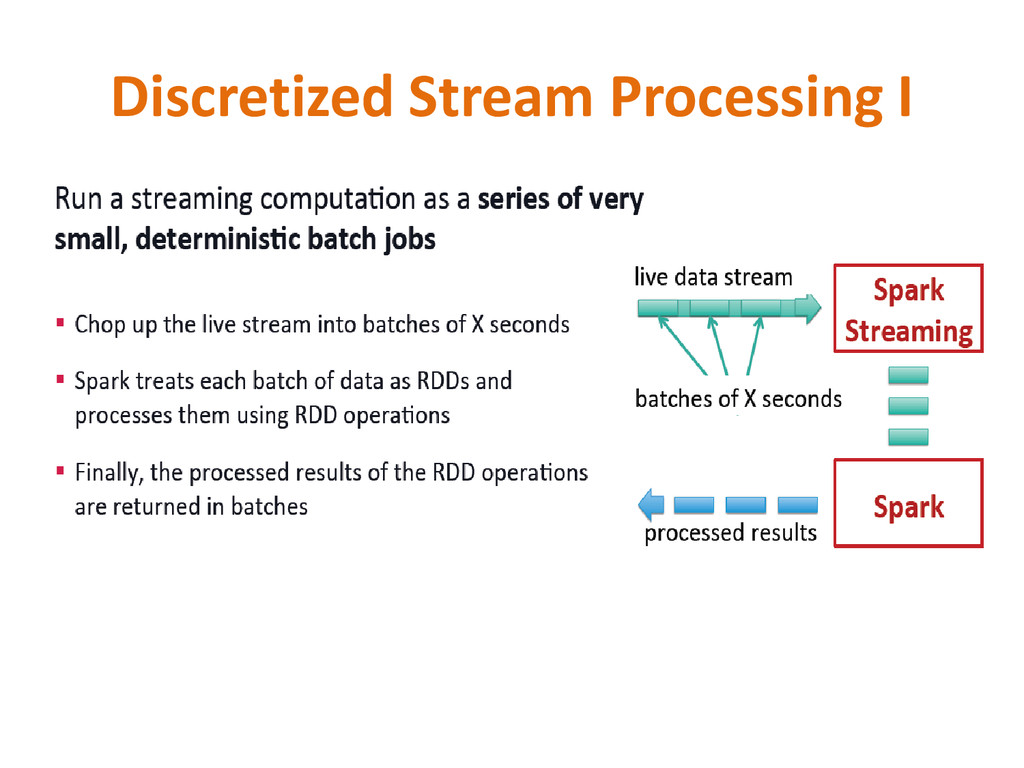
live data streams. • Data can be ingested from many sources like Kafka, Flume, Twitter, ZeroMQ, Kinesis or plain old TCP sockets. • Data processed using complex algorithms expressed with high-level functions like map, reduce, join and window. • Finally, processed data can be pushed out to file systems, databases, and live dashboards. One can apply Spark’s machine learning, and graph processing algorithms on data streams.
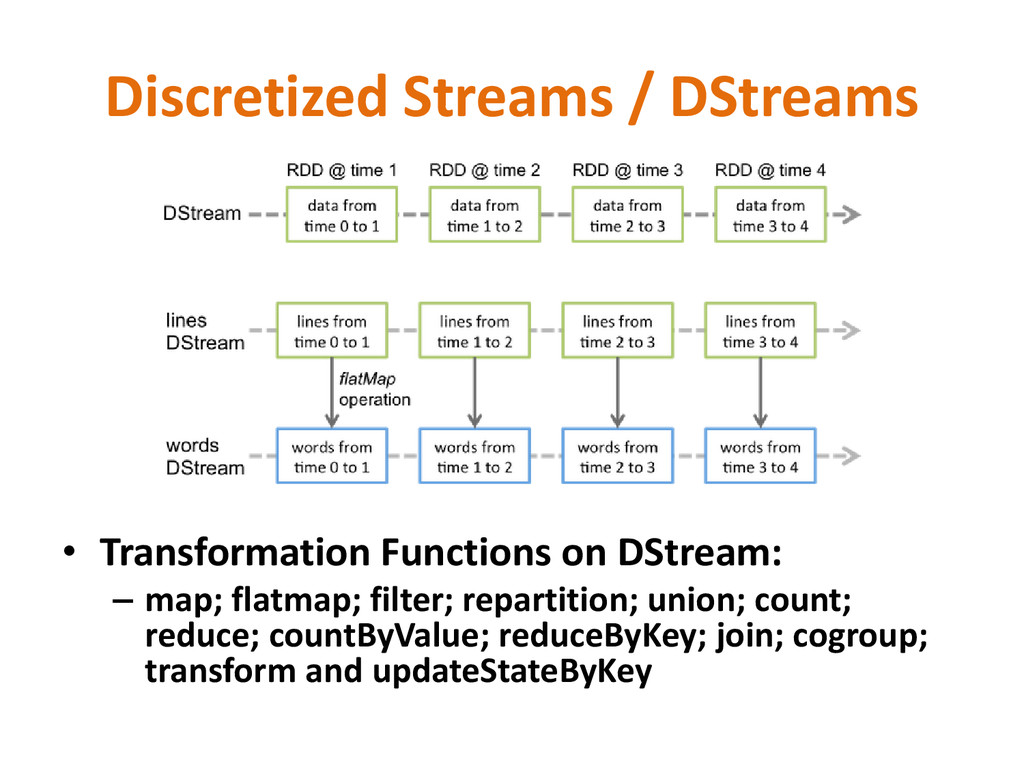
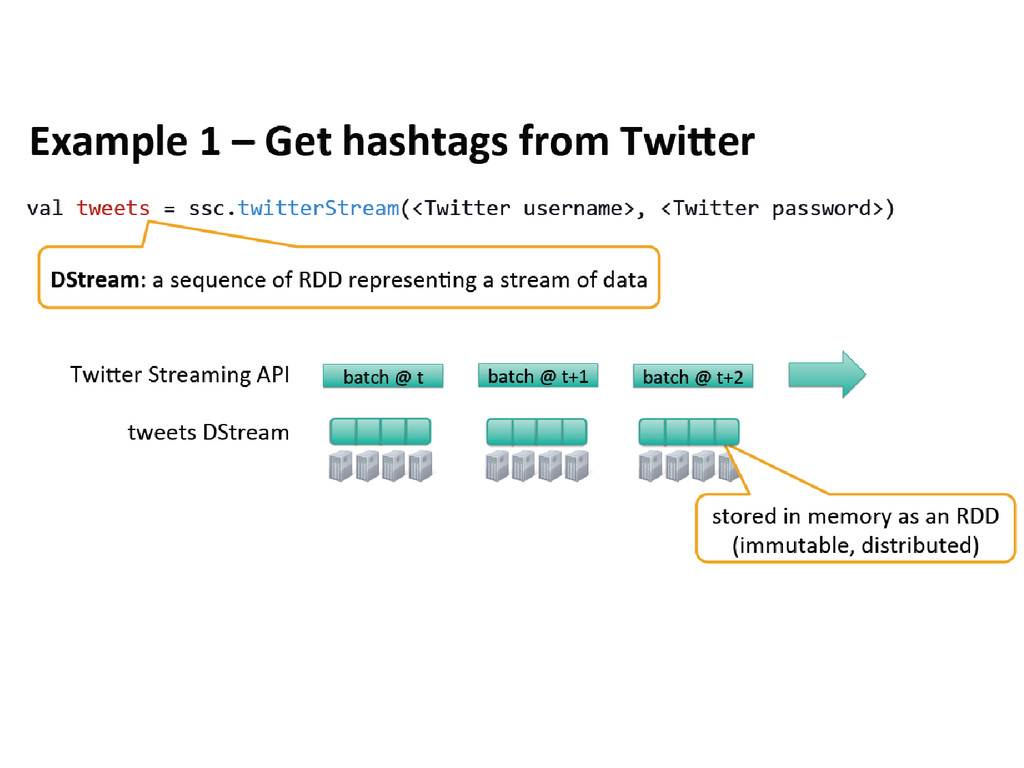
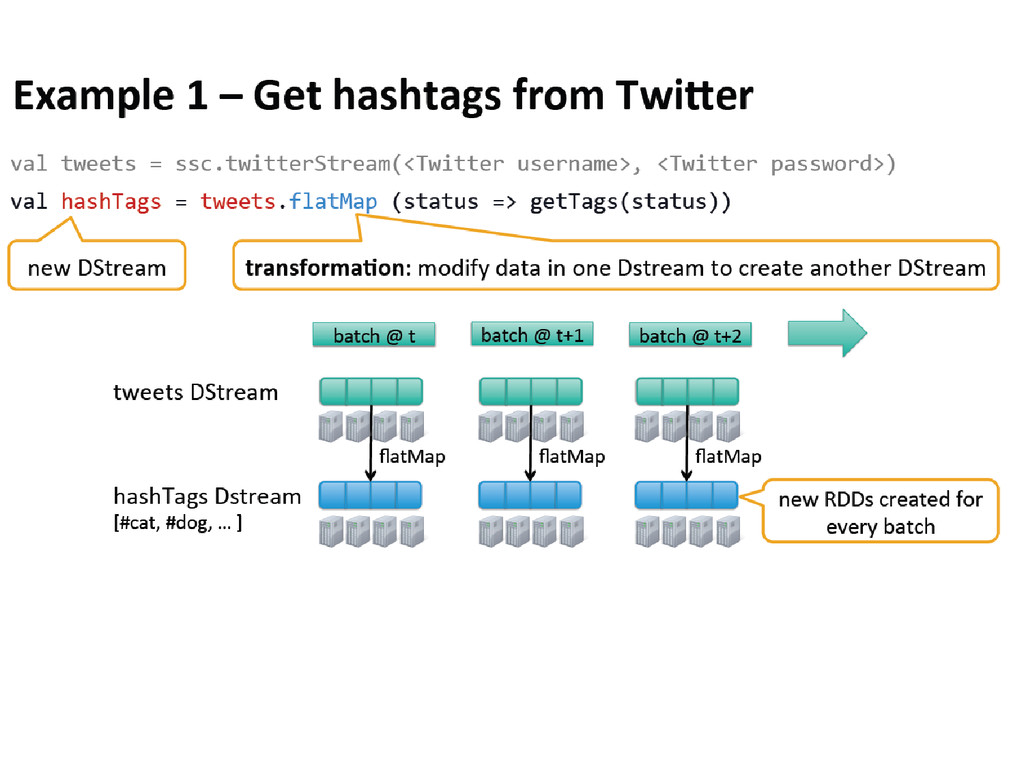
discretized stream or DStream, which represents a continuous stream of data. • DStreams can be created either from input data stream from sources such as Kafka, Flume, and Kinesis, or by applying high-level operations on other DStreams. Internally, a DStream is represented as a sequence of RDDs (Resilient Distributed Dataset). • RDDs are distributed data sets that can stay in memory and fallback to disk gracefully. RDDs if lost can be easily rebuilt using a graph that says how to reconstruct. RDDs are great if you want to keep holding a data set in memory and fire a series of queries - this works better than fetching data from disk every time.
Latency; Fault Tolerance (Every Record Processed) • Summary: Storm is a good choice if you need sub-second latency and no data loss. Spark Streaming is better if you need stateful computation, with the guarantee that each event is processed exactly once. Spark Streaming programming logic may also be easier because it is similar to batch programming, in that you are working with batches (albeit very small ones).
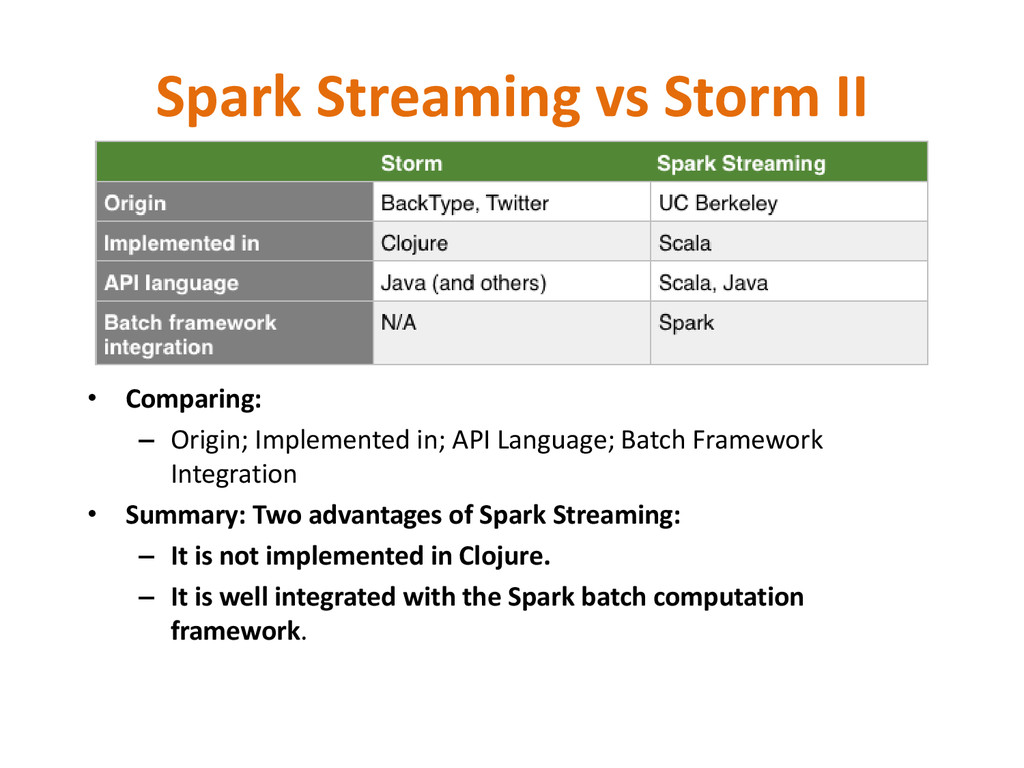
in; API Language; Batch Framework Integration • Summary: Two advantages of Spark Streaming: – It is not implemented in Clojure. – It is well integrated with the Spark batch computation framework.
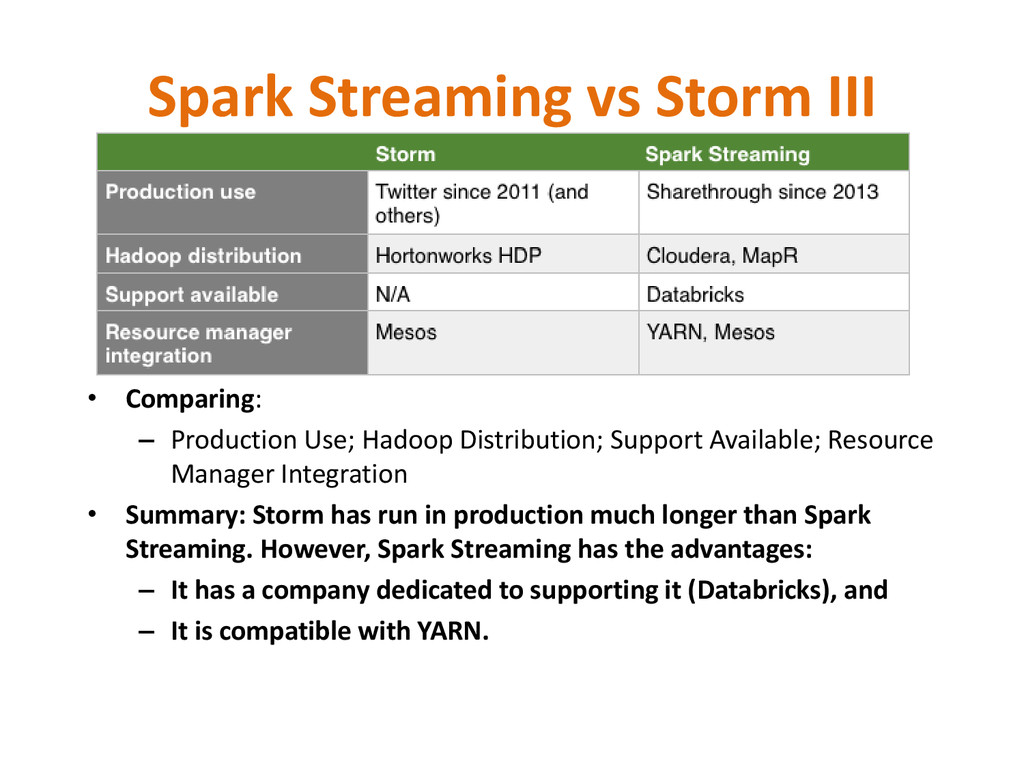
Hadoop Distribution; Support Available; Resource Manager Integration • Summary: Storm has run in production much longer than Spark Streaming. However, Spark Streaming has the advantages: – It has a company dedicated to supporting it (Databricks), and – It is compatible with YARN.
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
![Thank You Email: [email protected]](https://files.speakerdeck.com/presentations/cf8adee03b8201329954420b5d3f0408/slide_37.jpg){kind=link}